
はじめに
今回、MySQLを利用して部分一致を実現しようとしていました。
テーブルレコード自体は数万件が想定されるもので、パフォーマンス懸念から
LIKEではなく、FULLTEXT INDEX一択で考えていました。
結論を述べると、パフォーマンステストをする中でLIKE検索に切り替えました。
今回のユースケースではFULLTEXT INDEX適用時にngramパーサーを設定しましたが、それによってLIKEの方が圧倒的にパフォーマンスが良かったためです。
この記事では「LIKEよりFULLTEXT INDEXの方がパフォーマンスが良い」と聞くことも多い中、なぜこのようなことになったのかの解説と検証となります。
※FULLTEXT INDEXが何なのかは、ここでは割愛します。
前提
検証環境
- MySQL8.0(dockerコンテナ)
- articlesテーブル
- id (PK)
- title(FULLTEXT INDEX)20文字格納
- content(FULLTEXT INDEX)100文字格納
ngramパーサーを設定した経緯
検証の前になぜ今回ngramパーサーを設定したかですが、部分一致としてヒットするべきレコードがヒットしなかったからです。
下記のように2つのテーブルにそれぞれ同じ値が入ったレコードがあるとします。
| ngram_setting(ngramパーサー設定×) | not_ngram(ngramパーサー設定○) |
|---|---|
| あかさたなはまやらわ | あかさたなはまやらわ |
下記でそれぞれのテーブルにクエリを投げたいと思います。
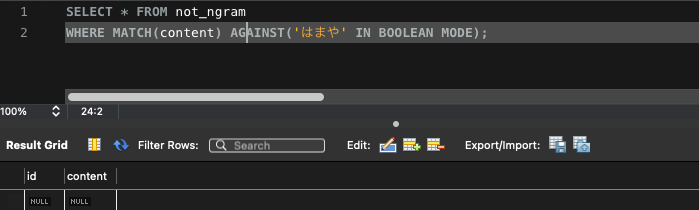
ngram設定×(ヒットしない)
SELECT * FROM not_ngram
WHERE MATCH(content) AGAINST('はまや' IN BOOLEAN MODE);
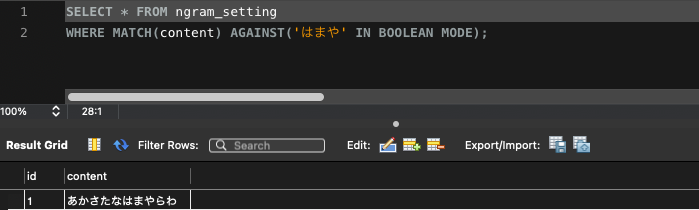
ngram設定○(ヒットする)
SELECT * FROM ngram_setting
WHERE MATCH(content) AGAINST('はまや' IN BOOLEAN MODE);
なぜこのようなことになるのか、それは文字列分割の挙動の違いになります。
ngramパーサー設定なしのデフォルトでは、スペースやカンマ区切りに文字列分割してインデックスを作成します。
ngramパーサーを設定すると、ngram_token_sizeの設定値で分割されます。(デフォルトは2)
ではこちらも下記で例を見ます。
まずは、ngramパーサーを設定していない方のテーブルです。
下記のように3レコードが入っています。
| id | content |
|---|---|
| 1 | あかさたなはまやらわ |
| 2 | さしすせそ たちつてと |
| 3 | 私はあいうえおが好きです |
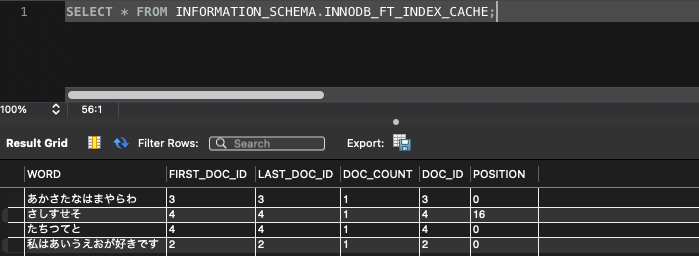
文字列分割で作成されたインデックスを見てみますと、1レコード目と3レコード目はcontentカラムの値がそのまま入っています。
そして、2レコード目は分割されてます。
これはカラムの値である「さしすせそ」と「たちつてと」の間にスペースがあるため検知され分割されました。
検索文字列として、この分割された状態のインデックスに完全一致させないと部分一致として機能しません。
そのため、先ほどヒットしなかったのは、検索文字列が「はまや」であったが、それに完全一致するインデックスがなかったためです。
では、逆にngramパーサーを設定したテーブルをみてみます。
下記のように2レコードが入っています。
| id | content |
|---|---|
| 1 | あかさたなはまやらわ |
| 2 | 私はあいうえおが好きです |
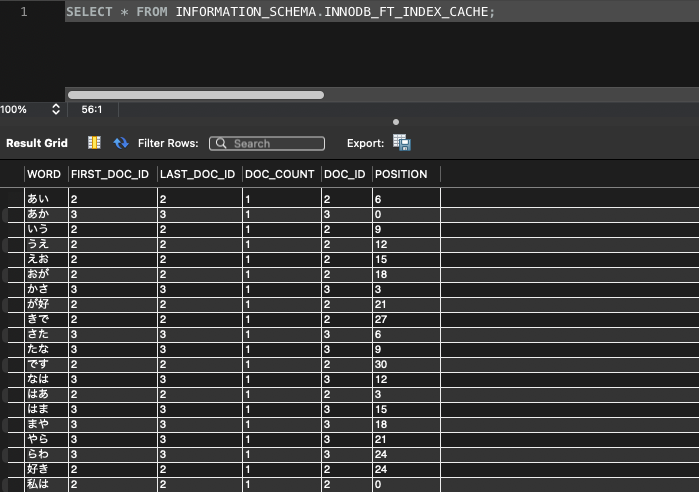
2文字ごとに分割されています。
これによって先ほどはngramパーサーを設定したテーブル側は日本語の部分一致が実現できました。
このような挙動から日本語で正確な部分一致を実現するためにngramパーサーを設定しました。
次はLIKEに切り替えた理由である、ngramパーサー設定のFULLTEXT INDEXとLIKE検索のパフォーマンス比較です。
