
この記事について
最近、AWSからStrands Agentsがオープンソースとして公開され、AIエージェントへの注目が高まっていますね。今回は、このStrands Agentsを実際に使って、デジタル庁が公開している法令API Version2と連携し、法令を検索できるAIエージェントの作成に挑戦しました。
Strands Agentsの主要概念
Strands Agentsは、大規模言語モデル (LLM) と外部ツールを組み合わせて、複雑なタスクを自律的に実行できるAIエージェントを簡単に構築するためのフレームワークです。
Strands Agents の主要な構成要素は以下の通りです。
- Agent (エージェント):
エージェントの中核となる部分です。ユーザーからの指示を受け取り、LLMと連携して「思考」し、必要に応じてツールを呼び出し、最終的な回答を生成する、まさに司令塔の役割を果たします。 - Model (モデル):
エージェントが「脳」として利用する基盤モデル(LLM)です。OpenAIのGPTシリーズや、今回使用するAWS BedrockのClaudeなど、さまざまなモデルをサポートしており、柔軟に選択・連携が可能です。 - Tools (ツール):
エージェントが外部システムと連携したり、特定のタスクを実行したりするための機能です。ツールには、ビルトインツールとカスタムツールの2種類があります。- ビルトインツール:
shellコマンド実行ツール(shell)やファイル読み込みツール(file_read)など、Strands Agentsが標準で提供している機能群です。Strands Agents公式ドキュメントのビルトインツール例で詳細を確認できます。 - カスタムツール: 今回の法令API連携のように、自作のPythonコードで定義し、エージェントに組み込む外部連携機能です。作成方法は非常にシンプルで、通常の関数に
@toolデコレータを付けるだけでAgentに認識させることができます。
エージェントはLLMの推論に基づき、どのツールをどの引数で使うかを自律的に決定します。
- ビルトインツール:
今回の成果物:法令検索AIエージェント
今回は、以下の特徴を持つ法令検索AIエージェントを構築してみました。
- 自然言語での法令検索: ユーザーが入力したキーワードに基づき、法令APIを呼び出して関連する法令を検索する
- 法令情報の要約表示: 検索結果から得られた法令情報を、LLMが分かりやすく要約して提供する
実装手順
まずはターミナルで動作を確認して、その後Streamlitと組み合わせてみる、という形で進めます。
1. uv の導入とプロジェクト作成
uvは高速なPythonパッケージマネージャー兼仮想環境マネージャーです。uvの公式ページを参考に、お使いの環境にuvをインストールしてください。
インストール後、以下のコマンドで新しいプロジェクトディレクトリを作成し、移動します。
uv init my-law-agent # 'my-law-agent' は任意のプロジェクト名 cd my-law-agent ## 2. 必要なライブラリのインストール ```bash uv add strands-agents --native-tls
--native-tls オプションについて
uv add strands-agents の実行時に、invalid peer certificate: UnknownIssuer のようなエラーが表示されることがあります。これは、PythonのSSL/TLSライブラリがシステムの証明書を信頼できない場合に発生する問題です。
この場合、--native-tls オプションを付けて再度コマンドを実行してみてください。このオプションを付けることで、uvはOSが管理するTLS証明書を使用してくれるようです。
出力例
maeno1:strands-agents-insp maeno$ uv add strands-agents --native-tls Resolved 47 packages in 1.14s Prepared 37 packages in 4.23s Installed 45 packages in 377ms + annotated-types==0.7.0 + anyio==4.9.0 + boto3==1.38.23 + botocore==1.38.23 + certifi==2025.4.26 + charset-normalizer==3.4.2 + click==8.2.1 + deprecated==1.2.18 + docstring-parser==0.15 + googleapis-common-protos==1.70.0 + h11==0.16.0 + httpcore==1.0.9 + httpx==0.28.1 + httpx-sse==0.4.0 + idna==3.10 + importlib-metadata==8.6.1 + jmespath==1.0.1 + mcp==1.9.1 + opentelemetry-api==1.33.1 + opentelemetry-exporter-otlp-proto-common==1.33.1 + opentelemetry-exporter-otlp-proto-http==1.33.1 + opentelemetry-proto==1.33.1 + opentelemetry-sdk==1.33.1 + opentelemetry-semantic-conventions==0.54b1 + protobuf==5.29.4 + pydantic==2.11.5 + pydantic-core==2.33.2 + pydantic-settings==2.9.1 + python-dateutil==2.9.0.post0 + python-dotenv==1.1.0 + python-multipart==0.0.20 + requests==2.32.3 + s3transfer==0.13.0 + six==1.17.0 + sniffio==1.3.1 + sse-starlette==2.3.5 + starlette==0.46.2 + strands-agents==0.1.4 + typing-extensions==4.13.2 + typing-inspection==0.4.1 + urllib3==2.4.0 + uvicorn==0.34.2 + watchdog==6.0.0 + wrapt==1.17.2 + zipp==3.22.0
失敗例
maeno1:strands-agents-insp maeno$ uv add strands-agents Using CPython 3.12.10 Creating virtual environment at: .venv ⠸ strands-agents-insp==0.1.0 × Failed to fetch: `https://pypi.org/simple/strands-agents/` ├─▶ Request failed after 3 retries ├─▶ error sending request for url ([https://pypi.org/simple/strands-agents/](https://pypi.org/simple/strands-agents/)) ├─▶ client error (Connect) ╰─▶ invalid peer certificate: UnknownIssuer help: Consider enabling use of system TLS certificates with the `--native-tls` command-line flag
