
こちらの記事はAWS Top Engineerのクラウドインテグレーション事業部 クラウドコンサルティングセクション 松田 啓佑さんに監修していただきました。
はじめに
突然ですが、社内の膨大な資料の中から必要な情報を一瞬で見つけ出すことができたら、仕事はもっと効率的になりますよね。そこで、今回ご紹介するのは、AWSのインテリジェントな検索サービスAmazon Kendraです。
私が今回Amazon Kendraのファセット検索について学ぶきっかけとなったのは、アサインされた案件でこの機能に触れる機会があったものの、既に設定が完了していたため、仕組みや機能を深く理解できていなかったからです。
そこで、今回のブログ執筆を通して、Amazon Kendraを一から設定することで、私自身の理解力向上とAWSコンソール操作に慣れることを目的にしています。このハンズオンと解説が、皆さんのAmazon Kendraに対する理解を深める一助となれば幸いです。
Amazon Kendraとは?
そもそもAmazon Kendraとは?
一言でいうと機械学習(ML)を用いた、インテリジェントな検索サービスです。これではまだ難しいので、ここからAmazon Kendraの特徴について解説していきます。※詳細は公式ドキュメントをご覧ください。
1. 生成AIを活用した会話体験の提供
Kendra Retriever APIという、RAG(AIが解答の根拠となる資料を見つけて回答を生成する仕組み)ワークフローを最適化し、ユーザーの質問に最も関連する内容をエンタープライズコンテンツ(社内の資料やデータ)を見つけてくれるAPIを活用して、自然言語による質問に対しても高精度な検索サービスを提供します。さらに、Amazon Kendraは高度な専門知識がなくても、高精度のAIチャットを導入できる点は大きな特徴です。
2. インテリジェントな検索も可能
Amazon Kendraはユーザーの質問に対して、該当する資料を見つけるだけではなく、質問の意味を理解してユーザーの求める答えを返してくれます。例えば、「新卒社員は有給は何日ある?」という質問に対しては関連資料を見つけるだけでなく、「12日」という的確な回答を返してくれます。また、ユーザーの質問と最も似ているよくある質問とマッチさせて回答を返すこともできます。さらに表からもデータを抽出して回答することもできます。
3. ビジネス用語や専門用語の理解度が高い
ユーザーはAmazon Kendraにカスタムシノニムを設定することができ、ビジネス用語への理解を深めさせることができます。カスタムシノニムにより、Amazon Kendraはクエリを自動で拡張して一致したコンテンツを回答に含めます。例えば、「SLAとはなんですか?」と質問すると、Amazon Kendraは「Service Level Agreement」と「SLA」で検索をしてくれます。
Amazon Kendraの料金体系
Amazon Kendraではインデックスを作成した時点で料金が発生します。注意すべき点としては、インデックス内のストレージ容量やクエリ容量に関わらずインデックスを作成し、稼働を開始した時点から課金されるという点です。
また、現在Amazon Kendraでは以下の3つのインデックスタイプを提供しています。※料金体系は2025年10月時点のものです。
1. Basic Developer Edition
- ベースインデックスの料金は1時間あたり、1.125USD。
- 追加のストレージユニット、クエリユニットはなし。
- 開発や検証などの小規模なプランにおすすめ。
2. Basic Enterprise Edition
- ベースインデックスの料金は1時間あたり、1.4USD。
- 追加のストレージユニット、クエリユニットは両方とも1時間あたり0.7USD。
- 大規模な本番環境におすすめ。
3. GenAI Enterprise Edition
- ベースインデックスの料金は1時間あたり、0.32USD。
- 追加のストレージユニットは0.25USD、クエリユニットは0.07USD。
- コネクタは1インデックスあたり月30USD。
- RAG機能を使用する企業におすすめ。
Basic Developer EditionもしくはGenAI Enterprise Editionなら最初の30日間、最大750時間の無料利用枠が提供されています。
Amazon Kendraのファセット機能とは?
