
はじめに
プロジェクトの見積書(PDF)からWBS(Excel)を作成する手作業は、時間がかかり記入ミスも起きやすいものです。この定型業務を自動化するため、「PDFをAmazon S3にアップロードするだけで、AIが内容を読み取り、スケジュールまで計算されたWBSをExcel形式で出力する」サーバーレスな仕組みをAWSで構築しました。
システムの全容
1.構成図
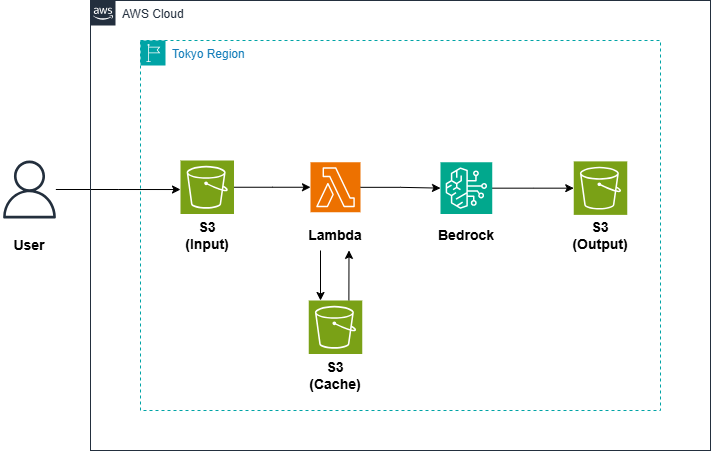
2.処理の流れ
- 利用者がPDFを入力用Amazon S3バケットにアップロードします。
- S3イベントをトリガーにAWS Lambda関数が起動します。
- AWS Lambdaはまず、キャッシュ用Amazon S3バケットに過去の解析結果(JSON)がないか確認します。
- キャッシュがない場合:
- LambdaはPDFをAmazon Bedrock (Claude 3.5 Sonnet)に送信します。
- Amazon Bedrockは、PDFの内容と階層構造を解析し、タスク情報をJSON形式で返します。
- Lambdaは、このJSONをキャッシュ用Amazon S3バケットに保存します。
- Excel生成:
- AWS Lambdaは、キャッシュまたはAmazon Bedrockから取得したJSONデータを元に、タスクの依存関係や日本の祝休日を考慮してスケジュールを自動計算します。
- 最終的なWBSをExcelファイルとして組み立てます。
- 出力:
- 完成したExcelファイルを出力用Amazon S3バケットに保存します。
3.実行結果
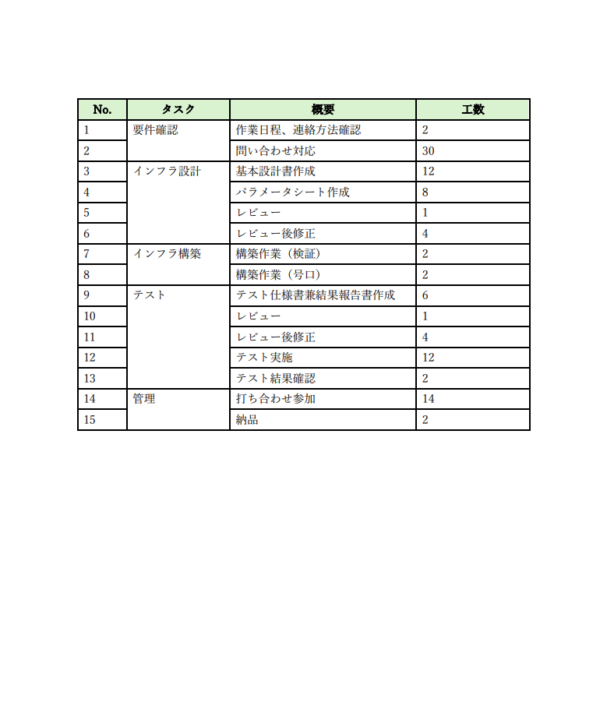
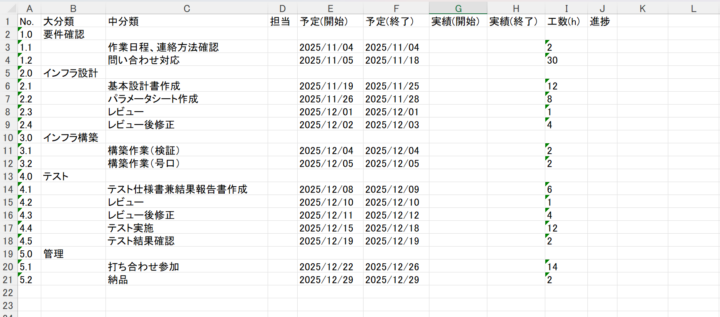
1枚目画像のPDFを入力した結果が2枚目の画像となります。
見積書PDFに記載されているタスクを「大分類」、概要を「中分類」とし、工数を基に作業予定日数を記載するようにしています。
テスト案件の概要
- 案件開始日は「2025/11/1」
- 土日祝は作業予定日には入れない
- 問い合わせ対応、打ち合わせ参加のタスクは納品日まで継続
- 上記以外のタスクはウォーターフォールで進行
4.詰まったところ
- Amazon Textractでは歯が立たなかった
当初、AWSのOCRサービスであるAmazon Textractを試しましたが、日本語の見積書特有の複雑な表レイアウト(結合セルや複数行にまたがる項目)をうまく解析できず、正確なデータ抽出が困難でした。 - AIが指示を無視して「解説」を始めた
解決策として、PDFを直接理解できるAmazon Bedrock (Claude 3.5 Sonnet)に切り替えました。しかし、最初の簡単な指示では、AIはJSONを出力せずに「このPDFは日本のプロジェクト計画書ですね…」と英語で解説を始めてしまいました。対策はAIの役割を厳密に定義する「システムプロンプト」と、XMLタグで指示を構造化した「ユーザープロンプト」を駆使することで、AIに「会話」ではなく「データ抽出ツール」としての役割を徹底させ、期待通りのJSONを出力させることに成功しました。 - AIの些細な「間違い」
強力なプロンプトでも、AIは稀に間違いを犯します。例えば、本来「管理」の中項目であるべき「納品」を、独立した大項目として誤認識することがありました。対策はAIの出力を100%信用するのではなく、AWS LambdaのPythonコード側で「もし『納品』が大項目になっていたら、『管理』に統合する」といった補正処理(後処理)を追加しました。これにより、AIの出力が多少ぶれても、最終的な成果物の品質を担保できるようにしました。
