
はじめに
みなさま、生成AIはお使いでしょうか。
この記事では話題となっている LLMOps 製品である、Langfuse について特徴や機能をハンズオンを用いて解説していきます。
なお、執筆時点ですと Langfuse の日本語の情報が比較的少ないため、詳細に解説していきたいと思います。
LLMOps とは
そもそも LLMOps とは何でしょうか。
LLMOps とは DevOps や MLOps などと同様に、生成 AI ( LLM )を用いたアプリケーションを開発、デプロイ、監視、管理するためのプラクティス、ツール、テクノロジーのことです。、LLMのライフサイクル全体を効率的かつ効果的に管理することを目的としています。
LLMOps が必要となった背景
LLM の利用が急速に拡大するにつれて、以下のような課題が顕在化し、LLMOps の必要性が高まりました。
- 複雑さの増大: LLM はモデルサイズが大きく、学習データも膨大なため、開発、デプロイ、運用が複雑となる。
- コストの問題: LLM の学習、推論には大量の計算リソースが必要であり、コスト管理が重要
- 性能の監視: LLM の性能は、入力データや環境の変化によって変動する可能性があり、継続的な監視が必要
- 品質の維持: LLM の出力は、品質が一定ではなく、有害な情報や誤った情報が含まれる可能性があります。品質を維持するための対策が必要
- セキュリティ: LLM は、悪意のあるユーザーによって攻撃される可能性があり、セキュリティ対策が必要
- ガバナンス: LLM の利用には、倫理的な問題や法規制の問題が伴う可能性があり、適切なガバナンス体制が必要
これらの課題を解決し、LLM の可能性を最大限に引き出すためには、LLMOps の導入が不可欠です。LLMOps を導入することで、LLM のライフサイクル全体を効率化し、コストを削減し、性能を向上させ、品質を維持し、セキュリティを確保し、ガバナンスを強化することができます。
具体的には、LLMOps は以下のようなタスクを支援します。
- データパイプラインの構築: LLM の学習に必要なデータを収集、加工、検証するためのパイプラインを構築
- モデルの学習: LLM を学習させるためのインフラストラクチャとツールを提供
- モデルの評価: LLM の性能を評価するための指標とツールを提供します。
- モデルのデプロイ: LLM を本番環境にデプロイするためのインフラストラクチャとツールを提供
- モデルの監視: LLM の性能を継続的に監視し、異常を検知するためのツールを提供
- モデルの改善: LLM の性能を改善するための手法とツールを提供
- セキュリティ対策: LLM を攻撃から保護するための対策を講じる
- ガバナンス体制の構築: LLM の利用に関する倫理的な問題や法規制の問題に対応するためのガバナンス体制を構築
LLMOps は、LLM の利用を成功させるための鍵となる概念です。LLM を開発、デプロイ、運用する際には、LLMOps の導入を検討することが重要です。
Langfuse の特徴
Langfuse GmbH により提供されている、LLMOps を実現するためのオープンソースの LLM Engineering Platform ツールです。
LangFuse は 2024 年 11 月 5 日時点で最も利用されているオープンソースの LLMOps 製品です。
Langfuse は API ファースト、OSS、ホスティング先を選択可能という特徴を持っています。
また、透明性を重視しており、ロードマップもパブリックに公開されています。
Langfuse 自体の概要は以下の公式ドキュメントから確認できます。
Langfuse は以下の 6 つの代表的な機能を持っており、それぞれの機能でできることは以下の通りです。
- Tracing:LLM へのリクエストを収集し、モニタリング
- Prompt Management:プロンプトのバージョン管理
- Evaluations:LLM の回答を評価
- Dastasets:期待する回答となるプロンプトの追求
- LLM Playground:Langfuse UI 上での各 LLM 実行
- Comprehensive API:Langfuse の機能をREST API で提供
これらの機能の中でも、特にTrace機能が重要と説明されています。
Langfuse’s core is tracing.
※ Introducing Langfuse 2.0: The LLM Engineering Platformより
Langfuse のライセンス形態
Langfuse ではライセンス形態が Langfuse Cloud (SaaS 型) と、セルフホスト型で異なります。
Saas 型
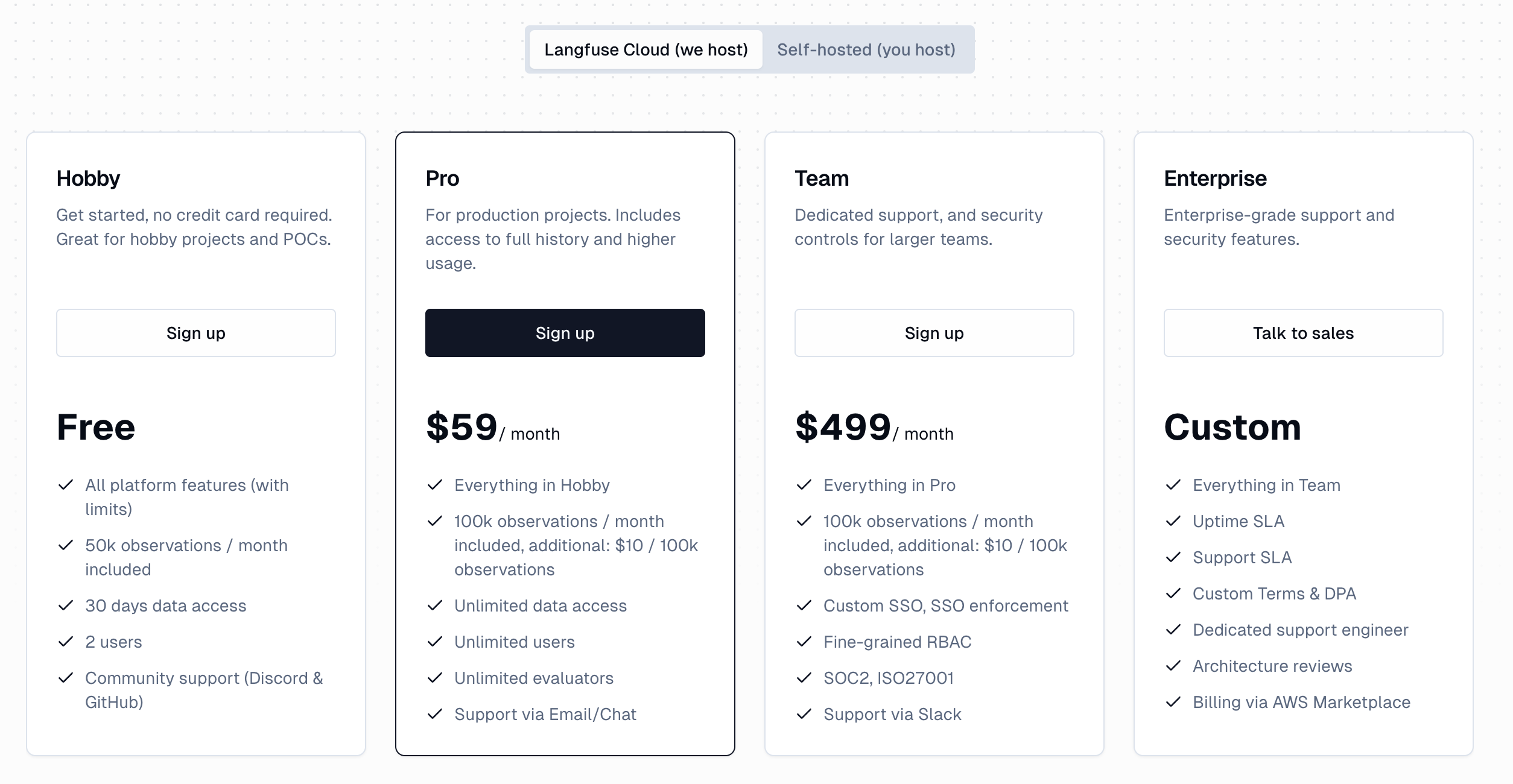
セルフホスト型
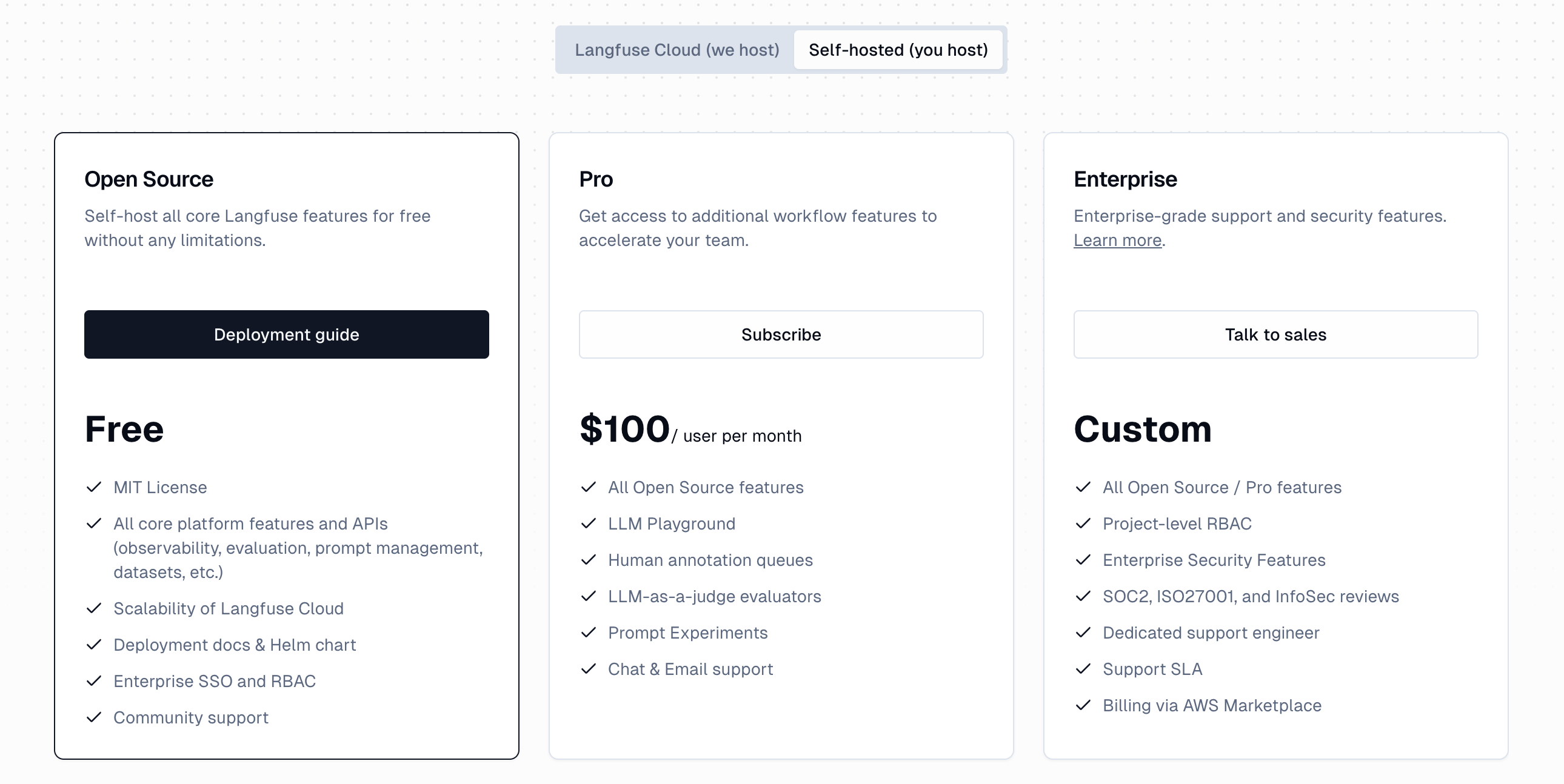
※ Pricing より
SaaS 版は事前に設定されている利用量を超過した場合は以降は自動的に課金されていくとのことですので、
事前の予算取りなどが必要な商用利用においてはセルフホスト型で利用するのが良いのではないでしょうか。
またセルフホスト版で自前で用意した環境へデプロイできるため、セキュリティ的にも柔軟に対応できるメリットがあります。
Langfuse のセットアップ
セルフホストの Langfuse は、Docker (Compose)、Kubernetes (Helm) などで起動できるようにサポートされています。
それではローカル環境で公式の手順通りにセットアップしてみます。
前提条件
前提として、ローカルPC上で以下の設定が完了しているものとします。
- Docker for Mac がインストールされている (筆者は Mac を利用)
- git コマンドがインストールされている
Langfuse のリポジトリを Clone
まずは以下コマンドを実行し、ローカルPCにLangfuseリポジトリを Clone します。
git clone https://github.com/langfuse/langfuse.git cd langfuse
Langfuse を起動
次に以下コマンドを実行し、ローカル PC 上で Langfuse コンテナを起動します。
docker compose up
Docker Cmpose 内に以下の 6 つのコンテナが含まれているため、以下コマンドを実行しすべてのコンテナが起動していることを確認します。
- langfuse-web
- langfuse-worker
- redis
- clickhouse
- postgres
- minio
docker ps --filter "label=com.docker.compose.project=langfuse"
langfuse-web コンテナが 3000 番ポートでリッスンしているため、すべてのコンテナが問題なく起動したらブラウザから http://localhost:3000 へアクセスすると以下のログイン画面が表示されます。
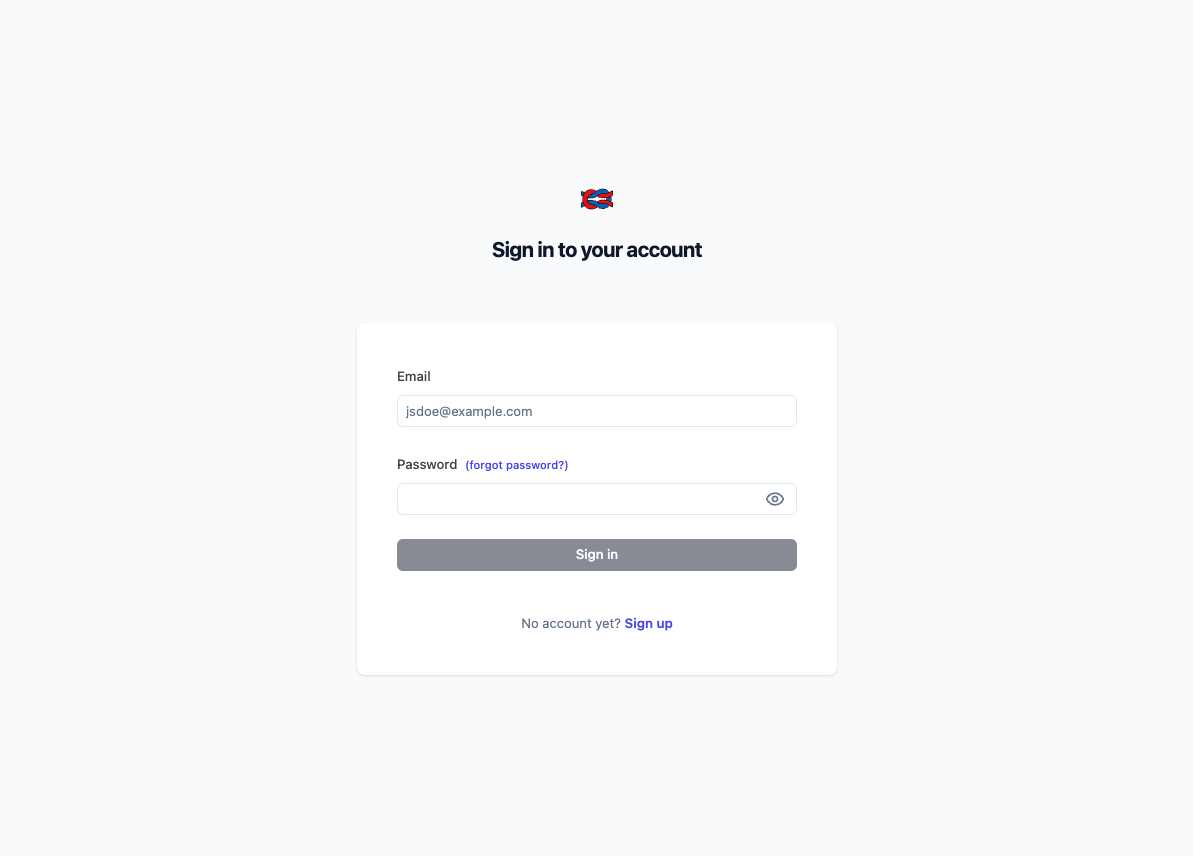
Sing Inボタン下部の Sing Up からアカウントを作成し、ログインすることで Langfuse を利用可能となります。
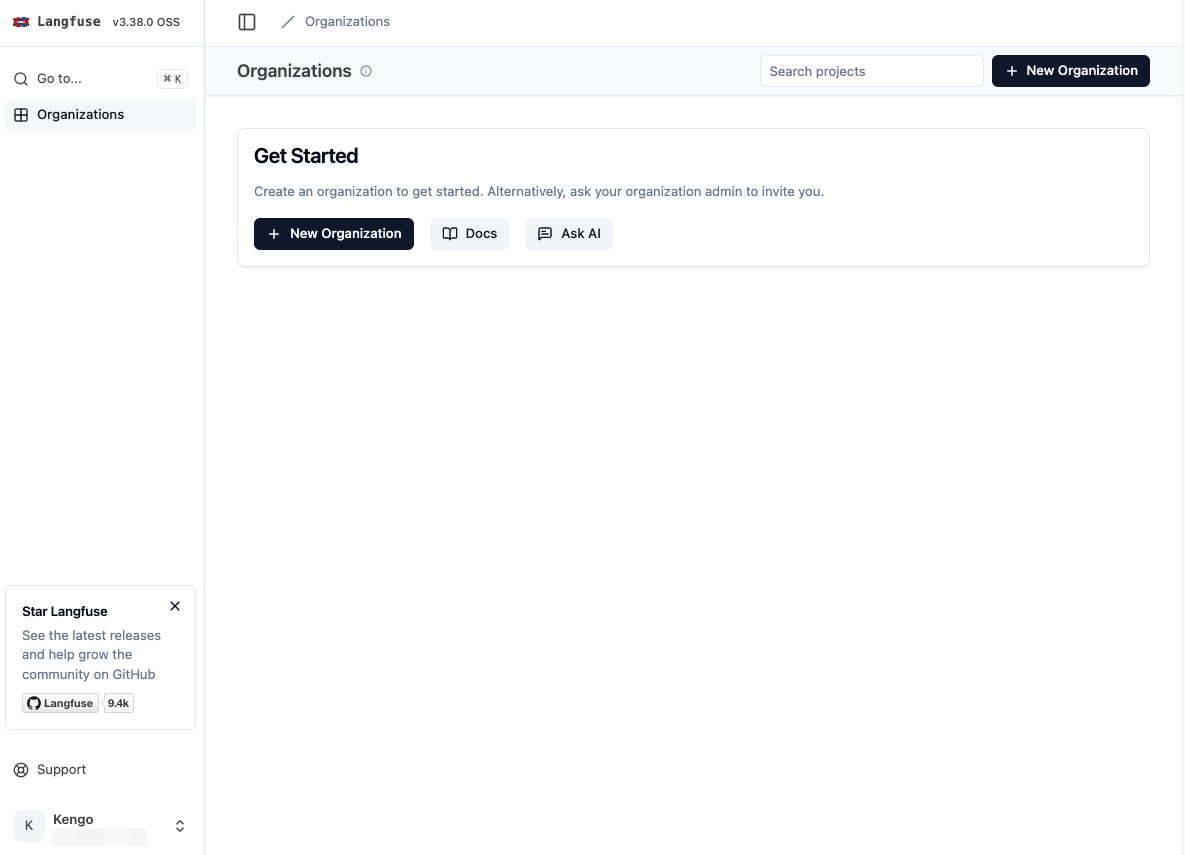
Organization と Project の作成
ログイン後の画面内の「New Organization」をクリックし、組織を作成します。
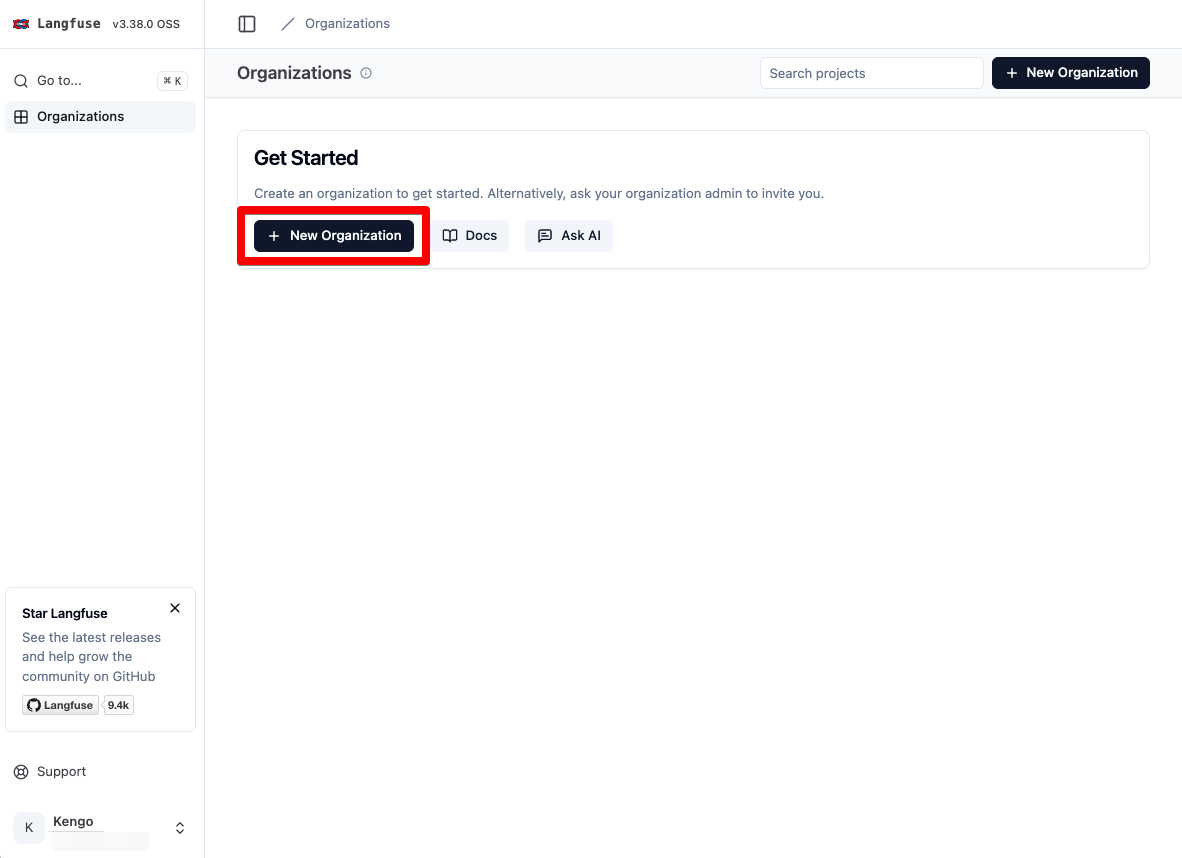
「Organization name」を入力して組織を作成します。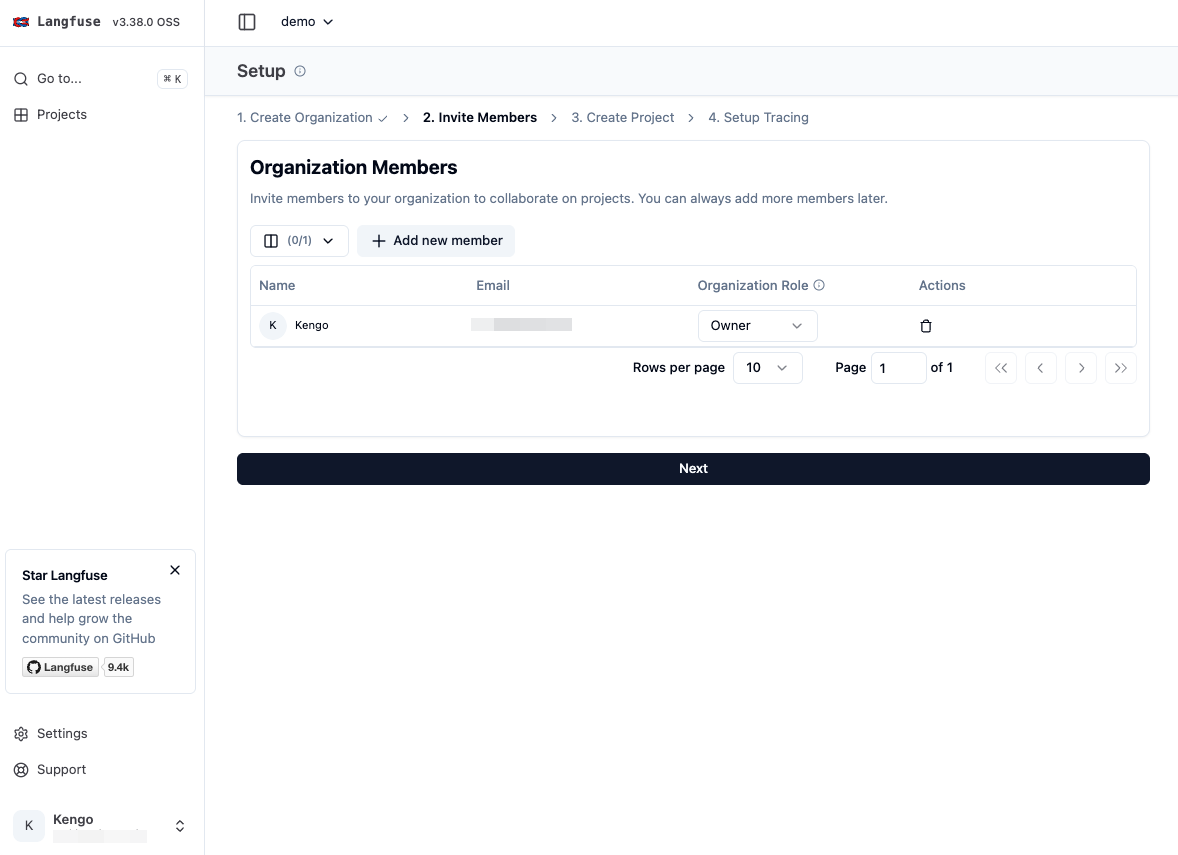
そのままプロジェクトも作成します。
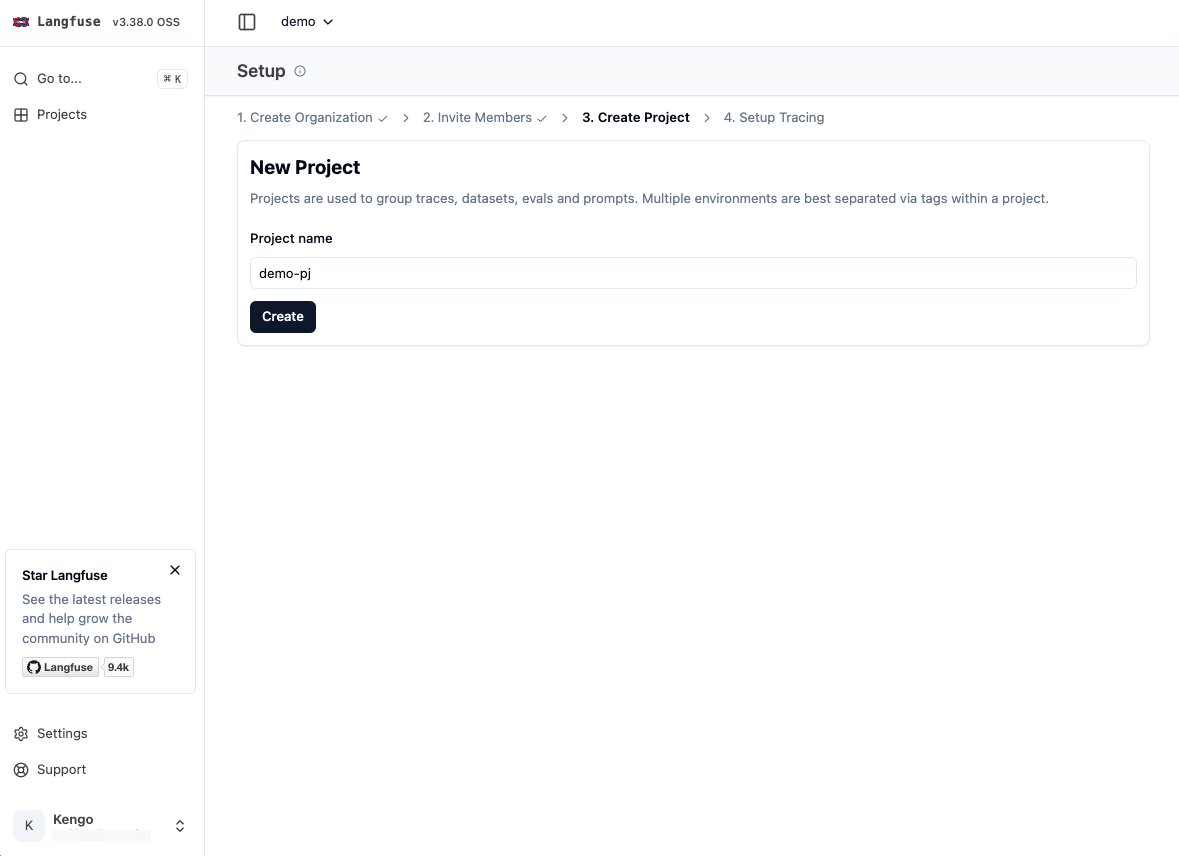
SDK 内で利用するため、そのまま API キーも作成します。
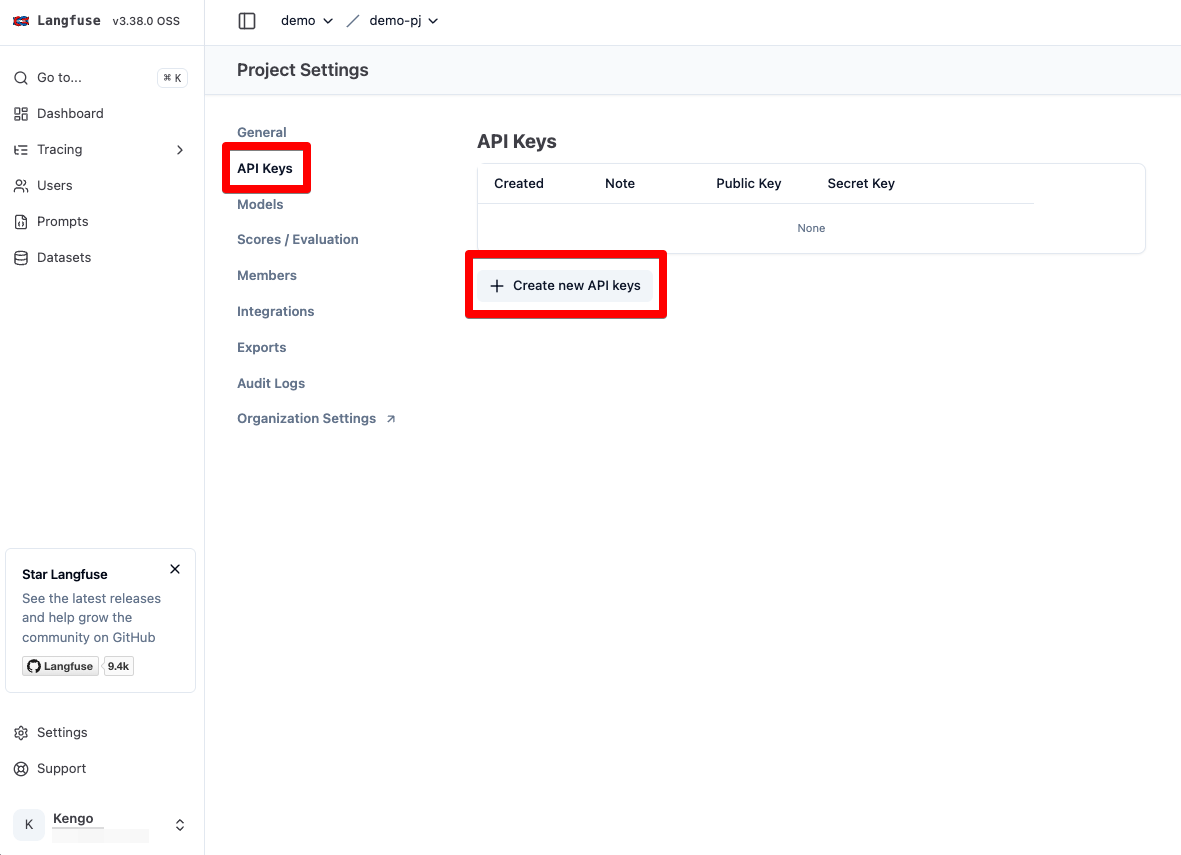
