
はじめに
この記事はGoogle Cloud Next 2025で公開されたセッション「Adapt Gemini Code Assist: Tailor code recommendations to your needs」についてのセッションメモです。誤りなどがありましたら随時、修正していく予定です。
本セッションを理解するために必要な知識をおさらい
本セッションの内容を深く理解するために、重要と考えられる知識を順番に挙げます。
1.AIコーディング支援ツールの基本的な理解:
- GitHub CopilotやAmazon CodeWhisperer、そして本題のGemini Code Assistなどが、どのような機能(コード補完、生成、チャット等)を提供し、開発者がどのように利用するものなのか、基本的な概念を知っていること。
- 重要性: セッション全体のテーマであり、これが無いと他の話の前提が理解できません。特に、既存ツールの「限界」を理解していると、カスタマイズ機能の価値がより明確になります。
2.基本的なソフトウェア開発ワークフローと課題の認識:
- 内容: ソースコード管理(Git、リポジトリ)、コーディング規約、API利用、ライブラリ/フレームワーク、テスト、デプロイといった一連の開発プロセスと、その中で発生しうる非効率(コードの不統一、内部情報の参照不足、オンボーディングの困難さ等)を理解していること。
- 重要性: なぜ「プロジェクト固有の文脈」が重要なのか、カスタマイズ機能が解決しようとしている具体的な開発現場のペインポイントを理解するために不可欠です。
3.生成AI / 大規模言語モデル(LLM)の基本概念:
- 内容: AIがどのようにテキストやコードを「生成」するのか、プロンプトやコンテキストがどのように影響するのか、といった大枠の仕組みを知っていること。
- 重要性: Gemini Code Assistがどのように動作するかの基礎となります。「文脈(コンテキスト)が重要」という点が腑に落ちやすくなります。
4.RAG(Retrieval-Augmented Generation / 検索拡張生成)の概念:
- 内容: AIが回答を生成する際に、外部の知識ソース(この場合はインデックス化されたプライベートコード)を参照して、より正確で根拠のある出力をする仕組みである、という概念を理解していること。(技術的な詳細までは不要)
- 重要性: コードカスタマイズ機能の核心技術であり、なぜプライベートコードを学習させると精度が上がるのかを理解する鍵となります。
5.AIとデータプライバシーに関する一般的な関心:
- 内容: 企業の機密情報やコードをAIサービスに連携する際の、セキュリティやプライバシーに関する一般的な懸念(情報漏洩、意図しない学習利用など)を認識していること。
- 重要性: セッション内で強調されていたプライバシー保護策(Googleのモデル学習に使わない、顧客管理の暗号鍵サポート等)の重要性を理解するために必要です。
上記に加えて、DORAレポートがDevOpsのパフォーマンス指標として知られていることや、ベクトルデータベース、Google Cloud (AlloyDB, CMEK) に関する知識があれば、さらに深い理解に繋がります。
セッションの内容を要約するとつまり
セッション全体の内容を5つの箇条書きで要約します。
1.課題と解決策
汎用的なAIコーディング支援は、DORAレポートでも指摘される課題(開発者の信頼性欠如、ソフトウェア安定性低下など)を持つ。Gemini Code Assistの「コードカスタマイズ」機能は、プロジェクト固有のプライベートコードをRAG(検索拡張生成)技術で学習し、文脈に合った支援を提供することで、これらの課題を解決する。
2.仕組みとプライバシー
顧客のコードリポジトリ(GitLab, Bitbucket等)を、Google Cloudプロジェクト内のGoogle管理下にある専用AlloyDBにインデックス化する。この顧客データはGoogleのベースモデル学習には決して使用されず、顧客はいつでもデータを削除可能で、CMEK(顧客管理の暗号鍵)もサポートされるなど、データプライバシーと管理が保証されている。
3.主なメリット
チームのコーディング規約やスタイルに準拠した提案により「コード品質と一貫性」が向上し、関連性の高いコード生成や補完によって「開発者の生産性」が大幅に向上する。これにより、DORAで示されたAI導入のリスクを軽減できる。
4.実践的な活用とデモ
デモでは、カスタマイズによってプロジェクト固有のデプロイスクリプトの特定や内部APIを利用したコード生成が正確に行えることが示された。
効果的な活用のためには、適切なコードのインデックス化、.aiignoreによる除外設定、プロンプトへのコンテキスト付与といったベストプラクティスが重要となる。
5.Q&Aと将来展望
質疑応答では、インデックス対象ブランチの選択が可能であることや、データ削除権限が顧客にあることなどが確認された。
将来的には、コードだけでなく設計ドキュメントなども連携させ、より深いコンテキスト理解に基づいた支援を目指している。
セッションの内容(本編)
問題提起
本セッションで語られたことはスライドの通り。

AIによるコーディング支援ツールは、私たちの開発ワークフローに革命をもたらしました。
しかし、「便利だけど、ちょっと惜しい…」と感じる瞬間はありませんか?
