はじめに
システムの更新などで NLB のターゲットグループを切り替えたい場面があります。
ALBであれば加重ルーティングによって確実にダウンタイムを発生させずに切り替えることが可能です。
NLBは、加重ルーティングができないので、AWS CLI による切り替えでダウンタイムが発生しないのか検証しました。
結論、AWS CLI による切り替えでは、瞬断や新旧混在のリスクがあることがわかりました。
検証環境
以下の環境で、old から new の切り替えにダウンタイムが発生しないことを検証します。
| リソース | 用途/設定 |
|---|---|
| EC2 インスタンス | Instance-oldInstance-new |
| Web サーバ | 各インスタンスで稼働させます。 アクセスすると自身のホスト名を返します。(例: “Hello from old”) |
| NLB | 1台 |
| ターゲットグループ | tg-old (Instance-oldを登録) tg-new (Instance-newを登録) |
検証
1. 初期状態の確認
まず NLB のリスナーが旧環境である tg-old へ紐付いている状態にします。

この状態でローカル端末から NLB へアクセスします。
レスポンスに old 側のホスト名が含まれることを確認できます。

2. テスト通信の開始
常に新しい接続が発生している状況をシミュレートするために、 0.1秒ごとに NLB へアクセスし続けるスクリプトを実行します。
成功・失敗がすべて記録されるようにします。
実行スクリプト
while true; do
# -s: 進捗非表示, -m 1: 最大1秒でタイムアウト, --connect-timeout 1: 接続タイムアウト1秒
curl -s -m 1 http://<NLBのDNS名> --connect-timeout 1
# $? は直前のコマンドの終了ステータス。0以外はエラー
if [ $? -ne 0 ]; then
echo "!!!!!! CONNECTION FAILED !!!!!!"
fi
echo "" # 見やすいように改行
sleep 0.1
done > connection_test_log.txt
実行すると、アクセスの結果がファイルに出力されていることが確認できます。
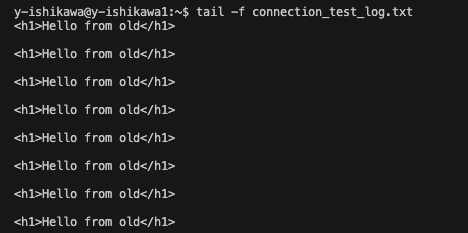
3. ターゲットグループの切り替え
テストを実行したままの状態を保ちます。
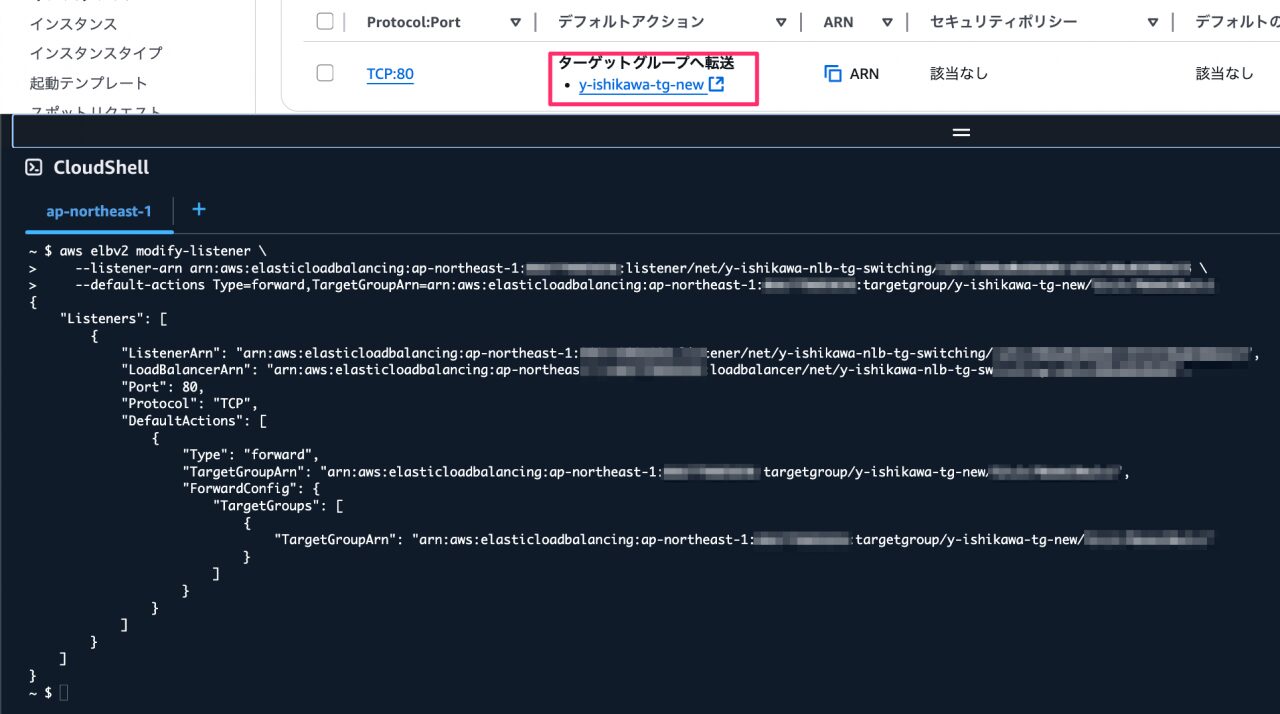
AWS CLI でリスナーの転送先を tg-old から tg-new へ変更します。
実行コマンド
aws elbv2 modify-listener \
--listener-arn <対象リスナーのARN> \
--default-actions Type=forward,TargetGroupArn=<tg-newのARN>
実行結果
4. 結果の確認
切り替え操作が完了したので、テストの結果を確認します。
connection_test_log.txt の中身を確認します。
↓抜粋
<h1>Hello from old</h1> <h1>Hello from old</h1> <h1>Hello from old</h1> <h1>Hello from old</h1> <h1>Hello from old</h1> <h1>Hello from old</h1> <h1>Hello from new</h1> <h1>Hello from old</h1> <h1>Hello from old</h1> <h1>Hello from new</h1> <h1>Hello from old</h1> <h1>Hello from old</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1> curl y-ishikawa-nlb-tg-switching-xxx.elb.ap-northeast-1.amazonaws.comcurl y-ishikawa-nlb-tg-switching-xxx.elb.ap-northeast-1.amazonaws.comcurl y-ishikawa-nlb-tg-switching-xxx.elb.ap-northeast-1.amazonaws.com CONNECTION FAILED curl y-ishikawa-nlb-tg-switching-xxx.elb.ap-northeast-1.amazonaws.comcurl y-ishikawa-nlb-tg-switching-xxx.elb.ap-northeast-1.amazonaws.comcurl y-ishikawa-nlb-tg-switching-xxx.elb.ap-northeast-1.amazonaws.com <h1>Hello from new</h1> <h1>Hello from new</h1> <h1>Hello from new</h1>