Secret Key と Public Key をコピーしておきます。
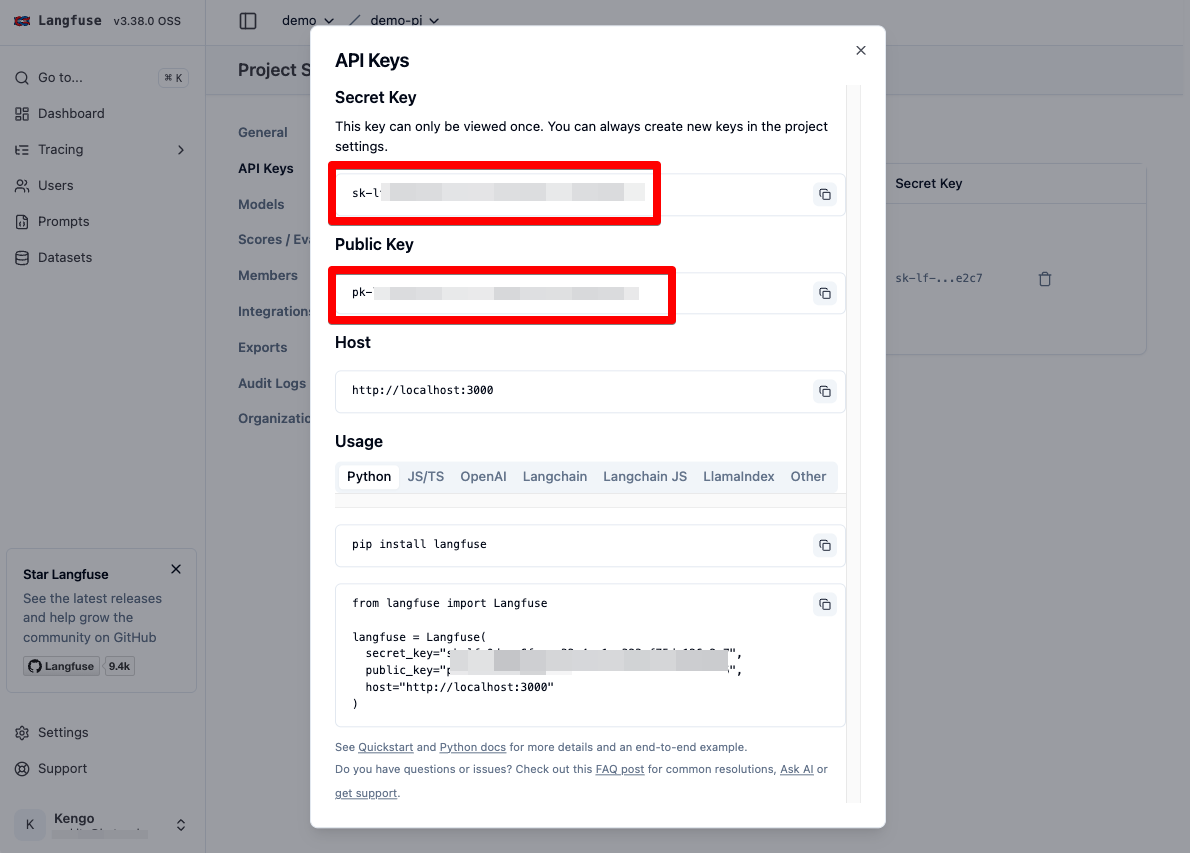
これでセットアップは完了です。
Langfuse 実行の準備
次のセクションからPython によるハンズオンをしていきます。メイン機能である Trace から順番に試してみましょう。
ここでは Langfuse SDK を使って、LLM は Vertex AI の Gemini 2.0 Flash を利用し LangChain から呼び出します。
LangChainをかんたんに説明すると、異なる LLM をラップし統一された使用感で LLM を実行することができます。なお、LangChain と Langfuse は名前が似ていますが、直接的な関係はなく開発元も異なる別製品となります。
前提条件
- Vertex AI API が有効化された Googel Cloud Project が用意されていること
- 実行する端末に gcloud コマンドがインストールされ、認証情報がセットアップされていること
- (LangChain がラップしているVertex AI SDK が自動的に参照するため)
利用バージョン
利用する各ツールのバージョンは以下の通りです。
- Python:3.11
- Langfuse:2.59.7
- LangChain:0.3.20
- langchain-google-vertexai:2.0.13
- google-cloud-aiplatform:1.78.0
pip install langfuse==2.59.7 langchain==0.3.20 langchain-google-vertexai==2.0.13 google-cloud-aiplatform==1.78.0
執筆時点の Langfuse 最新バージョンには以下のバグが存在するため、本記事通りに実施する場合は上記のバージョン固定を行ってください。
機能① : Tracing による LLM 実行のモニタリング
LLM が組み込まれたアプリケーションでは、LLM へのアクセスが繰り返し行われ、かつ Chat 型の場合はリクエストごとに順序関係があります。
Trace がないと問題が起きた際に、どの LLM リクエストが起因となっているかを特定するのが困難になります。
そこで Langfuse SDK を利用することで、LLM の種類やフレームワークなどに囚われることなく、一元的な LLM 実行を収集・分析することができます。
Trace の実行
Tracing は Langfuse では LLM Application Observability という機能で提供され、LLM API への単発実行時のインプットやアウトプット、メタデータを収集することができます。
ここでは Gemini 2.0 Flash に対して、以下の馬券の画像を渡し記載されている文字を抽出してもらいます。
なお、画像は Photock さんからお借りして、GCS へアップロードします。

実行環境で以下を demo.py として保存します。
なお、コメントが追加されている変数の値はご自身の環境の値で書き換えを行ってください。
# Initialize Langfuse handler
from langfuse.callback import CallbackHandler
from langchain_core.messages import HumanMessage
from langchain_google_vertexai import ChatVertexAI
langfuse_handler = CallbackHandler(
secret_key="", # 事前に取得した Secret Key に書き換え
public_key="", # 事前に取得した Public Key に書き換え
host="http://localhost:3000",
)
# Your Langchain code
llm = ChatVertexAI(model_name="gemini-2.0-flash-001", project="") # プロジェクトを自身のプロジェクト ID に書き換え
# Prepare input for model consumption
media_message = {
"type": "image_url",
"image_url": {
"url": "", # 画像を GCS へアップロードして gs:// のリンクに書き換え
},
}
text_message = {
"type": "text",
"text": """添付した画像に記載されている文字を抽出してください。ぼやけている可能性もあるのでよく注意して確認してください。なお、抽出結果だけ出力してください。""",
}
message = HumanMessage(content=[media_message, text_message])
# Add Langfuse handler as callback (classic and LCEL)
print(llm.invoke([message], config={"callbacks": [langfuse_handler]}))
コードの解説としては以下の通りです。
- まず Langfuse の CallbackHandler クラスを呼び出し、Trace のセットアップを行います。
- 次に LangChain で Gemini 2.0 Flash を呼び出す設定を行い、llm.invoke() で実行する際の config に上記で作成した Langfuse の CallbackHandler インスタンスを指定します。
- これにより、実行結果が Langfuse に Trace されます。この際の詳細な挙動やパラメータは以下のドキュメントで解説されています。
demo.py を実行します。
python demo.py
実行結果
content='2015年2回7日\n中山\n9 レース 単\n勝\n11 ジーニマジック\n☆☆500円\nJRA\n合計 ★★★★50枚****500円\n鎌ヶ谷特別\nJRA 中山\n3月21日\nWIN\nWIN\nJR\n0606101377614 1010010176214 50154086 308152\n' additional_kwargs={} response_metadata={'is_blocked': False, 'safety_ratings': [], 'usage_metadata': {'prompt_token_count': 1836, 'candidates_token_count': 110, 'total_token_count': 1946, 'cached_content_token_count': 0}, 'finish_reason': 'STOP', 'avg_logprobs': -0.03019662336869673} id='run-c4028189-5f66-4c15-b6d8-9fb28d926fda-0' usage_metadata={'input_tokens': 1836, 'output_tokens': 110, 'total_tokens': 1946}
これで実行結果が Langfuse 側に送信されているので、確認してみましょう。
再度 Langfuse に戻り、左メニューの Tracing -> Traces をクリックすると、Trace が追加されています。
Trace ID をクリックすることで、先程の LLM 実行の結果を確認することができます。
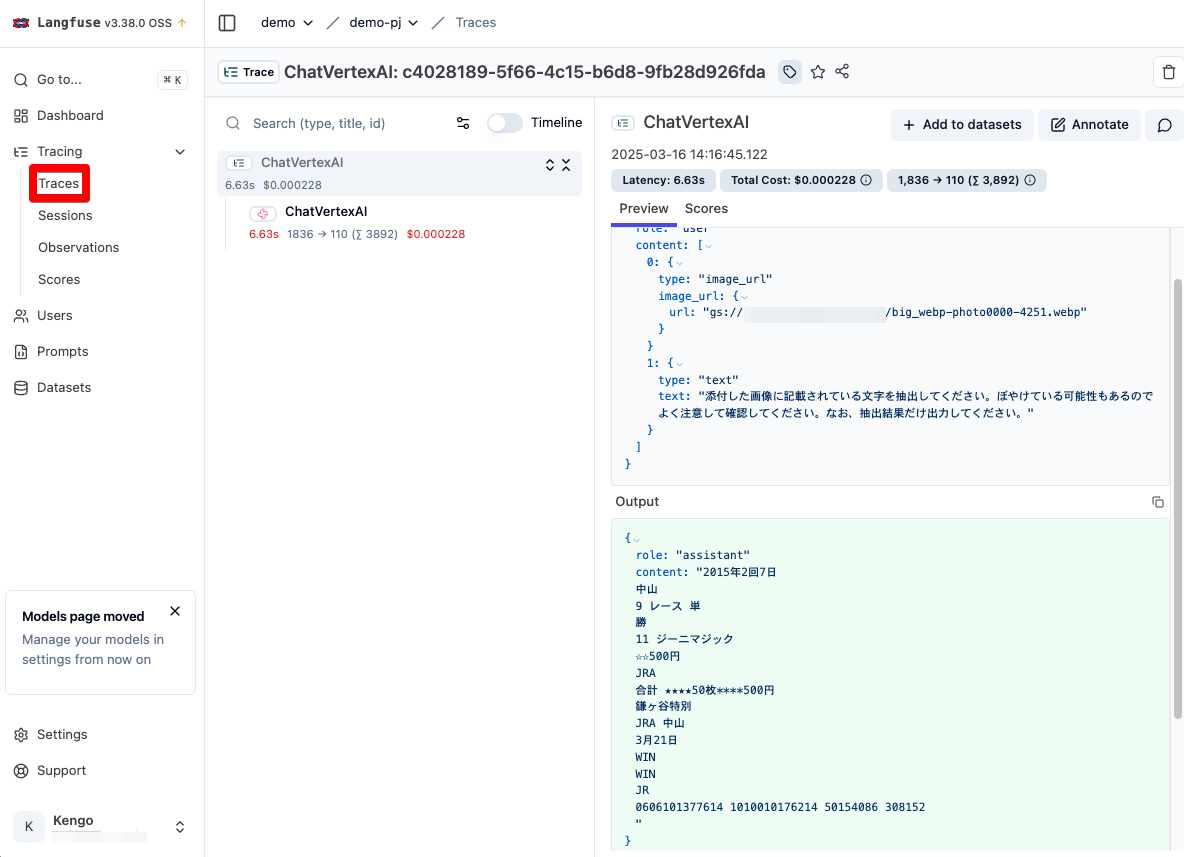
インプットとアウトプットが構造的に出力され、非常に見やすいですね。
また、呼び出したモデル情報や、レイテンシー、料金なども自動的に収集されています。
実行結果については、実際の写真と目視で比較してみましたが、「☆☆500円」の☆が1つ足りなかったりと惜しい点はあるものの、被写体が斜めに写っている画像にも関わらずほとんど完璧に出力されていました。