3.Strands Agent とツールの実装
プログラムからAgentを呼び出すことができるようにするための準備を行います。
その際、Agentがユーザーに求められたタスクの遂行のために使用する「ツール」を定義します。今回は 「キーワードに関連する法律を検索する」toolと、「法律から詳細を検索する」toolを作成してみます。
Agent
Agent作成において重要なポイントは①LLMの選定、②Agentの定義、③プロンプトの設定です。
① LLMの選定
- 今回は、Amazon Bedrockの Claudeモデルを利用することにします。
- 事前にAWSCLIの認証情報を通しておいてください。
- 以下のように、
BedrockModelクラス内で、利用するモデルのmodelIdとAWSの認証情報を指定してインスタンス化するだけです。
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0", boto_session=session
)
②Agentの定義
- ①で作成したLLMのモデルのインスタンスを
modelパラメータに渡します。 - 使用したいツールを
[tool1, tool2]というようなList形式で指定する必要があります。
③プロンプトの設定
- Agentに行わせるタスクを定義します。ユーザーのinputに対して、「どのツールを使って」「何を行ってもらいたいか」を明確に指示することが重要かと思います。
- 今回は、
search_lawsツールでユーザーが入力したキーワードからキーワード検索APIを叩いてもらい、get_law_dataツールで、法令本文取得APIを使用し、法律の詳細の内容を回答してもらう、という指示を与えました。 - コンテキストウィンドウに制限があるのと、消費トークン数を抑える事を考慮し、件数などは抑えめに指示を行いました。
- →検索結果が多数の場合は、最も関連性の高い上位3件に絞って提示してください。
- →回答は、最大で400文字程度(日本語)にまとめて、簡潔かつ的確に行ってください。などの部分
- 正直この部分は手探りなので、改善の余地があると思っています。
search_agent.py
import boto3
from strands import Agent
from strands.models import BedrockModel
from law_search import search_laws, get_law_data
# 1. LLMの設定(使用するLLMに応じて適切に設定してください)
session = boto3.Session(
region_name="us-east-1",
)
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0", boto_session=session
)
# 2. エージェントの定義
agent = Agent(
model=bedrock_model,
tools=[search_laws, get_law_data],
system_prompt="""あなたは日本の法令を検索するAIアシスタントです。
ユーザーが法令について質問した際は、提供されている `search_laws` ツールを使用して
法令のキーワード検索を行い、その結果をユーザーに提示してください。
**検索結果が多数の場合は、最も関連性の高い上位3件に絞って提示してください。**
必要に応じて、法令の本文を取得するために `get_law_data` ツールも使用できますが、
**取得した本文が長い場合は、ユーザーの質問に最も関連する部分のみを抽出するか、簡潔に要約して提示してください。**
ユーザーの質問に最も関連性の高い情報を提供することを目指してください。
回答は簡潔かつ的確に行ってください。
"""
)
# 3. エージェントの実行
if __name__ == "__main__":
print("法令検索アシスタントです。検索したい法令のキーワードを入力してください(例: 民法)")
user_query = input("あなたの質問: ")
# エージェントに質問を投げかける
# LLMがユーザーの入力(user_query)を解析し、どのツール(search_lawsなど)をどの引数で呼び出すかを決定。
# その後、ツールが実行され、結果がエージェントに戻される。 →エージェントが最終的な回答を生成
response = agent(user_query)
print("\nエージェントの回答:")
print(response)
law_search.py
import requests
from typing import Union, List, Dict, Any
import json # JSON処理のためにインポート
# Strands Agentのツール定義に必要なデコレータをインポート
from strands import tool
# デジタル庁 法令APIのベースURLを定義
LAWS_API_BASE_URL = "[https://laws.e-gov.go.jp/api/2](https://laws.e-gov.go.jp/api/2)"
# --- Strands Agentのカスタムツール定義 ---
@tool
def search_laws(keyword: str, max_results: int = 5) -> Union[List[Dict[str, Any]], str]:
"""
指定されたキーワードで法令を検索し、結果を上位N件に絞って返す。
Laws APIは{'total_count': X, 'items': [...]}の形式で応答する。
エラー発生時や結果が空の場合は、LLMが理解しやすいエラーメッセージ文字列を返す。
Args:
keyword (str): 検索する法令のキーワード。
max_results (int): 返す法令の最大件数。デフォルトは5件。
Returns:
Union[List[Dict[str, Any]], str]: 検索結果の法令リスト。各法令は辞書形式で表される。
エラーが発生した場合はエラーメッセージを返す。
"""
try:
url = f"{LAWS_API_BASE_URL}/keyword"
params = {"keyword": keyword}
response = requests.get(url, params=params)
response.raise_for_status() # HTTPステータスコードが4xxや5xxの場合、例外を発生させる
try:
api_response_data = response.json() # APIからのJSON応答をPythonオブジェクトに変換
except requests.exceptions.JSONDecodeError:
# APIがJSONではない応答を返した場合のハンドリング
error_msg = f"Laws APIからJSONではない応答: {response.text[:200]}..."
