
はじめに
本記事では、Amazon BedrockとAWS Lambdaを組み合わせ、予約における“代替提案”機能を生成AIで実現する構成を紹介します。
構築するのは検証レベルであり、チャット形式での部屋予約・空室確認・代替提案の流れを最小構成で試せるものです。
目的
チャットによる対話部分に生成AIを活用し、簡易的な予約機能を構築・検証することを目的としています。
注意事項
- 本構成は実サービスではなく検証目的の構成です。
- 認証(Cognito等)や決済、キャンセル処理などの本格的な予約システムに必要な要素は含んでおりません。
- 本記事で使用したコード(CloudFormationは除く)は以下のリポジトリを参考にしています。
- GitHub:amazon-bedrock-agent-test-ui-main
(コードは Apache License 2.0 に基づいて公開されており、必要なライセンス条項に従って使用・改変しています。)
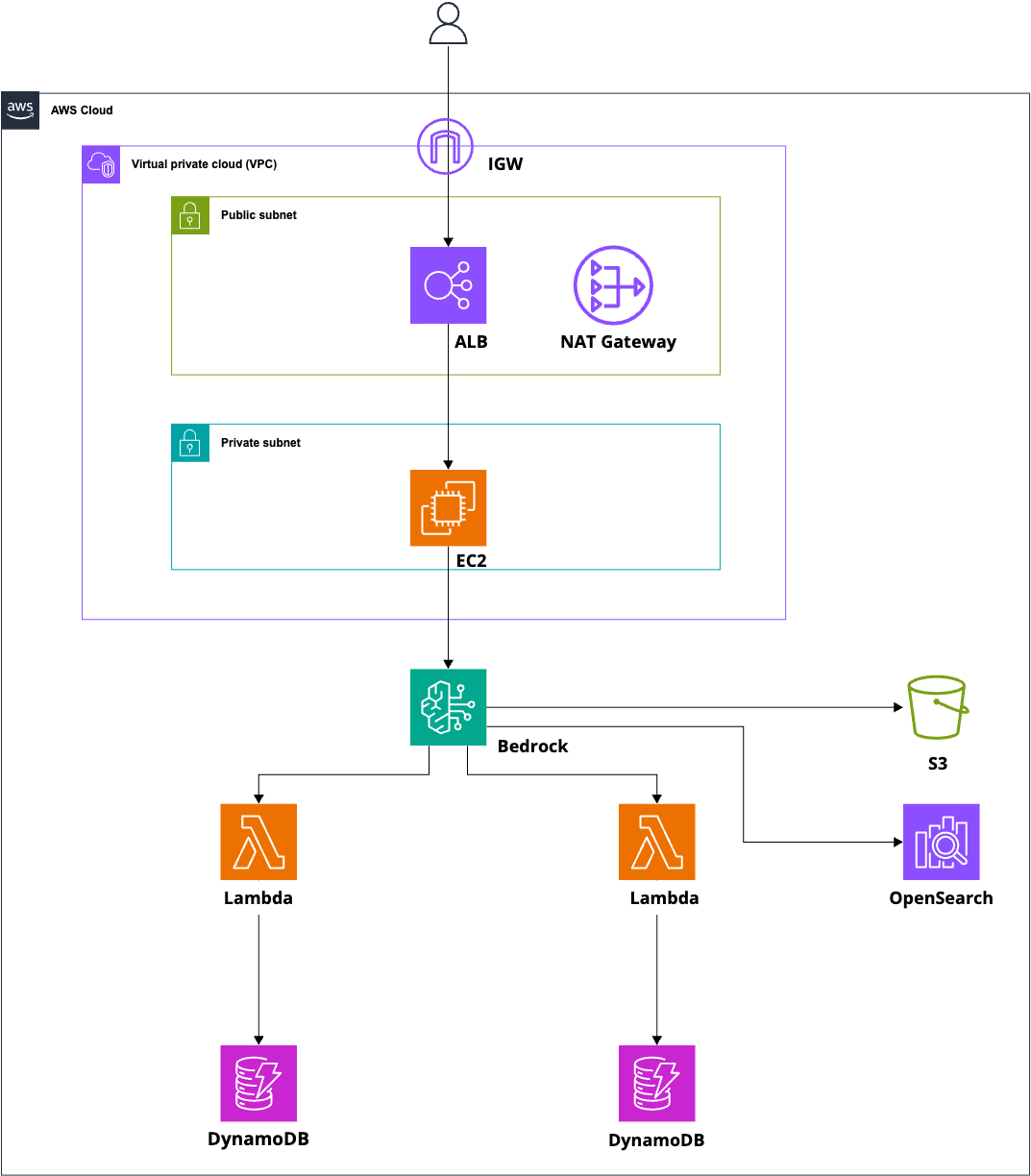
想定システム/使用AWSサービス一覧/利用リージョン
本記事で構築するのはホテルの部屋予約をチャット形式で行うシンプルな予約支援システムです。
ユーザーが「〇月〇日に海の見える部屋を予約したい」と入力すると、その部屋に空きがあれば予約をする。満室だった場合、顧客傾向分析レポート(RAGで使うPDFデータ)をもとに、類似ニーズを満たす代替案(例:夜景の見える部屋)を提示します。
システムには以下のAWSサービスを使用します。
- Amazon Bedrock(Agents、Knowledge Bases、Action Group)
- Bedrock、エージェント、ナレッジベース、アクショングループと記載していきます。
- Amazon S3(PDFレポート格納用)
- S3と記載していきます。
- AWS Lambda(空室確認・予約関数)
- Lambdaと記載していきます。
- Amazon OpenSearch Serverless(ベクトルデータベース)
- OpenSearchと記載していきます。
- Amazon DynamoDB(空室情報・予約データ)
- DynamoDBと記載していきます。
- Amazon EC2(Streamlitの簡易チャットUI)
- EC2と記載していきます。
- Application Load Balancer(EC2公開用)
- ALBと記載していきます。
予約支援機能についてはマネージメントコンソールで構築し、アプリデプロイのためのインフラリソースはAWS CloudFormationで構築します。StreamlitアプリはDockerを使ってデプロイします。
利用リージョンはバージニア北部です。
構成図はこちらとなります。
構築・検証の流れ
予約支援機能の構築からアプリケーション開発、動作確認、リソース削除までを以下の順で進めていきます。
- 予約支援機能構築手順
- RAG用データ作成とS3バケットへのアップロード
- Bedrockエージェント設定
- Bedrockナレッジベース設定
- 空室情報テーブルの作成/空室確認関数の作成
- 予約テーブルの作成/予約情報関数の作成
- アプリケーション開発手順
- インフラ構築
- アプリの設定
- ターゲットの登録
- アプリの稼働確認
- リソースの削除
- アプリ用インフラの削除
- Bedrockエージェントの削除
- Bedrockナレッジベースの削除
- Lambda関数の削除
- DynamoDBのテーブル削除
- OpenSearchのコレクション削除
- S3の削除
- その他リソース
予約支援機能構築手順
RAG用データ作成とS3バケットへのアップロード
AIが文脈に沿った代替提案をするには事前知識となる情報を読み込ませる仕組みが必要です。(いわゆるRAG)
この仕組みの実現にBedrockのナレッジベースを使用します。
まず、RAGの情報源となる「予約傾向分析レポート」をS3 バケットへアップロードします。
「予約傾向分析レポート」は以下の内容で、各部屋タイプと特徴、顧客傾向と予約パターン、AIによる代替提案ルールが記載されています。
# ホテル予約傾向分析レポート **〜 顧客のニーズ傾向と部屋選択の関連分析 〜** - 作成日:2025年5月1日 - 作成者:AIエージェント用ナレッジソースチーム --- ## 1. 各部屋タイプと特徴 | 部屋タイプ | タグ名 | 特徴 | |------------------|------------------|----------------------------------------------------| | OceanViewRoom | 海の見える部屋 | 高層階/オーシャンビュー/朝日が差し込む大窓/バルコニー付 | | CityViewRoom | 夜景の見える部屋 | 高層階/シティビュー/夜景ライトアップが美しい/防音性高 | | QuietRoom | 静かな部屋 | 中層階以下/通りに面していない/防音強化/読書・作業に最適 | | SpaciousRoom | 広めの部屋 | ファミリー/複数人向け/ベッド複数/ソファ・テーブル完備 | | BathtubRoom | バスタブ付きの部屋 | 温浴設備充実/長期滞在者に好まれる/浴室・トイレ分離 | | BudgetRoom | 低価格の部屋 | 最小限の設備/ビジネス客や短期滞在向け/眺望なし | | PetFriendlyRoom | ペット可の部屋 | ペット用アメニティ有/床が傷つきにくい/バルコニー付が多い | --- ## 2. 顧客傾向と予約パターン ### OceanViewRoom - **主な利用者層**:カップル/観光客/ハネムーン - **共通嗜好**:ロマンチックな雰囲気、美しい眺望を重視 - **代替候補**:CityViewRoom(景観を求めるニーズが共通) ### CityViewRoom - **主な利用者層**:若年層カップル/写真・SNS志向の観光客 - **共通嗜好**:映える景色、高層階、非日常感 - **代替候補**:OceanViewRoom、SpaciousRoom ### QuietRoom - **主な利用者層**:ビジネス客/高齢者/長期滞在 - **共通嗜好**:安眠、作業空間、静音性 - **代替候補**:SpaciousRoom、BathtubRoom ### SpaciousRoom - **主な利用者層**:ファミリー/グループ旅行者/女子会 - **共通嗜好**:ゆとりのある空間、多目的利用 - **代替候補**:BathtubRoom ### BudgetRoom - **主な利用者層**:ビジネス客/学生/一人旅 - **共通嗜好**:コスト重視、最低限の快適性 - **代替候補**:QuietRoom ### PetFriendlyRoom - **主な利用者層**:愛犬家/家族旅行 - **共通嗜好**:ペットとの同伴、床材や空間の安全性 - **代替候補**:SpaciousRoom --- ## 3. AIによる代替提案ルール | 予約希望部屋タイプ | 代替提案候補 | |------------------|----------------| | OceanViewRoom | CityViewRoom | | CityViewRoom | OceanViewRoom / SpaciousRoom | | QuietRoom | SpaciousRoom / BathtubRoom | | SpaciousRoom | BathtubRoom | | BudgetRoom | QuietRoom | | PetFriendlyRoom | SpaciousRoom |
上記はMarkdown形式です。今回はこれをPDF変換し、S3にアップロードします。(MarkdownをPDFに変換する方法の記載は省きます。適宜エディタツール等で実施ください)
アップロード先となるS3バケットを作成します。S3バケット名は「hotel-rag-knowledge-20250501」とします。
Amazon S3→バケット→バケット作成に進み、バケット名にhotel-rag-knowledge-20250501と入力します。バケット作成ボタンを押下します。
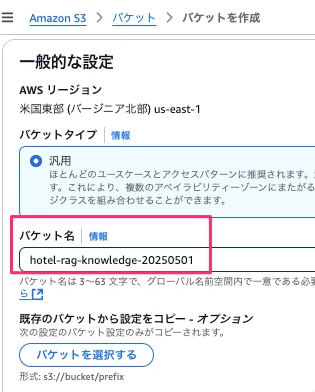
「hotel-rag-knowledge-20250501」が作成できたら、このバケットを選択、オブジェクトをアップロードします。
Amazon S3→バケット→hotel-rag-knowledge-20250501→アップロードを選択、「予約傾向分析レポート」をドラッグアンドドロップ等でS3バケットに配置、アップロードボタンを押下します。
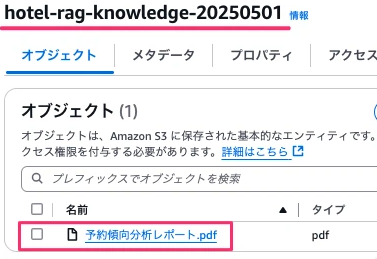
アップロードができました。
Bedrockエージェント設定
Amazon Bedrock→エージェント→エージェントを作成を押下します。
名前は「room-reserve-agent」とします。説明はオプションですが用途が分かるよう記載しておきます。今回はマルチエージェントを使用しないのでチェックなしで作成ボタンを押下します。
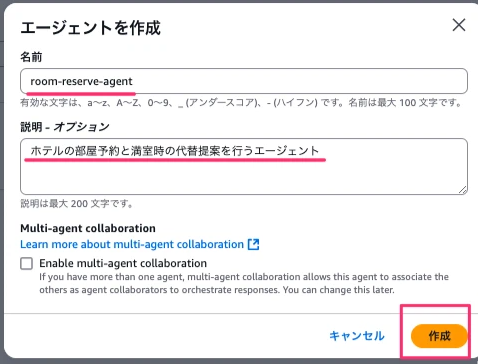
これでエージェントの箱が作成できます。作成が完了するとエージェントビルダー画面に遷移します。ここで具体的な設定を進めます。
エージェントビルダー画面でモデルを選択します。
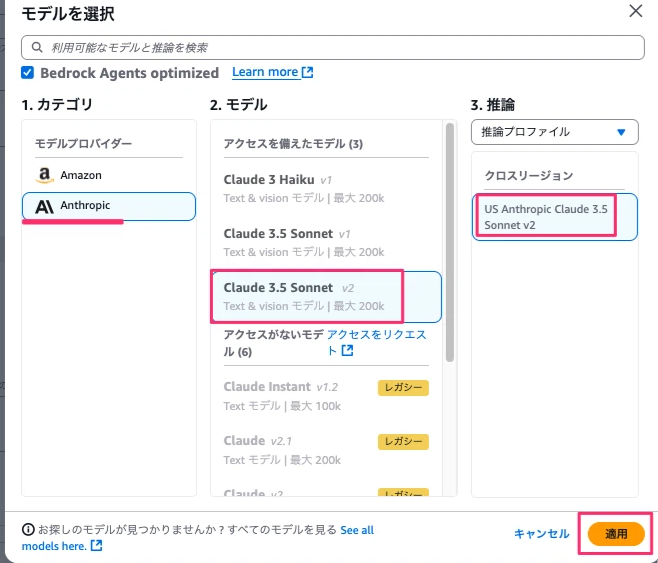
今回はAnthropicのClaude3.5 Sonnet v2で進めます。
※モデルを選択で使用したいモデルが選べるよう、あらかじめモデルアクセスで有効化しておく必要があります。Amazon Bedrock→モデルアクセス→モデルアクセスを変更→使用したいモデルを選択し次へボタンを押下→送信ボタンを押下します。数分待つとモデルが有効化され、有効化したモデルがモデルを選択で選べる状態となります。
次にエージェント向けの指示を設定します。
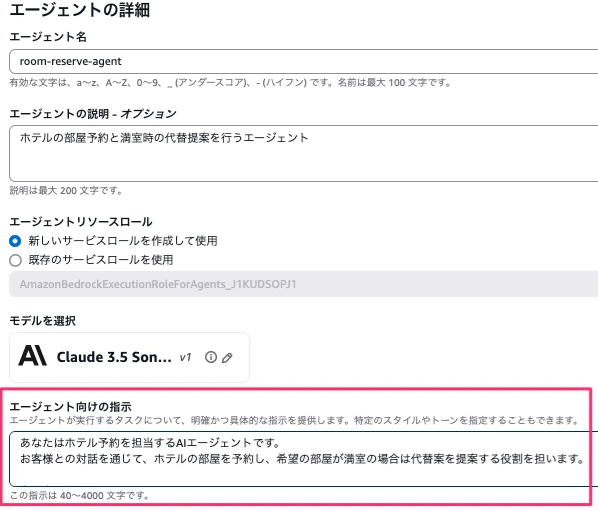
以下の文章をエージェント向けの指示に入力します。
あなたはホテル予約を担当するAIエージェントです。 お客様との対話を通じて、ホテルの部屋を予約し、希望の部屋が満室の場合は代替案を提案する役割を担います。 主なタスク 1.お客様を丁寧に歓迎してください(例:「ようこそ。当ホテルのご予約を承ります。」) 2.チャット形式で部屋の予約受付を行ってください 3.空室確認を行い、空きがあれば予約処理を行ってください 4.希望の部屋が満室だった場合、Knowledge Base(顧客傾向分析レポート)に基づいて、ニーズが近い代替部屋タイプを提案してください 5.最終的に予約が確定したら、「予約が完了したこと」を明確に伝えてください 会話時のルール 1.終始、丁寧で安心感のある対応を心がけてください 2.顧客の希望部屋タイプが「海の見える部屋」や「夜景の見える部屋」などの場合、その意味を汲み取って類似の部屋を提案してください(例:「綺麗な景色を重視される方にはCityViewRoomも人気です」) 3.空室確認や予約処理はアクション(Lambda)経由で行います 確認する情報の例: チェックイン日(例:2025年5月10日) 部屋タイプ(例:OceanViewRoom) 補足事項 予約処理を行う際は、お客様からの最終確認を得てから進めてください 重要:部屋タイプの説明や顧客の好み傾向については、Knowledge Base に格納されたレポート(PDF)を参照してください 会話の文脈を常に把握し、適切に情報を引き継いでください
ここまでできたら保存して終了ボタンを押下します。
遷移した画面にて、準備ボタンを押下します。
ここで一度、テスト画面上で生成AIに話しかけてみます。
設定したエージェント向けの指示には「お客様を丁寧に歓迎してください」と記載しているので、丁寧な返事が生成されるはずです。
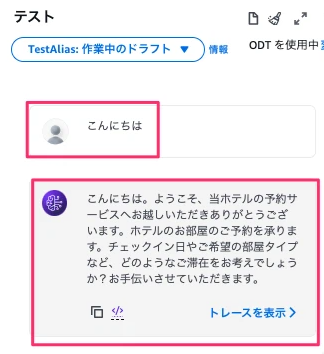
「こんにちは」と入力したところ、「こんにちは。ようこそ、当ホテルの予約サービスへお越しいただきありがとうございます。」との丁寧な返答が生成されました。
Bedrockナレッジベース設定
次にナレッジベースを作成します。
Amazon Bedrock→ナレッジベース→作成ボタン押下→ベクトルストアを含むナレッジベースを選択、押下します。
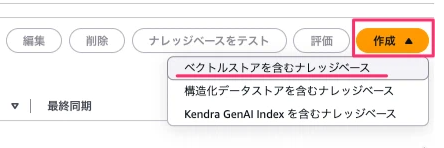
遷移した画面にてナレッジベース名「hotel-room-knowledge」を入力します。オプションですが、こちらも用途が分かるよう簡単に説明文を記載しておきます。
Query EngineのデータソースはS3とし、次へボタンを押下します。
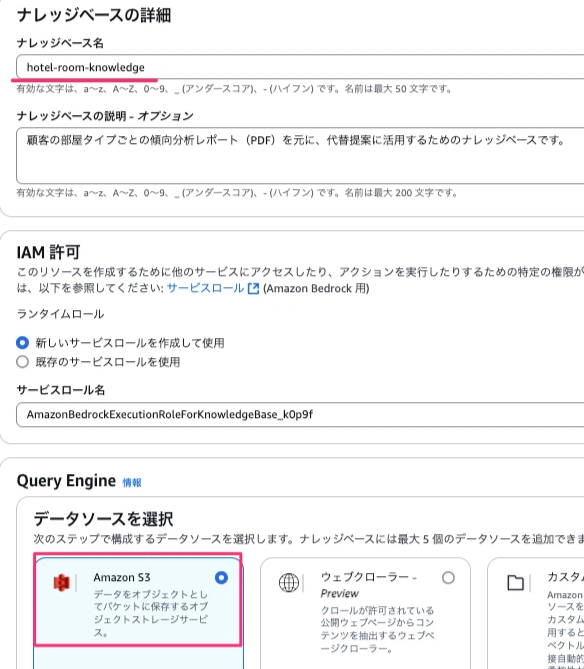
S3 sourceでRAG用に作成したS3バケットを設定します。
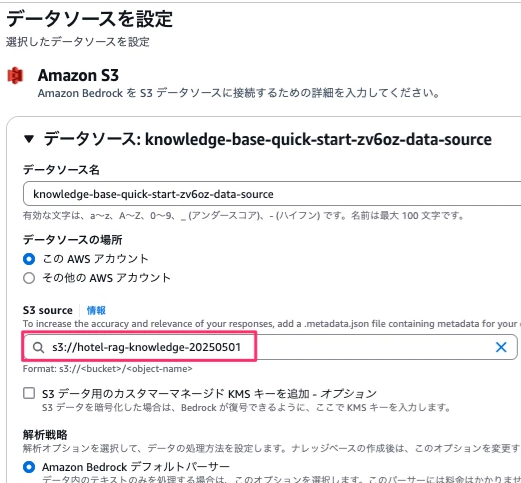
埋め込みモデルを選択します。モデルを選択から今回はAmazonのTitan Text Embeddings V2で進めます。
※こちらについてもあらかじめモデルアクセスで有効化しておく必要があります。
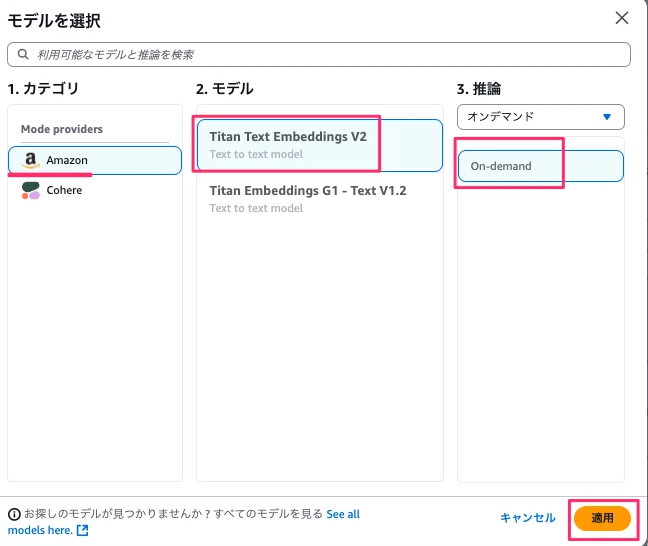
ベクトルストアはAmazon OpenSearch Serverlessとし、次へボタンを押下します。
遷移した画面でナレッジベースを作成ボタンを押下します。
数分待つとナレッジベースが作成されます。
データソースを選択し、同期ボタンを押下します。