生成されたコードがプロジェクトの規約に合わなかったり、内部ライブラリを考慮してくれなかったり、結局手直しに時間がかかってしまったり。。。
Google Cloudの Gemini Code Assist は、この課題に対する強力な答えを持っています。
それが「コードカスタマイズ」機能です。これは、Geminiを単なる汎用AIアシスタントから、あなたのプロジェクトとチームの専属アシスタントへと進化させる機能です。
本セッションでは、Gemini Code Assistのコードカスタマイズがどのように機能し、どのようなメリットがあり
そしてその能力を最大限に引き出すためのベストプラクティスについて解説されました。
なぜ「カスタマイズ」が必要なのか? DORAの調査(Insights)が示すAI支援の課題
AIコーディング支援は大きな可能性を秘めていますが、その導入は常に順風満帆とは限りません。
DORA (DevOps Research and Assessment) の調査によれば、生成AIツールの活用は、時に開発プロセスに新たな課題をもたらす可能性が指摘されています。
実際に「DORA 2024 Insights」では、AIツールによる67%の生産性向上が期待される一方で
開発者の39%がAI生成コードを信頼しておらず、ソフトウェアの安定性が7%低下した、という具体的な調査結果が示されています。
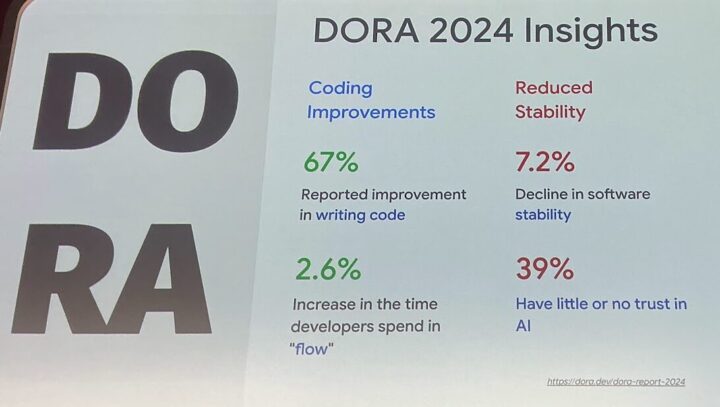
これは、プロジェクト固有の文脈を理解しない汎用的なAI支援がDORAが懸念する以下のようなリスクに繋がりかねないことを明確に示しています。
- 提案の手直しに時間がかかる (結果的に作業負荷が増加)
- コードベース全体の一貫性が損なわれる (コード品質の低下)
- 社内のベストプラクティスや共通ライブラリが軽視される (内部ナレッジの形骸化)
- 新しいメンバーがプロジェクトの“お作法”を学ぶのが難しい
- 生産性向上のつもりが、逆にレビュー負荷が増える
これらのリスクは、「作業負荷の増加」、「コード品質・安定性の低下」、そして「社内ベストプラクティスの浸食」といった、ソフトウェア開発パフォーマンスへの具体的な悪影響に繋がりかねません。AIの力を最大限に引き出すには、これらの課題に対処する必要があります。
解決策: あなたのコードを理解する Gemini Code Assist カスタマイズ

Gemini Code Assistのコードカスタマイズは、RAG (Retrieval-Augmented Generation / 検索拡張生成) という技術を用いて、これらの問題を解決します。
仕組みの概要:
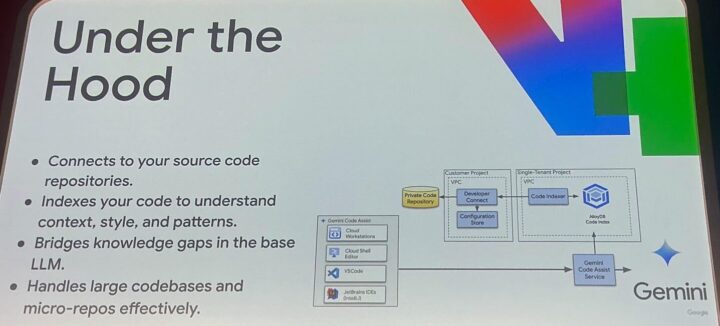
1.接続: あなたが管理するプライベートなコードリポジトリ(Cloud Source Repositories、 GitLab、 Bitbucketなど、クラウド/オンプレミス問わず)に接続します。
2.インデックス作成: リポジトリ内のコードを読み取り、その意味や構造をベクトル情報としてGoogle Cloudプロジェクト内に作成される、Googleが完全に管理する専用のAlloyDBインスタンスにインデックス化します。
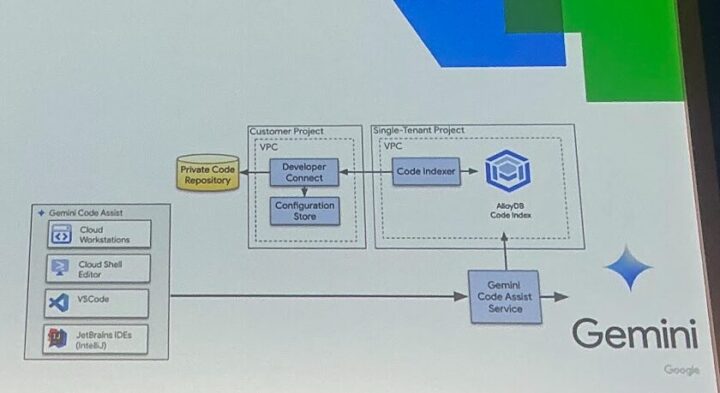
※重要: このインデックス化されたコードは、Googleの汎用モデルのトレーニングには使用されません。データはあなたの管理下にあり、いつでも削除可能です。プライバシーは保護されます。