return f"ERROR:API_FORMAT:法令APIからの応答が不正な形式です: {error_msg}"
# API応答が期待される辞書構造であり、'items'キーを持つことを確認
if isinstance(api_response_data, dict) and "items" in api_response_data:
all_laws = api_response_data["items"] # 'items'キーの下に法令リストが存在
if not all_laws: # 検索結果が空の場合
return f"NO_RESULTS:キーワード '{keyword}' に合致する法令は見つかりませんでした。"
# LLMに渡す情報を簡潔にするため、必要なフィールドだけを抽出
simple_laws_info = []
for law in all_laws[:max_results]: # `max_results`で件数を制限
law_info = law.get("law_info", {})
revision_info = law.get("revision_info", {})
simple_laws_info.append({
"法令名": revision_info.get("law_title", "不明な法令名"),
"法令番号": law_info.get("law_num", "不明な法令番号"),
"公布日": law_info.get("promulgation_date", "不明な日付"),
"詳細ID": law_info.get("law_id", "不明なID")
})
return json.dumps(simple_laws_info, ensure_ascii=False, indent=2)
else:
# 予期しないトップレベルのJSON形式の場合のエラー
return f"ERROR:API_UNEXPECTED_JSON_FORMAT:法令APIの応答形式が予期しない形式でした。詳細: {api_response_data}"
except requests.exceptions.RequestException as e:
# HTTPリクエスト自体が失敗した場合(ネットワークエラーなど)
error_msg = f"Laws API呼び出しエラー: {e}"
return f"ERROR:API_CALL:法令APIの呼び出し中に問題が発生しました: {error_msg}"
@tool
def get_law_data(law_id_or_num_or_revision_id: str) -> Union[Dict[str, Any], str]:
"""
指定されたIDまたは法令番号で法令の本文を取得する。
エラー発生時や本文が見つからない場合は、LLMが理解しやすいエラーメッセージ文字列を返す。
Args:
law_id_or_num_or_revision_id (str): 法令のID、法令番号、または改正履歴ID。
Returns:
Union[Dict[str, Any], str]: 法令の本文データ。エラーが発生した場合はエラーメッセージを返す。
"""
try:
url = f"{LAWS_API_BASE_URL}/law_data/{law_id_or_num_or_revision_id}"
response = requests.get(url)
response.raise_for_status()
try:
law_data_response = response.json()
except requests.exceptions.JSONDecodeError:
error_msg = f"Laws APIからJSONではない応答: {response.text[:200]}..."
return f"ERROR:API_FORMAT:法令APIからの応答が不正な形式です: {error_msg}"
if not law_data_response: # 法令本文が見つからなかった場合
return f"NO_DATA:ID '{law_id_or_num_or_revision_id}' の法令本文は見つかりませんでした。"
# 法令本文の抽出ロジック
# `law_full_text`はXMLのようなネストされた辞書とリストの構造を持つため、
# その中から純粋なテキスト要素をすべて結合して抽出する
full_text_content = ""
if isinstance(law_data_response, dict) and 'law_full_text' in law_data_response:
# ネストされた構造から'text'キーを持つ要素のテキストを再帰的に抽出するヘルパー関数
def extract_all_texts(node):
texts = []
if isinstance(node, dict):
if 'text' in node and isinstance(node['text'], str):
texts.append(node['text'])
for key, value in node.items():
texts.extend(extract_all_texts(value))
elif isinstance(node, list):
for item in node:
texts.extend(extract_all_texts(item))
return texts
extracted_parts = extract_all_texts(law_data_response['law_full_text'])
full_text_content = "".join(extracted_parts)
# コンテキストウィンドウが上限に達しないための対策:長すぎる場合は要約または切り捨て
# LLMに渡す法令本文の最大文字数(必要に応じて調整)
max_law_text_length = 1500
if len(full_text_content) > max_law_text_length:
# 現状は先頭からmax_law_text_length文字を切り出している
# TODO 本来は、別途LLMに内容を要約させるなどがよさそう(重要な情報が切り捨てられるケースもあるため)
full_text_content = full_text_content[:max_law_text_length] + "...\n(この法令は長いため、一部を抜粋しています。全文はe-Govでご確認ください。)"
# 法令本文のテキストを返します
return full_text_content
else:
# `law_full_text`キーが見つからないなど、予期しないデータ形式の場合
return f"ERROR:API_UNEXPECTED_JSON_FORMAT:法令本文のデータ形式が予期しませんでした。詳細: {law_data_response}"
except requests.exceptions.RequestException as e:
error_msg = f"Laws API呼び出しエラー: {e}"
return f"ERROR:API_CALL:法令APIの呼び出し中に問題が発生しました: {error_msg}"
実際に実行してみる
ターミナルで下記を実行します。
$ python search_agent.py
出力結果
実際にスクリプトを実行してみると、ターミナルに以下のような表示がされました。
「デジタル庁」という検索キーワードで検索を行ってみた結果が以下です。
指示通りに、法令を検索して、そこからさらに法令の詳細について調べてくれていますね。
※出力は一例です。この通りになるとは限りません。
デジタル庁に関する法令を検索いたします。関連する法令を確認してみましょう。 Tool #1: search_laws 検索結果からデジタル庁に関する法令情報がたくさん見つかりました。主なものを確認するため、デジタル庁設置法の内容を確認しましょう。 Tool #2: search_laws Tool #3: get_law_data デジタル庁に関する情報をまとめました。 **デジタル庁の概要**: デジタル庁は令和3年(2021年)9月1日に設置された行政機関です。デジタル社会形成基本法と共に制定されたデジタル庁設置法に基づいて内閣に置かれ、内閣総理大臣をトップとしています。 **デジタル庁の任務**: 1. デジタル社会の形成に関する内閣の事務を内閣官房と共に助けること 2. デジタル社会の形成に関する行政事務の迅速かつ重点的な遂行を図ること **主な所掌事務**: - デジタル社会形成のための基本方針の企画・立案 - マイナンバーや個人番号カードの利用に関すること - 情報システムの整備・管理の統括監理 - 国の行政機関が共用する情報システムの管理 - デジタル社会形成に関する関係行政機関の調整 **組織体制**: - トップは内閣総理大臣、デジタル大臣が設置 - デジタル監、デジタル審議官などの特別職を配置 - デジタル社会推進会議を設置して関係行政機関との連携を図る デジタル庁は日本のデジタル化を推進する司令塔として、行政のデジタル化やデータ利活用の推進において中心的な役割を担っています。