データソースの同期が完了したらテストをします。
ナレッジベースをテストボタンを押下します。
遷移した画面でモデルを選択→AnthropicのClaude 3.5 Sonnet v2を選択し、適用ボタンを押下します。
では、プロンプトに「海の見える部屋を好む人は、他にどんな部屋タイプを好みますか?」と入力し、実行してみます。
「予約傾向分析レポート」より、CityViewRoomについて言及した返答をするはずです。
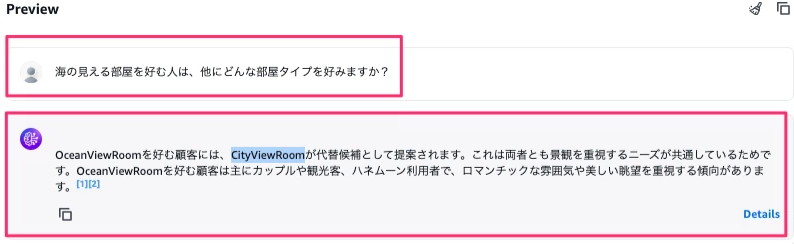
想定通り、CityViewRoomが代替候補として挙がりました。
次にこのナレッジベースを先ほど作成したエージェントに設定します。
エージェントを選択し、編集ボタンを押下します。

ナレッジベースの追加ボタンを押下します。

作成したナレッジベースを選択し、エージェント向けのナレッジベースの指示を入力します。(日本語を入力しています)
入力できたらAddボタンを押下します。
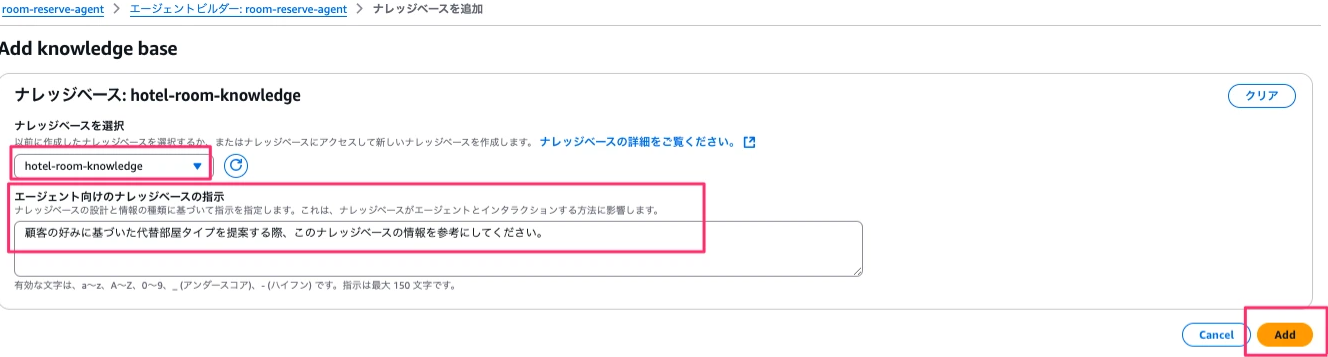
遷移した画面で保存して終了ボタンを押下→準備ボタンを押下します。
では、再度テストしてみます。プロンプトに「海の見える部屋を好むお客様には、他にどの部屋タイプがおすすめですか?」と入力し実行します。