そして驚くべきは、左下側のかなりピントがボケている鎌ケ谷の鎌を正確に認識していたり、一番右下の人間では識別できない数字も出力されています。(もはやあっているかも不明)
Gemini 2.0 Flash、すごい…
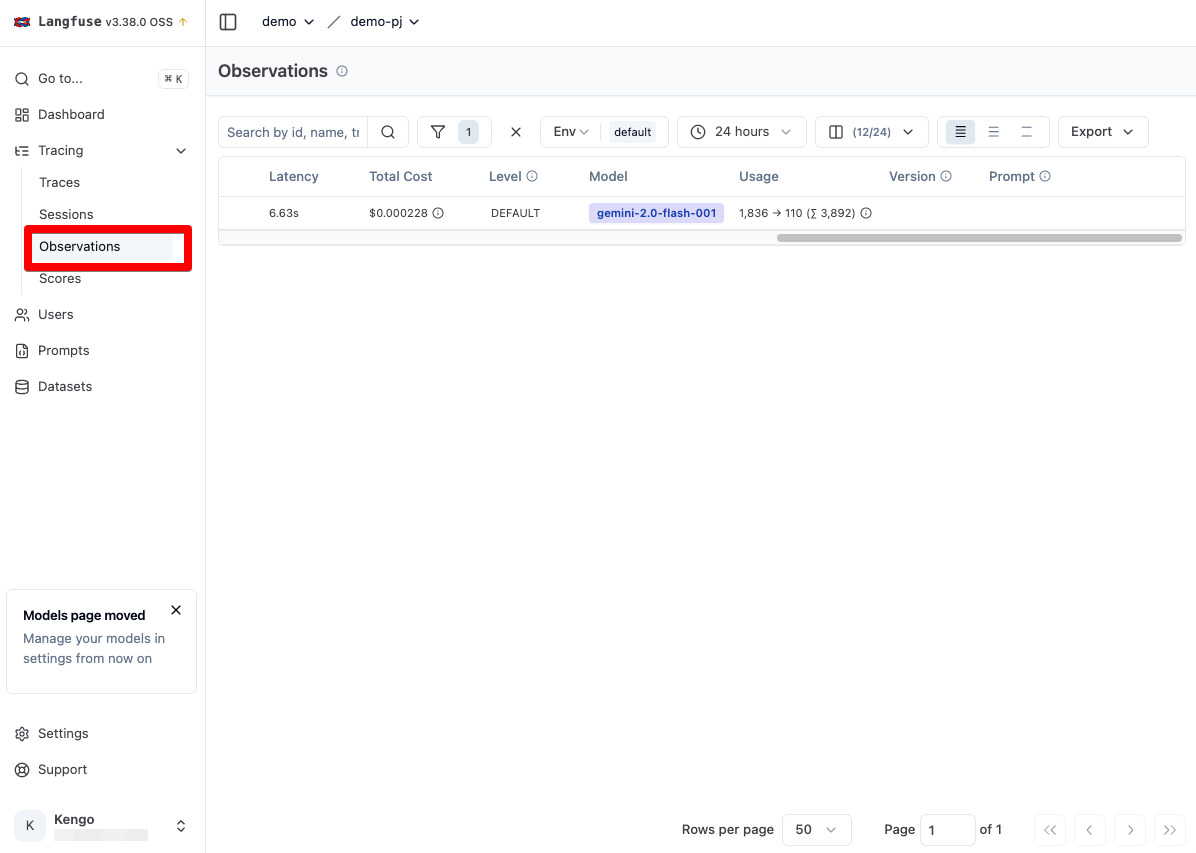
Traces と Observations の違い
また Traces に似た機能として、Observations が存在します。
これらは基本的には似た機能となりますが、Observationsの一覧画面には呼び出した LLM の Type や 開始時間、終了時間、後述するプロント管理で利用したプロンプト名やそのバージョンの列などが追加されており、より俯瞰して分析しやすい UI となっています。
ただし Observations の ID は Trace ID ですので、ID をクリックすると先ほどの Traces の詳細画面へと遷移する形になります。
Environments による環境の区分機能
また LLM Application Observability には Environments と呼ばれる、production や develop などの実行環境を指定する機能が存在します。
これによりどの環境の Trace なのかを分類し、また一覧でフィルターすることが可能となります。
それでは実際にやってみましょう。
Trace で使ったコードを以下のように修正し、environment.py とします。
# Initialize Langfuse handler
import os
from langfuse.callback import CallbackHandler
from langchain_core.messages import HumanMessage
from langchain_google_vertexai import ChatVertexAI
# Either set the environment variable or the constructor parameter. The latter takes precedence.
os.environ["LANGFUSE_TRACING_ENVIRONMENT"] = "production"
langfuse_handler = CallbackHandler(
secret_key="", # 事前に取得した Secret Key に書き換え
public_key="", # 事前に取得した Public Key に書き換え
host="http://localhost:3000",
)
# Your Langchain code
llm = ChatVertexAI(model_name="gemini-2.0-flash-001", project="") # プロジェクトを自身のプロジェクト ID に書き換え
# Prepare input for model consumption
media_message = {
"type": "image_url",
"image_url": {
"url": "", # 画像を GCS へアップロードして gs:// のリンクに書き換え
},
}
text_message = {
"type": "text",
"text": """添付した画像に記載されている文字を抽出してください。ぼやけている可能性もあるのでよく注意して確認してください。なお、抽出結果だけ出力してください。""",
}
message = HumanMessage(content=[media_message, text_message])
# Add Langfuse handler as callback (classic and LCEL)
print(llm.invoke([message], config={"callbacks": [langfuse_handler]}))
コードの解説としては以下の通りです。
- OS 側の環境変数「LANGFUSE_TRACING_ENVIRONMENT」の値として、production を指定しています。
- これにより Langfuse SDK が自動的にこの環境変数の値を参照し、environment として Trace に設定を行ってくれます。
environment.py を実行します。
python environment.py
再度 Trace に戻ると、一覧画面の Environments 列に production の Trace が追加されています。なお、Environments のデフォルト値は default となります。
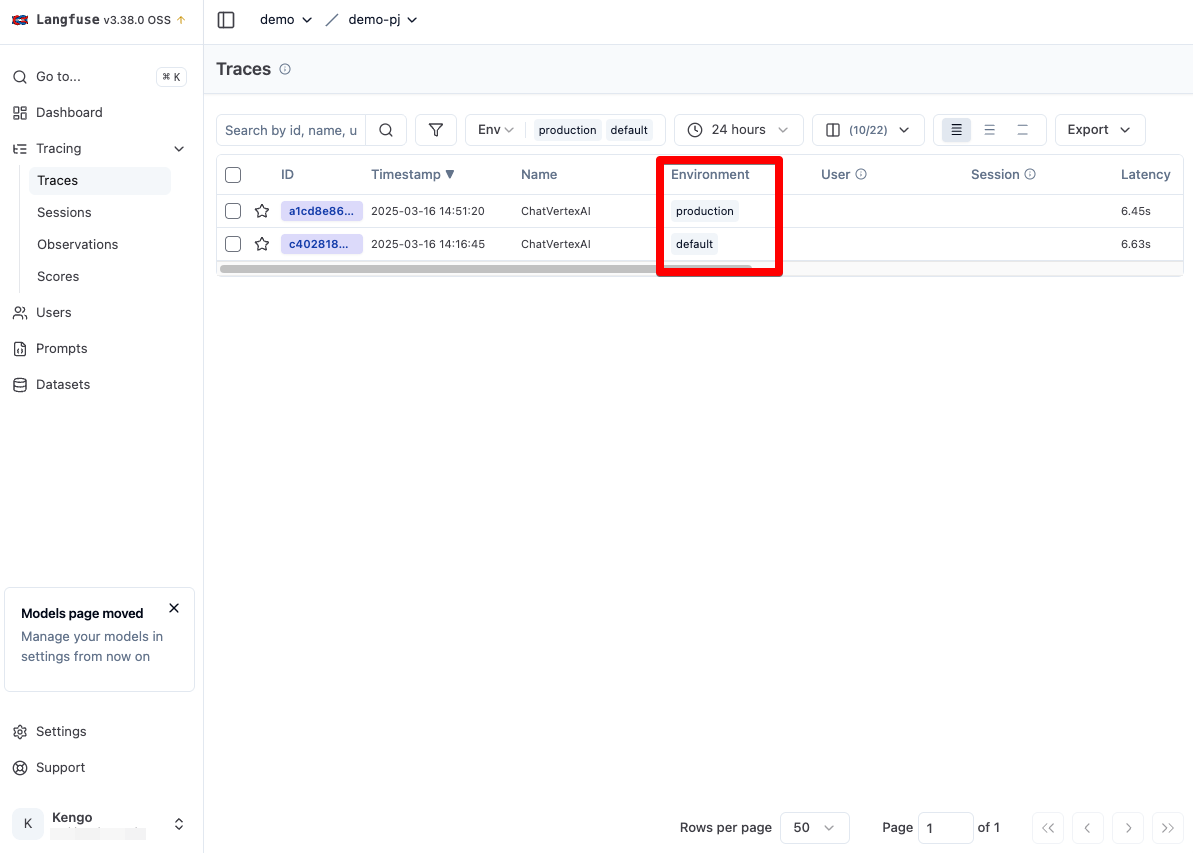
さらに画面上部の ENV を production のみとすることで、production の Trace のみを表示するようにフィルターすることができます。
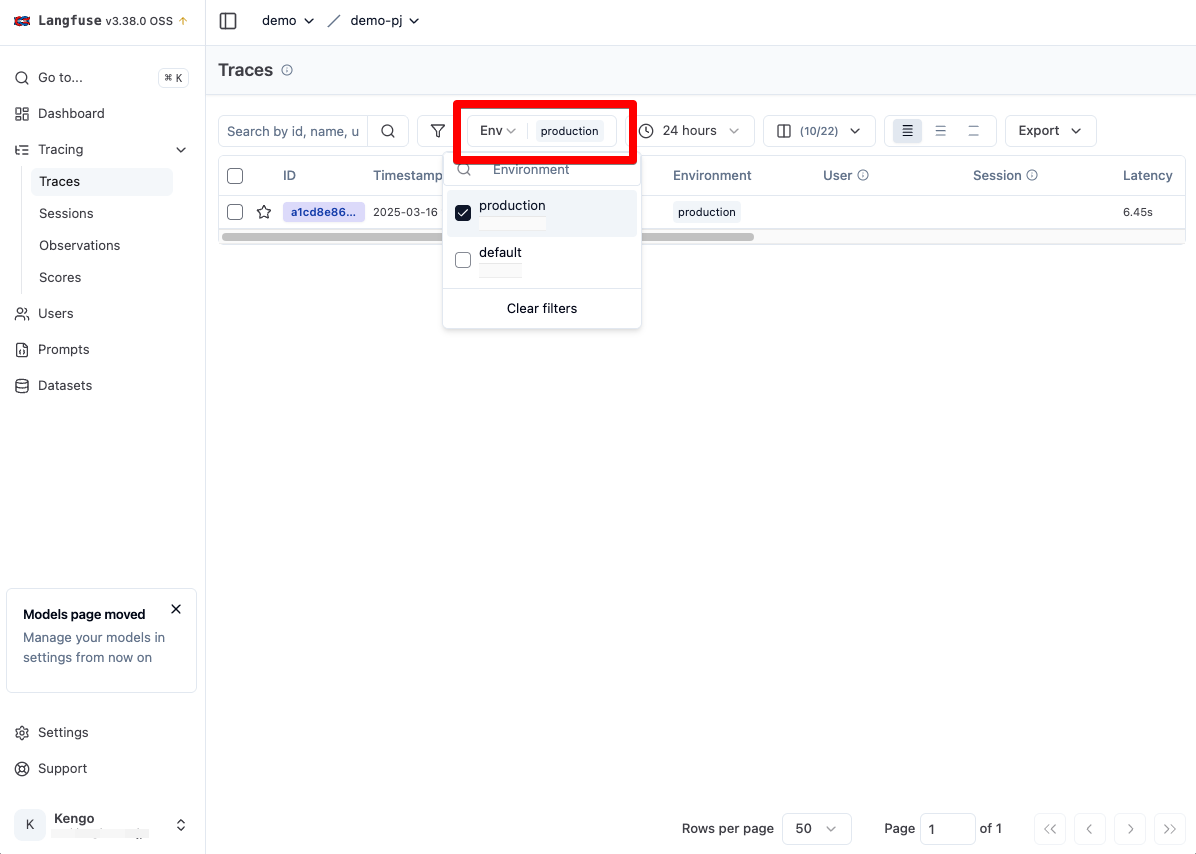
これまでのシステム開発の経験則から推測するには、環境は environment で指定するのではなく、Langfuse のプロジェクトを分けるのがオペレーションミス防止の観点から良いのではないのかと思いました。
ですが、わざわざ environment 機能が用意されている意図を考えてみたところ、おそらく Traces の一覧からあるシステムの全環境の Trace を一元的に管理することによって、環境間の精度低下やエラーをいち早く特定できるようにこのように作られているのではと個人的に思いました。
また、次に説明するマスキング機能を利用すれば、環境間の Trace で勘違いすることはあってもセキュリティ的に問題になるリスクも小さいですしね。
Releases & Versioning によるアプリケーションバージョニング機能
Environments と同様に Releases & Versioning 機能により、LLM を組み込んでいるアプリケーション自体に対してリリース名やバージョン情報を指定することができます。
詳細は以下のドキュメントで解説されています。
from langfuse.callback import CallbackHandler handler = CallbackHandler(release="")
上記のように Langfuse の CallbackHandler に直接指定することも可能ですが、Environments と同様に OS の環境変数 LANGFUSE_RELEASE に指定することで、Langfuse が自動的に参照します。
LLM Application Observability のその他の機能
なお、LLM Application Observability ではTracing や Environments、 Releases & Versioning の他にも以下の機能が提供されます。
- Sessions:チャット型アプリケーション(LLM)など、順序関係がある連続的な LLM 実行時の token やメタデータを収集。Session と Trace は 1 対 多の関係
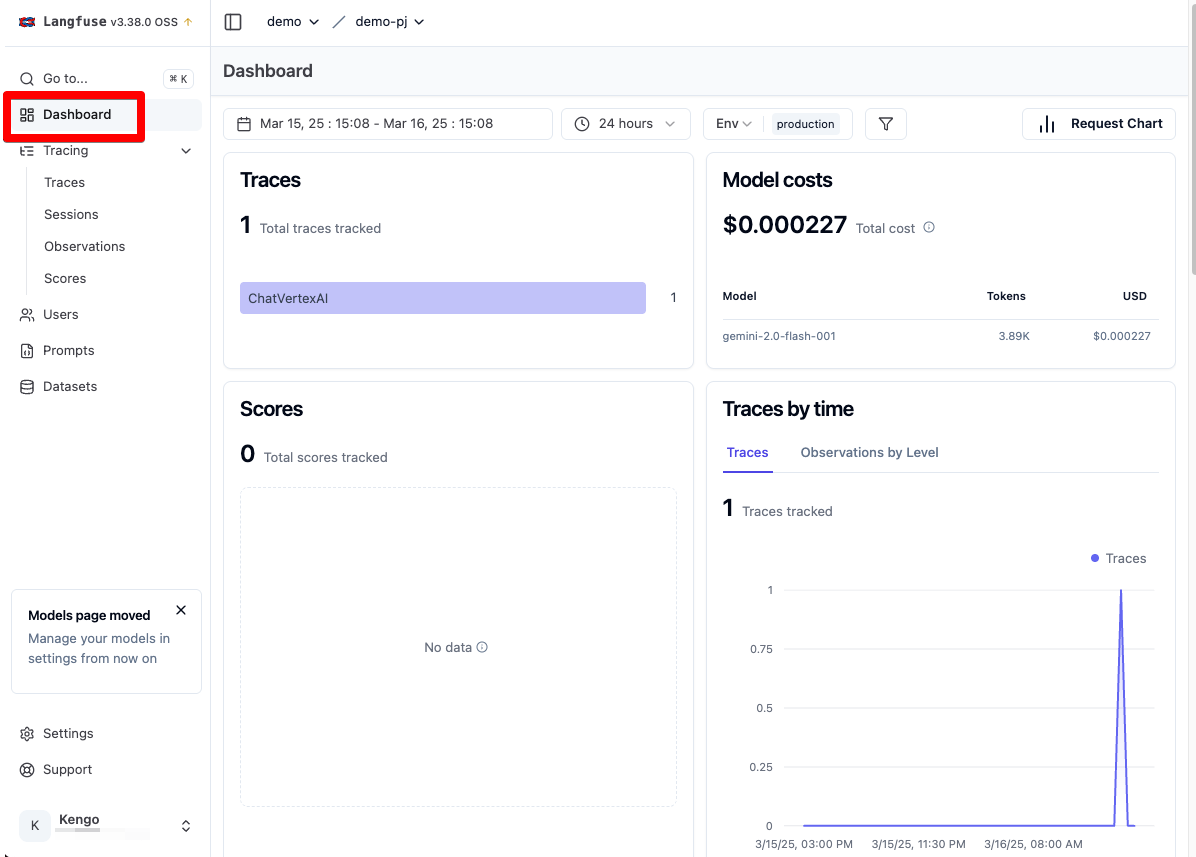
- Dashboard:Trace 情報を BI ツールのようにグラフィカルに表示する機能
- Timeline:LLM 実行時間をタイムラインとして表示。Session など複数の実行がある場合に順序関係ごとの時間を表示
以下は Dashbord 画面です。
以下は Timeline 画面です。Trace の詳細画面で Timeline のトグルを切り替えることで表示することができます。

また、Environments、 Releases & Versioning などと同様に以下の情報も Trace に付与することができます。
- Log Levels:出力するログのレベルを DEBUG などで指定
- Masking of sensitive LLM data:LangFuse に Trace を送信する前に token 内の個人情報をマスキングする処理を呼び出す
- Metadata:ユーザー独自のメタデータの追加