ファセット機能とは、検索結果のドキュメントに設定されているメタデータを使ってユーザーが検索結果を絞り込むための機能です。
社内ドキュメントには作成者や作成日、カテゴリ、プロジェクト名などの属性情報が設定されています。ユーザーが検索するとAmazon Kendraがこれらの属性情報を集計して検索結果の横やサイドバーに表示します。この絞り込み機能のことをファセット機能と呼びます。この後、よりイメージが沸くように実際にファセット機能を実装したハンズオンを解説していきたいと思います。
Amazon Kendraのファセット機能を1から試してみた
始める前に、前述のようにAmazon Kendraではインデックスを作成した時点で課金されるので検証等で長期間使わない際は削除するのを忘れないようにしましょう。
※初めてコンソールを触ったので、自身の勉強のためにもできるだけ細かく手順を解説します。少々長くなりますが、ご了承ください。
【ステップ1】
はじめにメタデータの付与とファセットの準備をするために今回ドキュメントを保管するデータソースとなるS3にバケットiret-dx-shinoharaを作成します。
【ステップ2】
作成したバケットにファセット対象となるドキュメントをアップロードする。今回はAWS認定資格のSAAとSOAの試験ガイド(PDF)の2つをアップロードする。(写真はSAAのアップロード画面のみ)
【ステップ3】
ファセット機能を使うためにAttributeFilter(属性フィルタ)用のmetadataフォルダを作成する。
AttributeFilter用のmetadataフォルダを作成する理由は、Amazon Kendraが検索対象のドキュメント(ファイル)に付加された属性情報を認識し、検索の絞り込みに利用できるようにするためです。metadataフォルダは、ドキュメント本体のファイルとそのドキュメントに関する属性情報ファイルを分けて格納するために使われます。
【ステップ4】