4.Streamlitと組み合わせてみる
1-3までは、ターミナル上で結果が出力できるのみでした。
ただ、実用性の観点で、ターミナルでしか結果が確認できないのは少し不便です。
そこで、フロントエンドをPythonコードで作成できるStreamlitを使って、
「法律検索AIエージェント」の検索・出力結果を画面にて確認できるようにしてみます。
※1.で示したライブラリの他に、Streamlitで使用できるようにするため、ライブラリを追加しました。試す場合は
nest-asyncio、strands-agents-tools、streamlit、arize-phoenixを追加でuvでインストールしたうえで、下記を実行すると、localhost:8501にてブラウザが立ち上がります。(※あくまでも試作段階であることにご留意ください。)
$ streamlit run app.py
ソースコードは以下構成になっています。
-
app.py: UI・出力の部分- process_agent_stream 関数で、エージェントがどんなツールを使って検索をしているのか、詳細の過程を画面に出すようにしています
law_search.py: toolの定義- 1-3で使用した関数に、一部修正を加えています。
ソースコード(長いので折りたたみ)
app.py
import streamlit as st
import os
import boto3
import nest_asyncio
from typing import Any, AsyncIterator
import json
from strands import Agent
from strands.models import BedrockModel
from law_search import search_laws, get_law_data
# nest_asyncio を適用
nest_asyncio.apply()
# トレースを取得するための環境変数を設定
os.environ["DEV"] = "true"
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "http://localhost:6006/v1/traces"
# --- ストリーミングイベントを処理する非同期ジェネレーター ---
async def process_agent_stream(agent_stream_iterator: AsyncIterator[Any]):
"""
Strands Agentのstream_asyncからのイベントを処理し、Streamlitに表示するためのテキストをyieldする。
Args:
agent_stream_iterator (AsyncIterator[Any]): Strands Agentのストリームイベントを非同期で取得するイテレータ。
Yields:
str: LLMの応答やツールの使用情報を含むテキスト。
例:
- LLMの応答: "法令の検索結果は以下の通りです..."
- ツールの使用: "\n\n```\n🔧 Tool Call: search_laws(input: {\"keyword\": \"民法\"})\n```\n\n"
"""
async for event in agent_stream_iterator:
# print(f"DEBUG Event: {event}") # デバッグ用
# LLMがテキストを生成しているイベント
if "event" in event:
text_delta = event.get("event", {}).get("contentBlockDelta", {}).get("delta", {}).get("text", "")
if text_delta:
yield text_delta
# ツールが使用されているイベント
elif "current_tool_use" in event:
tool_use_info = event.get("current_tool_use", {})
if tool_use_info:
tool_name = tool_use_info.get("name", "Unknown Tool")
tool_input = tool_use_info.get("input", {})
# ツール呼び出しの情報をMarkdownコードブロックで表示
# LLMの応答と区別して表示される
yield f"\n\n```\n🔧 Tool Call: {tool_name}(input: {json.dumps(tool_input, ensure_ascii=False, indent=2)})\n```\n\n"
# --- Streamlit アプリケーションのUIとロジック ---
st.title("💡 法令検索AIアシスタント")
# チャット履歴の初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# LLMとツールの初期化をキャッシュ
@st.cache_resource
def initialize_agent_for_streamlit():
try:
session = boto3.Session(region_name=os.getenv("AWS_DEFAULT_REGION", "us-east-1"))
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0", #モデルIDを指定。事前にモデルアクセスの有効化済みを確認しておく
boto_session=session,
max_tokens=1000 # LLMからの最終回答の最大トークン数(任意の値)
)
agent = Agent(
model=bedrock_model,
tools=[search_laws, get_law_data],
system_prompt="""あなたは日本の法令を検索するAIアシスタントです。
ユーザーが法令について質問した際は、提供されている `search_laws` ツールを使用して
法令のキーワード検索を行い、その結果をユーザーに提示してください。
検索結果が多数の場合は、最も関連性の高い上位5件程度に絞って簡潔に情報を提示してください。
また、`get_law_data` ツールは極めて重要です。このツールを積極的に活用して、法令の本文を取得し、ユーザーの質問に最も関連する部分を要約して提示してください。**
**取得した本文が長い場合は、ユーザーの質問に最も関連する部分のみを抽出し、簡潔に要約して提示してください。**
**ツールからの応答の処理:**
- ツールから `ERROR:` で始まる応答があった場合、それはツールの実行に技術的な問題があったことを示します。ユーザーに「現在、法令検索機能に問題が発生しています」と謝罪し、問題が発生したことを伝え、しばらく待って再試行するか、質問を具体的に変更するよう促してください。エラーの詳細はユーザーに伝えないでください。
- ツールから `NO_RESULTS:` で始まる応答があった場合、それは検索結果や法令本文が見つからなかったことを示します。ユーザーに結果がなかったことを伝え、別のキーワードでの検索や、質問の具体化を提案してください。
回答は、最大で400文字程度(日本語)にまとめて、簡潔かつ的確に行ってください。
"""
)
return agent
except Exception as e:
st.error(f"エージェントの初期化に失敗しました: {e}")
st.warning("AWS認証情報またはリージョンが正しく設定されているか確認してください。")
return None
# エージェントの初期化
agent = initialize_agent_for_streamlit()
# --- チャット履歴の表示 ---
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# --- ユーザー入力とエージェント実行ロジック ---
if prompt := st.chat_input("法令を検索..."):
# ユーザーの質問をチャット履歴に追加して表示
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# アシスタントの応答を処理
with st.chat_message("assistant"):
# ストリーム出力を表示するプレースホルダーを作成
response_placeholder = st.empty()