- Multi-Modality and Attachments:画像や音声ファイルをインプットした際に自動で収集する機能。ただし現時点では画像はbase64エンコードでインプットされたものが対象
- Sampling:Langfuse に送信する Trace の量を制御
- Tagging traces:フィルター対象にできるユーザー独自のタグの追加
- Users:Langfuse ユーザー情報。このユーザーごとに Trace を分類、分析することが可能
機能② : Prompt Management によるプロンプトのバージョン管理
続いては Prompt Management 機能の解説です。
Langfuse のような LLMOps ツールを使わない場合、通常はソースコード側にプロンプトをハードコーディングするか自前DBで管理する必要があります。
ですがその方式ですと、プロンプトを変更する都度ソースコードの修正及びアプリケーションの再デプロイが必要となってしまい、運用コストが上がってしまいます。
この Prompt Management 機能を利用することにより、Langfuse 上で一元的にプロンプト管理を行うことができます。またバージョン管理機能により、プロンプトの変更履歴を追ったり、精度が低下した際に迅速にロールバックすることも可能です。
またプロンプトはもちろん Langfuse SDK からも作成できますが、Langfuse の UI 上からも作成することができます。これにより非エンジニアでもプロンプトの更新ができます。
また後述する Playground 機能により、バージョンを追加する前にテスト実行することができ、不要なデプロイを軽減することができます。
プロンプトの作成
それではプロンプトを作成していきましょう。
ここではせっかくなので UI 上から作成し、それを LangChain で利用する形でハンズオンをしていきます。
Langfuse の左メニューから Prompts を選択し、New prompt ボタンからプロンプト作成画面を開きます。
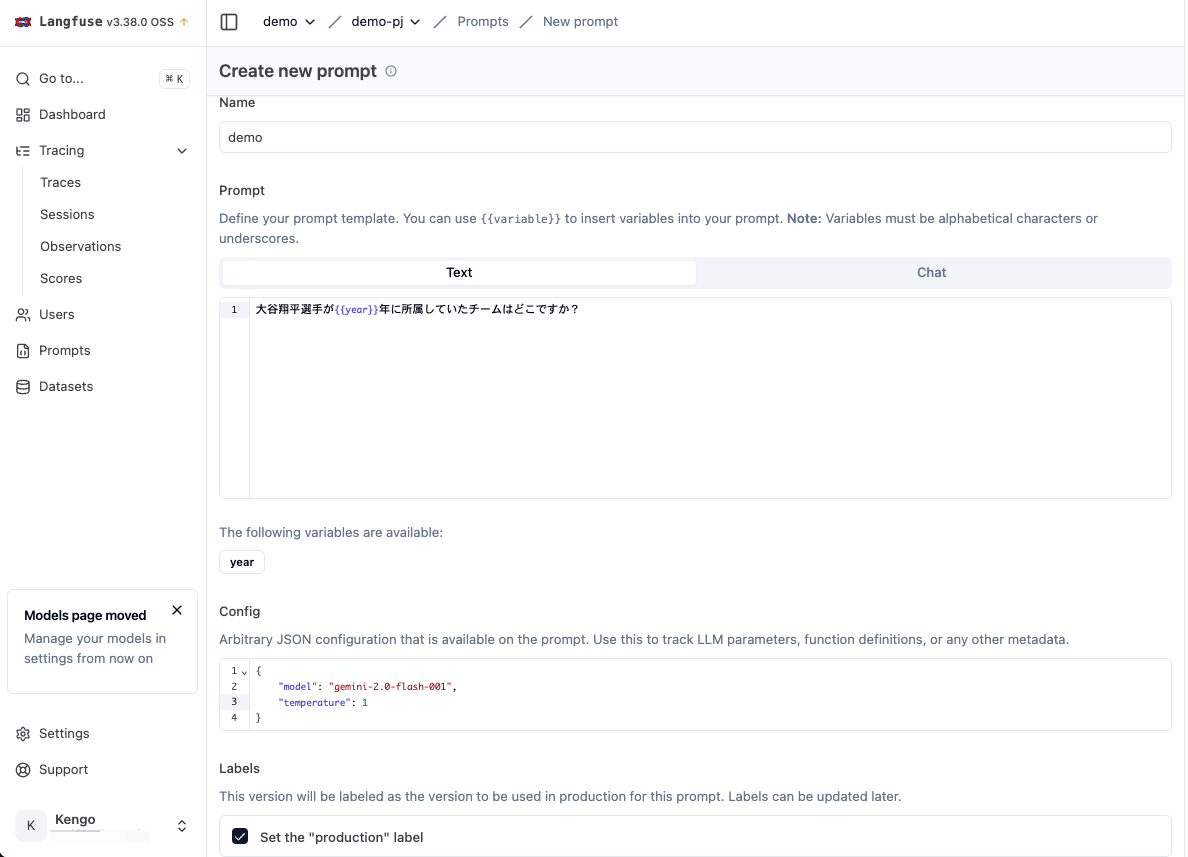
次の通りに作成します。
- Name:demo
- Prompt(type):text
- Prompt(form):大谷翔平選手が{{year}}年に所属していたチームはどこですか?
- Config::{“model”: “gemini-2.0-flash-001”, “temperature”: 1}
- Labels:Set the “production” label にチェック
なお、プロンプト内に {{var_name}} を追加することで、通常の変数と同様にその箇所に値を動的に入れることができます。
プロンプトが作成され、production と latest タグが付与されています。
デフォルトでは一番新しいバージョンに latest タグが付与され、利用されます。
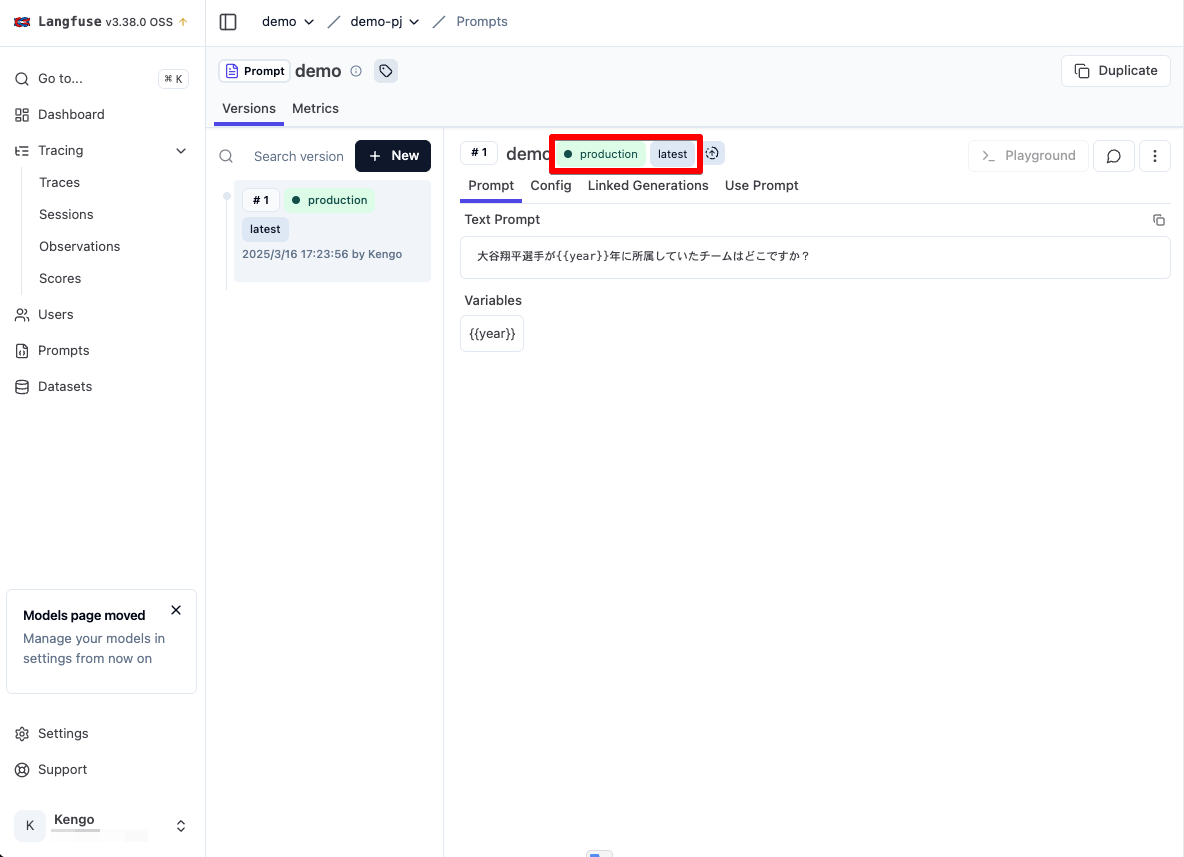
それではこのプロンプトを LangChain から呼び出してリクエストしてみましょう。
以下の use_prompt_template.py を作成し実行します。
# Initialize Langfuse handler
import os
from langfuse import Langfuse
from langfuse.callback import CallbackHandler
from langchain_google_vertexai import ChatVertexAI
from langchain_core.prompts import PromptTemplate
# Either set the environment variable or the constructor parameter. The latter takes precedence.
os.environ["LANGFUSE_PUBLIC_KEY"] = "" # 事前に取得した Public Key に書き換え
os.environ["LANGFUSE_SECRET_KEY"] = "" # 事前に取得した Secret Key に書き換え
os.environ["LANGFUSE_HOST"] = "http://localhost:3000"
os.environ["LANGFUSE_TRACING_ENVIRONMENT"] = "production"
# Initialize Langfuse client
langfuse = Langfuse()
# Initialize Langfuse CallbackHandler for Langchain (tracing)
langfuse_handler = CallbackHandler()
# Get current `production` version
langfuse_prompt = langfuse.get_prompt("demo")
print(f"実行するプロンプトの内容:{langfuse_prompt.prompt}")
langchain_prompt = PromptTemplate.from_template(
langfuse_prompt.get_langchain_prompt(),
metadata={"langfuse_prompt": langfuse_prompt},
)
# Your Langchain code
model = langfuse_prompt.config["model"]
temperature = str(langfuse_prompt.config["temperature"])
model = ChatVertexAI(model_name=model, temperature=temperature, project="") # プロジェクトを自身のプロジェクト ID に書き換え
chain = langchain_prompt | model
var_input = {
"year": "2021",
}
# Add Langfuse handler as callback (classic and LCEL)
response = chain.invoke(input=var_input, config={"callbacks": [langfuse_handler]})
print(response.content)
ソースコードの解説としては以下の通りです。
- langfuse.get_prompt() で先ほど UI 上で作成したプロンプトを取得します。なお、この際プロンプトに付与されているラベルを指定することもできます。
- 次に PromptTemplate.from_template で LangChain のプロンプトに変換し chain します。利用するプロンプトには上で取得したオブジェクトの get_langchain_prompt() メソッドを呼び出しています。これは Langfuse と LangChain でプロンプト内の変数の扱いが異なるため(LangFuse は {{}} で LangChain は {})、その変換をしてくれています。
As Langfuse and Langchain process input variables of prompt templates differently ({} instead of {{}}), we provide the prompt.get_langchain_prompt() method to transform the Langfuse prompt into a string that can be used with Langchain’s PromptTemplate. You can pass optional keyword arguments to prompt.get_langchain_prompt(**kwargs) in order to precompile some variables and handle the others with Langchain’s PromptTemplate.