metadataフォルダにSAAとSOAのファイルをアップロードする。その際に、拡張子を.pdf.metadata.jsonとするように注意しましょう。理由はAmazon Kendraが明確にメタデータを教えて元データと紐付けるためです。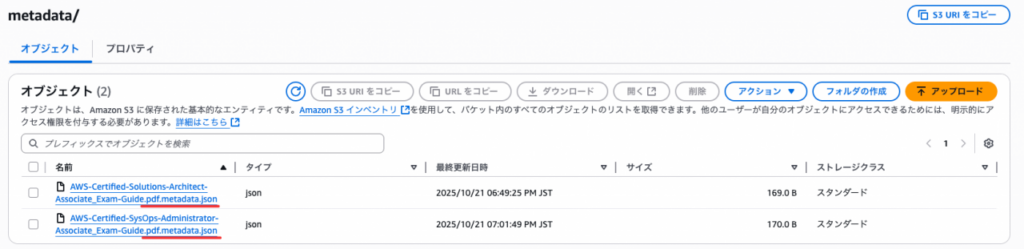
【ステップ5】
適当にフォルダを作成してVS Codeで開き、以下の内容でJSONファイルを作成します。そしてSAAとSOAのファイルをアップロードします。この際、ファイルはステップ4でアップロードしているのと同じ、.pdf.metadata.jsonの拡張子がついていることを確認しましょう。また、DocumentIdは元ドキュメントのS3 URIを指定します。元ドキュメントなので.pdf.metadata.jsonではないことに注意しましょう。
※今回はカテゴリのみでファセット機能を利用するのでAttributesには_categoryのみ付与しています。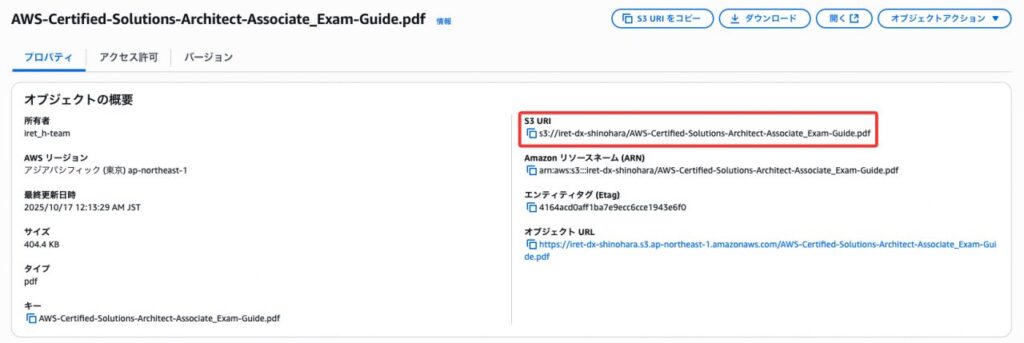