おわりに
今回の開発を通じて、生成AIが従来のOCRでは難しかった、文脈やレイアウトの理解を要するタスクでかなり便利なことが分かりました。
一方で、AIを業務自動化のツールとして安定稼働させるには、強力なプロンプトエンジニアリングと、AIの癖を吸収するプログラム側の後処理という「AIとの付き合い方」が非常に重要だと実感しました。
S3にファイルを置くだけで動くこのサーバーレスな仕組みは、一度作れば非常に低コストで運用できます。皆さんの周りの定型業務も、AIで自動化できるかもしれません。
付録:技術詳細(再現したい方向け)
IAMロールの権限
Lambdaの実行ロールには、以下のAWS管理ポリシーをアタッチしています。
AWSLambdaBasicExecutionRoleAmazonS3FullAccessAmazonBedrockFullAccess
(注: 今回は検証のため広範なアクセス権を付与していますが、実際の運用環境では、特定のS3バケットのみにアクセスを許可するなど、最小権限の原則に従ってより厳密なポリシーを設定することをお勧めします。)
Lambdaレイヤー
以下のライブラリを含むレイヤーを作成しました。
- ライブラリ一覧
openpyxl jpholiday - 作成コマンド
py -m pip install openpyxl jpholiday -t ./python/
Lambda関数の全コード (Python 3.13)
import json
import boto3
import os
import base64
from io import BytesIO
from openpyxl import Workbook
import re
import datetime
import jpholiday
import math
import urllib.parse
# 環境変数からバケット名を取得
OUTPUT_BUCKET = os.environ['OUTPUT_BUCKET']
CACHE_BUCKET = os.environ['CACHE_BUCKET']
# AWSサービスクライアントを初期化
s3_client = boto3.client('s3')
bedrock_runtime = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
def post_process_bedrock_json(bedrock_json):
"""Bedrockの解析結果の癖(「納品」が大項目になる問題)を補正する"""
corrected_json = bedrock_json
management_item = None
delivery_item = None
delivery_item_index = -1
for i, item in enumerate(corrected_json):
if item.get('large_item') == '管理':
management_item = item
if item.get('large_item') == '納品':
delivery_item = item
delivery_item_index = i
if management_item and delivery_item:
management_item['medium_items'].extend(delivery_item.get('medium_items', []))
if delivery_item_index != -1:
del corrected_json[delivery_item_index]
print("Merged '納品' into '管理'.")