- またプロンプト取得時に、作成時に指定した config を取得できるため、その値をプロンプトから取得し、model と temperature の変数に代入しています。
- 最後にプロンプトに代入する値を定義する変数 var_input を、invoke() 時に指定して実行することでプロンプトで変数となっていた箇所に値が代入された状態で実行されます。
python use_prompt_template.py
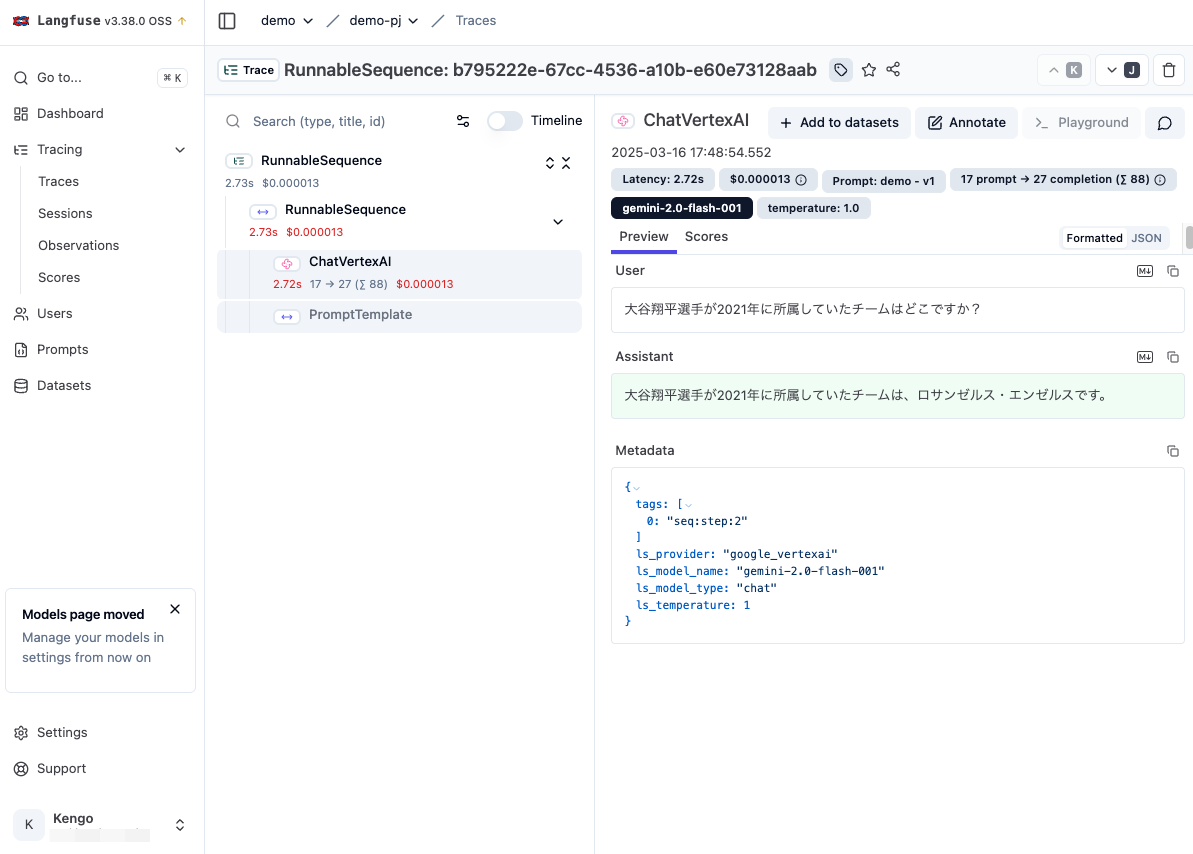
作成された Trace を見てみると、先程と異なり RunnableSequence として収集されています。
また、利用したプロンプトやバージョン情報なども付与されています。
新しいバージョンを追加
では先ほど作成したプロンプトに新しいバージョンを追加してみましょう。
プロンプトの詳細画面で New ボタンをクリックすることで、新しいバージョンを追加することができます。
現在の最新バージョンの値がフォームに入った状態の作成画面となるため、Prompt に以下を追加します。
またその年のホームラン数はいくつですか?
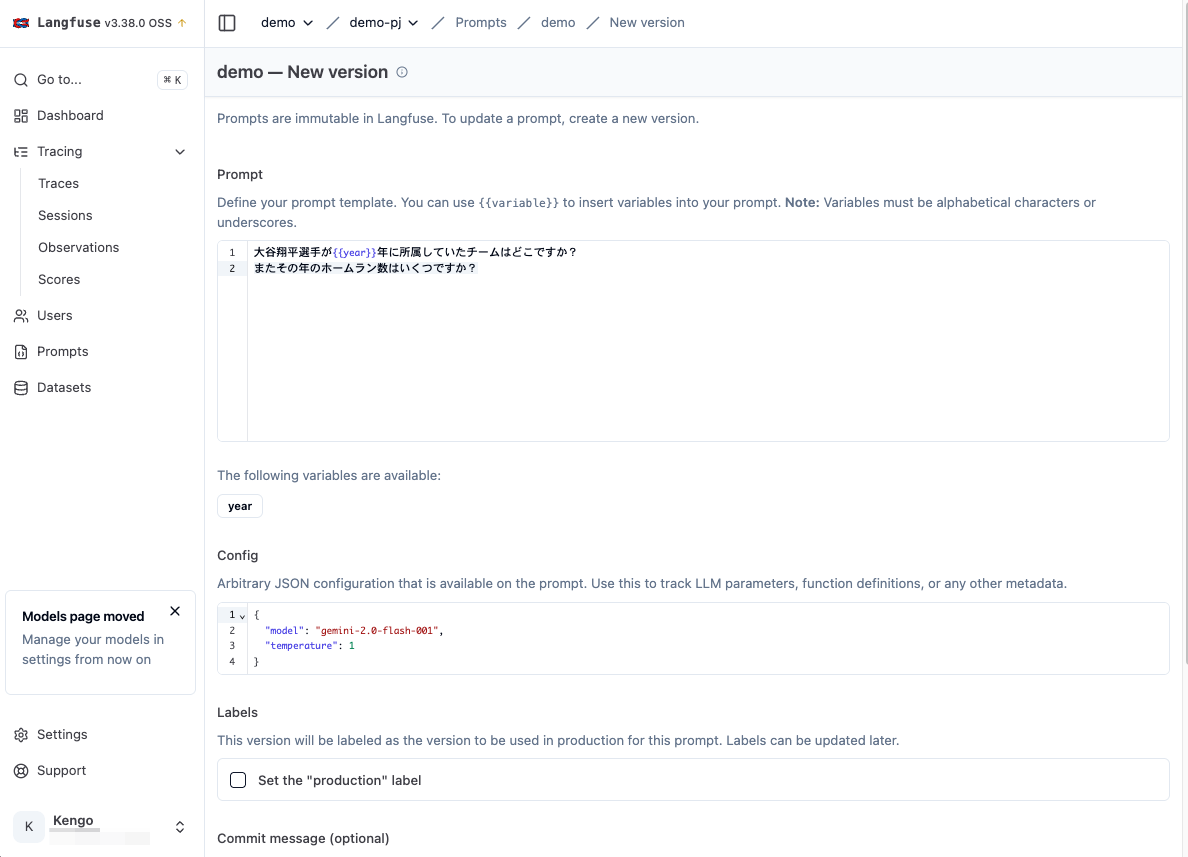
初回作成時は Labels の Set the "production" label にチェックが入っていましたが、バージョン追加時はここがオフになっています。
これは production ラベルがついた新たなバージョンを追加してしまうと、すぐさまそちらが参照されるため安全上からオフになっていると推測されます。今回は一旦チェックを外しておきましょう。
そしてページ下部の Review changes ボタンをクリックすると現在の登録済み最新バージョンと入力中のバージョンの差分の比較を見ることができます。
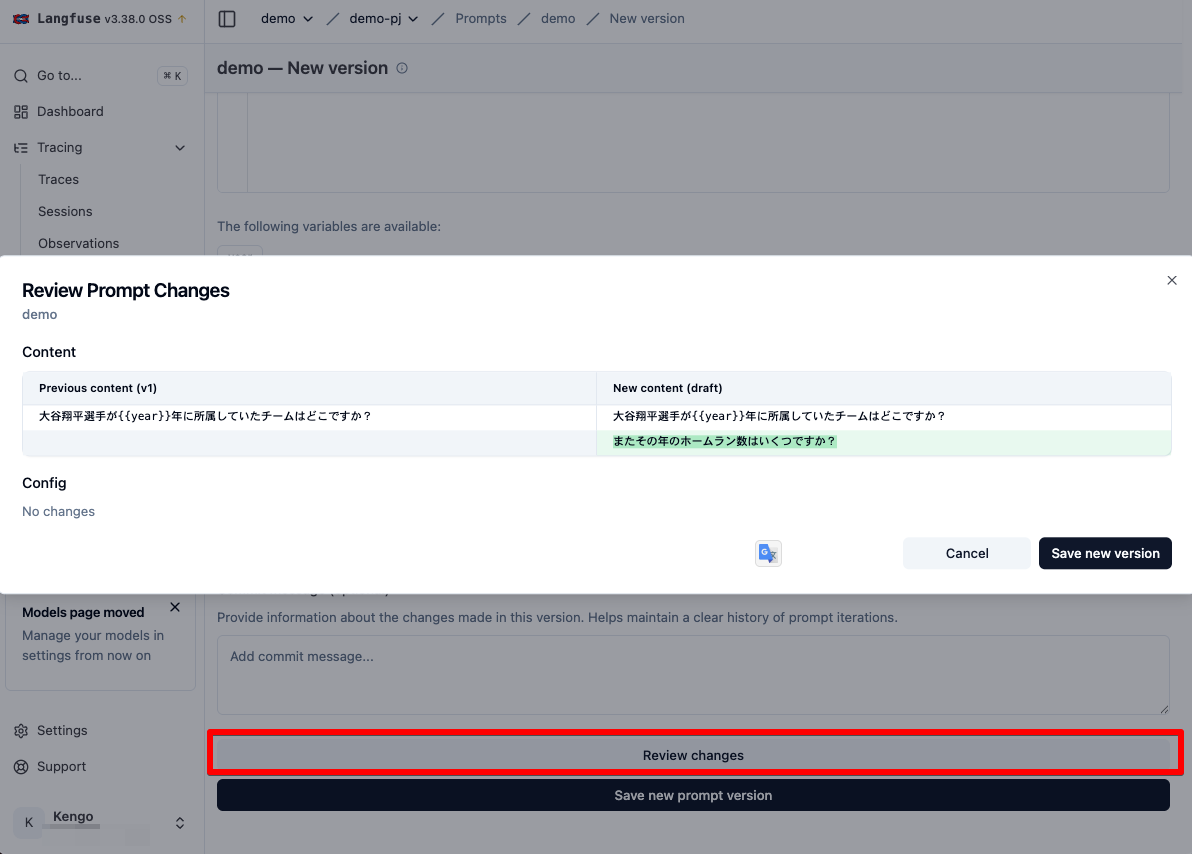
では新規バージョンを登録します。

どうやらバージョン 1 に production タグのみが、バージョン 2 には latest タグのみが付与されています。この状態で先程の use_prompt_template.py を実行するとどちらのバージョンが実行されるでしょうか。
python use_prompt_template.py
実行するプロンプトの内容:大谷翔平選手が{{year}}年に所属していたチームはどこですか?
大谷翔平選手が2021年に所属していたチームは、ロサンゼルス・エンゼルスです。
バージョン 1 が引き続き実行されています。
そうなんです。use_prompt_template.py には Environment として production が指定されているので、プロンプト側も production ラベル付与されているバージョン 1 が実行されます。
ではバージョン 2 にも production ラベルを付与してみましょう。バージョン名の↑矢印アイコンから追加できます。
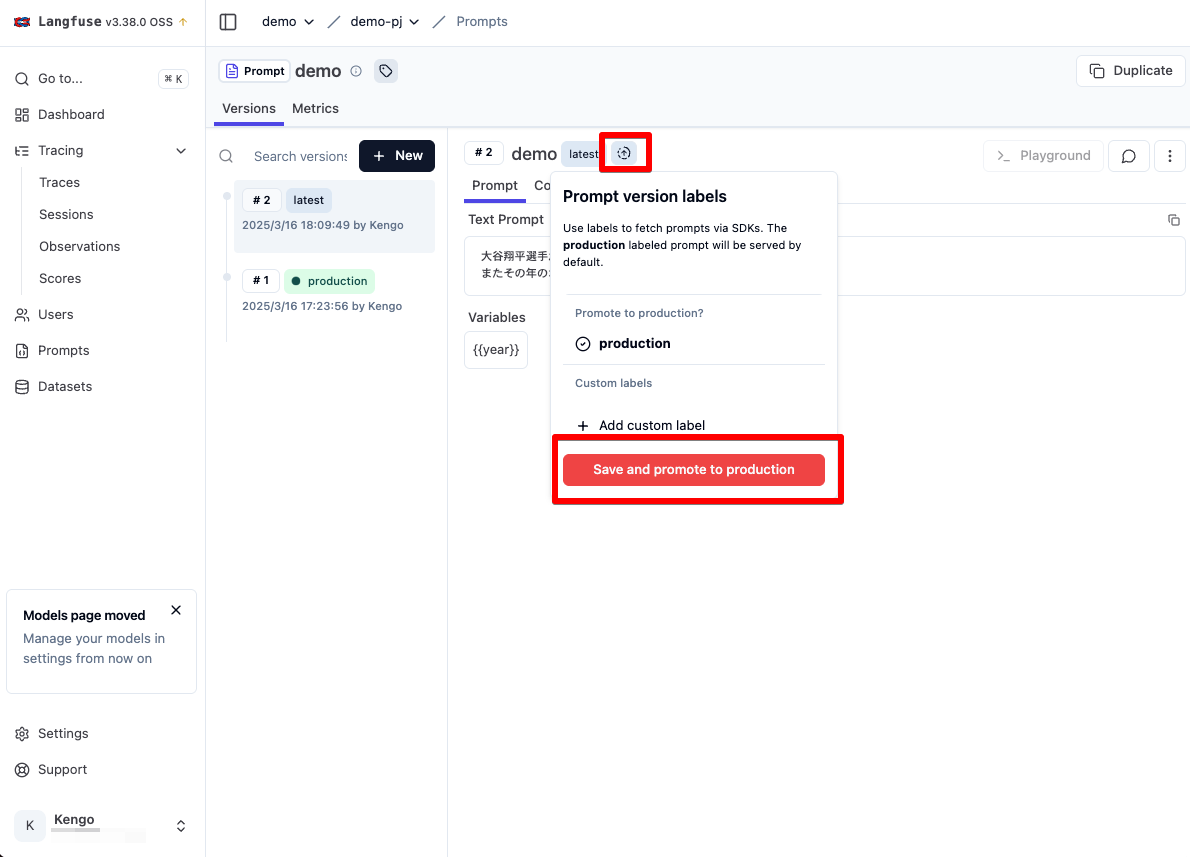
再度実行すると、バージョン 2 のプロンプトで実行されていることが確認できます。
python use_prompt_template.py
実行するプロンプトの内容:大谷翔平選手が{{year}}年に所属していたチームはどこですか?
またその年のホームラン数はいくつですか?
大谷翔平選手が2021年に所属していたチームは、ロサンゼルス・エンゼルスです。
2021年のホームラン数は46本でした。
このように明示的にチェックを入れない限りは急に作成したプロンプトが本番環境に適用されてしまった、とはならないので安心ですね。
変数を多用することのデメリット
これまでの流れからすでに勘の良い方はすでに察しているかと思いますが、プロンプト内で変数を指定してもそれに値を代入するのはソースコードで行っています。
つまり変数の値を変えたい場合や追加、削除したい場合はソースコード側を変更する必要があります。
これではこのセクションの最初で説明した、プロンプトの変更によるソースコードの変更やデプロイをしなくて済むというメリットがなくなってします。
ですので、絶対に変動しないようなもの以外は極力変数は利用せずバージョンでカバーするのが良いのではないかと筆者は考えます。
また、現状の プロンプト作成機能では Gemini に対して 画像などのマルチモーダルファイルを渡すのが難しい、もしくはできない可能性があるため、ここは詳細に調査して別記事にしようと思います。
Prompt Composability による別プロンプトの引用
Prompt Composability 機能によりプロンプト作成時に、作成済みの別プロンプトを参照することができるとのことです。
When creating the prompt via the Langfuse UI, you can use the Add prompt reference button to insert a prompt reference tag into your prompt.
ですが、セルフホスト版では Add prompt reference ボタンが見当たらなかったため、まだ利用できないかもしれないです。
※ 最近発表された機能のため
Langfuseのプロンプト管理がますます便利に!