SAAの場合はカテゴリAとします。
{
"DocumentId": "s3://iret-dx-shinohara/AWS-Certified-Solutions-Architect-Associate_Exam-Guide.pdf",
"Attributes": {
"_category": "カテゴリA"
}
}
SOAの場合はカテゴリBとします。
{
"DocumentId": "s3://iret-dx-shinohara/AWS-Certified-SysOps-Administrator-Associate_Exam-Guide.pdf",
"Attributes": {
"_category": "カテゴリB"
}
}
これでメタデータの付与とファセットの準備は完了です。
【ステップ6】
はじめにAmazon Kendraでインデックスの作成をします。Index nameはiret-index-shinoharaで、IAM RoleはCreate a new role(Recommended)を選択してRole nameをAmazonKendra-ap-northeast-1-test-index-role-iret-shinoharaにします。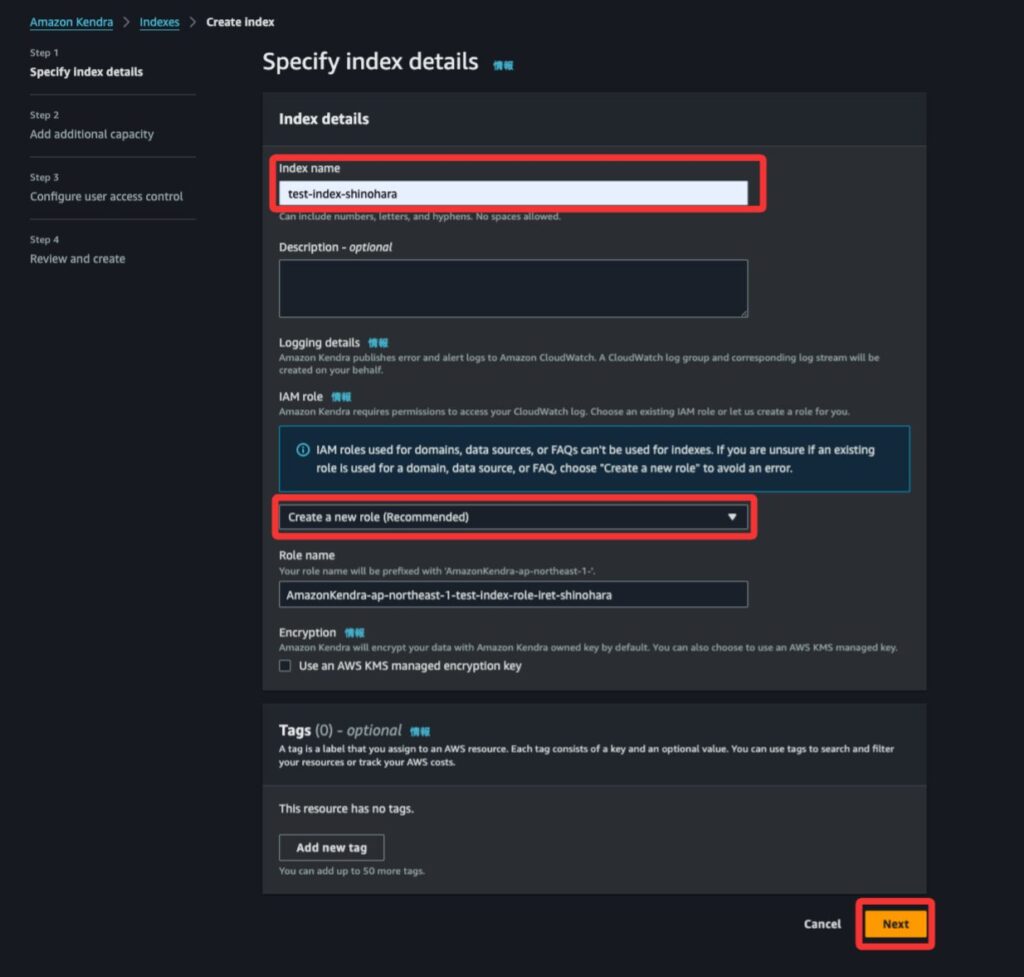
【ステップ7】
残りはデフォルトのままで設定します。最後の確認画面まで行ったら、Createを押下します。Createを押下して数秒待つと自動で画面遷移して作成が開始されます。(今回は15分ほど作成にかかりました。)※Editionsは検証のため、安い方のDeveloper editionを選択しました。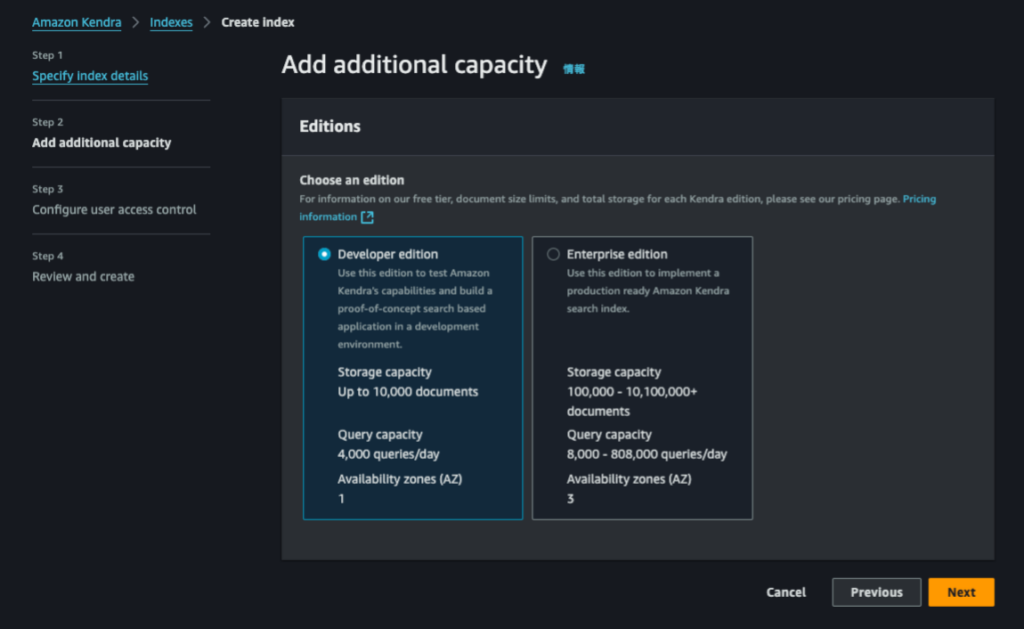
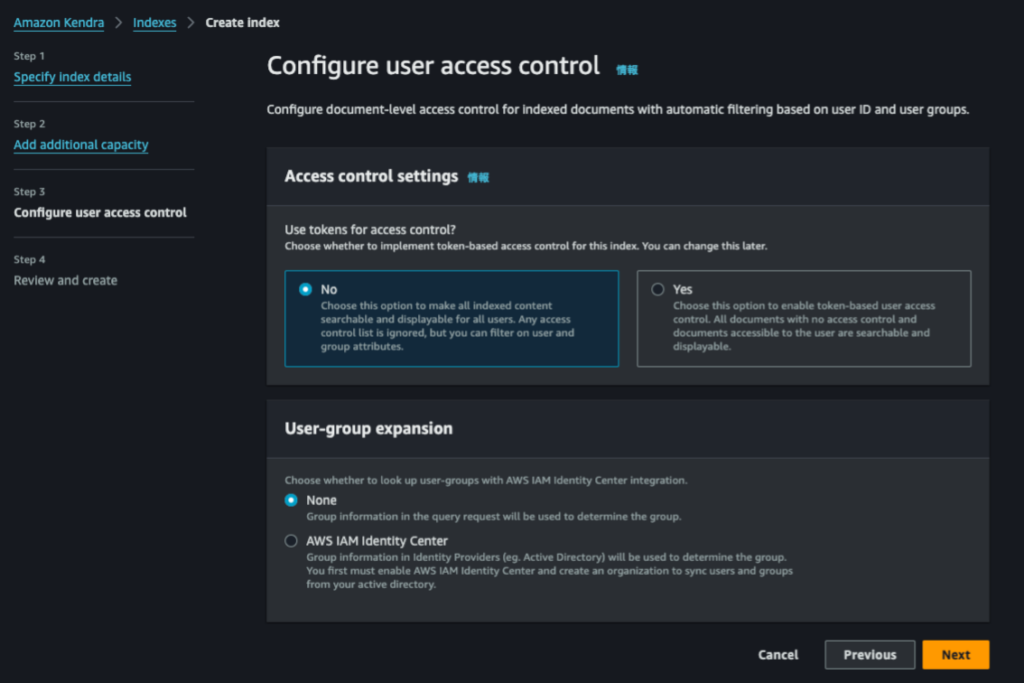
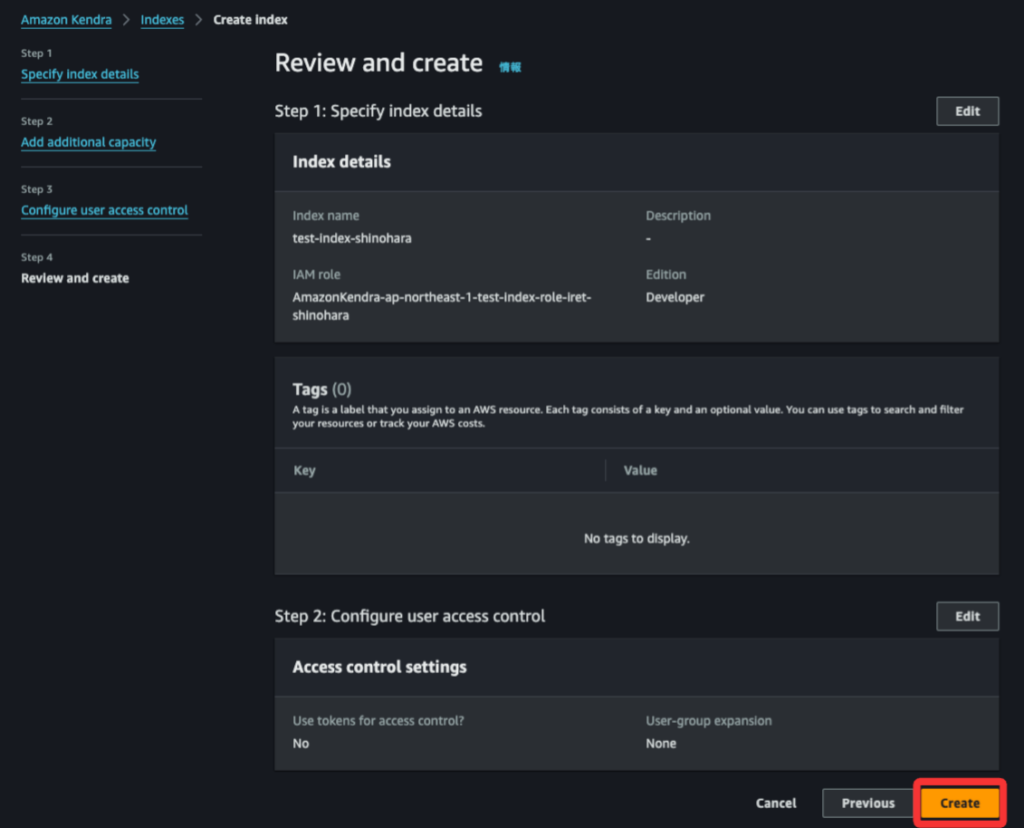