「予約傾向分析レポート」の通り、夜景の見える部屋(CityViewRoom)をおすすめしてくれました。
空室情報テーブルの作成/空室確認関数の作成
一旦Bedrockから離れ、空室情報・予約データのための設定に進みます。
まずはDynamoDBに空室情報テーブルを作成します。
空室確認ロジックなので2件の初期データを手動登録します。
1件目のデータ
Partition key としてdateを設定。型は文字列。値は2025-05-02とする。
次に属性名に部屋の名前、値に空き数を入力。型は数値とします。
空き数に関しては全室1とします。
2件目のデータ
Partition key としてdateを設定。型は文字列。値は2025-05-03とする。
次に属性名に部屋の名前、値に空き数を入力。型は数値とします。
海の見える部屋は空き数0、他の部屋は空き数1とします。
実際の設定に進みます。
DynamoDB→テーブル→デーブルの作成に進み、テーブル名に「RoomAvailabilityTable」と入力、パーティションキーに「date」と入力し、テーブルの作成ボタンを押下します。
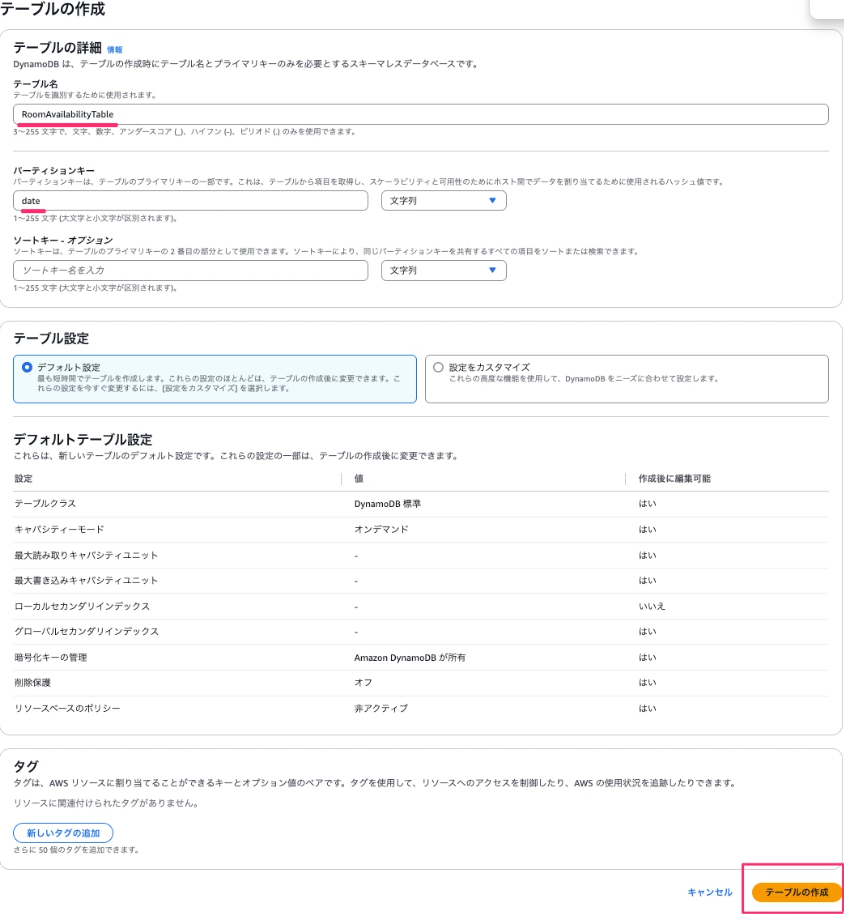
テーブルが作成されたら、作成したテーブル「RoomAvailabilityTable」を選択、テーブルアイテムの探索ボタンを押下→項目を作成を押下します。
1件目のデータは以下の通り入力し、項目を作成ボタンを押下します。
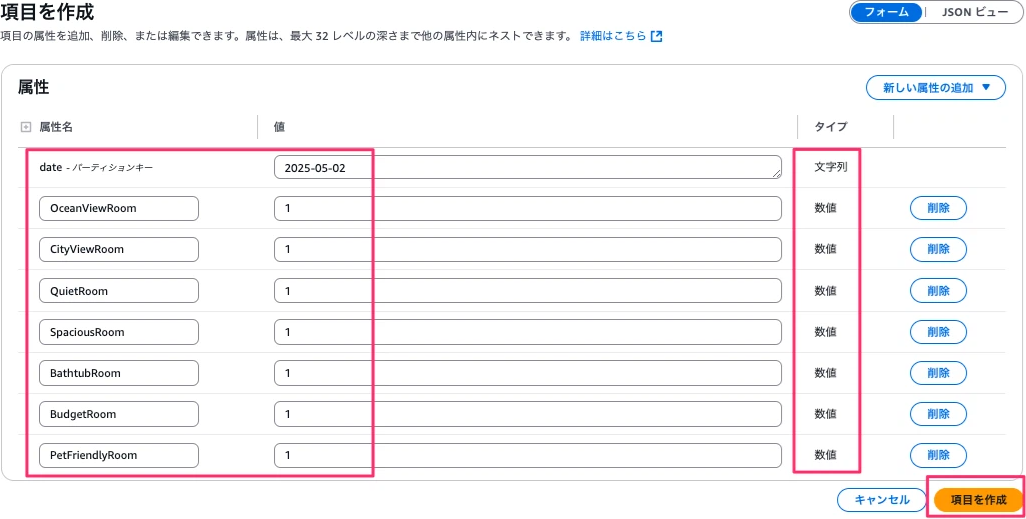
2件目のデータも同様に作成しますが、日付は2025-05-03とし、OceanViewRoomの値は0とします。値の入力ができたら項目を作成ボタンを押下します。
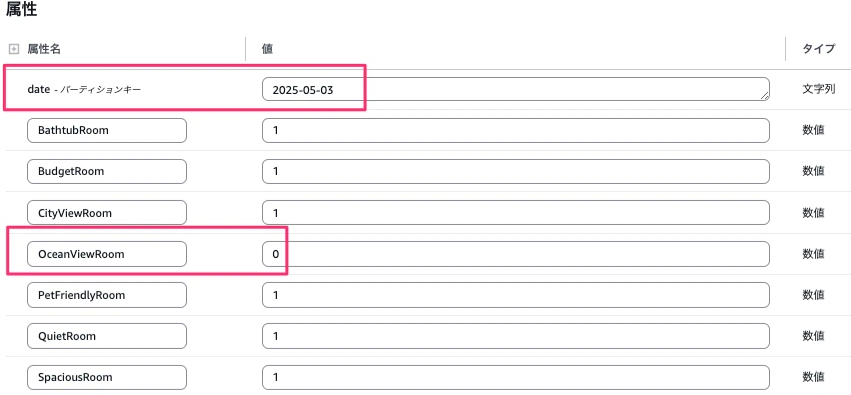
作成ができたら次はLambdaの設定に進みます。
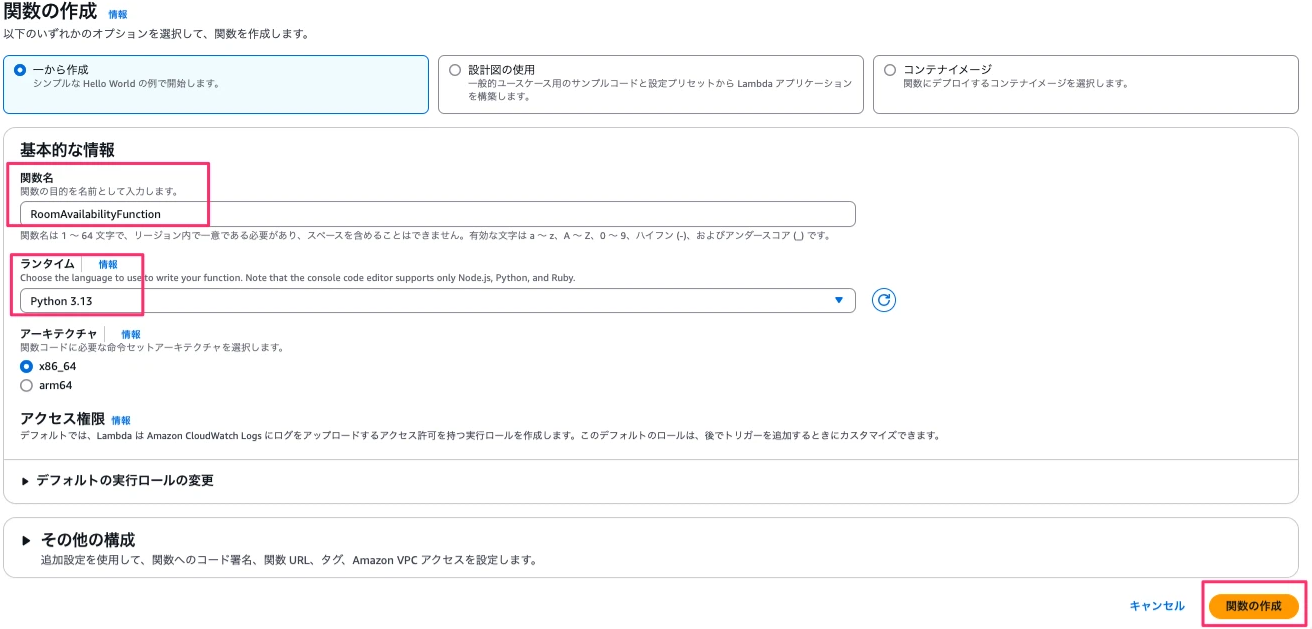
Lambda→関数を選択→関数を作成ボタンを押下します。
関数名に「RoomAvailabilityFunction」、ランタイムに「Python 3.13」を設定し、関数の作成ボタンを押下します。
作成後、まずタブの設定を選択、一般設定のタイムアウトを3秒から1分に変更します。一般設定→編集→タイムアウトを1分→保存ボタンを押下します。

次に権限周りの設定です。LambdaからDynamoDBにアクセスするのでDynamoDBへの権限を付与します。
設定→アクセス権限を選択、実行ロールのロール名を選択すると、IAMの画面に遷移します。許可ポリシーの許可を追加→ポリシーをアタッチでAmazonDynamoDBFullAccessを選択、許可を追加ボタンを押下します。
※今回は検証目的ですのでDynamoDBのフルアクセス権限を付与しています。本番の環境では必要最小限の権限設定を推奨します。

