
はじめに
当該記事はラスベガスで行われている Google Cloud Next 2025 の Day2 に行われた Achieve robust business continuity on Google Cloud for mission-critical apps セッションに関する記事となります。
概要
当該セッションでは、ミッションクリティカルなアプリケーションを作成するときに、Google Cloud でのインフラ構築において、対策する内容を中心に話されていました。本記事ではその内容をレポートいたします。
セッションのステップ
セッションはミッションクリティカルの定義からはじまり、それらを達成するための様々な仕組みについて解説されておりました。
今回説明であったのは 99.999% のサービス継続性が求められるアプリケーションをミッションクリティカルなアプリケーションと定義し説明されておりました。
セッション内ではアーキテクチャパターンから運用においての試験や運用監視に至るまで、大きなボリュームの内容でした。
ミッションクリティカルなアーキテクチャ及びそれに伴う考慮事項
マルチリージョンとしてアーキテクチャとして2パターン紹介がありました。
主要な構成の考慮
プライマリリージョンとスタンバイリージョンのパターン
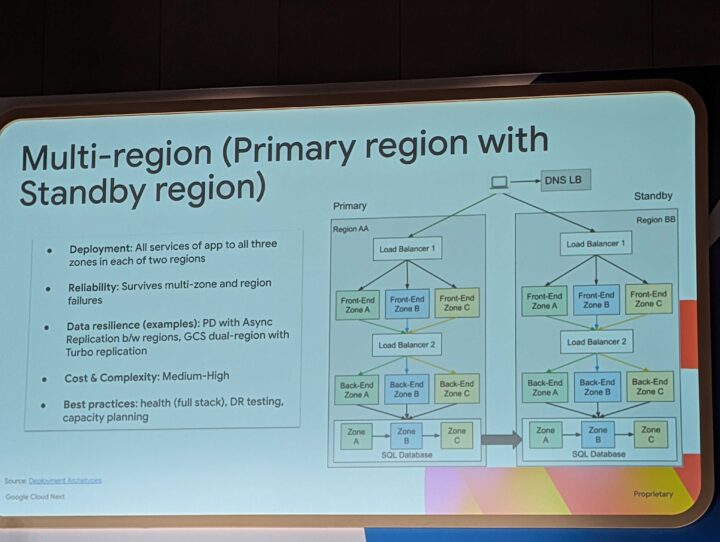
こちらのケースでは、プライマリとスタンバイになるため、障害時に切り替わるような形となり、通常時は利用されていない状態となります。
そのため、切り替わった際に、プライマリと同様な挙動ができるようにレプリケーションや両サービスへのデプロイを常に行っておく必要があります。
こちらの場合は、サービス継続制の意味で切り替えをどのように行うか、フルスタックの監視の重要性と、復旧対応としてフェイルオーバー、フェイルバック試験を繰り返し行うことの重要性が語られていました。
両プライマリリージョンパターン
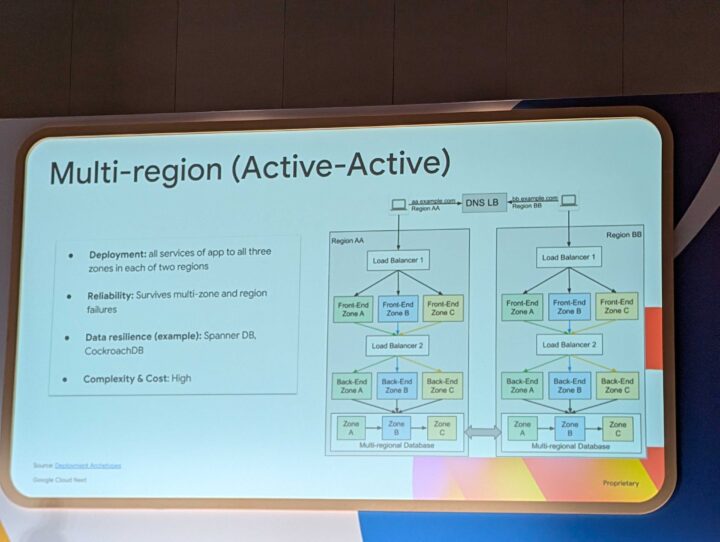
こちらのケースでは両プライマリとなるため、常にデータ同期を行うことの運用の煩雑さについて語られていました。
切り替えとしては、片リージョンへのリダイレクトを行う程度で、切り替えの容易制は高くなります。
アクティブスタンバイと比較しコストがこちらのほうが要することとなります。
その他として、アーキテクチャを組むうえでサービスの仕様上理解せねばならないことを説明されておりました。