Indexが無事、作成されました。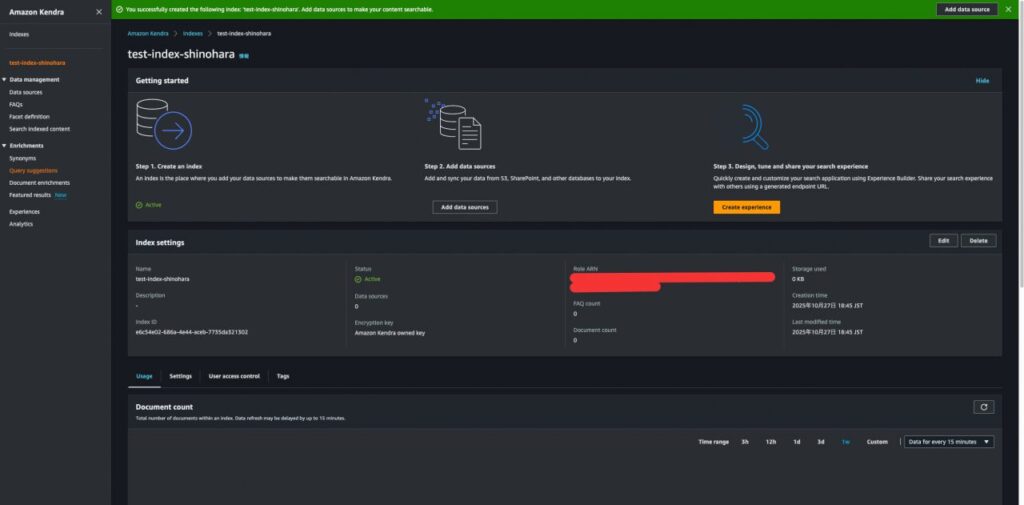
【ステップ8】
次にData Sourceの設定をします。今回はAmazon S3をData Sourceとして設定します。
Amazon KendraではData Sourceとして多くのコネクタを提供しています。例えば、Microsoft SharePoint、Salesforce、ServiceNow、Google ドライブ、Confluence などがあげられます。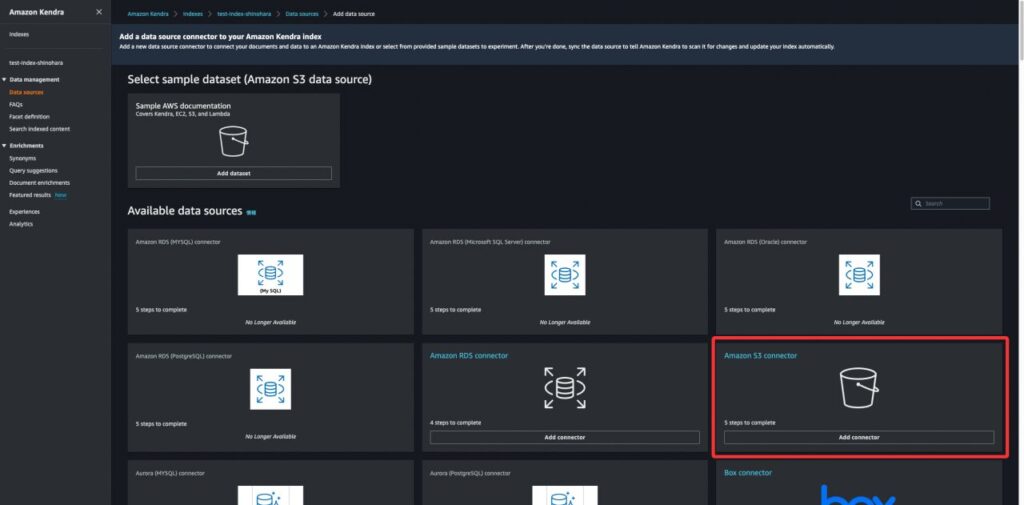
【ステップ9】
Data Source Nameをtest-shinohara-data-sourceにします。Default language of source documentsはAmazon S3にアップロードしたドキュメントの言語を設定します。