次にコードの設定です。
以下のコードを記載し、保存→デプロイを実行します。
import json
import boto3
# DynamoDB クライアントを作成
client = boto3.client('dynamodb')
def lambda_handler(event, context):
# ユーザーからの入力を取得(予約希望日)
print(f"The user input is {event}")
user_input_date = event['parameters'][0]['value']
# DynamoDB テーブルから該当日の空室情報を取得
response = client.get_item (TableName='RoomAvailabilityTable', Key={'date': {'S': user_input_date}})
#print(response)
room_inventory_data = response['Item']
print(room_inventory_data)
# Bedrock エージェントに返す形式でレスポンスを構築
agent = event['agent']
actionGroup = event['actionGroup']
api_path = event['apiPath']
get_parameters = event.get('parameters', [])
response_body = {
'application/json': {
'body': json.dumps(room_inventory_data)
}
}
print(f"The response to agent is {response_body}")
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
session_attributes = event['sessionAttributes']
prompt_session_attributes = event['promptSessionAttributes']
api_response = {
'messageVersion': '1.0',
'response': action_response,
'sessionAttributes': session_attributes,
'promptSessionAttributes': prompt_session_attributes
}
return api_response
このコードは指定された日付の各部屋タイプの空室状況をDynamoDBから取得し、Bedrockエージェントに返す役割を担います。
ここまで出来たら、Bedrockのエージェントに戻ります。
Amazon Bedrock→エージェント→room-reserve-agentを選択→エージェントビルダーで編集ボタンを押下します。
アクショングループの追加を押下します。
アクショングループに「action-group-roomAvailability」と入力、オプションですが説明に「空室確認」と入力します。
次に、アクショングループタイプでAPIスキーマで定義を選択し、アクショングループの呼び出しには先ほど作成したLambda関数を選択します。
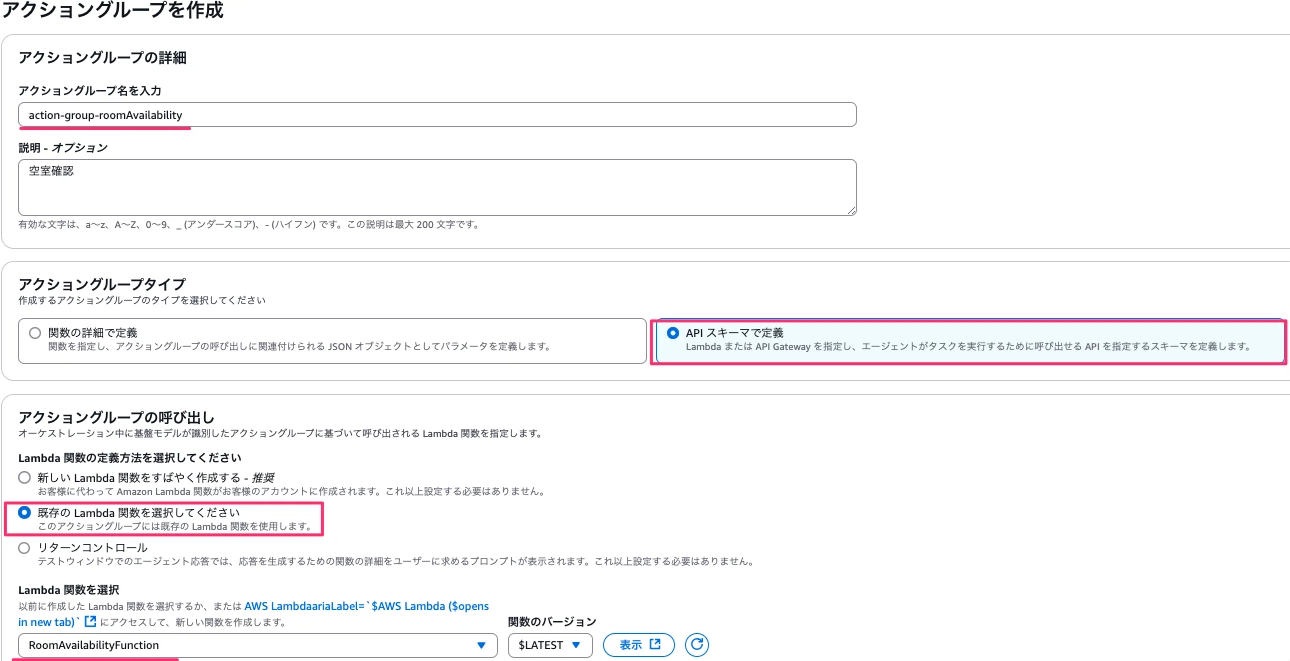
続けてアクショングループスキーマを設定します。
インラインスキーマエディタで定義を選択し、以下を入力します。
openapi: 3.0.0
info:
title: Hotel Room Inventory API
version: 1.0.0
description: API for checking hotel room inventory
paths:
/getRoomInventory/{date}:
get:
summary: Get hotel room inventory by date
description: Returns availability of each room type on a specific date
operationId: getInventorySummary
parameters:
- name: date
in: path
description: Date to check
required: true
schema:
type: string
responses:
"200":
description: Room inventory for given date
content:
application/json:
schema:
type: object
properties:
OceanViewRoom:
type: integer
CityViewRoom:
type: integer
QuietRoom:
type: integer
SpaciousRoom:
type: integer
BathtubRoom:
type: integer
BudgetRoom:
type: integer
PetFriendlyRoom:
type: integer
このスキーマはBedrockエージェントがLambda関数と連携し、部屋ごとの空室状況を取得できるようにするものです。
入力したら作成ボタンを押下します。
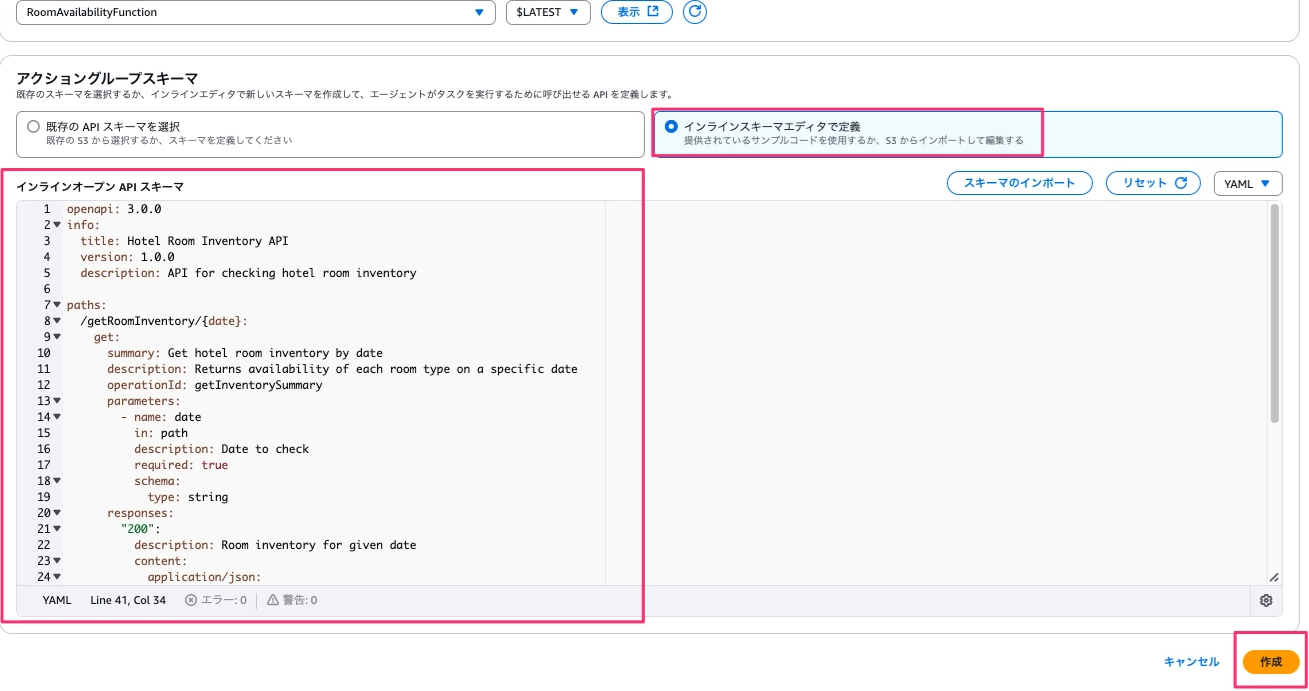
作成できたら保存して終了ボタンを押下し、準備ボタンを押下します。
ここで先ほど作成したLambdaに戻ります。
Bedrock側がLambdaを呼び出せるよう、アクセス権限を編集します。
Lambda→関数→RoomAvailabilityFunction→設定→アクセス権限→リソースベースのポリシーステートメントのアクセス権限を追加ボタンを押下します。
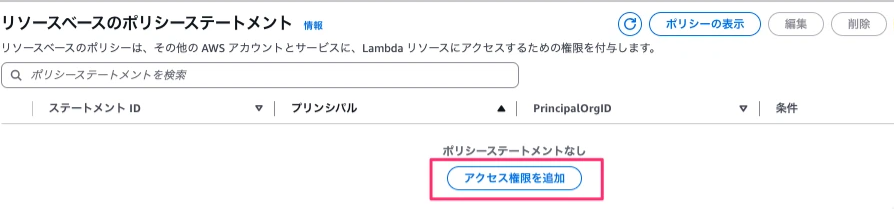
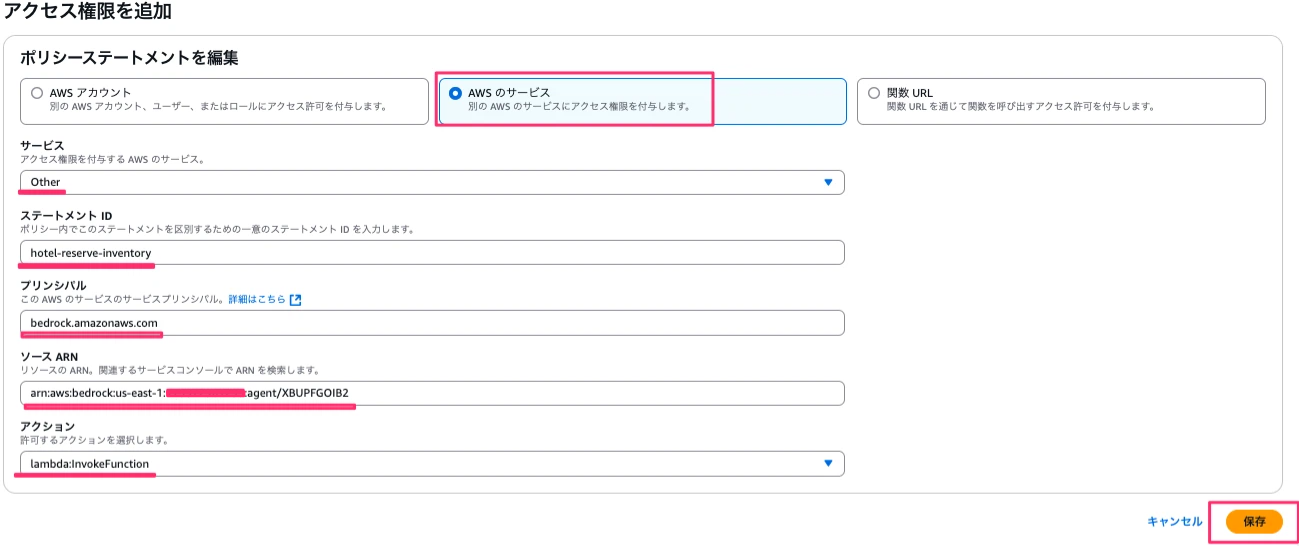
遷移した画面でAWSのサービスを選択、サービスはOtherを選択、ステートメントIDは「hotel-reserve-inventory」と入力、プリンシパルは「bedrock.amazonaws.com」、ソース ARNは紐付けるBedrockエージェントのエージェントARN、アクションはlambda:InvokeFunctionとし、保存ボタンを押下します。
保存ができたらテストをします。
Bedrockエージェントに戻り、テストのプロンプトに「2025年5月2日の空き部屋を教えてください。」と入力してみます。
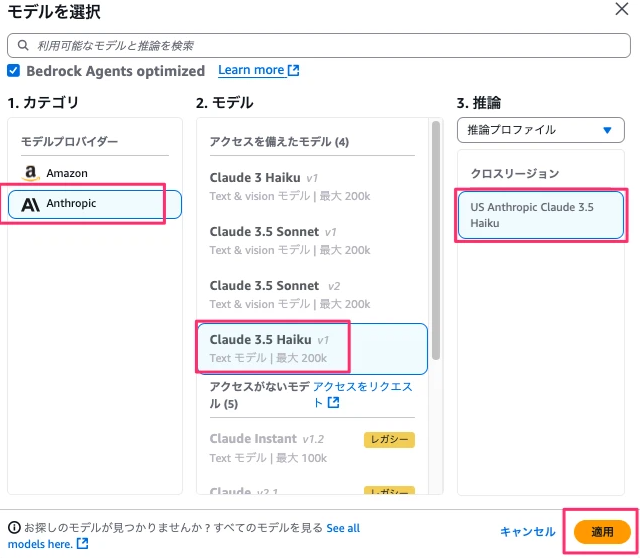
※テストを実行したところ、Bedrockにて429 エラー”Too many requests, please wait before trying again.”が発生しました。これはBedrock側の呼び出し頻度(レート)制限によるもので、今回使用しているAWSアカウントの都合、Claude 3.5 Sonnet V2のクォータ制限が2 req/minとなっておりました。
なので、エージェントでの使用モデルをAnthropicのClaude 3.5 Haikuに変更し、テストを再実施しました。以下の結果はモデル変更後のテスト結果です。
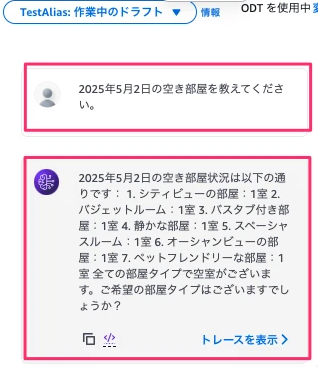
2025年の5月2日は空きのある状態(空室情報テーブルで全て値を1にしている)なので、全ての部屋タイプで空室があるとの返答が確認できました。
「2025年5月3日の空き部屋を教えてください。」と入力した場合、海の見える部屋は満室と返答するかも確認しておきます。
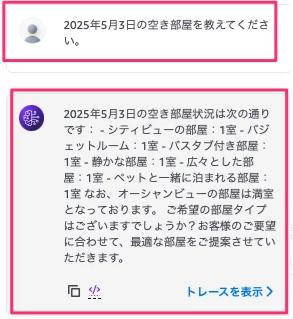
期待通り、オーシャンビューの部屋は満室との返答が確認できました。
(スペーシャスルームと広々とした部屋とで表現に揺らぎがあるのがやや気になりますが、今回はスルーします)
予約テーブルの作成/予約情報関数の作成
空室関係の処理はできたので、次は予約関係の処理に進みます。
まずDynamoDBにテーブルを作成します。予約記録を保持するためのテーブルであり、ユーザーの予約ごとに1件ずつデータを登録します。
Partition keyとしてreserveID を設定します。型は文字列です。
他の値はユーザーの入力に基づきLambda からUUID 、guestName(文字列)、checkInDate(文字列)、roomType(文字列)、numberofNights(数値)が登録されます。
実際の設定に進みます。
DynamoDB→テーブル→デーブルの作成に進み、テーブル名に「RoomReserveTable」と入力、パーティションキーに「reserveID」と入力し、テーブルの作成ボタンを押下します。
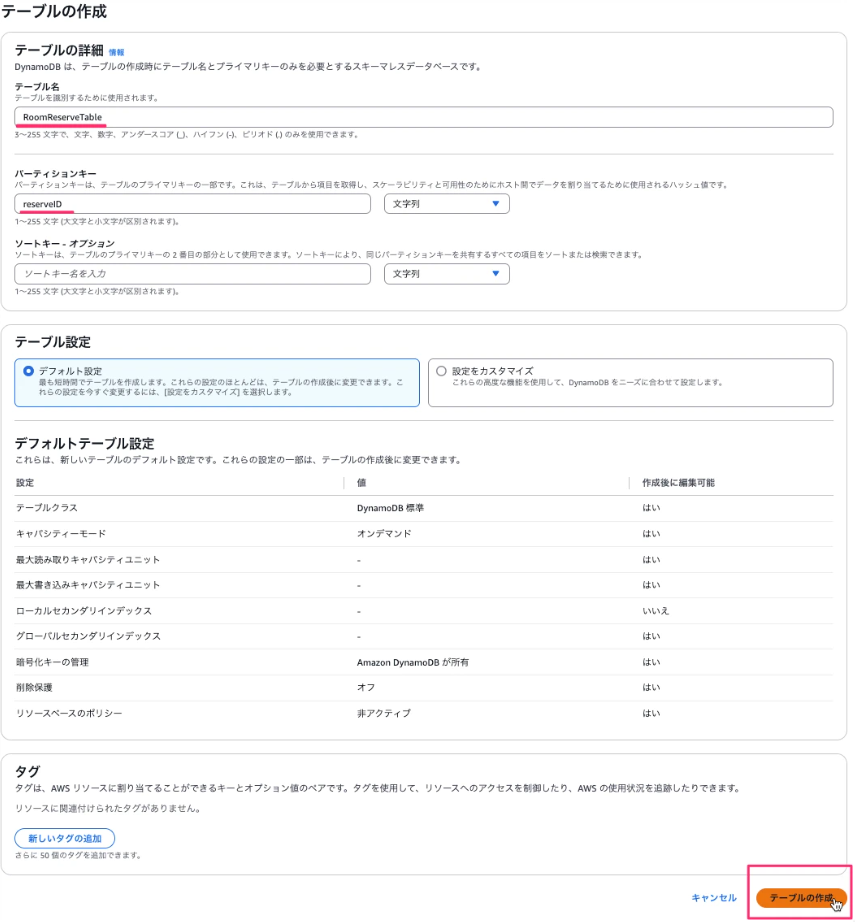
DynamoDBは以上です。Lambda関数の作成に進みます。
Lambda→関数を選択→関数を作成ボタンを押下します。
関数名に「RoomReservationFunction」、ランタイムに「Python 3.13」を設定し、関数の作成ボタンを押下します。
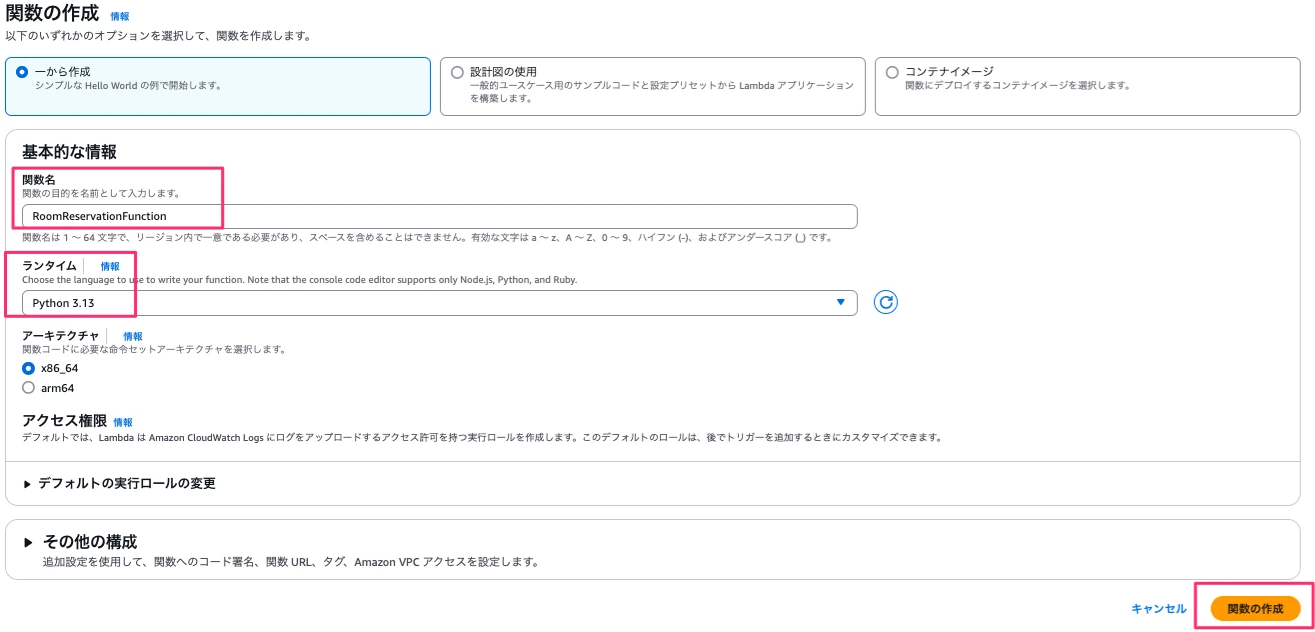
作成後、まずタブの設定を選択、一般設定のタイムアウトを3秒から1分に変更します。一般設定→編集→タイムアウトを1分→保存ボタンを押下する。

