この記事について
Amazon Bedrockでお馴染みの、Knowledge Bases for Amazon Bedrock(以下Knowledge Baseと表記)という機能と、Agents for Amazon Bedrock(以下Agentsと表記)という機能を使用して、Streamlitと組み合わせたチャットボット構築を試してみた記事です。
前編である本記事では、Knowledge Base・Agentsの基礎的な概念やチャットボットの全体像についてお伝えできればと思います。
用語解説
Knowledge Base
「Management Consoleから、RAGの仕組みを実装し、アプリケーションに組み込むエンドポイントを作成できる」Amazon Bedrockの一機能のことです。
全体像はこんな感じです。
図中の Knowledge Bases for Amazon Bedrockの枠で囲まれている箇所が Knowledge Basesが担う役割であり、RAGの枠組みを作るための縁の下の力持ち、といった位置付けになると言えます。
これによって、APIにリクエストを送る(プロンプトを送る)だけで簡単にRAGが実現できるようになります。
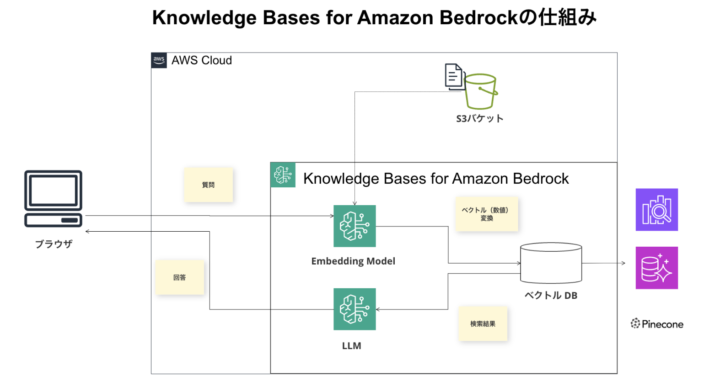
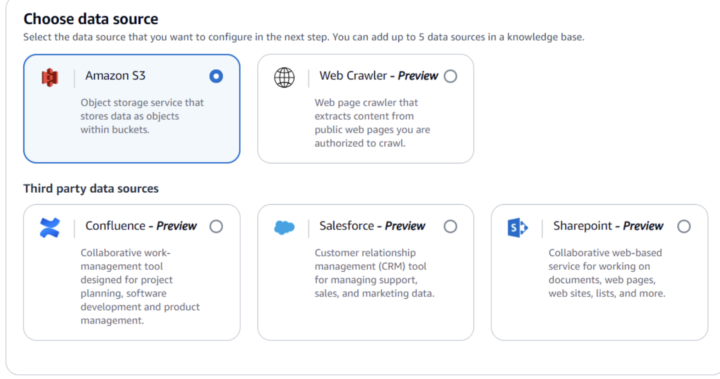
また、データソース(ナレッジベースの元となる情報の格納先)はS3がサポートされているようです。
※Webクローラーや、Confluence, Salesforce, Sharepointなどサードパーティのデータソースも指定ができるとの記載がありますが、現状ではPreviewとなっているようです。
試しにPineconeをベクトルDBにした上で、データソースをWebクローラーにした場合、OpenSearchしかデータソースに指定できない、というエラー表示が出ていたのでまだまだ制約はあるようです。
Agents
「生成AIに意思を持たせ、自律してタスクをこなすようにする仕組みを作る」ためのAmazon Bedrockの一機能となります。なお、Agentsの機能はAmazon Bedrockに限った話ではなく、LangChain Agents(LangChain)やVertex AI Agents(Google Cloud)など、他の生成AIプラットフォームでも使われている機能となります。
Knowledge Baseと関連付けを行うことで、パフォーマンス向上につながります。
また、Action Groupと呼ばれるものを定義してやることで、特定なユーザーが「やってくれたらいいな」というタスクを実行できるように設定することができます。詳しくは後編で触れます。
Streamlit
 (画像はStreamlit公式が提供しているサンプルアプリケーションをデプロイしたもの)
(画像はStreamlit公式が提供しているサンプルアプリケーションをデプロイしたもの)
Pythonを用いて簡単にフロントエンドを構築できるOSSのライブラリです。
図表の描画から、LLMを使ったチャットボットの構築まで幅広く使われるようです。
Githubアカウントがあれば、Streamlit Community Cloudというクラウドサービス上に作成したアプリケーションをデプロイすることができます。
Pinecone
 (画像は公式サイトより引用)
(画像は公式サイトより引用)
OSSのベクトルDBです。
Knowlede Baseを構築する際、OpenSearch、Aurora(PostgreSQL pgvector)、MongoDBなどと同様に、ベクトルDBとして選択できるようになっています。
使用する際は、AWS Marketplace経由でサブスクリプションの申し込みが必要です。(従量課金制のプランを選択すれば、購入自体に費用はかかりません)今回作成したRAGチャットボットにも組み込みました。(詳細は後編で触れます。)
後にも触れますが、Pineconeには無料プランもあり、安価にベクトルDBを構築したい場合には便利かもしれません。
※余談ですが、日本語ではPineconeは松ぼっくり、という意味らしいです。
ベクトルインデックス(Vector index)
ベクトルデータベースには、あるデータが、コンピューターが計算しやすいように数値化されたもの(Embedding)が保存されますが、人間の世界同様、情報を整理しておかなければ正確かつ早い検索は実現できません。そこで使用されるのがベクトルインデックスです。
似たもの同士を一緒にし、情報整理をしてくれるものだと考えるとわかりやすいのではないでしょうか。
詳細にはK-meansクラスタリングと呼ばれるような機械学習の技術が使われていたりと、複雑な機械学習のロジックが使用されているようです。単純化のため、ここでは触れません。
今回作成したものの全体像
今回作成したRAGチャットの構成はこのような形です。
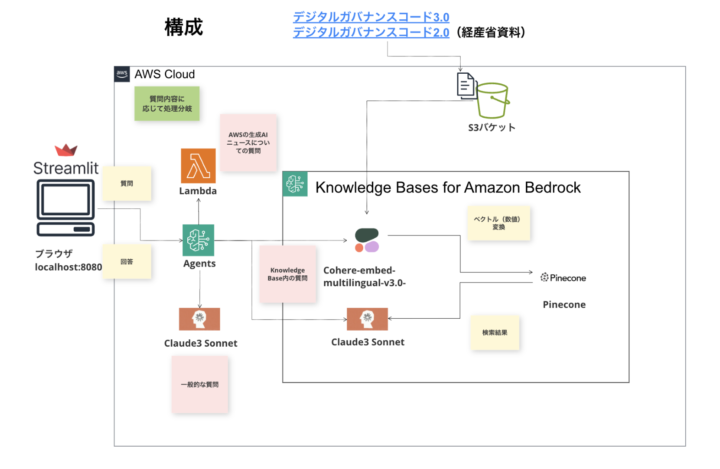
ここで行っていることとしては以下になります。
- ナレッジベースのデータに関する質問は、ナレッジベースの情報に基づいて回答する
- 特定のタスクに関する指示があれば、AgentがLambda関数のトリガーとなり、処理を行わせて回答させる
- ナレッジベース外、かつタスクに無関係な質問や指示は、LLMのもつ一般的な知識で回答させる。
前編まとめ
Amazon Bedrock Knowledge Bases/Agentsと Streamlitを使ったRAGチャットボット構築(前編)ということで、今回は用語解説を中心に行いました。
後編では、実際にRAGチャットボット作成の過程をご紹介できればと思います。後編もお楽しみに。