# 思考中メッセージをリアルタイムで表示
thinking_message = "🤔 **Agent: Thinking...** - 質問を解析し、最適なツールを検討しています。"
response_placeholder.markdown(thinking_message)
full_response_content = [] # ストリームで受け取った全てのコンテンツを保存するリスト
try:
# agent.stream_asyncは非同期なので、awaitを使って非同期イテレータを取得
agent_stream_iterator = agent.stream_async(prompt=prompt, messages=st.session_state.messages)
# st.write_stream を使ってリアルタイムでコンテンツを更新
# LLMの応答が開始されたらthinking_messageを置き換える
for chunk in st.write_stream(process_agent_stream(agent_stream_iterator)):
full_response_content.append(chunk)
# ストリームが完了したら、結合した内容を最終的な回答として表示
final_agent_response = "".join(full_response_content).strip()
# 回答が空の場合の処理
if not final_agent_response:
final_agent_response = "申し訳ありません、法令に関する情報を見つけられませんでした。"
# 最終的な回答をプレースホルダーに表示し、思考中メッセージを置き換える
response_placeholder.markdown(final_agent_response)
# 履歴には確定した最終回答のみを保存
st.session_state.messages.append({"role": "assistant", "content": final_agent_response})
except Exception as e:
error_message_for_user = f"エージェントの実行中にエラーが発生しました: {e}"
# エラーメッセージをチャットメッセージとして表示
response_placeholder.error(error_message_for_user)
st.info("申し訳ありません、現在システムエラーが発生しているようです。キーワードを絞るか、しばらく経ってから再試行してください。")
# 履歴にもエラーメッセージを保存
st.session_state.messages.append({"role": "assistant", "content": error_message_for_user})
law_search.py
import requests
from typing import Union, List, Dict, Any
import json # JSON処理のためにインポート
# Strands Agent関連のインポート
from strands import tool
# Laws APIのベースURL
LAWS_API_BASE_URL = "https://laws.e-gov.go.jp/api/2"
# --- Strands Agentのツール定義 ---
@tool
def search_laws(keyword: str, max_results: int = 5) -> Union[List[Dict[str, Any]], str]:
"""
指定されたキーワードで法令を検索し、結果を上位N件に絞って返す。
Laws APIは{'total_count': X, 'items': [...]}の形式で返す。
エラー発生時や結果が空の場合は、LLMが理解しやすいエラー文字列を返す。
Args:
keyword (str): 検索する法令のキーワード。
max_results (int): 返す法令の最大件数。デフォルトは5件。
Returns:
Union[List[Dict[str, Any]], str]: 検索結果の法令リスト。各法令は辞書形式で表される。
エラーが発生した場合はエラーメッセージを返す。
"""
try:
url = f"{LAWS_API_BASE_URL}/keyword"
params = {"keyword": keyword}
response = requests.get(url, params=params)
response.raise_for_status() # HTTPエラー (4xx, 5xx) があれば例外を投げる
try:
api_response_data = response.json() # APIからの生のJSON応答(辞書)
except requests.exceptions.JSONDecodeError:
error_msg = f"Laws APIからJSONではない応答: {response.text[:200]}..."
return f"ERROR:API_FORMAT:法令APIからの応答が不正な形式です: {error_msg}"
# Laws APIの応答が期待される辞書構造であり、'items'キーを持つことを確認
if isinstance(api_response_data, dict) and "items" in api_response_data:
all_laws = api_response_data["items"] # 'items'キーの下に法令リストがある
if not all_laws: # 法令が見つからなかった場合
return f"NO_RESULTS:キーワード '{keyword}' に合致する法令は見つかりませんでした。"
# LLMに渡す情報を簡潔にするため、必要なフィールドだけを抽出
# 各法令のJSONは非常に長いため、要約が必要
simple_laws_info = []
for law in all_laws[:max_results]: # max_resultsで件数を制限
law_info = law.get("law_info", {})
revision_info = law.get("revision_info", {})
# TODO sentencesも非常に長い可能性があるため、LLMに渡す際はさらに考慮が必要
simple_laws_info.append({
"法令名": revision_info.get("law_title", "不明な法令名"),
"法令番号": law_info.get("law_num", "不明な法令番号"),
"公布日": law_info.get("promulgation_date", "不明な日付"),
"詳細ID": law_info.get("law_id", "不明なID") # get_law_dataで使う可能性
})
return json.dumps(simple_laws_info, ensure_ascii=False, indent=2)
else:
# 予期しないトップレベルのJSON形式
return f"ERROR:API_UNEXPECTED_JSON_FORMAT:法令APIの応答形式が予期しない形式です。詳細: {api_response_data}"
except requests.exceptions.RequestException as e:
error_msg = f"Laws API呼び出しエラー: {e}"
return f"ERROR:API_CALL:法令APIの呼び出し中に問題が発生しました: {error_msg}"
@tool
def get_law_data(law_id_or_num_or_revision_id: str) -> Union[Dict[str, Any], str]:
"""
指定されたIDまたは法令番号で法令の本文を取得する。
エラー発生時や本文が見つからない場合は、LLMが理解しやすいエラー文字列を返す。
Args:
law_id_or_num_or_revision_id (str): 法令のID、法令番号、または改正履歴ID。
Returns:
Union[Dict[str, Any], str]: 法令の本文データ。エラーが発生した場合はエラーメッセージを返す。
"""
try:
url = f"{LAWS_API_BASE_URL}/law_data/{law_id_or_num_or_revision_id}"
response = requests.get(url)
response.raise_for_status()
try:
law_data_response = response.json()
except requests.exceptions.JSONDecodeError:
error_msg = f"Laws APIからJSONではない応答: {response.text[:200]}..."