次に権限周りの設定です。LambdaからDynamoDBにアクセスするのでDynamoDBへの権限を付与します。
設定→アクセス権限を選択、実行ロールのロール名を選択すると、IAMの画面に遷移します。許可ポリシーの許可を追加→ポリシーをアタッチでAmazonDynamoDBFullAccessを選択、許可を追加ボタンを押下します。
※今回は検証目的ですのでDynaoDBのフルアクセス権限を付与しております。本番の環境では必要最小限の権限設定を推奨します。

次にコードの設定です。以下のコードを記載し、保存→デプロイを実行します。
# ランダムな一意IDを生成するためのライブラリ uuid をインポート(予約IDなどのユニークキー生成に使用)
import json
import boto3
import uuid
# DynamoDBクライアントの作成
client = boto3.client('dynamodb')
# エージェントから受け取った入力データを取得・表示
def lambda_handler(event, context):
print(f"The user input from Agent is {event}")
input_data = event
# 入力データから guestName, checkInDate, numberofNights, roomType を取り出す
input_data = event['requestBody']['content']['application/json']['properties']
print(type(input_data))
print(input_data)
for item in input_data:
if item['name'] == 'guestName':
guestName = item['value']
elif item['name'] == 'checkInDate':
checkInDate = item['value']
elif item['name'] == 'numberofNights':
numberofNights = item['value']
elif item['name'] == 'roomType':
roomType = item['value']
print(guestName)
# 指定された日付の部屋在庫を RoomAvailabilityTable から取得
response = client.get_item(TableName='RoomAvailabilityTable', Key={'date': {'S': checkInDate}})
print(response)
room_inventory_data = response['Item']
print(room_inventory_data)
# 希望する roomType の在庫数を取得し、整数に変換して表示
if roomType not in room_inventory_data:
return {
'statusCode': 400,
'body': json.dumps({'error': f'Invalid room type: {roomType}'})
}
current_room_inventory = int(room_inventory_data[roomType]['N'])
# 在庫が0ならエラーメッセージを返す
if current_room_inventory == 0:
response = {
'statusCode': 404,
'body': json.dumps({'error': f'No {roomType} available for the specified date'})}
print(response)
return response
else:
# 予約ID(UUID)を生成
reserveID = str(uuid.uuid4())
# 予約情報を RoomReserveTable に登録
response_reserve = client.put_item(
TableName='RoomReserveTable',
Item={
'reserveID': {"S": reserveID},
'checkInDate': {"S": checkInDate},
'roomType': {"S": roomType},
'guestName': {"S": guestName},
'numberofNights': {"S": numberofNights}})
# 予約IDを表示
print(f"The response from Lambda is {reserveID}")
# Bedrock Agents が期待する形式でレスポンスを整形して返す
agent = event['agent']
actionGroup = event['actionGroup']
api_path = event['apiPath']
# POSTリクエストのパラメータ取得
post_parameters = event['requestBody']['content']['application/json']['properties']
response_body = {
'application/json': {
'body': json.dumps(reserveID)
}
}
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
session_attributes = event['sessionAttributes']
prompt_session_attributes = event['promptSessionAttributes']
api_response = {
'messageVersion': '1.0',
'response': action_response,
'sessionAttributes': session_attributes,
'promptSessionAttributes': prompt_session_attributes
}
return api_response
このコードはユーザーから受け取った宿泊希望日の空室情報を確認し、在庫があれば予約情報をDynamoDBに登録。予約IDをBedrockエージェントに返す処理をします。
ここまで出来たら、Bedrockのエージェントに戻ります。
Amazon Bedrock→エージェント→room-reserve-agentを選択→エージェントビルダーで編集ボタンを押下します。
アクショングループの追加を押下します。

アクショングループに「action-group-roomReservation」と入力、オプションですが説明に「予約確認」と入力します。
次に、アクショングループタイプでAPIスキーマで定義を選択し、アクショングループの呼び出しでは先ほど作成したLambda関数を選択します。
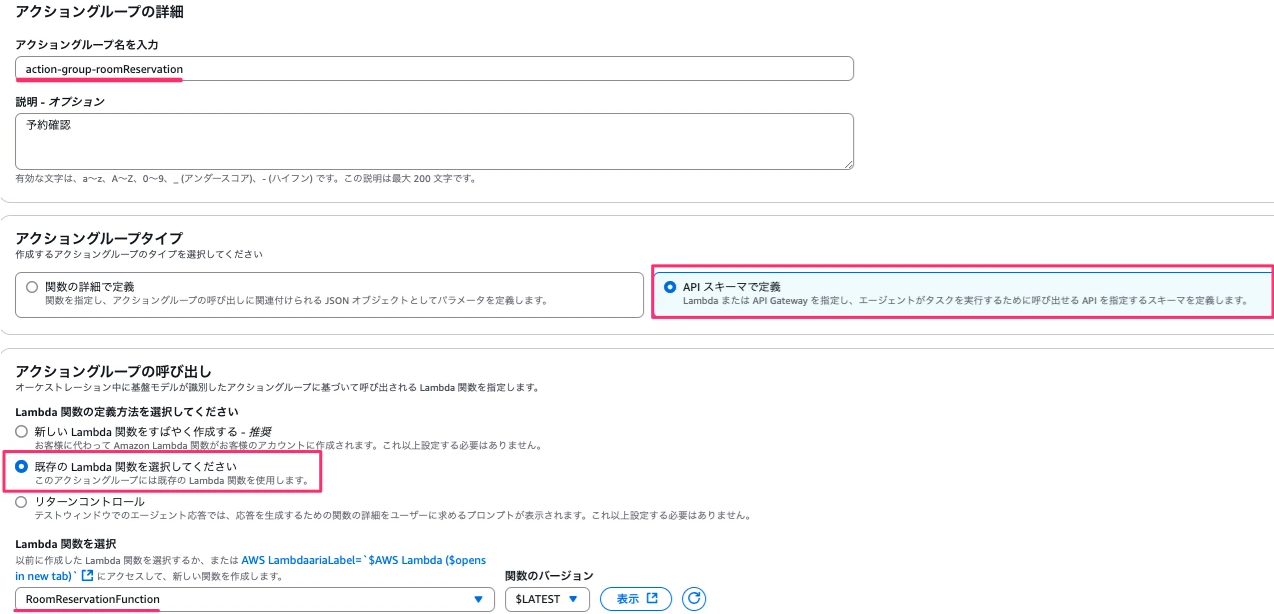
続けてアクショングループスキーマを設定します。
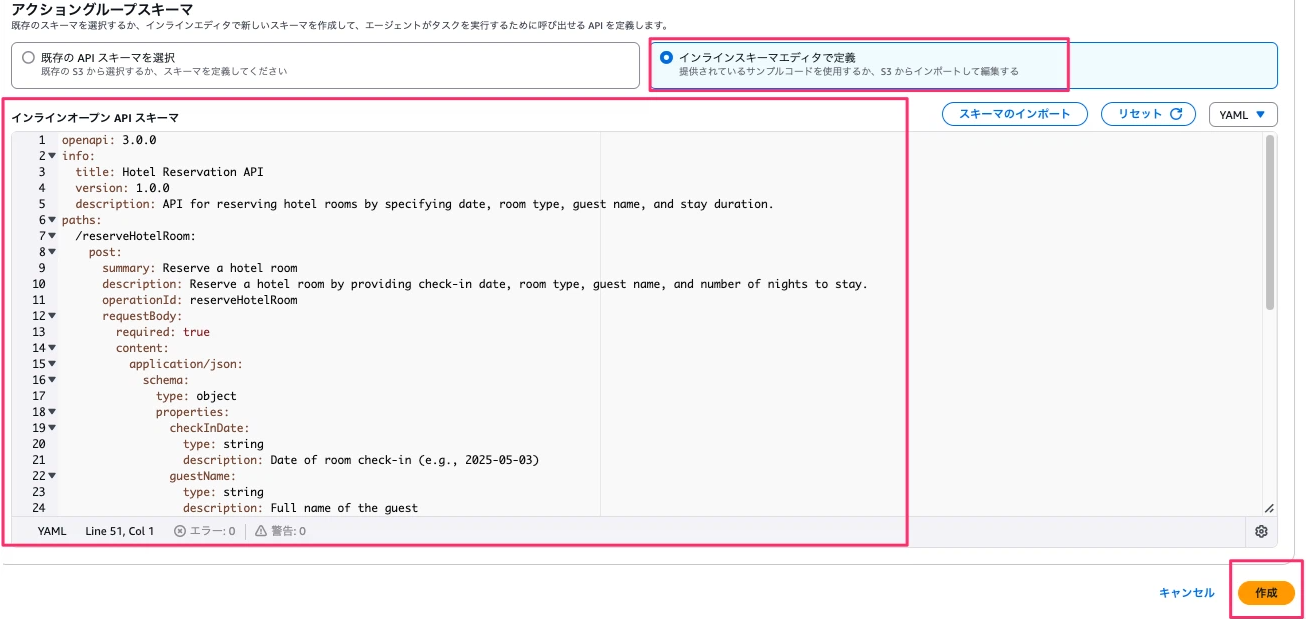
インラインスキーマエディタで定義を選択し、以下を入力します。
openapi: 3.0.0
info:
title: Hotel Reservation API
version: 1.0.0
description: API for reserving hotel rooms by specifying date, room type, guest name, and stay duration.
paths:
/reserveHotelRoom:
post:
summary: Reserve a hotel room
description: Reserve a hotel room by providing check-in date, room type, guest name, and number of nights to stay.
operationId: reserveHotelRoom
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
checkInDate:
type: string
description: Date of room check-in (e.g., 2025-05-03)
guestName:
type: string
description: Full name of the guest
roomType:
type: string
description: Type of room (e.g., OceanViewRoom, BudgetRoom, CityViewRoom, etc.)
numberofNights:
type: integer
description: Number of nights for the reservation
required:
- guestName
- checkInDate
- roomType
- numberofNights
responses:
"200":
description: Successfully reserved the room
content:
application/json:
schema:
type: object
properties:
reserveID:
type: string
description: Your reservation is confirmed. Reservation ID returned.
"400":
description: Invalid request - missing or invalid input parameters
"404":
description: Room not available for the selected date and type
このスキーマはBedrockエージェントがLambda関数と連携し、チェックイン日や部屋タイプなどの情報をもとに宿泊予約を実行できるようにするものです。予約が成功すると予約IDが返されます。
入力したら作成ボタンを押下します。
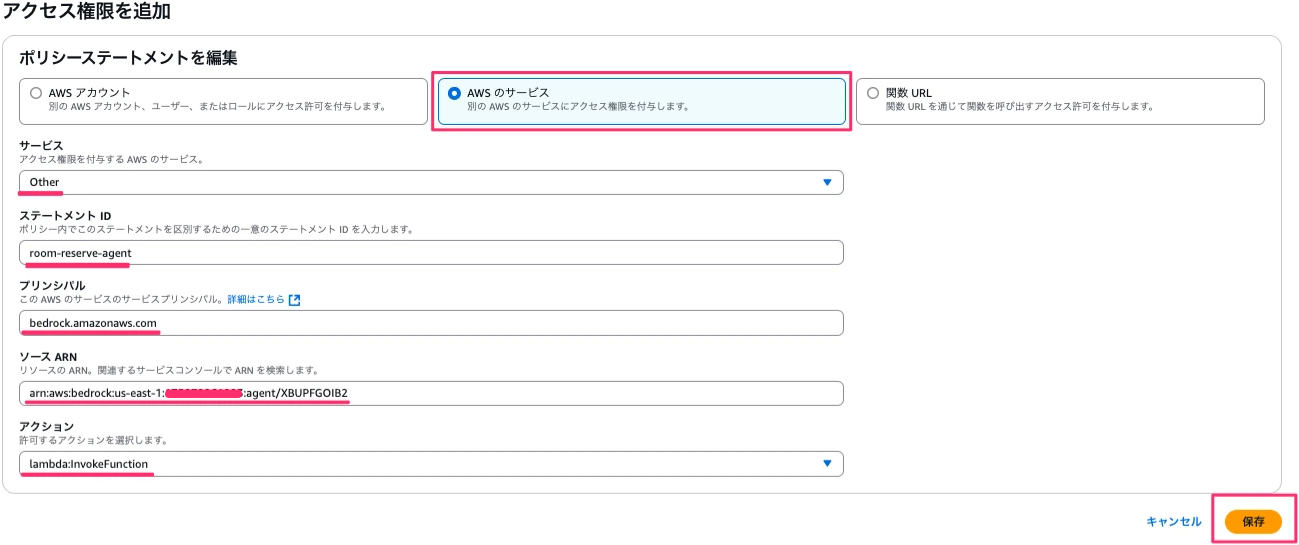
作成できたら保存して終了ボタンを押下し、準備ボタンを押下します。 ここで先ほど作成したLambdaに戻ります。Bedrock側がLambdaを呼び出せるよう、アクセス権限を編集します。Lambda→関数→RoomReservationFunction→設定→アクセス権限→リソースベースのポリシーステートメントのアクセス権限を追加ボタンを押下します。