FULLTEXT INDEXとLIKEでの部分一致速度比較
検証1(5万レコードから1万レコードを抽出)
まずは5万件から1万件のレコードを抽出してみます。
FULLTEXT INDEX
SELECT * FROM articles
WHERE MATCH(content) AGAINST('あいうえお' IN BOOLEAN MODE);
![]()
0.123 secと1万件ぐらいですが、かなり遅い印象です。
LIKE
SELECT * FROM articles WHERE content LIKE '%あいうえお%';
![]()
0.0031 secとFULLTEXT INDEXより39.6倍も早いです。圧倒的ですね。
検証2(10万レコードから5万レコードを抽出)
次に10万件から5万件を抽出してみます。
FULLTEXT INDEX
SELECT * FROM articles
WHERE MATCH(content) AGAINST('あいうえお' IN BOOLEAN MODE);
![]()
1.768 secと使い物になってないですね。。。
LIKE
SELECT * FROM articles WHERE content LIKE '%あいうえ%';
![]()
LIKEは相変わらずFULLTEXT INDEXより早く31.5倍も早いです。
検証3(検索文字列をngram_tokenサイズと同等にする)
現状のngram_token_sizeは2です。そのため検索文字列を2で実施してみます。
抽出レコードは検証2と同じく5万件です。
FULLTEXT INDEX
SELECT * FROM articles
WHERE MATCH(content) AGAINST('あい' IN BOOLEAN MODE);
![]()
0.0056 secとかなりのパフォーマンス改善が見られますね。
LIKE
SELECT * FROM articles WHERE content LIKE '%あい%';
![]()
こちらは0.0096とほんの少しだけパフォーマンスは落ちましたが、気にするほどでもないですね。
いまだにFULLTEXT INDEXよりパフォーマンスは良いです。
今回は詳細なパフォーマンス比較ではないため、検証はここで終わりますが
LIKEに切り替えた理由としては、おわかりいただけたかと思います。
なぜ今回LIKEの方がパフォーマンスが良かったのか
ここに来てやっと本題となります。
なぜ今回LIKEの方がパフォーマンスが良かったのか。
ngramパーサーを利用することでインデックスサイズが増えてしまうというのも1つかもしれません。
大きい要因のヒントは、検証3で実施したngram_token_sizeに検索文字列数を合わせるというところです。
FULLTEXT INDEXは転置インデックスとなっています。
転置インデックスとは、含まれる単語ごとで文章をリスト化するようなものです。
「あい」という単語を含む本を探したいときに、あらかじめ「あい」が含まれている本を、リストにまとめておいてくれている形です。
そのため、今回検証3でパフォーマンスが改善したのはngram_token_sizeを2としているため、2文字ごとにそのようなリストがあり素早く取得できるためです。
検証1と2で遅かったのは、ngram_token_sizeを超えた検索文字列であることで、
「あい」や「いう」が含まれたリストはあるが、それらが連続しているリストは保持していないため、結局ほとんどのレコードを確認しなければならず、パフォーマンスが落ちる。
ngramパーサーは単語間にスペースや区切り文字が入らない、日本語と中国語と韓国語を利用する際に使用するものなので、英語の場合は必要なくLIKEよりパフォーマンスも出せると思います。
しかし今回のユースケースでは日本語検索であるため、FULLTEXT INDEXで部分一致を実現するのであれば、ngramパーサー設定は必須でした。
さらに、ngram_token_sizeの値の文字数でしか検索文字列をリクエストできない、なんていう不便な要件を入れることもできないため、今回はLIKEを利用することにしました。
最後に
データ量などにもよりますが、MySQLで部分一致を実現する際に安易にFULLTEXT INDEXを選択はせず、検証してみてほしいなと思ったと同時に自分も検証するべきだったなと思います。
1つまた良い学びになりました。