作っておいたプロンプトを別のプロンプトから共通部品的に呼び出せるので、使い回しするようなペルソナとかアウトプット定義とかを再利用でき、めちゃ便利。全部に同じような内容を入れとくのとかメチャ長いプロンプトからの脱却が! pic.twitter.com/sDni0NJaEN
— Langfuse JP同好会 (@LangfuseJP) March 14, 2025
機能③ : Evaluations による LLM 回答の評価
続いては Evaluations による LLM の回答内容の評価方法を解説していきます。
LLM を用いない通常のソフトウェアテストの場合は例外の有無などを評価基準にできますが、LLM を組み込んだアプリケーションの場合は品質を評価するための厳密な基準が存在しません。ですので、評価が難しくなります。
そこで Evaluations では LLM アプリケーションを評価するための以下の 4 つの評価方法が提供されます。
- Human Annotation:人間が手動で Trace に対してスコアを付与
- LLM-as-a-Judge:評価用 LLM に自動でスコアを付与させる
- User Feedback:フロントエンドに評価用フォームを用意し、実際の LLM アプリケーション利用者からの評価を収集
- Custom Scores:独自の方式で出力したスコアを SDK (API)経由で付与
また Evaluations では 評価値を Score として管理します。
スコアの作成
Evaluation を始める前にまずはどのような基準で評価をするかのスコアをプロジェクト単位で作成する必要があります。
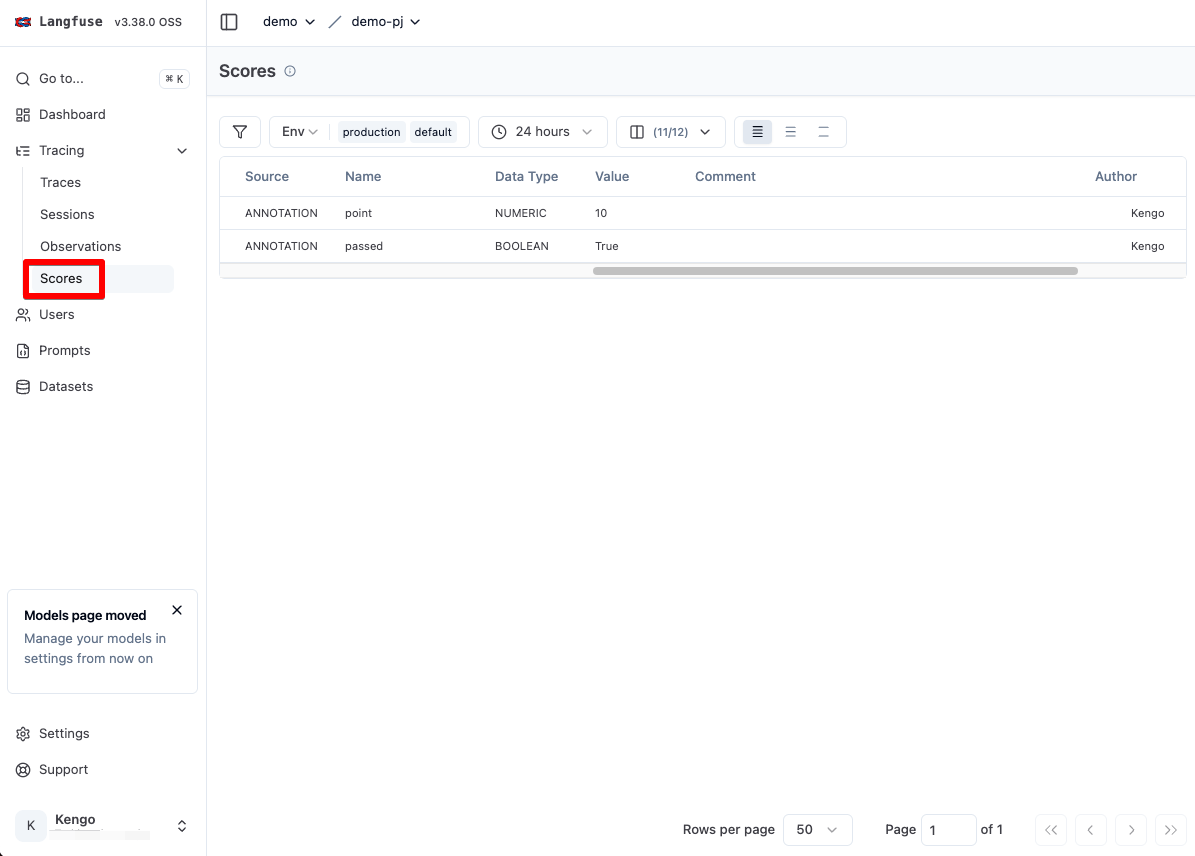
LangFuse の左メニュー Setting をクリックし、さらに Scores / Evaluation から以下のスコアを作成します。
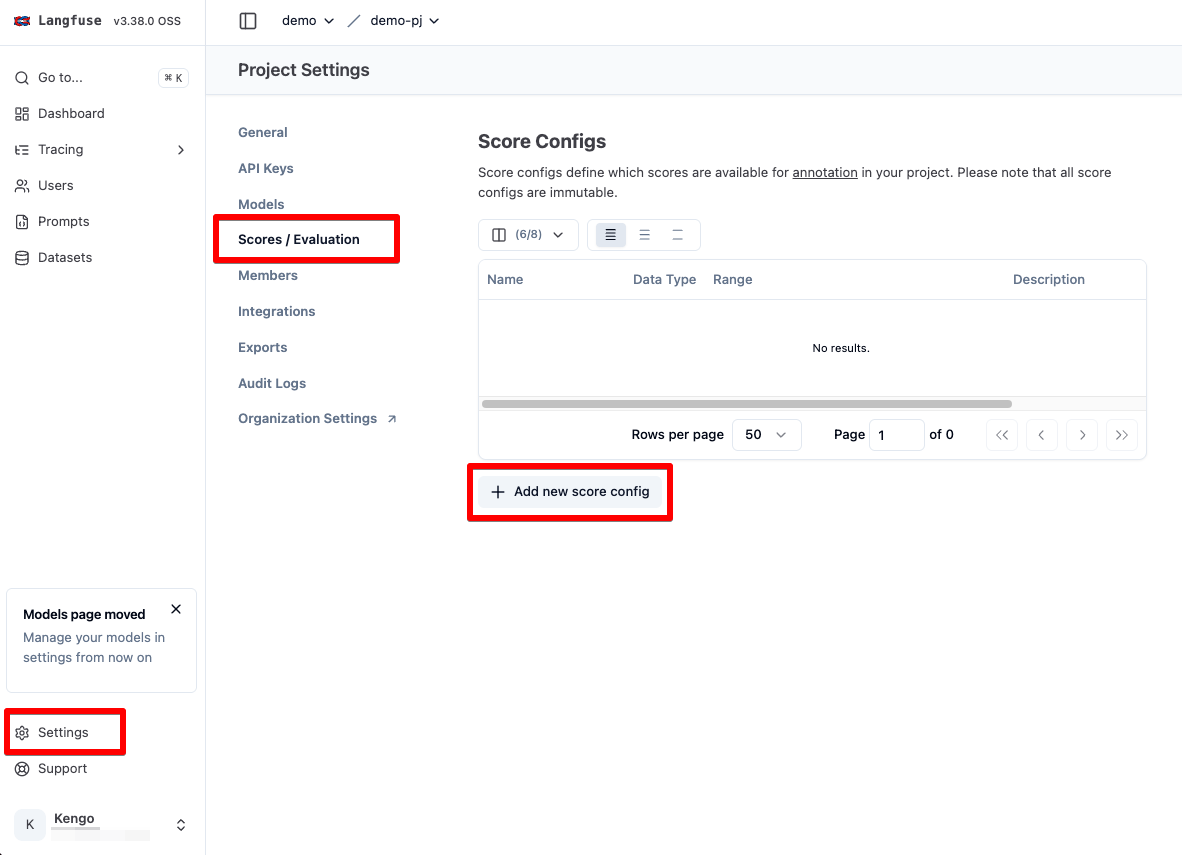
- スコア 1
- Name: point
- Data Type: NUMERIC
- Minimum: 1
- Maxinum: 10
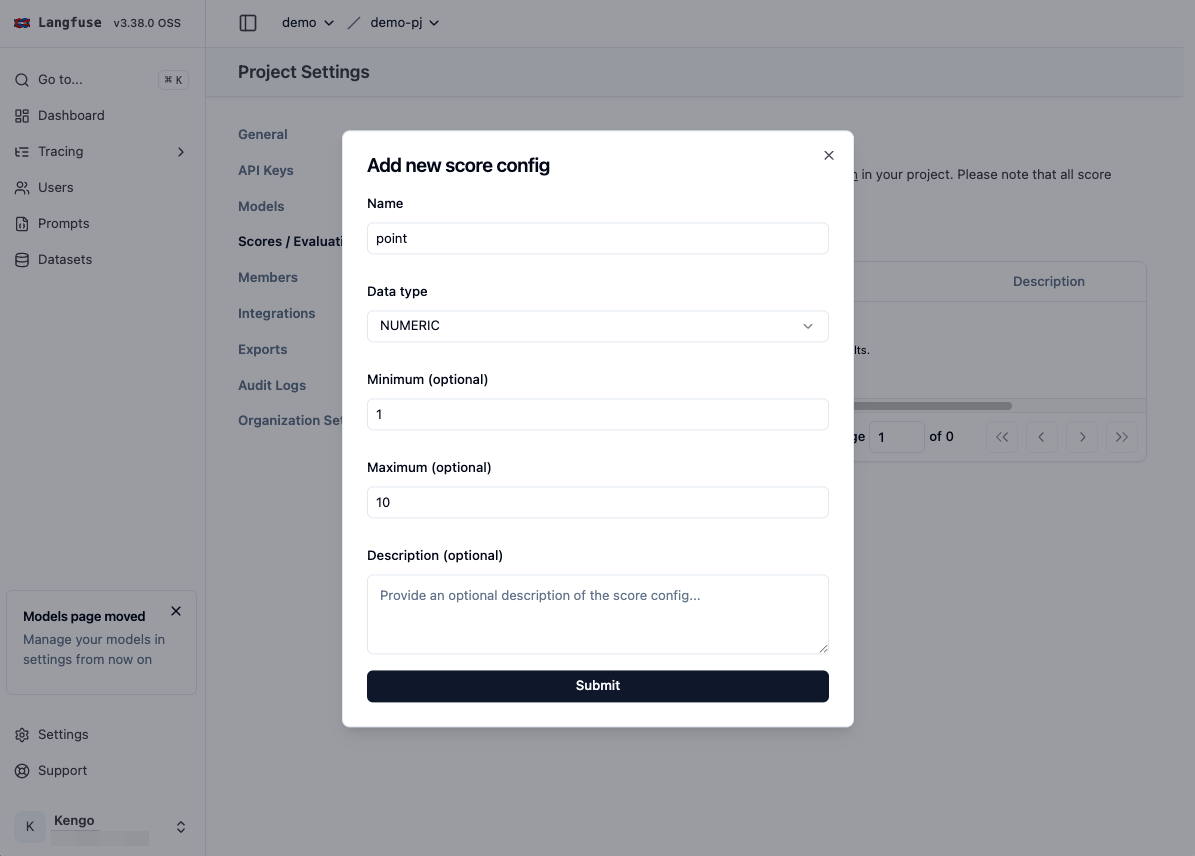
- スコア 2
- Name: passed
- Data Type: BOOLEAN
- 1: True
- 0: False
スコア 1 はシンプルに回答精度を 10 段階で評価するもの、スコア 2 は本番反映可能かを Yes / No で判断するものとします。
このあたりはアプリケーションの特徴に合わせて作成するのが良いかと思います。
Human Annotation による手動スコアの付与
Human Annotation では Trace に対して手動でスコアを付与することが可能です。
では Trace の詳細画面に移動し、スコアを手動で付与してみます。Annotate ボタンをクリックすることで、スコアの入力フォームが開かれます。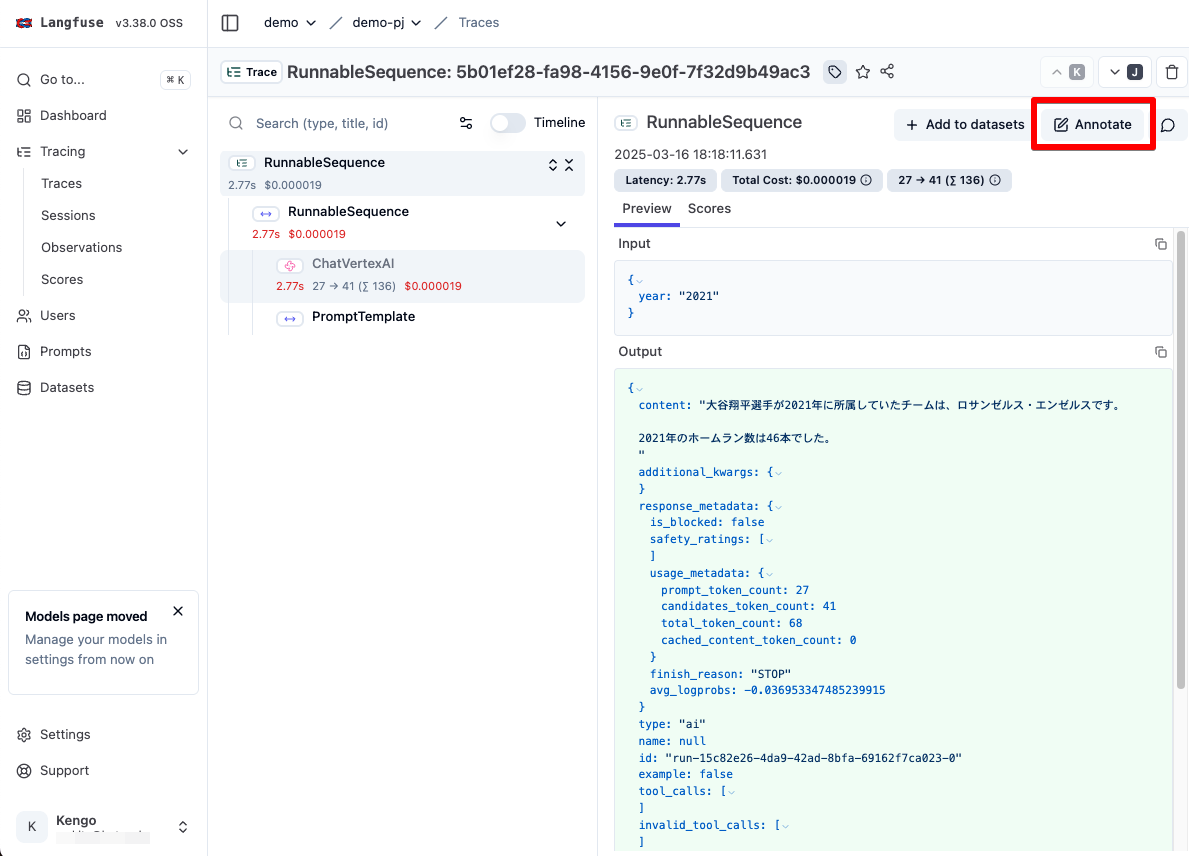
入力するスコアを選択し、値を入力します。
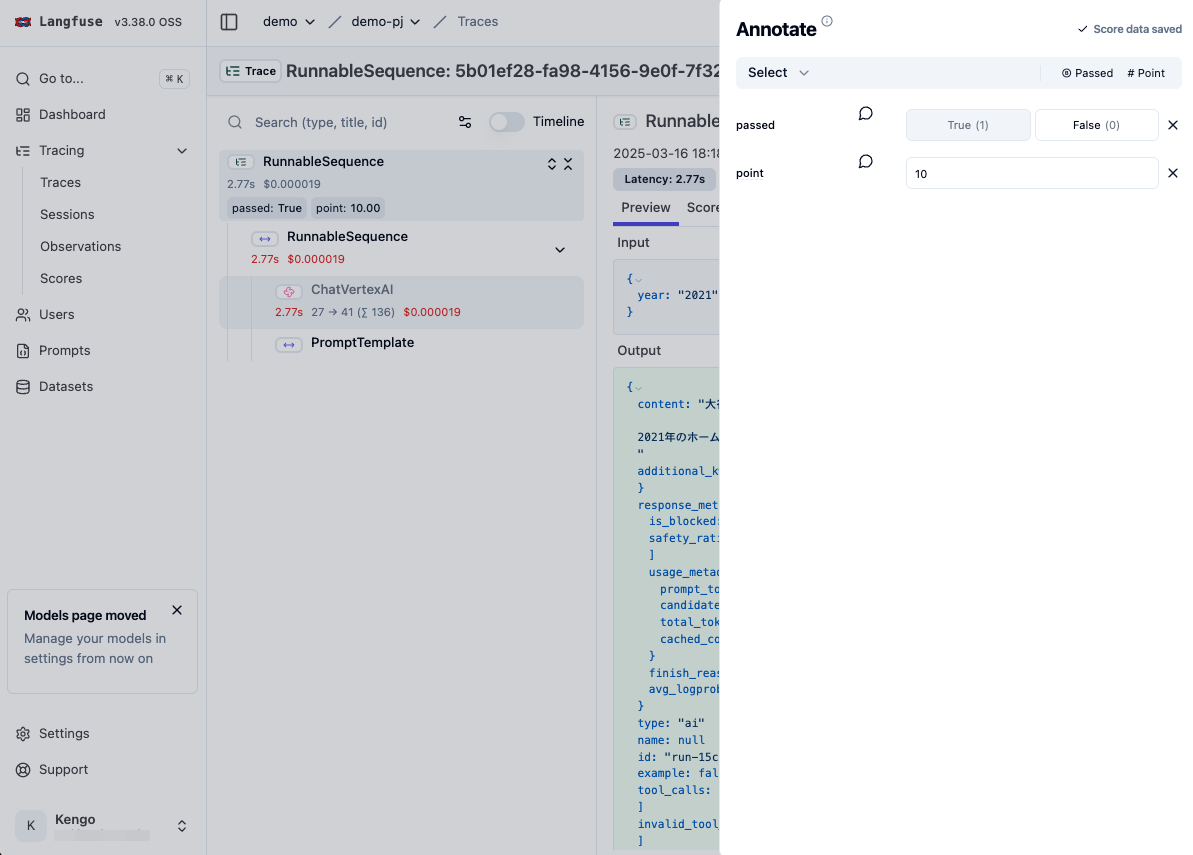
Trace 詳細画面内の Score タブをクリックすると入力されたスコアが反映されています。
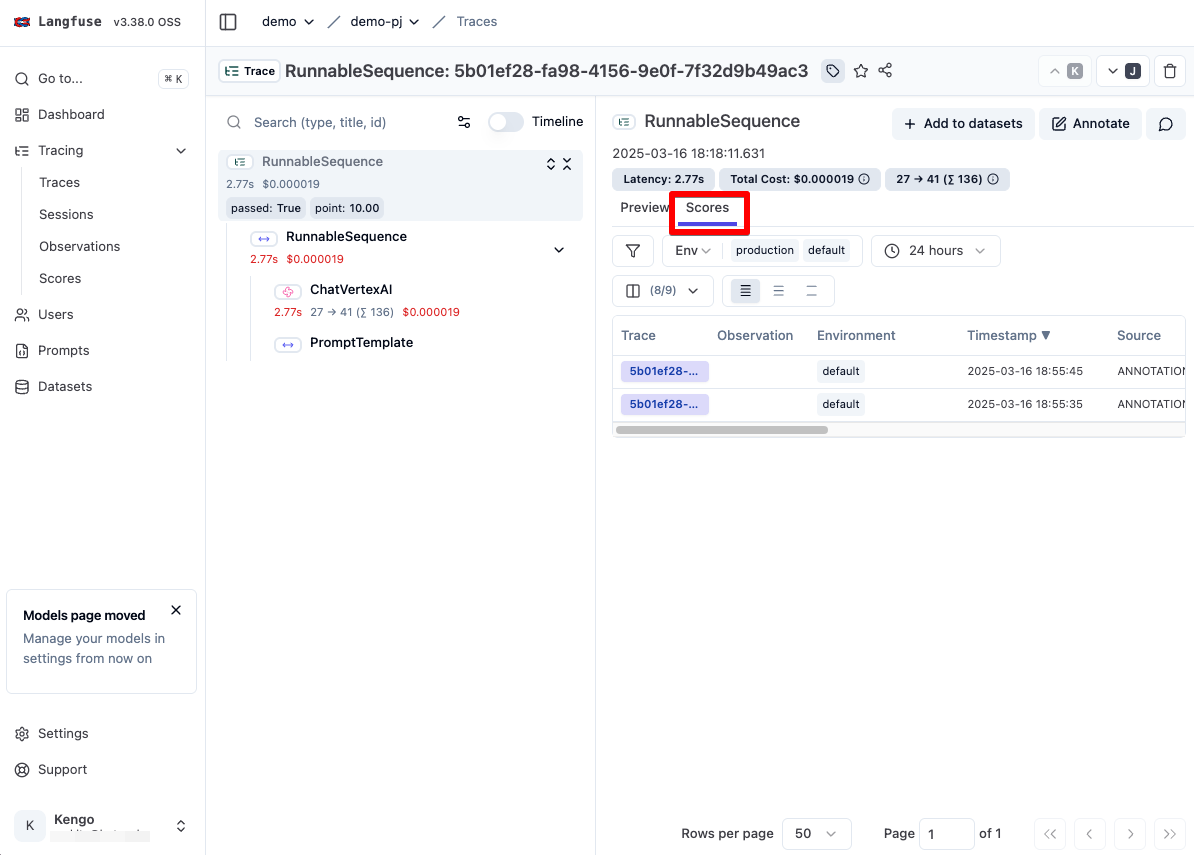
また 左メニューの Tracing -> Scores を選択すると、Trace に対するスコアが一覧表示されます。
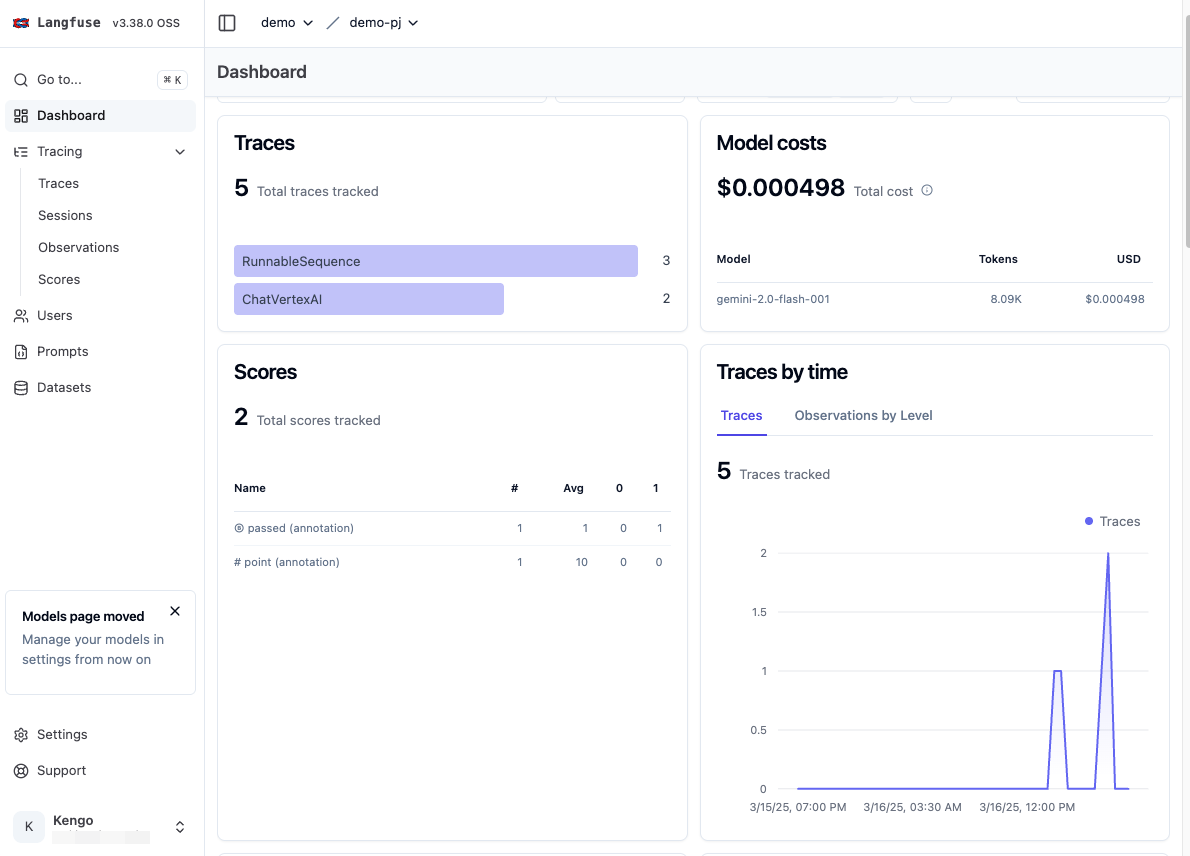
また Dashboard にはスコアが反映されていることが確認できます。
なお、Human Annotation には Annotation Queues というアノテーション対象の Trace を管理する機能があります。
これは Traceをこのキューに入れることで、アノテーションが必要な Trace をキュー管理することができるという機能です。
ですが、Annotation Queues はセルフホスト版ですと Pro ライセンスから利用できる機能ですので、詳細が知りたい方は以下のドキュメントから確認できます。
LLM-as-a-Judge による自動的なスコアリング
LLM-as-a-Judge を利用することにより、LLM により自動的にスコアを付与することができます。
ですが、Annotation Queues 同様、セルフホスト版では Pro ライセンスから利用できる機能となっています。
LLM-as-a-Judge を利用する際は、評価用の LLM を指定し、評価用テンプレートを用意する必要があります。
Langfuse により評価方式ごとの評価用プロンプトテンプレートが提供されているため、簡単に導入することができます。
詳細は以下ドキュメントから確認できます。
User Feedback による実際の利用者からの評価の収集
User Feedback では TypeScript の評価用フィードバックコンポーネントが Langfuse により提供されているため、これをアプリケーションのフロントエンドに組み込むことで、アプリケーション上から利用者による直接のスコア登録を行うことができます。
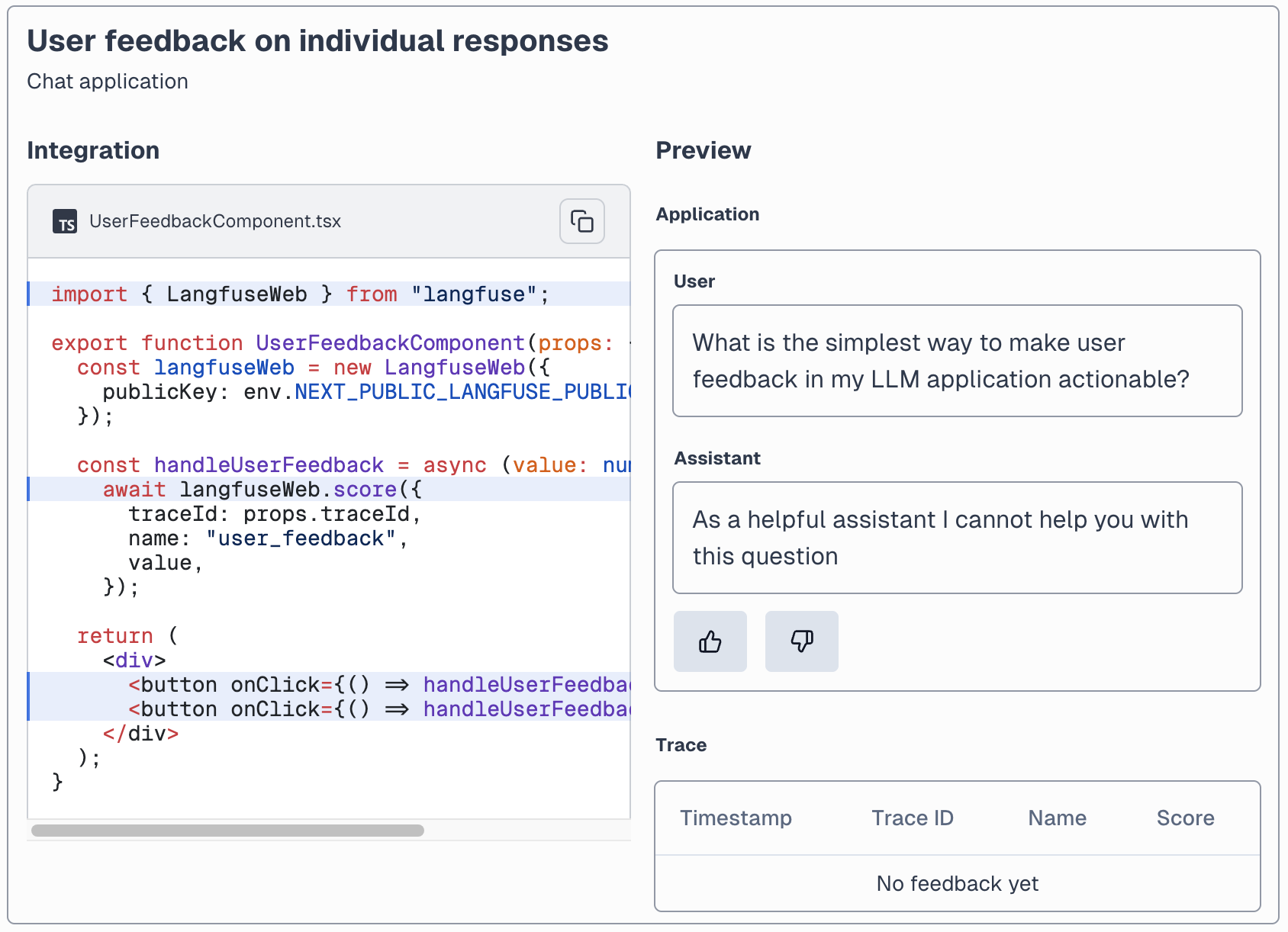
※ 画像は公式サイトより引用
詳細は以下ドキュメントをご確認ください。
機能④ : Datasets による期待される回答の追求
続いては Datasets 機能の解説となります。
Datasets では用意されたインプットトークンと期待するアウトプットトークン、およびメタデータ(オプション)のセットをアイテムとして管理します。Dataset と Item は 1 対 多の関係です。
この Datasets を用いて 複数の LLM アプリケーション を実行することにより、どのアプリケーション(プロンプト)であれば期待する結果が出力されるのかを評価することができます。
データセットの作成と実行
データセットは Langfuse UI 上からも作成できますが、繰り返し処理が発生するためここでは SDK内から作成します。
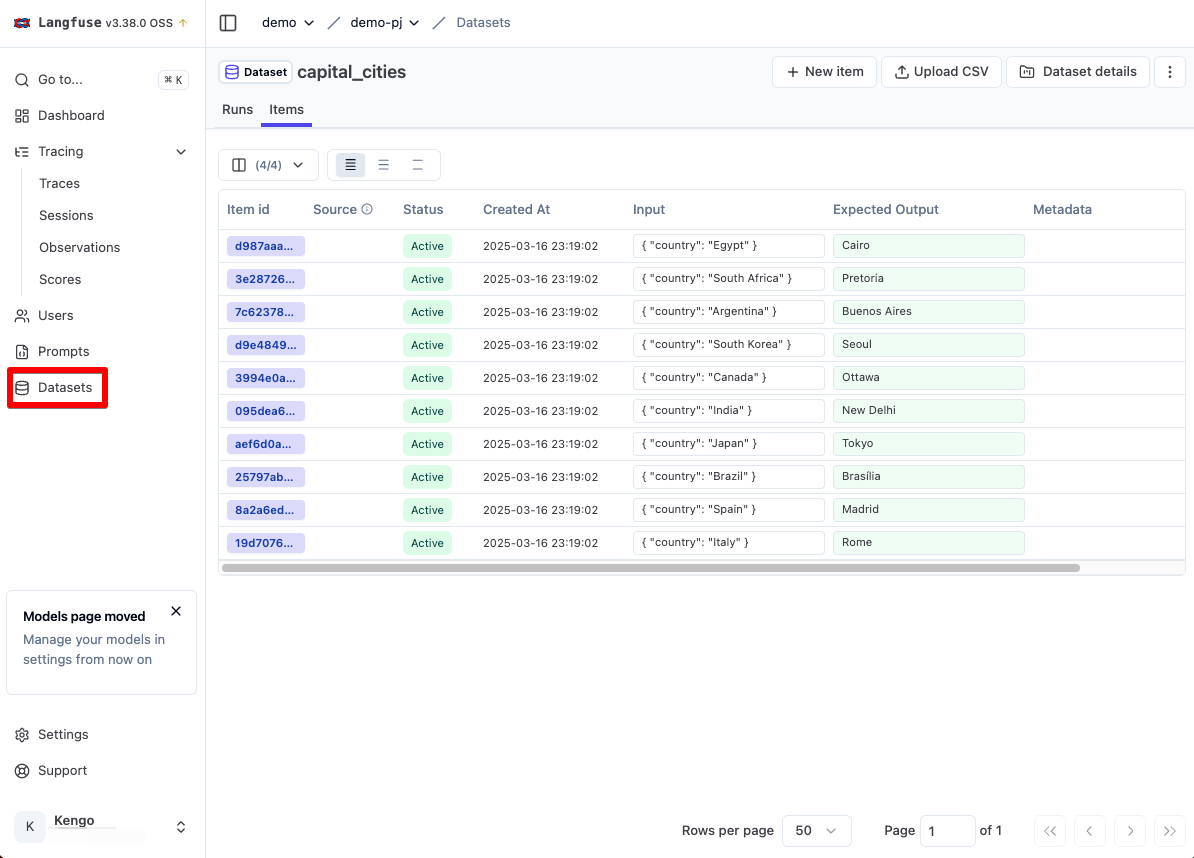
UI 上から作る場合は左メニューの Datasets から作成可能です。
以下は SDK から作成したデータセットとアイテムが表示されています。
それではデータセットとアイテムを作成して、そのデータセットをインプットとして受け取り LLM リクエストを実行する以下のファイルを datasets.py と作成します。
# Initialize Langfuse handler
import os
from langfuse import Langfuse
from langchain_google_vertexai import ChatVertexAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