old と new へのアクセスが混在している期間があるようです。
一度だけ、CONNECTION FAILEDも発生しています。
また、切り替えコマンド実施後、数秒は old への接続となっていました。
考察
この挙動は NLB が単一の機器ではなく、複数のノードで構成される分散システムであることに起因すると考えられます。AWS のシステムは、操作を受け付ける「コントロールプレーン」と、実際に通信を処理する「データプレーン」に分かれています。今回の結果は、この仕組みと特性を明確に示しています。
なぜ切り替え後に遅延や混在が発生したのか?
modify-listener コマンドを実行すると、まずコントロールプレーンが「リスナーの転送先を tg-new に変更する」という指示を即座に受け付けます。
しかし、その指示がデータプレーン、つまり実際に通信を処理している複数の NLB ノードに伝わるまでには、わずかな伝搬時間がかかります。この伝搬は、すべてのノードへ瞬時に、かつ同時に行われるわけではありません。
このため、以下の現象が発生します。
1. 遅延: コマンド実行後も、まだ新しい設定が届いていない NLB ノードは、古い tg-old へ通信を転送し続けます。
2. 混在: 設定が伝搬していく過程で、システム全体が「更新済みノード」と「未更新ノード」の混在状態になります。クライアントからのアクセスは、これらのノードに分散されるため、old と new のレスポンスが入り混じって返ってきます。
この仕組みは、AWS の多くのサービスで採用されている結果整合性 (Eventual Consistency) モデルの一例です。「変更は最終的には必ず全体に反映されるが、その途中経過では新旧の状態が混在しうる」という考え方です。
なぜ CONNECTION FAILED が発生したのか?
今回の検証で最も重要な発見は、この瞬間的な接続エラーです。これは、クライアントからのリクエストが、NLB ノードの設定をまさに書き換えている過渡状態のタイミングに到達してしまったために発生したと考えられます。
分散システムでは、このような設定の切り替え時に、ごくまれにパケットが正しく処理されない瞬間が生まれる可能性があります。理論上はシームレスでも、現実世界ではゼロリスクではないことをこの結果は示しています。
この挙動を考慮すると、NLB のターゲットグループ切り替えは「長時間ダウンしない」ものの、「ごく短時間の瞬断や接続エラーは起こりうる」と理解するのが正確です。
結論
今回の検証から、NLB のターゲットグループ切り替えは AWS CLI の modify-listener 操作によって 「長時間にわたるダウンタイム」は発生しない ことが分かりました。
しかし、AWSサービスの特性によって、瞬断や新旧混在のリスクがあることがわかりました。
Web ブラウザなど、リトライ機能を持つ一般的なアプリケーションであれば、この瞬間的なエラーはユーザーに意識されることなく自動的に回復されるでしょう。
一方で、1回ごとの接続成功率が非常に重要となるような、クリティカルな通信要件を持つシステムではこのリスクを考慮する必要があります。
そのようなケースでは、より高度なトラフィック管理が可能な ALB の加重ルーティングが、さらに安全な選択肢となります。
参考ドキュメント
modify-listener (AWS CLI Command Reference)
https://awscli.amazonaws.com/v2/documentation/api/latest/reference/elbv2/modify-listener.html
コントロールプレーンとデータプレーンについて
https://docs.aws.amazon.com/whitepapers/latest/aws-fault-isolation-boundaries/control-planes-and-data-planes.html