3.コンテキストに基づいた提案: あなたがコーディングやチャットを行う際、Geminiは一般的な知識に加えて、インデックス化されたあなたのコードベース固有の知識を参照し、より文脈に合った、的確な提案を行います。
カスタマイズがもたらすメリット: DORAの課題を克服
この機能により、チームはDORAの調査で明らかになったようなAI導入の懸念点(信頼性の欠如や安定性への影響など)を克服し、AIの真の価値を引き出すことができます。
1.ソフトウェア品質の向上:
- チームのコーディング規約やスタイルに一貫性が生まれる。
- 社内ライブラリや共通コンポーネントの利用が促進される。
- 既存の信頼できるコードパターンに基づいた提案により、コードの堅牢性・保守性が向上する (DORAで示された安定性の低下リスクに対抗)。
- コードレビューが容易になる。
2.開発者生産性の向上:
- プロジェクトに即した的確なコード補完・生成により、“手直し”の時間を削減 (DORAで示された信頼性の低いコード生成による作業負荷増に対抗)。
- ボイラープレートコードの記述から解放される。
- 新しいメンバーも、プロジェクト固有のコードを参考にしながら素早くキャッチアップできる。
- 開発者は、より創造的で本質的なタスクに集中できる。
これらは、DORAレポートが示すような、効果的な技術導入によるソフトウェアデリバリーパフォーマンスの向上に直結するメリットです。
効果を最大化する!コードカスタマイズ ベストプラクティス

せっかくのカスタマイズ機能も、使い方次第で効果が変わってきます。
ベストプラクティスを参考に、以下の点を意識してみましょう。
- 関連性の高いコードをインデックスする:
- 現在アクティブに開発・メンテナンスされているリポジトリやブランチを選びましょう。
- チームの最新のコーディング規約やベストプラクティスを反映したコードを中心にインデックスさせることが理想です。
- .aiignore を活用する:
- ドキュメント、テストデータ、生成ファイル、古いコード、実験的なコードなど、AIに参照させたくないファイルやディレクトリは、.gitignore と同様の構文で .aiignore ファイルに記述し、インデックス対象から除外しましょう。
- 良いコーディング習慣はAIのためにも:
- 分かりやすい変数名、関数名、明確な型定義などは、人間のためだけでなく、AIがコードの意図を正確に理解するためにも役立ちます。コードの可読性を高める努力は続けましょう。
- プロンプトにコンテキストを与える:
- 特にチャットで質問やコード生成を依頼する際は、関連する import 文や、手本としたい既存のコードスニペットを例として含めると、AIの理解度が深まり、より精度の高い応答が期待できます。
- 機能の使い分けを意識する:
- チャット: 新しい機能の設計相談、複雑なロジックの生成、リファクタリング方針の検討、エラーの原因調査など、広いコンテキストや説明が必要な場合に有効です。
- コード補完/生成: チャットで得た方針に基づいた具体的な実装、定型的なコードの記述、既存コードの修正などに活用しましょう。
- 諦めずにプロンプトを調整する:
- AIの応答は常に完璧ではありません。期待通りでなければ、質問の仕方や指示内容を変えて、何度か試してみましょう。
- チャットをもっと活用しよう:
- 単なるコード生成以外にも、チャットは強力なツールです。コードの説明、ドキュメントの要約(将来的にはドキュメント連携も強化予定)、代替実装の検討、デバッグのヒントなど、様々な用途で活用できます。
重要なポイント

- Geminiがあなたあるいは組織のコードに適合していること
