
この記事のポイント : 本記事では Datadog APM の 「分散トレーシングの基本 → 収集のはじめ方 → トレース画面の見方 → ボトルネック特定」の流れで解説します。APMを初めて触る方、まずは“最短で見える化”したいチームにおすすめです。
はじめに
Datadog APM(Application Performance Monitoring)は、アプリケーションの処理をトレース(Trace)として可視化し、どのサービス/処理(スパン)が遅いのかを一目で把握できます。メトリクスやログとあわせることで、インシデント初動の「何が遅いか」「どこが詰まっているか」を素早く特定できます。
現場では次のつまずきが典型です。
- Agent は入れたが APMがOFF のままでトレースが来ていない
- サービス名や環境タグがバラバラで比較できない
- トレース画面でどこから見ればよいか分からない
本記事はそれらを避けるための“最小構成の実践書”です。ゼロ→イチでトレースが見えるところまでをまとめました。
前提・動作環境
- Datadog アカウント(US/EU いずれか)
- Datadog Agent 導入済み(Linux/Windows/コンテナ環境のいずれか)
- 対象アプリに対応する Datadog トレーサー(例:Python
ddtrace、Node.jsdd-trace、Java エージェントなど) - タグ命名の指針:
env/service/versionを統一(例:env:prd、service:myapp)
ポイント:タグは最初に決めて固定すると比較と運用が安定します。
トレース収集の有効化 3 ステップ(Linux / Windows / Docker・Kubernetes)
Step 1|AgentでAPMをON
編集するファイル/設定のデフォルト配置先(フルパス)
Linux:/etc/datadog-agent/datadog.yaml
Windows:C:\ProgramData\Datadog\datadog.yaml
# /etc/datadog-agent/datadog.yaml(Linux)
apm_config:
enabled: true
# C:\ProgramData\Datadog\datadog.yaml(Windows)
apm_config:
enabled: true
Docker(コンテナ化Agent):
# 代表例(環境変数でAPMを有効化)
-e DD_APM_ENABLED=true
# APM ポート(8126/tcp)公開が必要な場合あり
-p 8126:8126
Kubernetes(Helm):
# values.yaml の最小例
datadog:
apm:
enabled: true
tags:
- env:prd
- service:myapp
agents:
containers:
agent:
ports:
- name: traceport
containerPort: 8126