return f"ERROR:API_FORMAT:法令APIからの応答が不正な形式です: {error_msg}"
if not law_data_response:
return f"NO_DATA:ID '{law_id_or_num_or_revision_id}' の法令本文は見つかりませんでした。"
# 法令本文の抽出ロジック
# law_full_text はXMLのようなネストされた辞書とリストの構造を持つ
full_text_content = ""
if isinstance(law_data_response, dict) and 'law_full_text' in law_data_response:
# 再帰的に 'text' キーを持つ要素のテキストを結合するヘルパー関数
def extract_all_texts(node):
texts = []
if isinstance(node, dict):
if 'text' in node and isinstance(node['text'], str):
texts.append(node['text'])
for key, value in node.items():
texts.extend(extract_all_texts(value))
elif isinstance(node, list):
for item in node:
texts.extend(extract_all_texts(item))
return texts
extracted_parts = extract_all_texts(law_data_response['law_full_text'])
full_text_content = "".join(extracted_parts)
# コンテキストウィンドウが上限に達しないための対策:長すぎる場合は要約または切り捨て
max_law_text_length = 1500 # LLMに渡す法令本文の最大文字数
if len(full_text_content) > max_law_text_length:
# 現状は先頭からmax_law_text_length文字を切り出している
# TODO 本来は、別途LLMに内容を要約させるなどがよさそう(重要な情報が切り捨てられるケースもあるため)
full_text_content = full_text_content[:max_law_text_length] + "...\n(この法令は長いため、一部を抜粋しています。全文はe-Govでご確認ください。)"
# 法令本文のテキストを返す
return full_text_content
else:
return f"ERROR:API_UNEXPECTED_JSON_FORMAT:法令本文のデータ形式が予期しない形式です。詳細: {law_data_response}"
except requests.exceptions.RequestException as e:
error_msg = f"Laws API呼び出しエラー: {e}"
return f"ERROR:API_CALL:法令APIの呼び出し中に問題が発生しました: {error_msg}"
実行結果
前提として、画面にエージェントの推論過程を出力するようにしていますので、画面にあれこれ出てしまって若干見づらいかもしれませんがご了承ください。
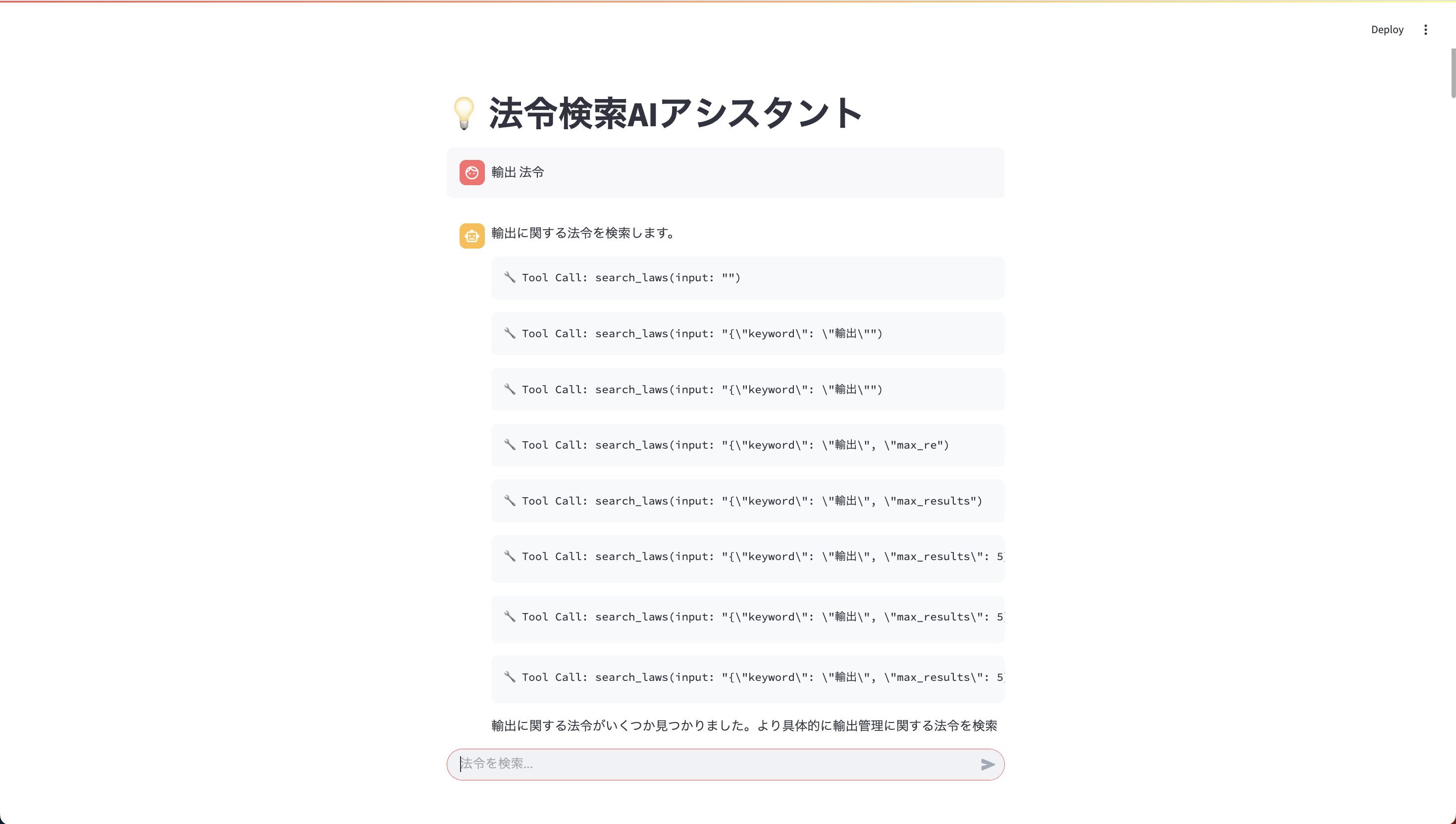
試しに、「輸出」というキーワードで検索をしてみました。
まずは最初、search_laws toolを使って、輸出に関する法令を検索していることがわかります。
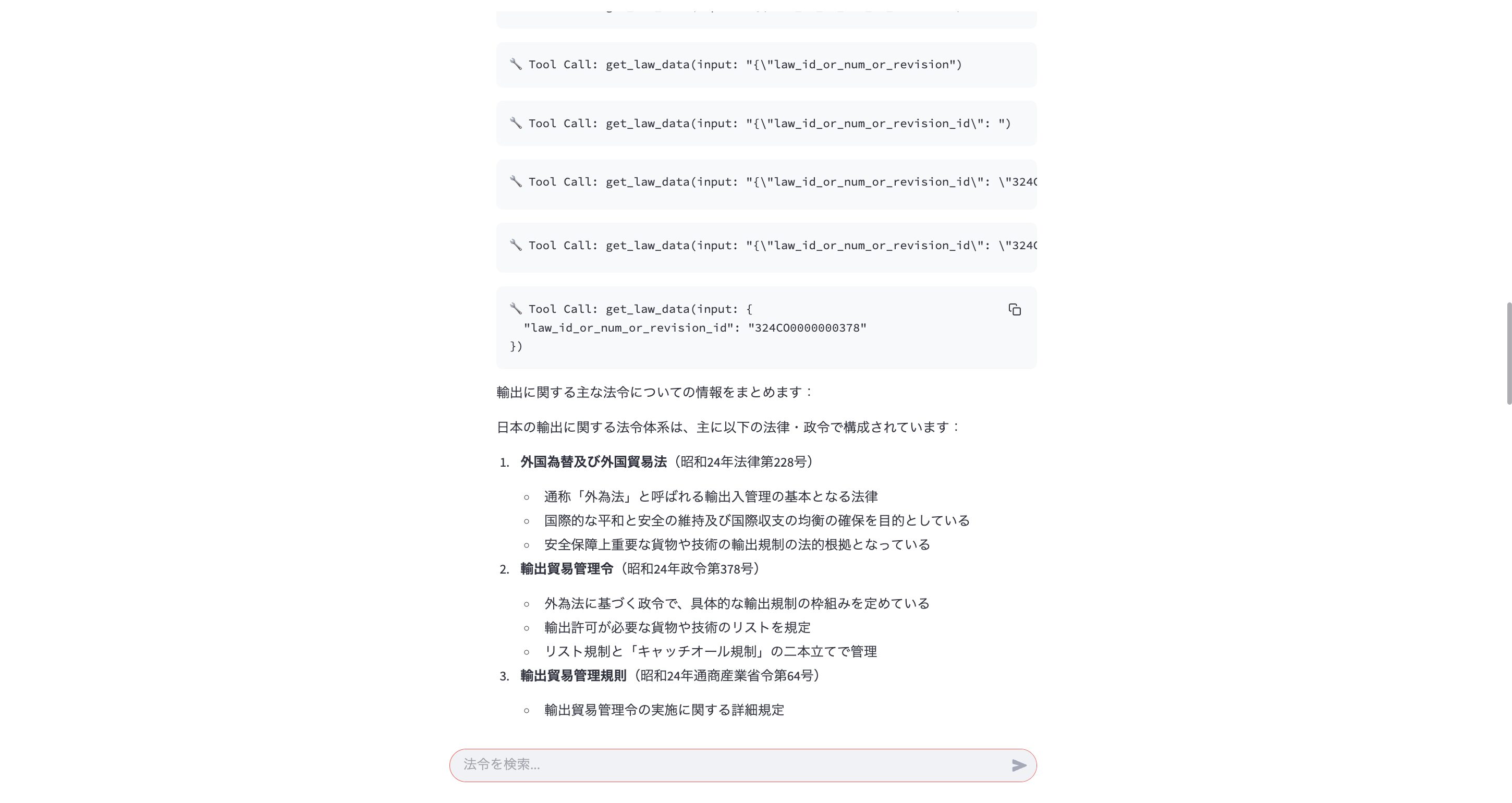
2枚目の画像が最終的な出力ですが、画像下部で、get_law_datatoolを使い、検索を行うことで、法令のより詳細な情報を提供してくれています。