# Either set the environment variable or the constructor parameter. The latter takes precedence.
os.environ["LANGFUSE_PUBLIC_KEY"] = "" # 事前に取得した Public Key に書き換え
os.environ["LANGFUSE_SECRET_KEY"] = "" # 事前に取得した Secret Key に書き換え
os.environ["LANGFUSE_HOST"] = "http://localhost:3000"
os.environ["LANGFUSE_TRACING_ENVIRONMENT"] = "develop"
# Initialize Langfuse client
langfuse = Langfuse()
# Create Dataset and Items
langfuse.create_dataset(name="capital_cities")
# example items, could also be json instead of strings
local_items = [
{"input": {"country": "Italy"}, "expected_output": "Rome"},
{"input": {"country": "Spain"}, "expected_output": "Madrid"},
{"input": {"country": "Brazil"}, "expected_output": "Brasília"},
{"input": {"country": "Japan"}, "expected_output": "Tokyo"},
{"input": {"country": "India"}, "expected_output": "New Delhi"},
{"input": {"country": "Canada"}, "expected_output": "Ottawa"},
{"input": {"country": "South Korea"}, "expected_output": "Seoul"},
{"input": {"country": "Argentina"}, "expected_output": "Buenos Aires"},
{"input": {"country": "South Africa"}, "expected_output": "Pretoria"},
{"input": {"country": "Egypt"}, "expected_output": "Cairo"},
]
# Upload to Langfuse
for item in local_items:
langfuse.create_dataset_item(
dataset_name="capital_cities",
# any python object or value
input=item["input"],
# any python object or value, optional
expected_output=item["expected_output"]
)
# we use a very simple eval here, you can use any eval library
# see https://langfuse.com/docs/scores/model-based-evals for details
# you can also use LLM-as-a-judge managed within Langfuse to evaluate the outputs
def simple_evaluation(output, expected_output):
return output == expected_output
# Your Langchain code
def run_my_langchain_llm_app(input, system_message, callback_handler):
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
system_message,
),
MessagesPlaceholder(variable_name="messages"),
]
)
chat = ChatVertexAI(model_name="gemini-2.0-flash-001", project="") # プロジェクトを自身のプロジェクト ID に書き換え
chain = prompt | chat
res = chain.invoke(
{ "messages": [HumanMessage(content=input)] },
config={"callbacks":[callback_handler]}
)
print(res.content)
return res.content
def run_langchain_experiment(experiment_name, system_message):
dataset = langfuse.get_dataset("capital_cities")
for item in dataset.items:
handler = item.get_langchain_handler(run_name=experiment_name)
completion = run_my_langchain_llm_app(item.input["country"], system_message, handler)
handler.trace.score(
name="exact_match",
value=simple_evaluation(completion, item.expected_output)
)
run_langchain_experiment(
"langchain_famous_city",
"The user will input countries, respond with the most famous city in this country"
)
run_langchain_experiment(
"langchain_directly_ask",
"What is the capital of the following country?"
)
run_langchain_experiment(
"langchain_asking_specifically",
"The user will input countries, respond with only the name of the capital"
)
run_langchain_experiment(
"langchain_asking_specifically_2nd_try",
"The user will input countries, respond with only the name of the capital. State only the name of the city."