return corrected_json
def calculate_final_schedule(wbs_data):
"""依存関係を考慮したウォーターフォール形式のスケジュールを計算する"""
project_start_date = datetime.date(2025, 11, 1)
def is_business_day(d):
return d.weekday() < 5 and not jpholiday.is_holiday(d)
def add_business_days(from_date, add_days):
current_date = from_date
days_to_add = int(add_days)
if days_to_add <= 0: return current_date
days_to_add -= 1
while days_to_add > 0:
current_date += datetime.timedelta(days=1)
if is_business_day(current_date):
days_to_add -= 1
return current_date
def get_next_business_day(from_date):
next_day = from_date + datetime.timedelta(days=1)
while not is_business_day(next_day):
next_day += datetime.timedelta(days=1)
return next_day
# Step 1: タスクを大項目ごとにグループ化
tasks_by_large_item = {}
for item in wbs_data:
if not item.get('is_main'):
large_item_no = item.get('no').split('.')[0]
if large_item_no not in tasks_by_large_item:
tasks_by_large_item[large_item_no] = []
tasks_by_large_item[large_item_no].append(item)
stream_end_dates = {}
# Step 2: 依存関係とタスクリストを定義
# PDFの構成に基づく大項目No: 要件=1, 設計=2, 構築=5, テスト=6
critical_path_nos = ['1', '2', '5', '6']
support_and_delivery_titles = ["問い合わせ対応", "打ち合わせ参加", "納品"]
parallel_nos = [k for k in tasks_by_large_item.keys() if k not in critical_path_nos]
# Step 3: 並列タスクのスケジュールを計算
for lg_no in parallel_nos:
current_date = project_start_date
for task in tasks_by_large_item.get(lg_no, []):
if any(support_title in task.get('title') for support_title in support_and_delivery_titles):
continue
effort = float(task.get('effort', '0'))
if effort > 0:
duration_days = math.ceil(effort / 3)
start_date = current_date
while not is_business_day(start_date): start_date += datetime.timedelta(days=1)
task['start_date'] = start_date
end_date = add_business_days(start_date, duration_days)
task['end_date'] = end_date
current_date = get_next_business_day(end_date)
stream_end_dates[lg_no] = current_date
# Step 4: 依存関係のある主要タスクを順番に計算
critical_path_current_date = project_start_date
for lg_no in critical_path_nos:
start_date_for_stream = critical_path_current_date
if lg_no in tasks_by_large_item:
for task in tasks_by_large_item[lg_no]:
if any(support_title in task.get('title') for support_title in support_and_delivery_titles): continue
effort = float(task.get('effort', '0'))
if effort > 0:
duration_days = math.ceil(effort / 3)
start_date = start_date_for_stream
while not is_business_day(start_date): start_date += datetime.timedelta(days=1)
task['start_date'] = start_date
end_date = add_business_days(start_date, duration_days)
task['end_date'] = end_date
start_date_for_stream = get_next_business_day(end_date)
critical_path_current_date = start_date_for_stream
stream_end_dates[lg_no] = critical_path_current_date
# Step 5: 納品タスクを最後にスケジュール
final_end_date_before_delivery = max(stream_end_dates.values()) if stream_end_dates else project_start_date
delivery_start_date = final_end_date_before_delivery
delivery_final_end_date = delivery_start_date
for task in wbs_data:
if "納品" in task.get('title'):
effort = float(task.get('effort', '0'))
if effort > 0:
duration_days = math.ceil(effort / 3)
start_date = delivery_start_date
while not is_business_day(start_date): start_date += datetime.timedelta(days=1)
task['start_date'] = start_date
end_date = add_business_days(start_date, duration_days)
task['end_date'] = end_date
delivery_final_end_date = end_date
# Step 6: 期間サポートタスクの日程を最終決定
for task in wbs_data:
if "問い合わせ対応" in task.get('title') or "打ち合わせ参加" in task.get('title'):
task['start_date'] = project_start_date
task['end_date'] = delivery_final_end_date
# Step 7: 日付を文字列に変換
for item in wbs_data:
for key in ['start_date', 'end_date']:
if isinstance(item.get(key), datetime.date):
item[key] = item[key].strftime('%Y/%m/%d')
return wbs_data
def create_wbs_excel(wbs_data_with_schedule):
wb = Workbook()
ws = wb.active
ws.title = "WBS"
headers = ["No.", "大分類", "中分類", "担当", "予定(開始)", "予定(終了)", "実績(開始)", "実績(終了)", "工数(h)", "進捗"]
ws.append(headers)
for item in wbs_data_with_schedule:
if item.get('is_main', False):
ws.append([item.get('no', ''), item.get('title', ''), "", "", "", "", "", "", "", ""])
else:
ws.append([
item.get('no', ''), "", item.get('title', ''), "",
item.get('start_date', ''), item.get('end_date', ''),
"", "", item.get('effort', ''), ""
])
in_mem_file = BytesIO()
wb.save(in_mem_file)
in_mem_file.seek(0)
return in_mem_file
def lambda_handler(event, context):
try:
s3_bucket = event['Records'][0]['s3']['bucket']['name']
s3_key_encoded = event['Records'][0]['s3']['object']['key']
s3_key = urllib.parse.unquote_plus(s3_key_encoded)
cache_key = os.path.splitext(s3_key)[0] + '.json'
bedrock_response_json = None
try:
print(f"Checking for cache file: s3://{CACHE_BUCKET}/{cache_key}")
response = s3_client.get_object(Bucket=CACHE_BUCKET, Key=cache_key)
cached_json_str = response['Body'].read().decode('utf-8')
print("Cache hit. Using cached Bedrock response.")