遷移した画面でAWSのサービスを選択、サービスはOtherを選択、ステートメントIDは「room-reserve-agent」と入力、プリンシパルは「bedrock.amazonaws.com」、ソース ARNは紐付けるBedrockエージェントのエージェントARN、アクションはlambda:InvokeFunctionとし、保存ボタンを押下します。
保存ができたらテストをします。Bedrockエージェントに戻ります。テストのプロンプトに「ホテルの予約をしたいです。名前は田中太郎、チェックイン日は2025年5月2日、宿泊は1泊で、部屋タイプは静かな部屋を希望します。」と入力してみます。

予約に成功しました。丁寧な文章で予約番号も含まれています。
今度は「ホテルの予約をしたいです。名前は佐藤三郎、チェックイン日は2025年5月3日、宿泊は1泊で、部屋タイプは海の見える部屋を希望します。」と入力します。

海の見える部屋が満室である旨と代替案である夜景の見える部屋を提案してくれました。では代替案で予約する旨を返します。「では夜景の見える部屋を代わりに予約します。」と入力します。

予約に成功しました。丁寧な文章で予約番号も含まれています。
予約情報を管理しているDynamoDBのテーブルを確認します。
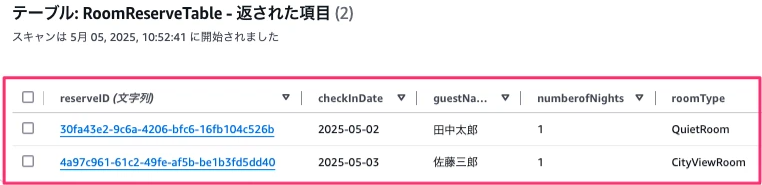
2つ予約をしたので、2つの情報が追加されています。
動作確認が取れたので、エージェントに対しバージョンを発行、そのバージョンにエイリアスを紐付けます。
Amazon Bedrock→エージェント→room-reserve-agentを選択→エイリアスの作成ボタンを押下します。
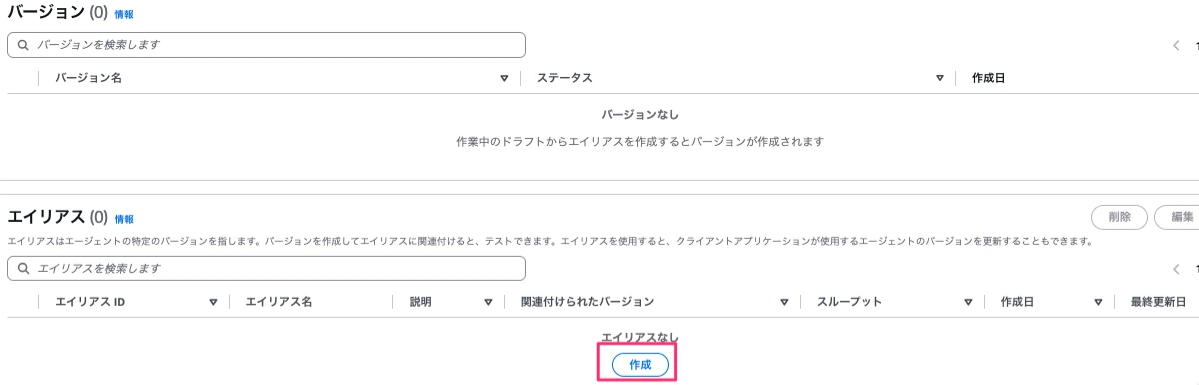
エイリアス名、説明に「v1」と入力しエイリアスを作成ボタンを押下します。
エイリアスが作成されバージョンが発行されました。