- RAGを活用すること
- AIの課題を克服すること
セッションQ&Aハイライト:気になるポイント
セッションの最後に行われた質疑応答では、参加者から多くの実践的な質問が寄せられました。主なポイントをまとめます。
Q.データプライバシーと管理:
Answer
顧客のコードがGoogleのベースモデル学習に使われることは絶対にありません。インデックスデータは顧客自身のGoogle Cloudプロジェクト内に作成されるGoogle管理のAlloyDBインスタンスに保存され、顧客はいつでもそのデータを削除できます。CMEK(顧客管理の暗号鍵)もサポートされています。
Q.インデックス対象とコード品質:
Answer
現時点では、選択されたリポジトリやブランチに含まれるコードがインデックス化されます。.aiignoreファイルで不要なコンテンツを除外できます。将来的には、コードの品質や利用頻度などを考慮したインデックスの改善も検討されています。
Q.コード以外の情報ソース
Answer
現在はコードが中心ですが、ドキュメントとの連携が次の重要な機能拡張として予定されています。将来的にはチャット履歴や仕様書など、他の情報ソースとの連携も視野に入れ、開発者がより豊かなコンテキストをシームレスに利用できることを目指しています。
Q.ブランチの選択
Answer
インデックスを作成する対象のブランチは、設定時に選択可能です。開発中のブランチを指定することもできます。
主な利用シーン
特に大規模なコードベースのリファクタリングや、既存のパターンに基づいたテストコードの生成などで効果を発揮するという声がありました。
他のAIツールとの違い: Gemini Code Assistは、Geminiモデル(特に大規模なコンテキストウィンドウを持つモデル)の能力、内部での複数の特化モデルの連携、そしてこの強力なプライベートコードカスタマイズ機能が大きな強みであると説明されました。
まとめ
Gemini Code Assistのコードカスタマイズ機能は、AIコーディング支援を次のレベルへと引き上げます。
あなたのチーム固有の知識をGeminiに学習させることで、開発プロセスにおける摩擦を減らし、DORAの調査(Insights)で示されたようなAI導入の課題(信頼性や安定性への懸念など)を乗り越え、その真価を発揮させる鍵となります。
データプライバシーにも配慮され、管理はGoogleに任せられるため、安心して導入を進めることができます。ぜひ、これらのベストプラクティスやQ&Aで得られた知見を参考に、Gemini Code Assistをあなたのチームにとって最高の「専属アシスタント」に育ててみてください。
感想
本セッションはGemini Code Assistの使い方や仕組みを深く知るためのセッションと言えるものでした。とくにGoogle管理のAlloyDBにインデックスが作成されているというところは知らなかったため、勉強になりました。
セッション会場においては自分が参加した中でも質疑応答が一番に多く、とても活発でした。(時間が足りない)
また、この記事には細かく書いていませんが、他のAIツールについても質問として述べられており、参加者には専門家が多い印象を受けました。(あるいはヘビーユーザと呼べそうな人)
セッションの内容をもとに今後に向けて検証を進めていけたらと考えていますが、
DORAのレポートはまだ読んでいないため、読みながら進めたいと思います。
ここも読んでおきたい
- Highlights from the 10th DORA report
- Google Cloud公式ブログによる見解