Step 2|アプリ側にトレーサーを導入
Python:
pip install ddtrace
DD_SERVICE=myapp DD_ENV=prd ddtrace-run python app.py
Node.js:
npm i dd-trace
# エントリで初期化(最上部で require)
// index.js(最上部)
const tracer = require('dd-trace').init()
const express = require('express')
// 以降、通常どおりにアプリを起動
Java(Java エージェント):
# dd-java-agent.jar を配置して起動オプションに付与
java -javaagent:/path/to/dd-java-agent.jar \
-Ddd.service=myapp -Ddd.env=prd \
-jar app.jar
Go(例):
go get gopkg.in/DataDog/dd-trace-go.v1/ddtrace/tracer
import "gopkg.in/DataDog/dd-trace-go.v1/ddtrace/tracer"
func main() {
tracer.Start(tracer.WithServiceName("myapp"))
defer tracer.Stop()
// アプリ本体...
}
補足:
DD_SERVICE/DD_ENV/DD_VERSIONを統一命名にすると、比較とリリース前後の差分確認が簡単になります。
Step 3|取り込み確認(まずは“届いているか”)
- Datadog UI → APM → Traces タブで、左ペインの検索バー(Search for)に
service:myappを入力し、最新トレースが表示されることを確認します。
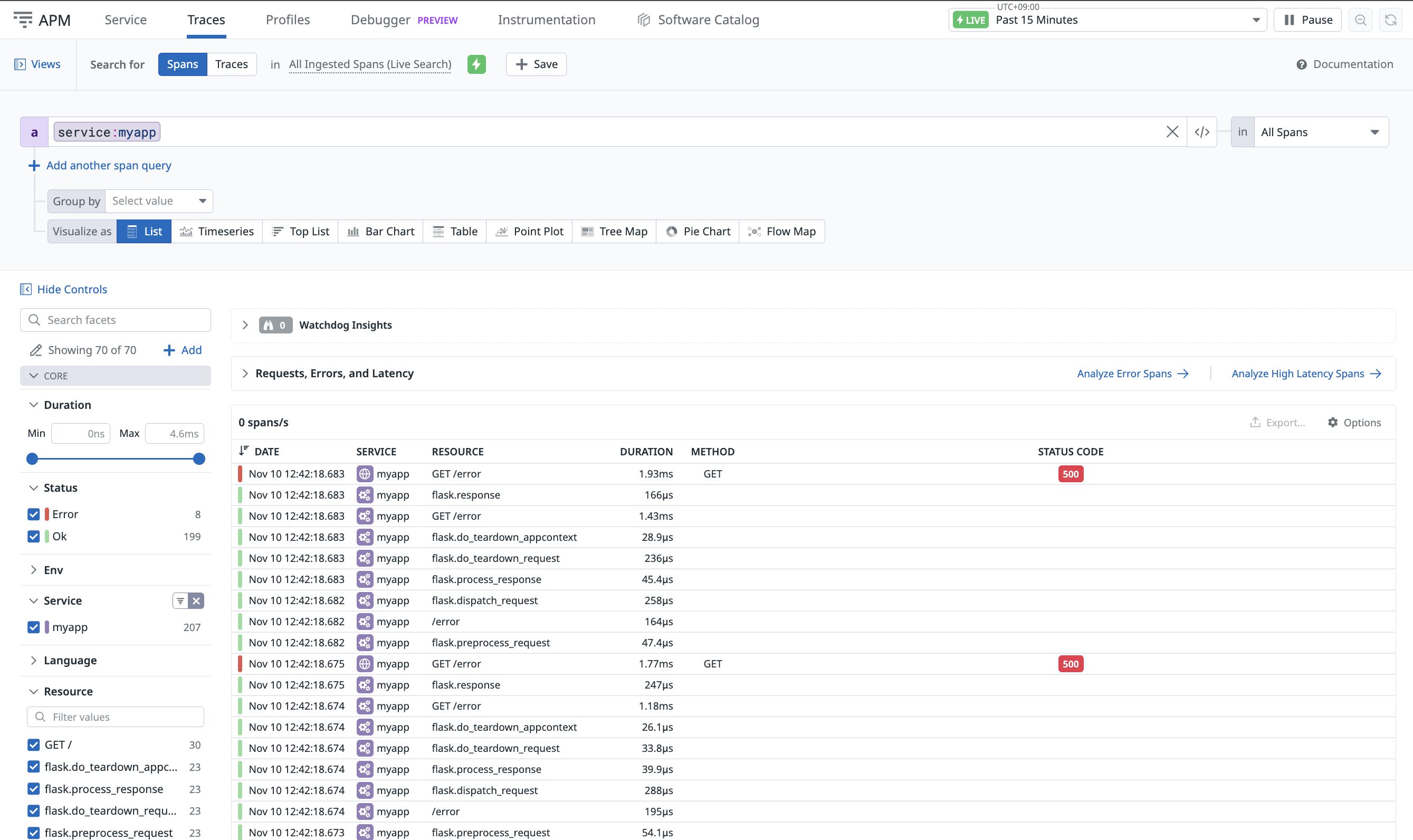
service:myapp」を指定)Tips:最初は簡単なエンドポイントを1回呼んでトレースを発生させると確認が早いです。
トレース画面の見方(ボトルネック特定の基本)
まず押さえる用語は2つです。
- トレース(Trace):1つのリクエスト全体の処理の流れ
- スパン(Span):トレース内の個々の処理(DBクエリ、外部API、関数など)
主な画面セクション
- トレース一覧:左ペインの一覧(Service / Status / Duration)で、遅延やエラーのあるトレースを選択
- トレース詳細(Flame Graph / Waterfall):中央の紫色バーでスパンごとの処理時間を確認(横に長いスパン=ボトルネック候補)
- サービスマップ:上部の「Map」タブで、サービス間の依存関係を俯瞰
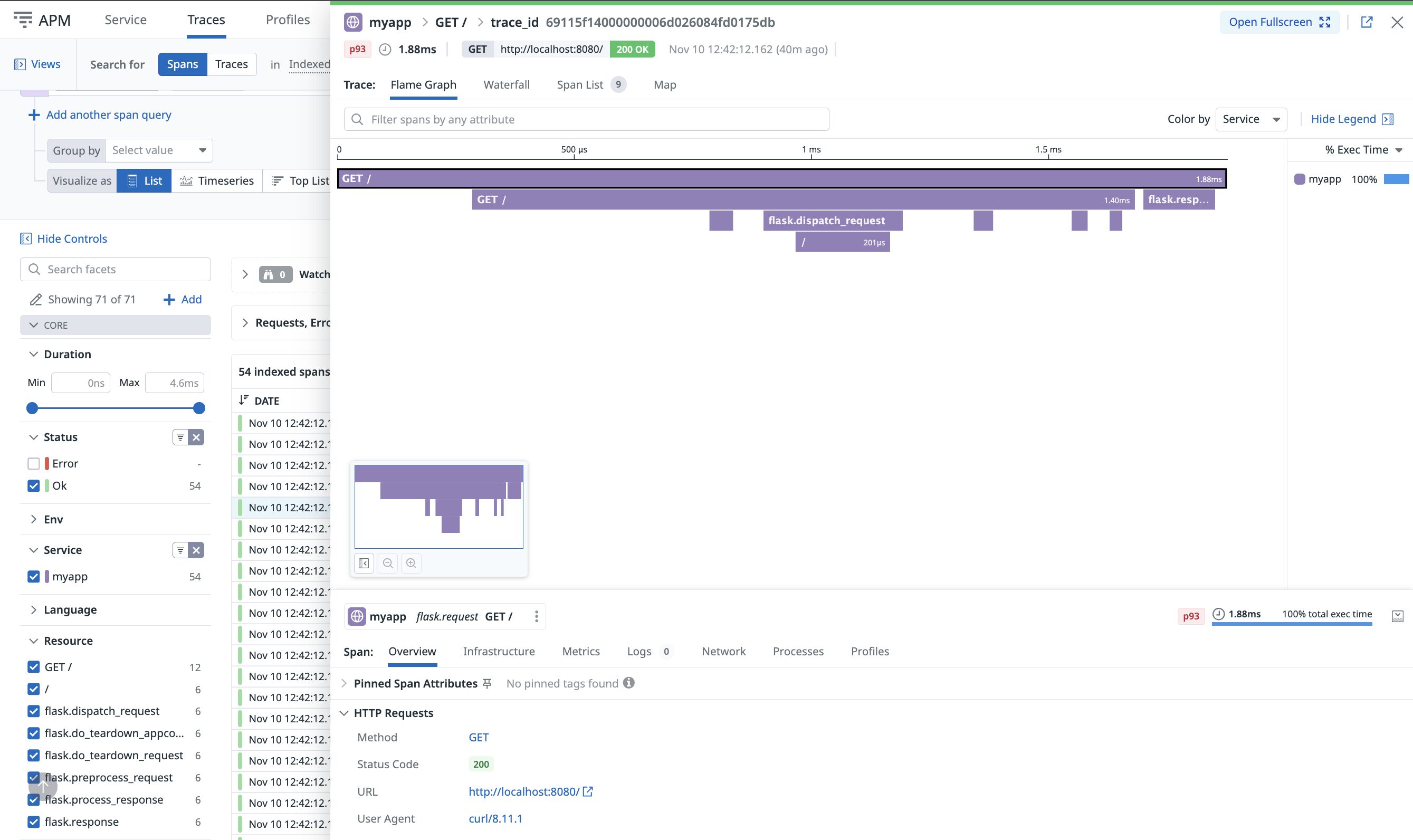
実際の特定フロー(最短3ステップ)
- トレース一覧から遅延が大きいものを開く(必要に応じて