これで生成AIを活用した予約支援機能の構築が完了しました。
次はこの機能をチャットベースで操作できるよう、Streamlitを用いたアプリケーション部分の作成に進みます。
アプリケーション開発手順
インフラ構築
アプリケーションのデプロイにあたり、NW系リソース、ALB、EC2を構築します。これらについてはCloudFormationで実施します。
※あらかじめEC2(AL2023)で使用するためのキーペア「test-keypair」を作成しておいてください。CloudFormationに関する詳細な説明は本記事からは省きます。
下記のコードを使いスタックを作成します。
ALBSecurityGroupのCidrIpについては一般公開で良ければ0.0.0.0/0、アクセス制限したい場合、指定のパブリックIPに書き換えてください。
AWSTemplateFormatVersion: '2010-09-09'
Description: Infrastructure for Streamlit App using EC2 and ALB
Parameters:
KeyName:
Type: String
Default: test-keypair
Description: Name of an existing EC2 KeyPair
Resources:
VPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
EnableDnsHostnames: true
EnableDnsSupport: true
Tags:
- Key: Name
Value: test-vpc
InternetGateway:
Type: AWS::EC2::InternetGateway
Properties:
Tags:
- Key: Name
Value: test-igw
AttachGateway:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
VpcId: !Ref VPC
InternetGatewayId: !Ref InternetGateway
PublicSubnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.1.0/24
AvailabilityZone: !Select [ 0, !GetAZs "" ]
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: test-public-01
PublicSubnet2:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.2.0/24
AvailabilityZone: !Select [ 1, !GetAZs "" ]
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: test-public-02
PrivateSubnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.3.0/24
AvailabilityZone: !Select [ 0, !GetAZs "" ]
Tags:
- Key: Name
Value: test-private-01
PublicRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref VPC
Tags:
- Key: Name
Value: test-public-rt
PublicRoute:
Type: AWS::EC2::Route
DependsOn: AttachGateway
Properties:
RouteTableId: !Ref PublicRouteTable
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref InternetGateway
PublicSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref PublicSubnet1
RouteTableId: !Ref PublicRouteTable
PublicSubnet2RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref PublicSubnet2
RouteTableId: !Ref PublicRouteTable
NatEIP:
Type: AWS::EC2::EIP
Properties:
Domain: vpc
Tags:
- Key: Name
Value: test-eip
NATGateway:
Type: AWS::EC2::NatGateway
Properties:
AllocationId: !GetAtt NatEIP.AllocationId
SubnetId: !Ref PublicSubnet1
Tags:
- Key: Name
Value: test-nat
PrivateRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref VPC
Tags:
- Key: Name
Value: test-private-rt
PrivateRoute:
Type: AWS::EC2::Route
Properties:
RouteTableId: !Ref PrivateRouteTable
DestinationCidrBlock: 0.0.0.0/0
NatGatewayId: !Ref NATGateway
PrivateSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref PrivateSubnet1
RouteTableId: !Ref PrivateRouteTable
ALBSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: ALB security group
VpcId: !Ref VPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 80
ToPort: 80
CidrIp: 0.0.0.0/0
Tags:
- Key: Name
Value: test-alb-sg
EC2SecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: EC2 security group
VpcId: !Ref VPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 8501
ToPort: 8501
SourceSecurityGroupId: !Ref ALBSecurityGroup
Tags:
- Key: Name
Value: test-ec2-sg
EC2Role:
Type: AWS::IAM::Role
Properties:
RoleName: test-ec2-role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: [ ec2.amazonaws.com ]
Action: [ "sts:AssumeRole" ]
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
- arn:aws:iam::aws:policy/AmazonBedrockFullAccess
InstanceProfile:
Type: AWS::IAM::InstanceProfile
Properties:
Roles: [ !Ref EC2Role ]
AppInstance:
Type: AWS::EC2::Instance
Properties:
ImageId: ami-0013610ea966aafe0
InstanceType: t4g.micro
KeyName: !Ref KeyName
SubnetId: !Ref PrivateSubnet1
SecurityGroupIds: [ !Ref EC2SecurityGroup ]
IamInstanceProfile: !Ref InstanceProfile
Tags:
- Key: Name
Value: test-app-01
TargetGroup:
Type: AWS::ElasticLoadBalancingV2::TargetGroup
Properties:
Name: test-ec2-tg
Protocol: HTTP
Port: 8501
VpcId: !Ref VPC
TargetType: instance
HealthCheckPath: /
ApplicationLoadBalancer:
Type: AWS::ElasticLoadBalancingV2::LoadBalancer
Properties:
Name: test-alb
Subnets: [ !Ref PublicSubnet1, !Ref PublicSubnet2 ]
SecurityGroups: [ !Ref ALBSecurityGroup ]
Scheme: internet-facing
Type: application
Listener:
Type: AWS::ElasticLoadBalancingV2::Listener
Properties:
DefaultActions:
- Type: forward
TargetGroupArn: !Ref TargetGroup
LoadBalancerArn: !Ref ApplicationLoadBalancer
Port: 80
Protocol: HTTP
アプリの設定
スタックの作成が完了したらセッションマネージャーからEC2にログインし、Docker ベースでのアプリ起動設定を進めます。
#### ユーザーを切り替える ####
sudo su -
#### フォルダ作成 ####
mkdir project-root
#### project-rootに移動 ####
cd project-root
#### app.pyを作成する ####
vi app.py
#### app.pyに以下を記載し保存する ####
from dotenv import load_dotenv
import json
import logging
import logging.config
import re
from services import bedrock_agent_runtime
import streamlit as st
import uuid
import yaml
# 環境変数から設定を取得する
agent_id = 'xxxxxxx' # 自分が作成したAgent IDとすること
agent_alias_id = 'xxxxxxx' # 自分が作成したAgent Alias IDとすること
ui_title = "Welcome to Hotel Reservation Agent"
ui_icon = "BEDROCK_AGENT_TEST_UI_ICON"
def init_session_state():
st.session_state.session_id = str(uuid.uuid4())
st.session_state.messages = []
st.session_state.citations = []
st.session_state.trace = {}
# ページ全体の設定と初期化処理
st.set_page_config(page_title=ui_title, page_icon=ui_icon, layout="wide")
st.title(ui_title)
if len(st.session_state.items()) == 0:
init_session_state()
# セッション状態をリセットするサイドバーのボタン
with st.sidebar:
if st.button("Reset Session"):
init_session_state()
# チャット内のメッセージ表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"], unsafe_allow_html=True)
# エージェントを呼び出すチャット入力欄
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
with st.chat_message("assistant"):
with st.empty():
with st.spinner():
response = bedrock_agent_runtime.invoke_agent(
agent_id,
agent_alias_id,
st.session_state.session_id,
prompt
)
output_text = response["output_text"]
# 出力がinstructionとresultを含むJSONオブジェクトかを確認する
try:
# When parsing the JSON, strict mode must be disabled to handle badly escaped newlines
# TODO: This is still broken in some cases - AWS needs to double sescape the field contents
output_json = json.loads(output_text, strict=False)
if "instruction" in output_json and "result" in output_json:
output_text = output_json["result"]
except json.JSONDecodeError as e:
pass
# 引用情報を追加する
if len(response["citations"]) > 0:
citation_num = 1
output_text = re.sub(r"%\[(\d+)\]%", r"<sup>[\1]</sup>", output_text)
num_citation_chars = 0
citation_locs = ""
for citation in response["citations"]:
for retrieved_ref in citation["retrievedReferences"]:
citation_marker = f"[{citation_num}]"
citation_locs += f"\n<br>{citation_marker} {retrieved_ref['location']['s3Location']['uri']}"
citation_num += 1
output_text += f"\n{citation_locs}"
st.session_state.messages.append({"role": "assistant", "content": output_text})
st.session_state.citations = response["citations"]
st.session_state.trace = response["trace"]
st.markdown(output_text, unsafe_allow_html=True)
trace_types_map = {
"Pre-Processing": ["preGuardrailTrace", "preProcessingTrace"],
"Orchestration": ["orchestrationTrace"],
"Post-Processing": ["postProcessingTrace", "postGuardrailTrace"]
}
trace_info_types_map = {
"preProcessingTrace": ["modelInvocationInput", "modelInvocationOutput"],
"orchestrationTrace": ["invocationInput", "modelInvocationInput", "modelInvocationOutput", "observation", "rationale"],
"postProcessingTrace": ["modelInvocationInput", "modelInvocationOutput", "observation"]
}
# サイドバーのトレース情報セクション
with st.sidebar:
st.title("Trace")
# 各トレースタイプを個別のセクションに分けて表示する
step_num = 1
for trace_type_header in trace_types_map:
st.subheader(trace_type_header)
# Bedrock コンソールの表示形式に合わせてトレースをステップ単位で整理する
has_trace = False
for trace_type in trace_types_map[trace_type_header]:
if trace_type in st.session_state.trace:
has_trace = True
trace_steps = {}
for trace in st.session_state.trace[trace_type]:
# Each trace type and step may have different information for the end-to-end flow
if trace_type in trace_info_types_map:
trace_info_types = trace_info_types_map[trace_type]
for trace_info_type in trace_info_types:
if trace_info_type in trace:
trace_id = trace[trace_info_type]["traceId"]
if trace_id not in trace_steps:
trace_steps[trace_id] = [trace]
else:
trace_steps[trace_id].append(trace)
break
else:
trace_id = trace["traceId"]
trace_steps[trace_id] = [
{
trace_type: trace
}
]
# Bedrock コンソールのようにトレースステップをJSON形式で表示する
for trace_id in trace_steps.keys():
with st.expander(f"Trace Step {str(step_num)}", expanded=False):
for trace in trace_steps[trace_id]:
trace_str = json.dumps(trace, indent=2)
st.code(trace_str, language="json", line_numbers=True, wrap_lines=True)
step_num += 1
if not has_trace:
st.text("None")
st.subheader("Citations")
if len(st.session_state.citations) > 0:
citation_num = 1
for citation in st.session_state.citations:
for retrieved_ref_num, retrieved_ref in enumerate(citation["retrievedReferences"]):
with st.expander(f"Citation [{str(citation_num)}]", expanded=False):
citation_str = json.dumps(
{
"generatedResponsePart": citation["generatedResponsePart"],
"retrievedReference": citation["retrievedReferences"][retrieved_ref_num]
},
indent=2
)
st.code(citation_str, language="json", line_numbers=True, wrap_lines=True)
citation_num = citation_num + 1
else:
st.text("None")
#### Dockerfileを作成する ####
vi Dockerfile
#### Dockerfileに以下を記載し保存する ####
FROM python:3.12-slim
# remember to expose the port your app'll be exposed on.
EXPOSE 8080
RUN pip install -U pip
COPY requirements.txt app/requirements.txt
RUN pip install -r app/requirements.txt
# copy into a directory of its own (so it isn't in the toplevel dir)
COPY . /app
WORKDIR /app
# run it!
ENTRYPOINT ["streamlit", "run", "app.py", "--server.port=8080", "--server.address=0.0.0.0"]
#### requirements.txtを作成する ####
vi requirements.txt
#### requirementsに以下を記載し保存する ####
boto3>=1.35,<1.36
python-dotenv>=1.0,<2.0
streamlit>=1.41,<2.0
PyYAML>=6.0.2,<7.0
#### フォルダ作成 ####
mkdir services
#### servicesに移動 ####
cd services/
#### bedrock_agent_runtime.pyを作成する ####
vi bedrock_agent_runtime.py
#### bedrock_agent_runtime.pyに以下を記載し保存する ####
import boto3
from botocore.exceptions import ClientError
import logging
logger = logging.getLogger(__name__)
def invoke_agent(agent_id, agent_alias_id, session_id, prompt):
try:
client = boto3.session.Session().client(service_name="bedrock-agent-runtime", region_name='us-east-1') # リージョン名を設定する
response = client.invoke_agent(
agentId='xxxxxxxxxx', # 自分が作成したAgent IDとすること
agentAliasId='xxxxxxxxxx', # 自分が作成したAgent Alias IDとすること
enableTrace=True,
sessionId=session_id,
inputText=prompt
)
output_text = ""
citations = []
trace = {}
has_guardrail_trace = False
for event in response.get("completion"):
# チャンクを結合して出力テキストを生成する
if "chunk" in event:
chunk = event["chunk"]
output_text += chunk["bytes"].decode()
if "attribution" in chunk:
citations += chunk["attribution"]["citations"]
# すべてのイベントからトレース情報を抽出する
if "trace" in event:
for trace_type in ["guardrailTrace", "preProcessingTrace", "orchestrationTrace", "postProcessingTrace"]:
if trace_type in event["trace"]["trace"]:
mapped_trace_type = trace_type
if trace_type == "guardrailTrace":
if not has_guardrail_trace:
has_guardrail_trace = True
mapped_trace_type = "preGuardrailTrace"
else:
mapped_trace_type = "postGuardrailTrace"
if trace_type not in trace:
trace[mapped_trace_type] = []
trace[mapped_trace_type].append(event["trace"]["trace"][trace_type])
except ClientError as e:
raise
return {
"output_text": output_text,
"citations": citations,
"trace": trace
}
#### project-rootに戻る ####
cd ..
#### yumアップデート ####
yum update -y
#### dockerインストール ####
yum install -y docker
#### docker起動 ####
systemctl start docker
#### docker有効化 ####
systemctl enable docker
#### dockerのインストール確認(バージョンが出力する)####
docker --version
Docker version 25.0.8, build 0bab007
#### dockerビルド ####
docker build -t hotel-reservation-app .
#### docker起動 ####
docker run -d -p 8501:8080 --name hotel-reservation hotel-reservation-app
ターゲットの登録
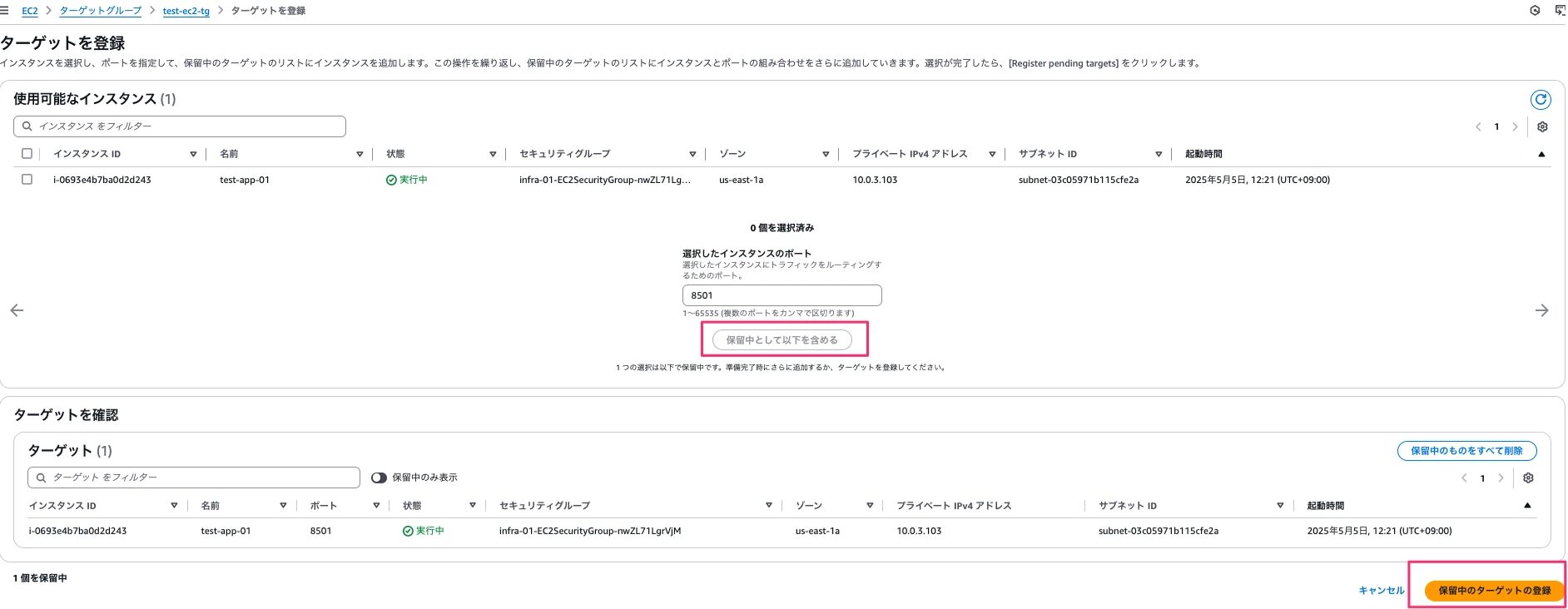
CloudFormationで作成したターゲットグループでターゲットの登録をします。EC2→ターゲットグループ→test-ec2-tg→ターゲットを登録から保留中として以下を含めるボタンを押下します。押下するとターゲットを確認にターゲットが設定されます。最後に保留中のターゲットの登録ボタンを押下します。
ターゲットの登録後、ヘルスステータスがHealthy状態になることを確認します。
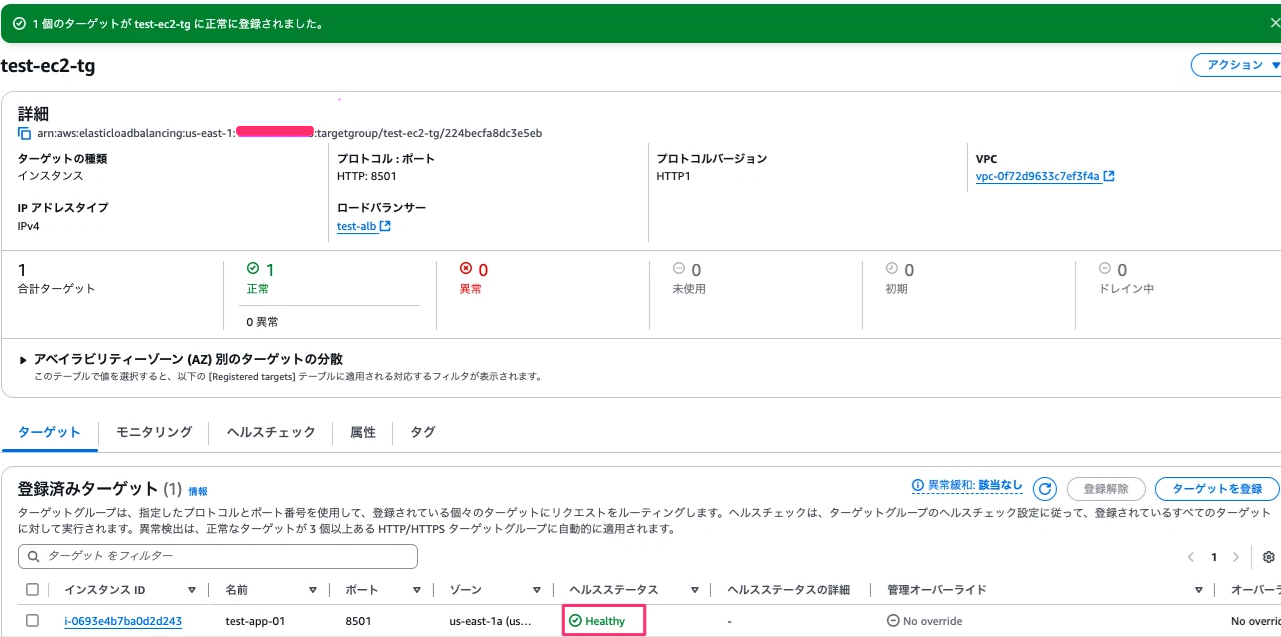
これでアプリの設定は完了です。次が最後です。アプリの稼働確認をします。
アプリの稼働確認
ALBのDNS値をコピーしブラウザに入力します。
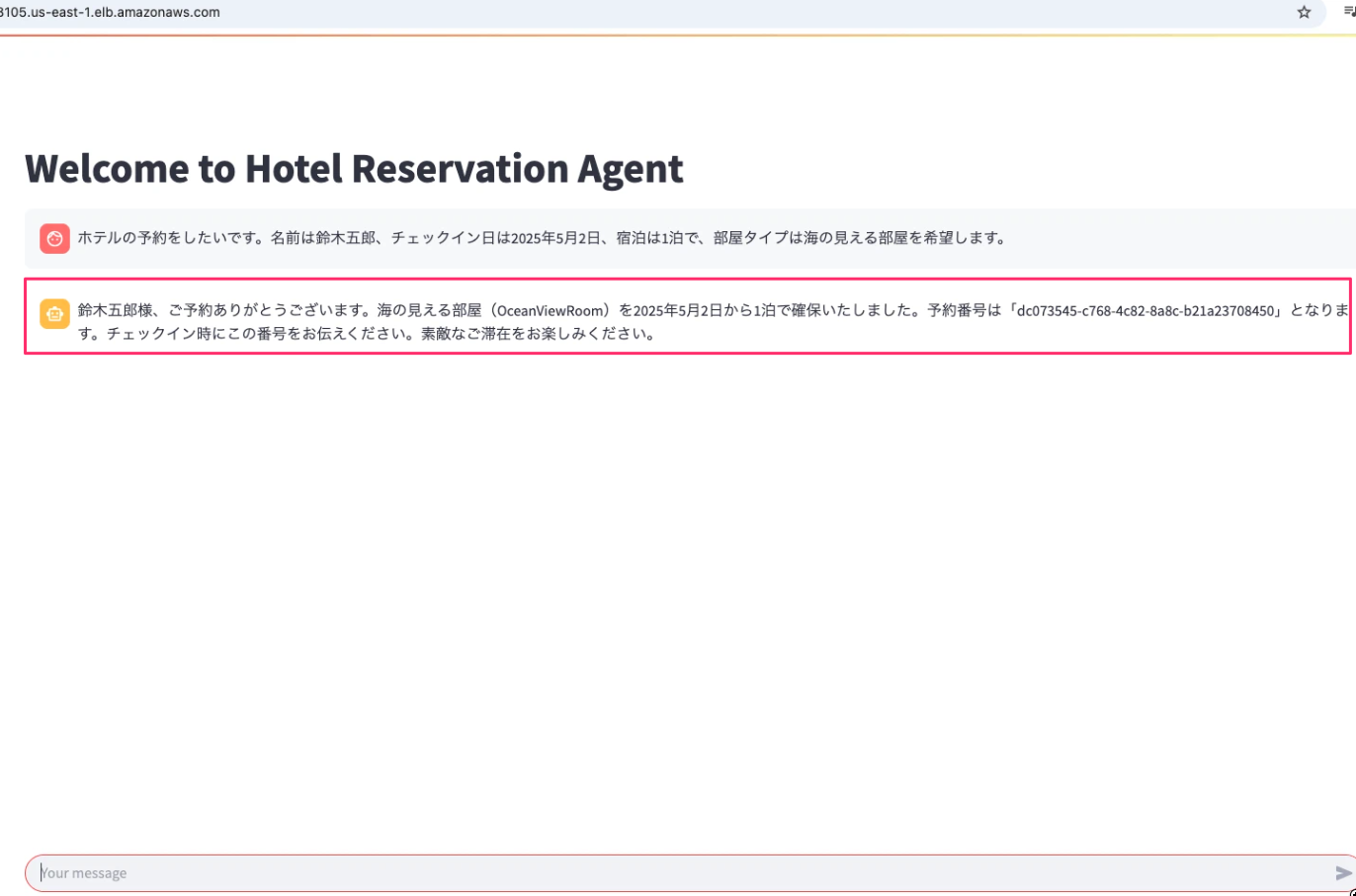
「ホテルの予約をしたいです。名前は鈴木五郎、チェックイン日は2025年5月2日、宿泊は1泊で、部屋タイプは海の見える部屋を希望します。」と入力しました。空きがあるので問題なく予約ができました。
次は代替案を提案してもらってから予約をします。
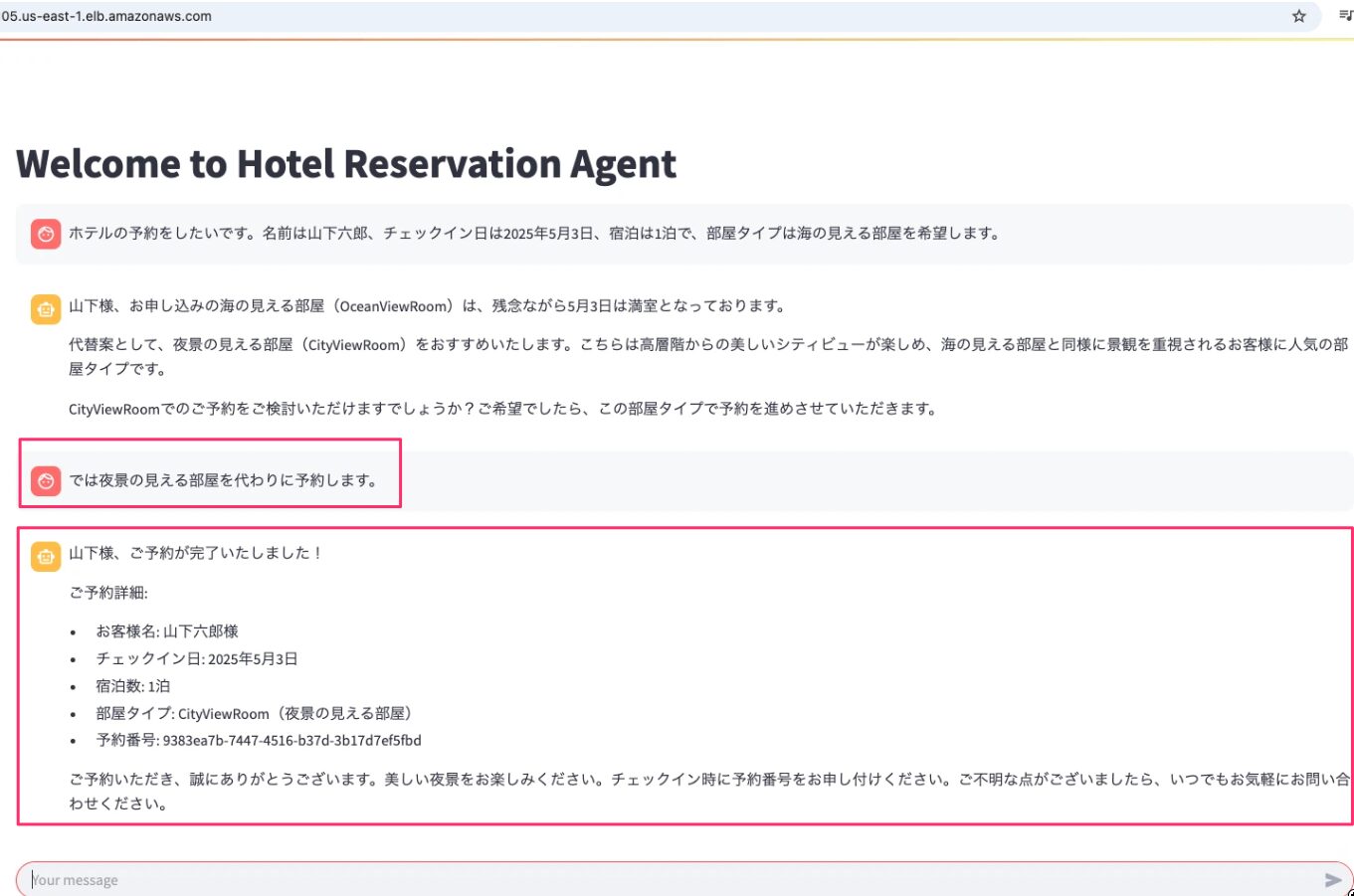
「ホテルの予約をしたいです。名前は山下六郎、チェックイン日は2025年5月3日、宿泊は1泊で、部屋タイプは海の見える部屋を希望します。」と入力し、代替案に対して「では夜景の見える部屋を代わりに予約します。」と入力しました。こちらも問題なく予約ができました。
DynamoDBのテーブルを確認します。
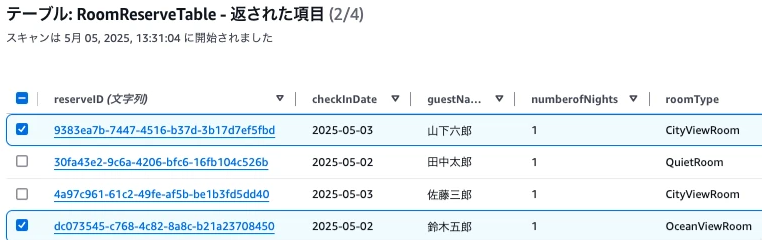
正しく2つのデータが追加されていることができました。
これでアプリ経由からも正しく予約、代替案の提示からの予約が確認できました。稼働確認が終わりましたので、リソースの削除についても簡単に記載しておきます。
リソースの削除
アプリ用インフラの削除
CloudFormationのスタックを削除します。
Bedrockエージェントの削除
エージェントを削除します。
Bedrockナレッジベースの削除
ナレッジベースを削除します。