参考)画面に出力された内容
輸出に関する法令を検索します。
🔧 Tool Call: search_laws(input: "")
🔧 Tool Call: search_laws(input: "{\"keyword\": \"輸出\"")
🔧 Tool Call: search_laws(input: "{\"keyword\": \"輸出\"")
🔧 Tool Call: search_laws(input: "{\"keyword\": \"輸出\", \"max_re")
🔧 Tool Call: search_laws(input: "{\"keyword\": \"輸出\", \"max_results")
🔧 Tool Call: search_laws(input: "{\"keyword\": \"輸出\", \"max_results\": 5}")
🔧 Tool Call: search_laws(input: "{\"keyword\": \"輸出\", \"max_results\": 5}")
🔧 Tool Call: search_laws(input: "{\"keyword\": \"輸出\", \"max_results\": 5}")
....中略
輸出に関する主な法令についての情報をまとめます:
日本の輸出に関する法令体系は、主に以下の法律・政令で構成されています:
外国為替及び外国貿易法(昭和24年法律第228号)
通称「外為法」と呼ばれる輸出入管理の基本となる法律
国際的な平和と安全の維持及び国際収支の均衡の確保を目的としている
安全保障上重要な貨物や技術の輸出規制の法的根拠となっている
輸出貿易管理令(昭和24年政令第378号)
外為法に基づく政令で、具体的な輸出規制の枠組みを定めている
輸出許可が必要な貨物や技術のリストを規定
リスト規制と「キャッチオール規制」の二本立てで管理
輸出貿易管理規則(昭和24年通商産業省令第64号)
輸出貿易管理令の実施に関する詳細規定
これらの法令により、武器や軍事転用可能な貨物・技術の輸出は、経済産業大臣の許可が必要とされています。特に国際的な平和と安全を脅かすおそれのある国・地域への輸出については、厳格な審査が行われます。
輸出に関する法令を検索します。
......中略(長いので)
外国為替及び外国貿易法の内容を確認します。
🔧 Tool Call: get_law_data(input: "")
🔧 Tool Call: get_law_data(input: "{\"")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_nu")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_nu")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision_id\": \"324A")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision_id\": \"324A")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision_id\": \"324A")
🔧 Tool Call: get_law_data(input: {
"law_id_or_num_or_revision_id": "324AC0000000228"
})
🔧 Tool Call: get_law_data(input: {
"law_id_or_num_or_revision_id": "324AC0000000228"
})
申し訳ありませんが、外国為替及び外国貿易法の内容を取得できませんでした。次に、輸出貿易管理令の内容を確認してみます。