status:errorを併用) - Flame Graph(または Waterfall)のタイムラインで最も長いスパンを特定
- 該当スパンの詳細(タグ、外形情報)を確認:DBならクエリ、外部APIなら宛先やリトライ、内部処理なら関数名など
コツ:「長いスパン」が1つだけならそこが改善ポイント。複数サービスで長いなら、サービスマップで依存関係を確認します。
検索クエリ/フィルタ例(コピペで使える)
よく使う属性(Search for クエリに入力):service, env, operation, resource, status(error など)
サービス × 環境:
service:myapp env:prd
エラーを含むトレース:
status:error service:myapp
遅いトレースに集中:(UI上はソートで「遅延の大きい順」)
service:myapp duration:>=1000
リリース前後の比較:
service:myapp env:prd version:1.2.0
Tips:APMの検索では
status:errorを使用します(error:trueは Logs 用です)。
最小の運用Tips(まずはこれだけ)
- タグ統一:
service/env/versionを必ず送る(命名を固定) - 週次レビュー:Traces の遅延上位をチームで10分見る → 改善タスク化
- ダッシュボード連携:トレース関連のウィジェットを1枚に集約し、入口を共通化
ミニTips:ログ・メトリクスとの往復が強力です。トレース詳細からログに飛び、該当時刻のエラー内容を確認しましょう。
つまずきポイントと対処
- トレースが来ない:Agent 側の
apm_config.enabled: true/コンテナはDD_APM_ENABLED=true、アプリ側トレーサー初期化とDD_SERVICE等を再確認 - サービス名が増殖:命名規則の揺れ(大文字小文字、ハイフン/アンダースコア)を排除。設定を1か所に寄せる
- どこを見ればよいか:「遅延ソート → 長いスパン → 詳細タグ」の順で3クリック
まとめ
Datadog APM は、アプリケーションの処理を“見える化”するうえで最も即効性のある機能です。
たとえば service:myapp のトレースを開き、Flame Graph 上で「一番長いスパン」を探すだけでも、遅延の正体がはっきり見えてきます。
導入のポイントはシンプルで、まずは Agent 側で APM を ON にし、トレーサーを導入、そして Traces タブで到着を確認。
週に一度、チームで遅延上位のトレースを見直すだけでも、パフォーマンス改善の糸口は必ず見つかります。
私自身も、ログやメトリクスだけでは気づけなかった「特定ルートの遅延」や「リリース後の劣化」を、トレースで初めて捉えられた経験があります。
APM を“継続的に見る文化”をチームに根づかせることが、最短で成果につながる第一歩だと感じています。