bedrock_response_json = json.loads(cached_json_str)
except s3_client.exceptions.NoSuchKey:
print("Cache miss. Calling Bedrock API.")
pdf_object = s3_client.get_object(Bucket=s3_bucket, Key=s3_key)
pdf_bytes = pdf_object['Body'].read()
base64_pdf = base64.b64encode(pdf_bytes).decode('utf-8')
system_prompt = "あなたは、日本語の見積書PDFから、表形式のデータを高精度に抽出するプロのOCRエキスパートです。指示された通りのJSON形式で情報を整理して出力してください。元のテキストを忠実に再現し、解釈や要約は加えないでください。"
user_prompt = """添付された見積書PDFの画像から、タスクの階層構造を正確に読み取り、以下のフォーマットに厳密に従ってJSONを出力してください。 - 出力は必ずJSON形式の配列 `[]` としてください。\n- 配列の各要素は、大項目を表すJSONオブジェクト `{}` です。\n- 各大項目オブジェクトは、以下のキーを持ってください。\n - `large_item`: 大項目のタスク名(文字列)\n - `medium_items`: 中項目のタスクリスト(配列)\n- `medium_items` 配列の各要素は、中項目を表すJSONオブジェクトで、以下のキーを持ってください。\n - `no`: No.列の値(文字列)\n - `task_name`: 中項目のタスク名(文字列)\n - `task_detail`: 小項目の詳細説明(文字列)\n - `effort`: 工数列の値(文字列)\n- 値が存在しないセルは、空文字列 `""` としてください。\n- JSON以外のテキスト(前置き、説明、コメントなど)は絶対に出力しないでください。 """
request_body = {
"anthropic_version": "bedrock-2023-05-31", "max_tokens": 4000, "system": system_prompt,
"messages": [{"role": "user", "content": [{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": base64_pdf}}, {"type": "text", "text": user_prompt}]}]
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body), modelId='anthropic.claude-3-5-sonnet-20240620-v1:0',
contentType='application/json', accept='application/json'
)
response_body = json.loads(response.get('body').read())
response_text = response_body.get('content', [{}])[0].get('text', '')
if not response_text.strip().startswith('['):
raise ValueError(f"Bedrock did not return valid JSON. Response: {response_text}")
bedrock_response_json = json.loads(response_text)
final_json_str = json.dumps(bedrock_response_json, ensure_ascii=False, indent=2)
s3_client.put_object(Bucket=CACHE_BUCKET, Key=cache_key, Body=final_json_str)
print(f"Saved Bedrock response to cache.")
corrected_data = post_process_bedrock_json(bedrock_response_json)
flat_wbs_data = []
large_item_no = 0
for large_item in corrected_data:
large_item_no += 1
flat_wbs_data.append({'no': f"{large_item_no}.0", 'title': large_item.get('large_item', ''), 'is_main': True})
for i, medium_item in enumerate(large_item.get('medium_items', [])):
task_name = medium_item.get('task_name', '')
task_detail = medium_item.get('task_detail', '')
final_task_name = task_detail if task_detail else task_name
flat_wbs_data.append({
'no': f"{large_item_no}.{i + 1}", 'title': final_task_name,
'effort': medium_item.get('effort', ''), 'is_main': False
})
wbs_with_schedule = calculate_final_schedule(flat_wbs_data)
excel_file = create_wbs_excel(wbs_with_schedule)
excel_key = os.path.splitext(s3_key)[0] + '.xlsx'
s3_client.put_object(Bucket=OUTPUT_BUCKET, Key=excel_key, Body=excel_file)
print(f"Successfully created WBS file: s3://{OUTPUT_BUCKET}/{excel_key}")
return {'statusCode': 200, 'body': json.dumps('Process completed successfully.')}
except Exception as e:
print(f"An error occurred in lambda_handler: {type(e).__name__} - {str(e)}")
import traceback
traceback.print_exc()
raise e