Lambda関数の削除
アクショングループで使用していたLambdaを削除します。
DynamoDBのテーブル削除
空室情報テーブル、予約テーブルを削除します。
OpenSearchのコレクション削除
ベクトル検索でOpenSearch Serverlessを選択していたので、コレクションが作成されています。これも削除します。
S3の削除
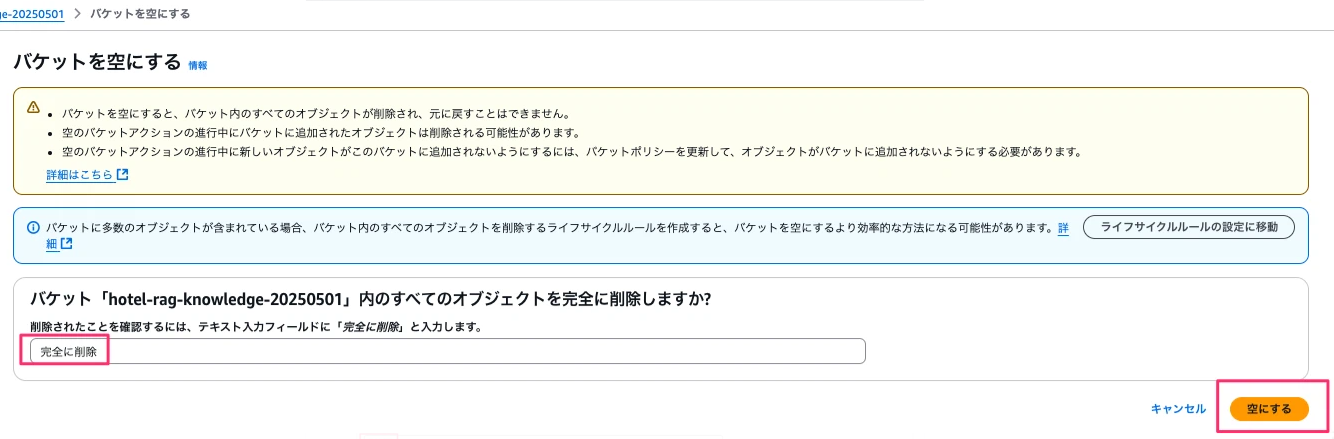
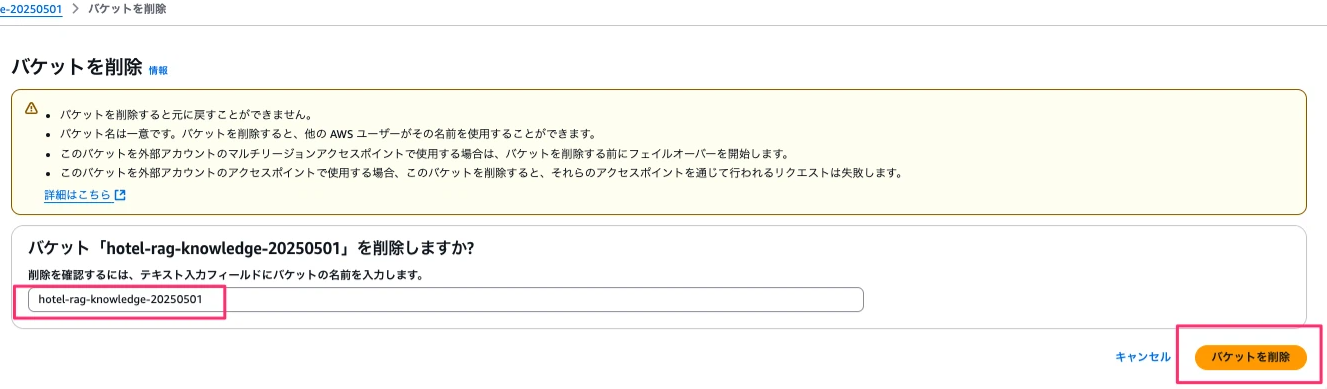
RAG用に作成したS3を削除します。バケット内を空にした後、バケットを削除します。
その他リソース
Bedrockエージェント、Lambda作成にあたりIAMロールが作成されていますので、適宜削除します。
終わりに
生成AIと連携した予約支援機能を構築してみての感想ですが、アプリのあり方が変わるかもしれないと感じました。例えば、従来の予約システムであればユーザーが「正確に操作しないとたどり着けないUI」が前提でした。
ただ、生成AIを導入すれば、ユーザーが自然な言葉を投げかけ、それをシステムが解釈して対応するという体験に変わります。
つまり、「人がシステムに合わせる」から「システムが人に寄り添う」形になります。これは予約アプリに限らず、さまざまな業務アプリやWebサービスにも応用されていくような気がします。
本記事が生成AIとアプリの連携を検討する際のヒントになれば幸いです。