- 利用するサービスやサービス上でのオプションによって網羅される範囲が異なることを意識する必要がある(例えば Cloud Storage と Persistent Disksで異なる)
- キャパシティプランニングとして、通常負荷、最大負荷時のスケールに伴うプランニング、サービス障害時にフェイルオーバーした場合のフェイルオーバー先のキャパシティ確保
- バックアップは最後の砦となるため、バックアップからのリストア試験を行うことの重要性を説明されており、それを行うことで戻るということだけでなく、そのプロセスを整理することが大事とのことでした
サービスを中断させずに継続させるにあたっての重要性
運用オペレーションとして、変更管理、テスト、インシデント検出及び対応、という対応の重要性について説明されていました。

障害試験
復旧に対する意識欠如を防ぎあらかじめ手順を固めておくことで、いつ障害があってもいいような準備を整え、重要なシーンで活用可能にすることが重要とのことでした。
- 非常に重要であり、本番環境前に問題を捉えるべきであると話しされており、リリース前段階での問題検知に対する重要性を挙げられておりました。それによる、遅延やサービス停止など、想定可能な範囲は非常に多くあるためかと思います。
- 変更管理
- ロールアウトは一気にやるものではなく、必要箇所を段階的におこなうべきであると強調されておりました。
- 監視(インシデント検出)
上記の内容もリリースにあたり監視は不可欠かと思いますが、日々の運用監視及び障害検知のアクションの重要かと考えております。

バックアップ
セッションでは単純なバックアップの取得に対する言及ではなく、すでに出ている内容ですが、リストアや復旧に対するリハーサルの重要性を話しておりました、
事例紹介
Charles Schwab 社の事例として、ミッションクリティカルな内容を Cloud 移行するところでの内容を中心に話いただきました。
事例内ではアーキテクチャのお話や、準備段階では、多層防御、セキュリティ対策、安全なロールアウト、スケーラビリティ、可観測性、インシデント対応 などに重点を置いたことが説明されました。
その中で得られた教訓として語られていたのが、安全なロールアウトの重要性です。
安全なロールアウト
ブルーグリーンデプロイメントを紹介されており、迅速なロールバックも行え、段階的なロールアウトが可能なことを示されておりました。
また、ABテストも一部のフリートで利用されており、こちらについても段階的に安全なロールアウトが重要であり、リリースされた機能に対するパフォーマンスや反応を比較し、安定性を評価されておりました。
これらは全体的にロールアウトされるのではなく、一部へのロールアウトを行い、リスク低減をはかりながら、段階的にリリースしていくことの重要性を強調されているように見受けられました。
まとめ
内容としてはアーキテクチャの実装例として、参考になるものであるのと同時に、要件定義を行ううえで、意識すべきことが盛り込まれており勉強になりました。また、オペレーションテスト、リストアテストなど当たり前のことですが、それを当たり前にやることの大事さを改めて感じました。
弊社の場合、インフラ、開発と連動するようなケースも多く、お互いに踏み込んで、こういった試験の内容や、オペレーションのテストを行うことで、いざってときの担保を行いながら、お客様及びユーザーに対して、自信をもったベストなサービス提供が行えると感じ、このセッションについては忘れてはならないものだと感じました。
新しいサービスばかりに目を向けるのではなく、Google Cloud を活用するにあたって、こういった部分も抑えていきたいと思います。