)
これは公式が提供している LangChain のデータセット実行のサンプルコードを Gemini 用に書き換えたものです。
このサンプルコードでは期待する回答に都市名を指定し、どのプロンプトであれば期待する回答になるかを確認するデモとなっています。
ソースコードの解説としては以下の通りです。
- local_items 変数に作成するデータセットを指定します。input が入力値、expected_output が期待する回答です。
- 次にデータセットを langfuse.create_dataset_item() で作成しています。
- run_my_langchain_llm_app 関数は実際に LLM を実行する関数です。
- run_langchain_experiment 関数は langfuse.get_dataset("capital_cities") で作成したデータセットを取得し、そこからインプットを取り出して、run_my_langchain_llm_app 関数を呼び出す関数です。この際に simple_evaluation 関数を呼び出してスコアを明示的に付与しています。simple_evaluation 関数は期待する回答と実際の回答が一致しているかを判定するだけの関数です。
- run_langchain_experiment 関数でこのデータセットを用いた LLM 実行を 4 回処理しています。引数の 2 つ目がシステムメッセージとなっており、LLM 実行時はこのシステムメッセージ + データセットの input がマージされた形で実行されます。
- この システムメッセージが指定された run_langchain_experiment 関数がここでは データセットを用いた LLM を実行するアプリケーションとなります。
python datasets.py
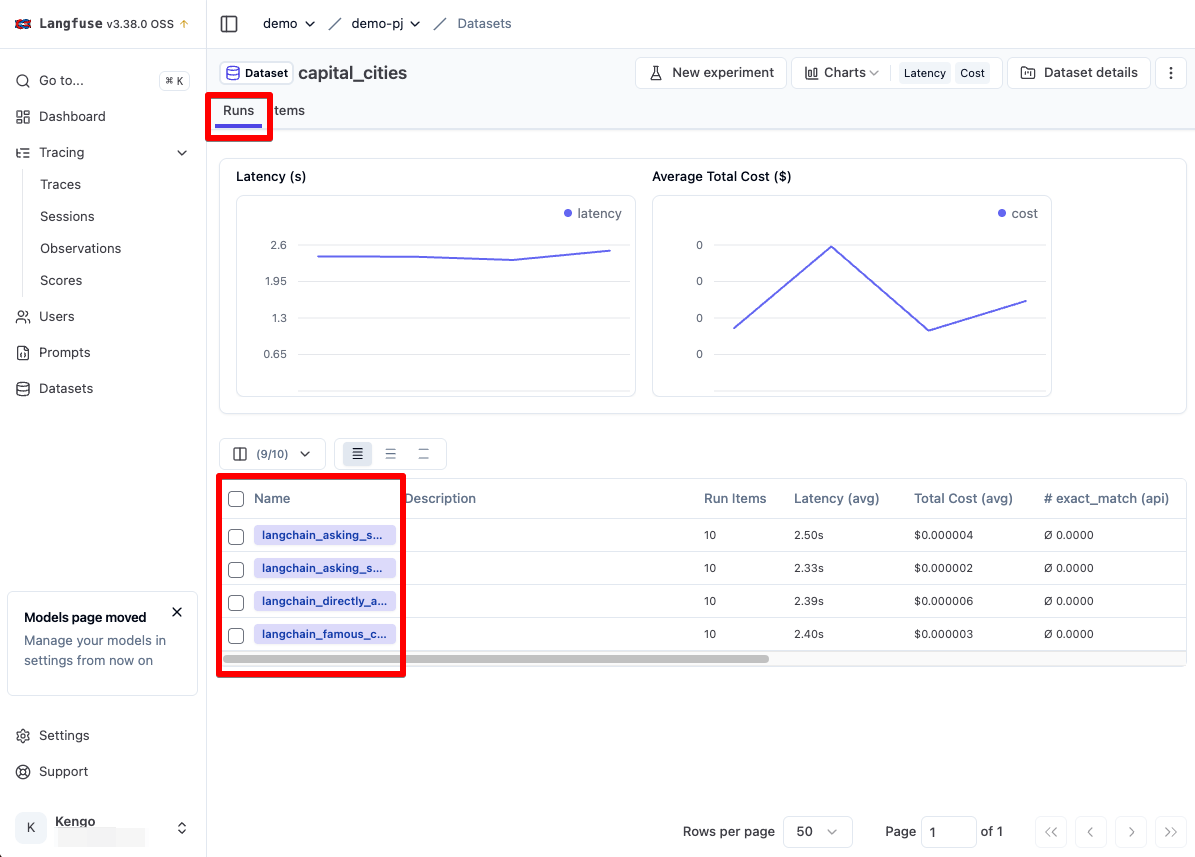
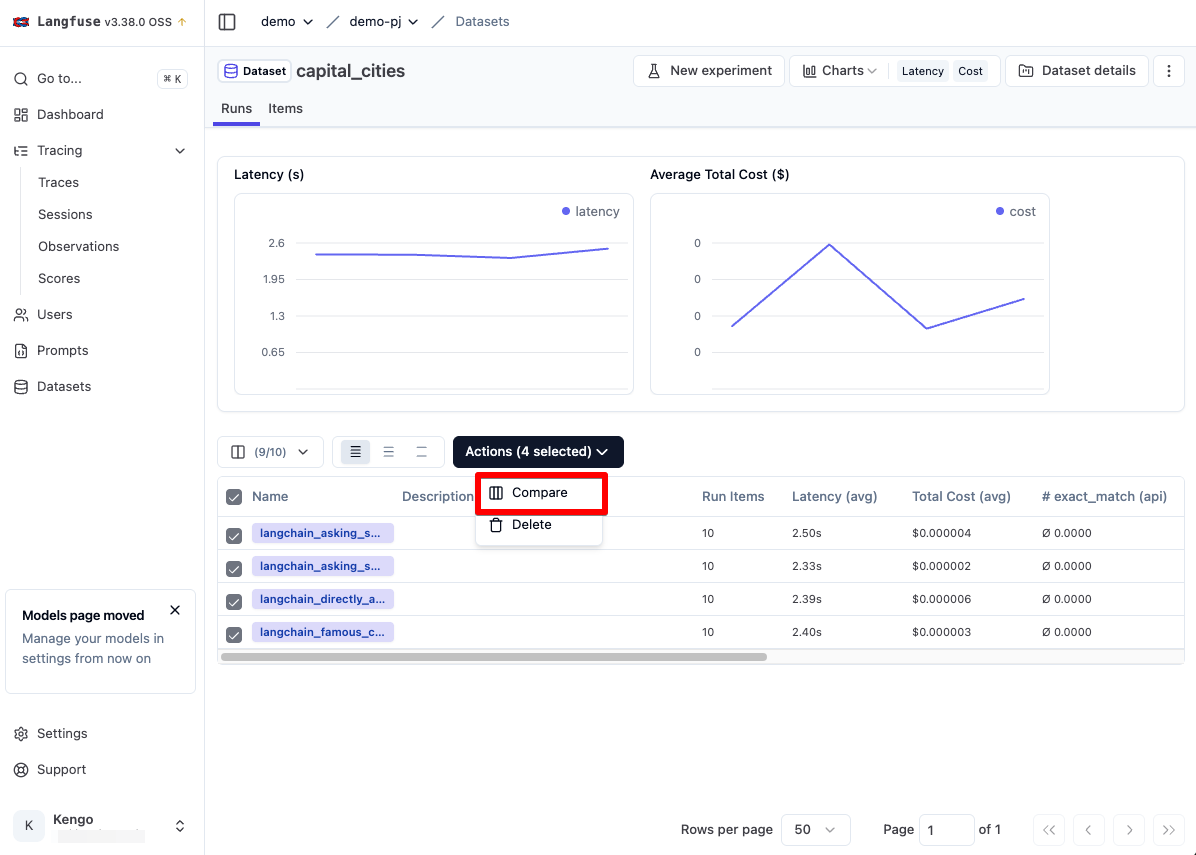
するとデータセットのインプット、期待する回答、選択した 4 つの Runs の回答結果が縦に並んだ状態で表示されます。
ただしここでバグがあり、各 Runs の結果が JSON で出力されています。(本来は JSON 内の content の中身だけが表示されるべき)
これは少し確認してみましたが、datasets.py 内で chain = prompt | chat で LangChain の Chains を作成しているのですが、それにより chain.invoke() した際のレスポンスが RunnableSequence オブジェクトになるため、その中からうまく content を取得できていないようでした。
試しに公式のサンプルコード通りに Open AI を用いて実行しても同様の結果となりました。
ただしい挙動は以下の公式動画から確認できますので、こちらを参照いただければと思います。
また Run のアウトプットが期待する回答と一致した場合は Exact_match のスコア列が先ほどの simple_evaluation 関数により 1 となります。

また Expected Output の特定の値をホバーすることで、拡大アイコンが出てくるのでそれをクリックすることで、選択したアイテムの結果を詳細に確認することができます。
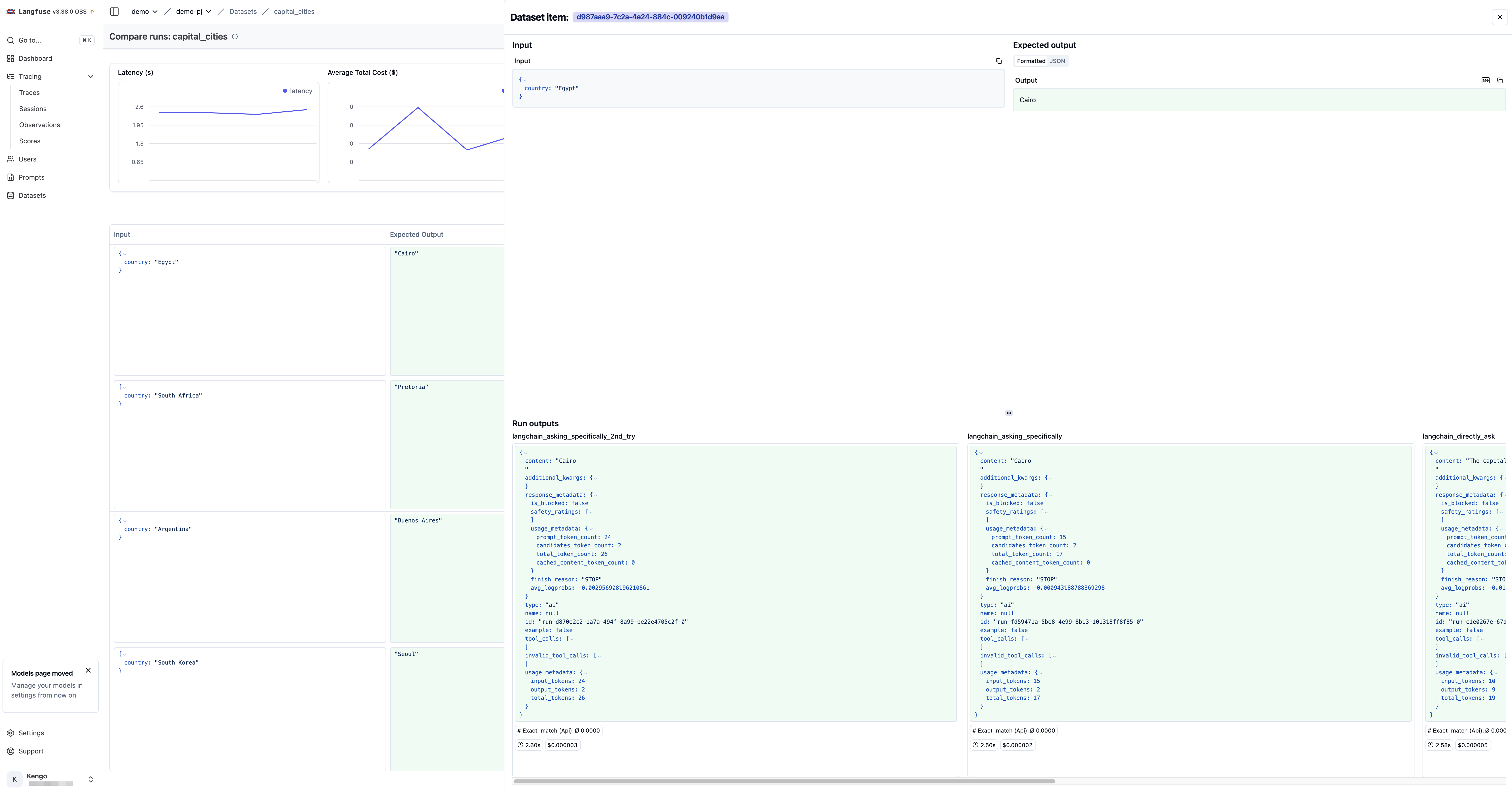
このようにデータセットでは、どのプロンプトであれば期待する回答になるかを複数で比較することができます。
また Run の比較画面ないから対象の Tarce にも遷移することができます。
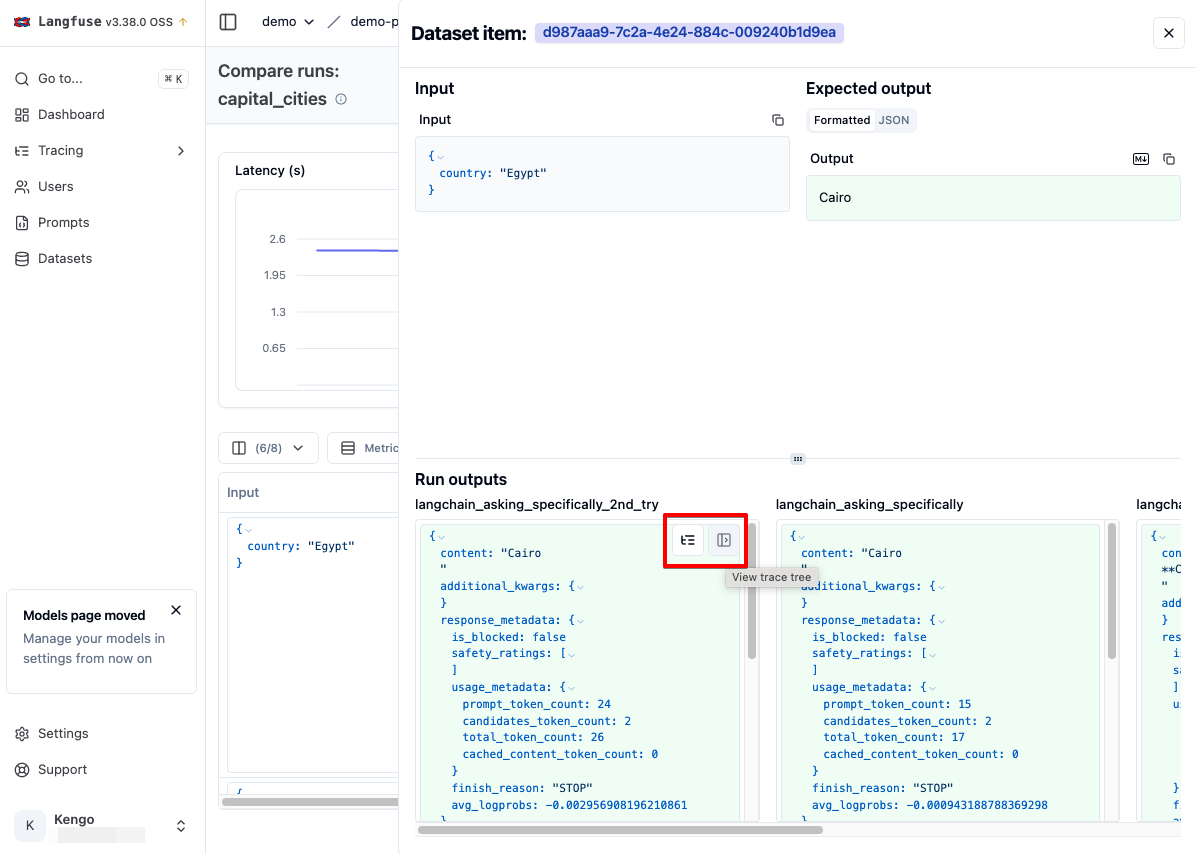
さらに Trace で収集したインプットとアウトプットをデータセットのアイテムとして追加することもできます。
Prompt Experiment による UI 上での Runs 実行
また Prompt Experiment により Runs をUI上で実行することができます。
ただし執筆時点では SaaS版のみで提供され、セルフホスト版は v3 から提供され、かつ Pro ライセンスから利用できるとのことです。
機能⑤ : LLM Playground で統合 UI による各 LLM の実行
続いては Playground 機能の解説となります。
Playground では Langfuse の UI 上で LLM へリクエストを実行することができます。また Prompt Management から直接そのプロンプトを実行できるとのことです。
こちらもセルフホスト版では Pro ライセンスから利用可能となっています。
SaaS 版を確認したところ、以下の UI となっていました。

また、利用可能なモデルは以下の通りです。
※ 公式ドキュメントから引用
- OpenAI / Azure OpenAI: gpt-4o, gpt-4o-2024-08-06, gpt-4o-2024-05-13, gpt-4o-mini, gpt-4o-mini-2024-07-18, o3-mini, o3-mini-2025-01-31, o1-preview, o1-preview-2024-09-12, o1-mini, o1-mini-2024-09-12, gpt-4-turbo-preview, gpt-4-1106-preview, gpt-4-0613, gpt-4-0125-preview, gpt-4, gpt-3.5-turbo-16k-0613, gpt-3.5-turbo-16k, gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, gpt-3.5-turbo-0301, gpt-3.5-turbo-0125, gpt-3.5-turbo
- Anthropic: claude-3-7-sonnet-20250219, claude-3-5-sonnet-20241022, claude-3-5-sonnet-20240620, claude-3-opus-20240229, claude-3-sonnet-20240229, claude-3-5-haiku-20241022, claude-3-haiku-20240307, claude-2.1, claude-2.0, claude-instant-1.2
- Google Vertex AI: gemini-2.0-flash-exp, gemini-1.5-pro, gemini-1.5-flash, gemini-1.0-pro. You may also add additional model names supported by Google Vertex AI platform and enabled in your GCP account through the `Custom model names` section in the LLM API Key creation form.
- Amazon Bedrock: All Amazon Bedrock models are supported.
- Any model that supports the OpenAI API: The Playground and LLM-as-a-Judge evaluations can be used by any framework that supports the OpenAI API schema such as Groq, OpenRouter, LiteLLM, Hugging Face, and more. Just replace the API Base URL with the appropriate endpoint for the model you want to use and add the providers API keys for authentication.
Playgroundの詳細な機能は以下の公式ドキュメントから確認できます。
機能⑥ : Comprehensive API による REST API 経由でのアクセス
最後に Comprehensive API の解説となります。
Langfuse では Comprehensive API というREST API が提供され、Trace の登録や プロンプトの取得など、Langfuse 上の機能を REST API 経由で実行することができます。
試しにセルフホスト版の /api/public/health へアクセスしてみます。
curl http://localhost:3000/api/public/health
{"status":"OK","version":"3.38.0"}
正常に起動していることが確認できますね。
なお、提供されている API は以下のページから確認することができます。
最後に
いかがでしたでしょうか。本記事で紹介したように Langfuse には LLM を快適、安全に運用するためのたくさんの機能がありますが、他にも LLM Security や Fine-tuning といった機能があり、非常多機能な製品です。
また、PostHog というテストツールと連携することで、より視覚的に Trace 情報を表示、分析することができます。
Langfuse と同様の製品に LangChain 公式の LangSmith がありますが、OSS という点でカスタマイズ性やホスティング先を自分で選択できる Langfuse は魅力的ですね。
また軽微なバグはあるものの、OSS の特性上そこは利用者でも修正できるため、より活発に利用されるとそれほど気にする必要もないかと思います。
是非みなさんも Langfuse で快適な LLM アプリケーション開発を行っていただければと思います!