🔧 Tool Call: get_law_data(input: "")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_n")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision_id\": ")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision_id\": \"324CO000")
🔧 Tool Call: get_law_data(input: "{\"law_id_or_num_or_revision_id\": \"324CO0000000378\"}")
🔧 Tool Call: get_law_data(input: {
"law_id_or_num_or_revision_id": "324CO0000000378"
})
輸出に関する主な法令についての情報をまとめます:
日本の輸出に関する法令体系は、主に以下の法律・政令で構成されています:
外国為替及び外国貿易法(昭和24年法律第228号)
通称「外為法」と呼ばれる輸出入管理の基本となる法律
国際的な平和と安全の維持及び国際収支の均衡の確保を目的としている
安全保障上重要な貨物や技術の輸出規制の法的根拠となっている
輸出貿易管理令(昭和24年政令第378号)
外為法に基づく政令で、具体的な輸出規制の枠組みを定めている
輸出許可が必要な貨物や技術のリストを規定
リスト規制と「キャッチオール規制」の二本立てで管理
輸出貿易管理規則(昭和24年通商産業省令第64号)
輸出貿易管理令の実施に関する詳細規定
これらの法令により、武器や軍事転用可能な貨物・技術の輸出は、経済産業大臣の許可が必要とされています。特に国際的な平和と安全を脅かすおそれのある国・地域への輸出については、厳格な審査が行われます。
toolの定義や、プロンプト、出力の仕方などにおいて、それぞれ改善できそうな部分がありますが、Agentがtoolを自律的に選択して、回答を導き出す部分まで確認することができたため、一旦検証はここまでとします。
番外編)トレースについて
今回構築したエージェントは、OpenTelemetryという標準技術を使って内部の動きを詳細に記録する機能を持っています。これは、エージェントがどのように思考し、どのツールを呼び出し、どのような結果を得たかといった「裏側」のプロセスを可視化するためのものです。
コード内の
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "http://localhost:6006/v1/traces"
という行がその設定を示しています。これは、エージェントが生成するトレースデータをlocalhost:6006でリッスンしているOpenTelemetry Collectorというプログラムに送信するという意味です。
今回はPhoenixというツールを使い、トレースを可視化しました。(※本記事では深くは触れませんが、ローカル環境で簡単にエージェントの内部の挙動を確認できます)
他にも、JaegerやLangfuseといったツールを使うことも可能で、エージェントの実行フローを追跡し、デバッグやパフォーマンスの最適化に役立てることができます。
まとめ
今回は、近年話題となっているAIエージェントに実際に触れてみました。
エージェントに実行させたいタスクが明確かつ的確である場合に、より活用性が高いのだろうな、と感じました。
また、従来の一問一答形式のAIチャットやRAGシステムでは、欲しい情報にたどり着くまでに何度も質問を重なければならない場合も少なくありません。しかし、「自律的に考えて、必要な情報検索を行ってくれる」AIエージェントを独自に定義して活用できれば、この手間とストレスを大きく軽減できると感じました。
まだStrands Agentsの一部の機能にしか触れられていないと思うので、今後もStrands Agentsの動向を追って、業務活用の余地について模索していきたいと思います。



