
はじめに
こんにちは。DX開発事業部の鹿嶋です。ねこ、吸ってますか?
先日、7月末に公開された LangExtract を試す機会があったため、せっかくなのでブログでご紹介させていただければと思います。
LangExtract とは?
LangExtract は、Google 社が開発した、 Gemini モデルを活用して非構造化テキストから構造化された情報を抽出する、オープンソースの Python ライブラリです。
https://developers.googleblog.com/en/introducing-langextract-a-gemini-powered-information-extraction-library/
例として、あるドキュメントの中から「企業名」「担当者名」といった特定の要素を抽出する、カスタマーレビューから「満足」「不満」といった感情を読み取るといったケースでの利用が想定されます。
こちらはあらかじめ決まった情報しか抽出できない、というわけではなく、ユーザが必要とする情報を抽出するように AI に対して指示を行うことで、抽出内容や抽出先を柔軟に制御することが可能です。
また、数万語以上の文字数があるレポートや小説などの長文ドキュメントからも必要な情報を抽出できるなど、高度な分析能力を備えた設計がされています。
実際に触ってみた
上記公式ブログのクイックスタートに記載されている、以下の手順を参考にセットアップします。
※仮想環境の構築や API キーの取得に関しては割愛されているので、GitHub のREADME を参考に設定してみてください
pip install langextract
import textwrap
import langextract as lx
# 1. Define a concise prompt
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text=(
"ROMEO. But soft! What light through yonder window breaks? It is"
" the east, and Juliet is the sun."
),
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"},
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"},
),
],
)
]
# 3. Run the extraction on your input text
input_text = (
"Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
)
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-pro",
)
まず、以下の部分でプロンプト(指示)を定義しています。AI はこの指示に従って動作します。
- 出現順に文字、感情、関係性を抽出すること
- 抽出には正確なテキストを使用すること
- 言い換えやエンティティの重複は避けること
- 文脈を追加するため、各エンティティに意味のある属性を付与すること
# 1. Define a concise prompt
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")次に、AI に対して学習のためのサンプルを渡します。
ここでは、extraction_class(カテゴリ)、extraction_text(抽出するテキスト)、attributes(エンティティの詳細情報)がそれぞれサンプルとして記述されており、対象のテキストから抽出すべき情報が以下のように示されています。
- 「ROMEO」は「登場人物」を表し、「驚き」の「感情」である
- 「But soft!」は「感情」表し、「穏やかな状態」のことを指している
- 「Juliet is the sun」は「関係性」を表し、「比喩」の表現である
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text=(
"ROMEO. But soft! What light through yonder window breaks? It is"
" the east, and Juliet is the sun."
),
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"},
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"},
),
],
)
]
最後に上記で定義した内容を元に、抽出を行います。
AI に実際に分析させる対象のテキストを与え、#1, #2 で定義した内容と、使用するモデルを元にして、テキストから必要となる情報を抽出します。
# 3. Run the extraction on your input text
input_text = (
"Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
)
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-pro",
)
実行結果は以下のとおりでした。
"extractions": [
{
"character": "Lady Juliet",
"character_attributes": {
"emotional_state": "longing"
}
},
{
"emotion": "longingly",
"emotion_attributes": {
"feeling": "yearning"
}
},
{
"relationship": "her heart aching for Romeo",
"relationship_attributes": {
"type": "romantic longing"
}
}
]
}
なおコードの追記により、こちらの結果を jsonl ファイルに保存 → HTML を作成することで、よりビジュアライズされた内容を確認することも可能です。
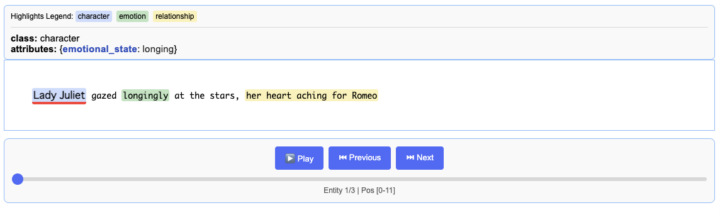
ちょっと応用してみた
とある見積書 PDF から情報を抽出し、その情報を今後の集計・比較・分析といった用途に役立てたい、という架空のシチュエーションを考えました。
まずは PDF から文字情報を抽出し、さらにそのテキストから必要情報を抽出する、といった流れとし、上記のクイックスタートのコードを、見積書のフォーマットから抽出したい情報を取得するよう書き換えます。
少々長くなってしまうので端折りますが、その結果がこちら。
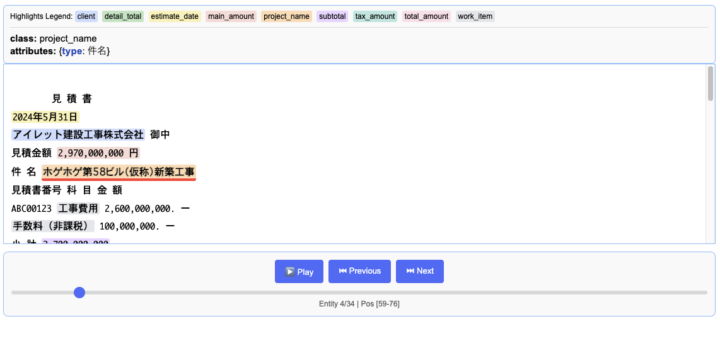
画像では全体は映しきれていませんが、必要情報がどのように、また何行目に記載されているか、といったところまで正確に抽出できています。
フォーマットや記載項目が異なるといったケース対しては別途調整が必要となりそうですが、概ね期待通りの結果を返してくれました!
おわりに
今回は LangExtract を実際に触ってみた感想をお伝えさせていただきました。
すでに Document AI といったドキュメントから情報を抽出するサービスはありますが、膨大なテキストの中からどの位置から来たのかを正確に特定できる点や、感情・比喩表現などの抽象的な概念に対しても柔軟に情報を抽出できる点など、Document AI にはない強みもきちんと持っていると感じました。
一例として、見積書からの情報抽出といったケースを試してみましたが、もちろん使い方はこれだけではなく、顧客からの問い合わせメールの分析や、議事録の文字データからの決定事項の抽出など、応用範囲はまだまだありそうです。
ぜひ皆さんも一度試していただき、日々の業務をさらに効率化するヒントを見つけてみてください!