今回はSAAとSOAの日本語の試験ガイドをアップロードしたのでJapaneseを選択します。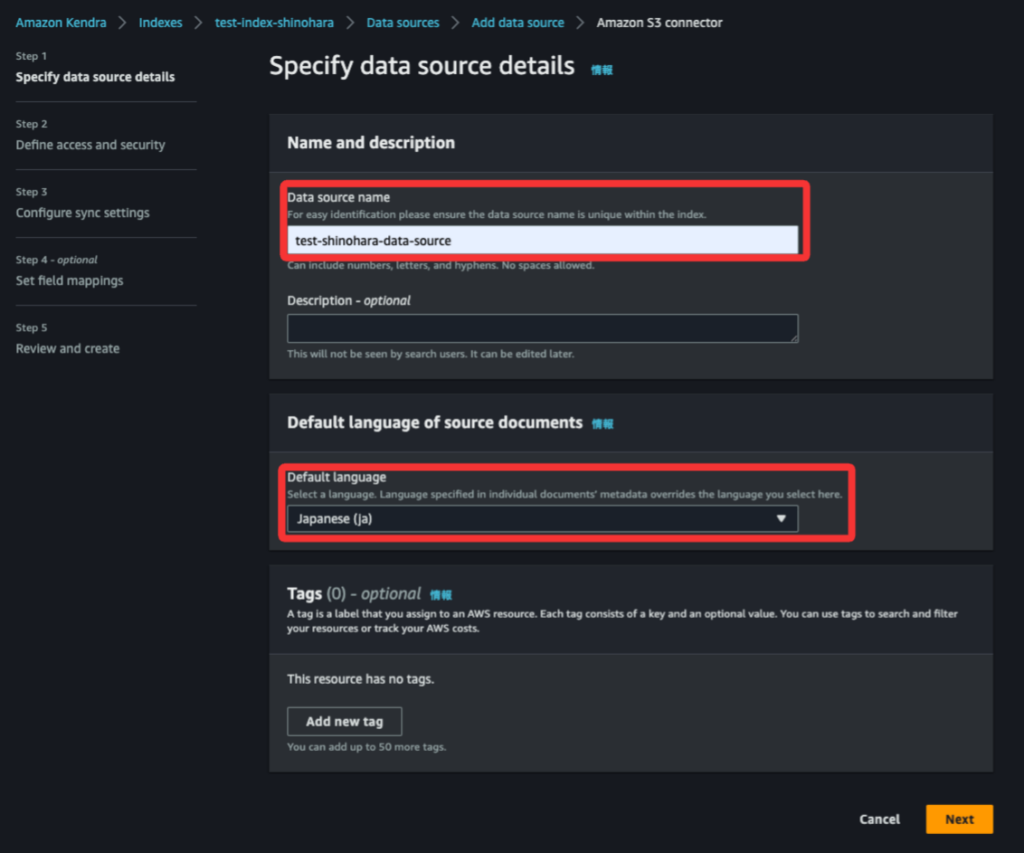
【ステップ10】
次の画面はデフォルトの設定にします。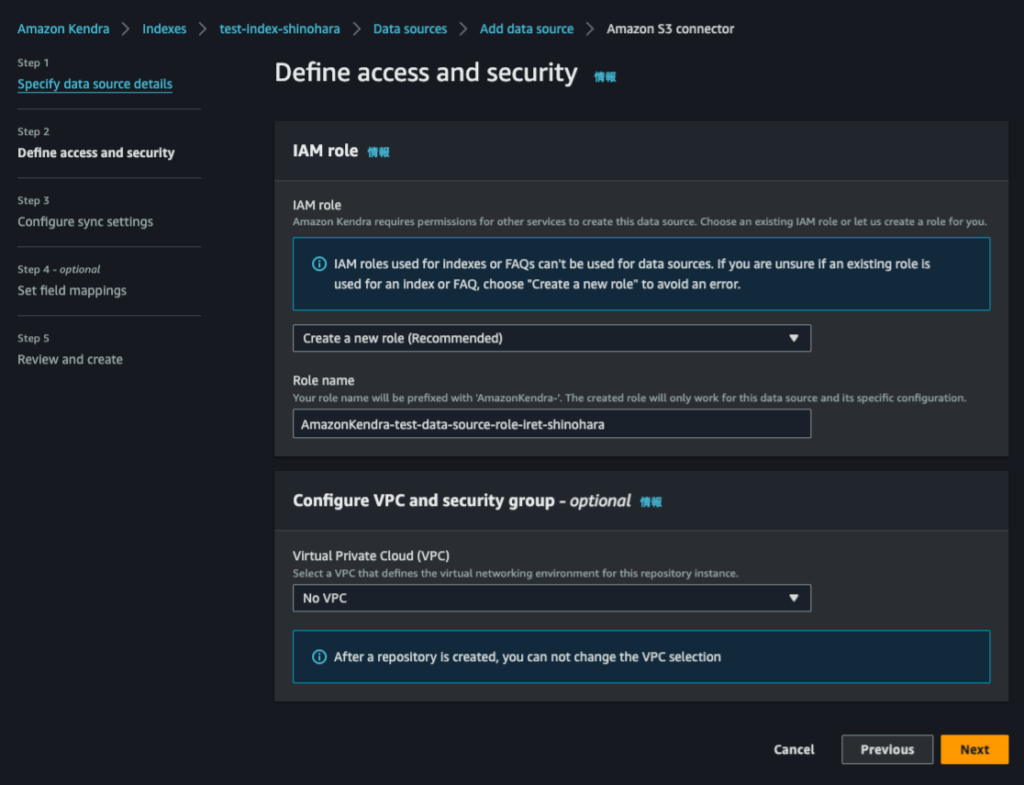
【ステップ11】
Enter the data source locationはステップ1で作成したiret-dx-shinoharaを指定します。Metadata files folder locationは3で作成した/metadataを指定します。Sync modeはデフォルトのFull syncを指定します。Sync run scheduleは必須項目ですが、今回は検証のみなので適当にDailyで指定しました。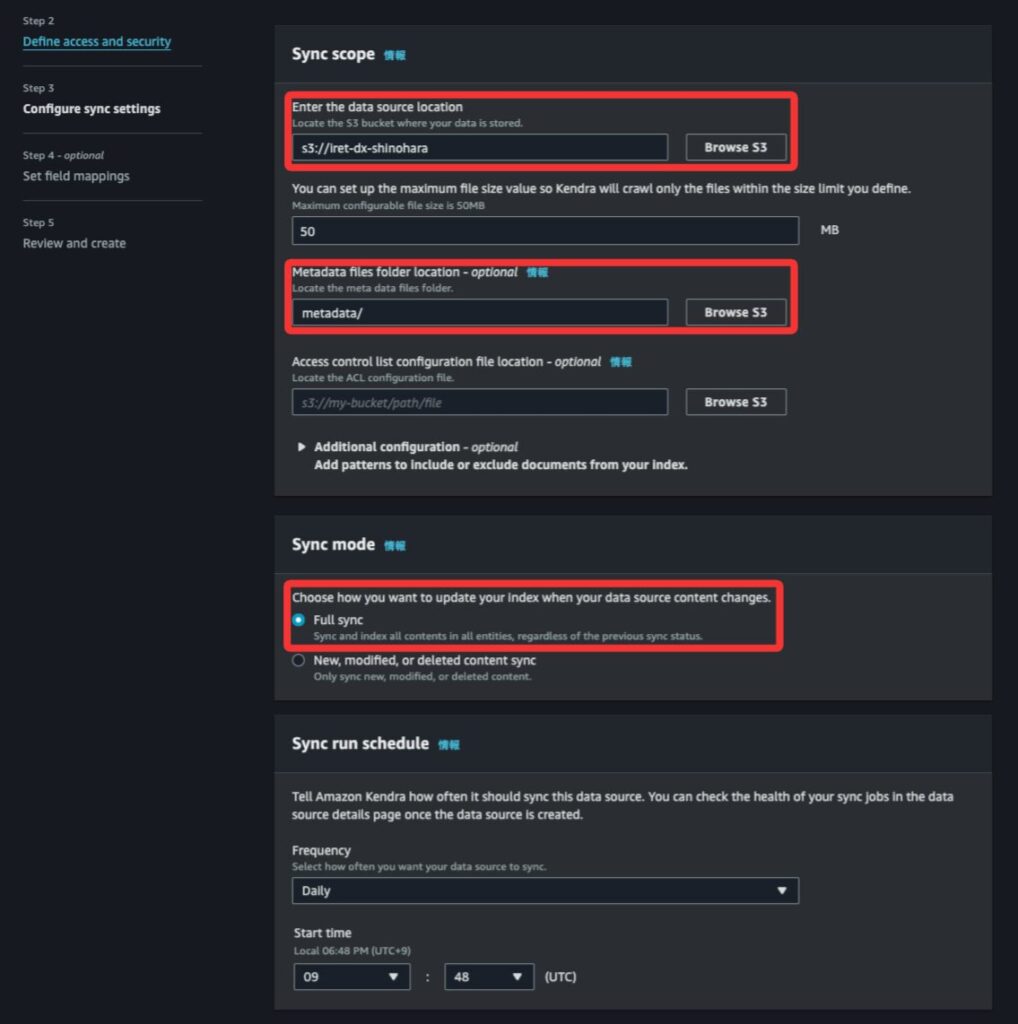
【ステップ12】
残りはデフォルトの設定にします。そして確認画面まで進んだらCreateを押下します。
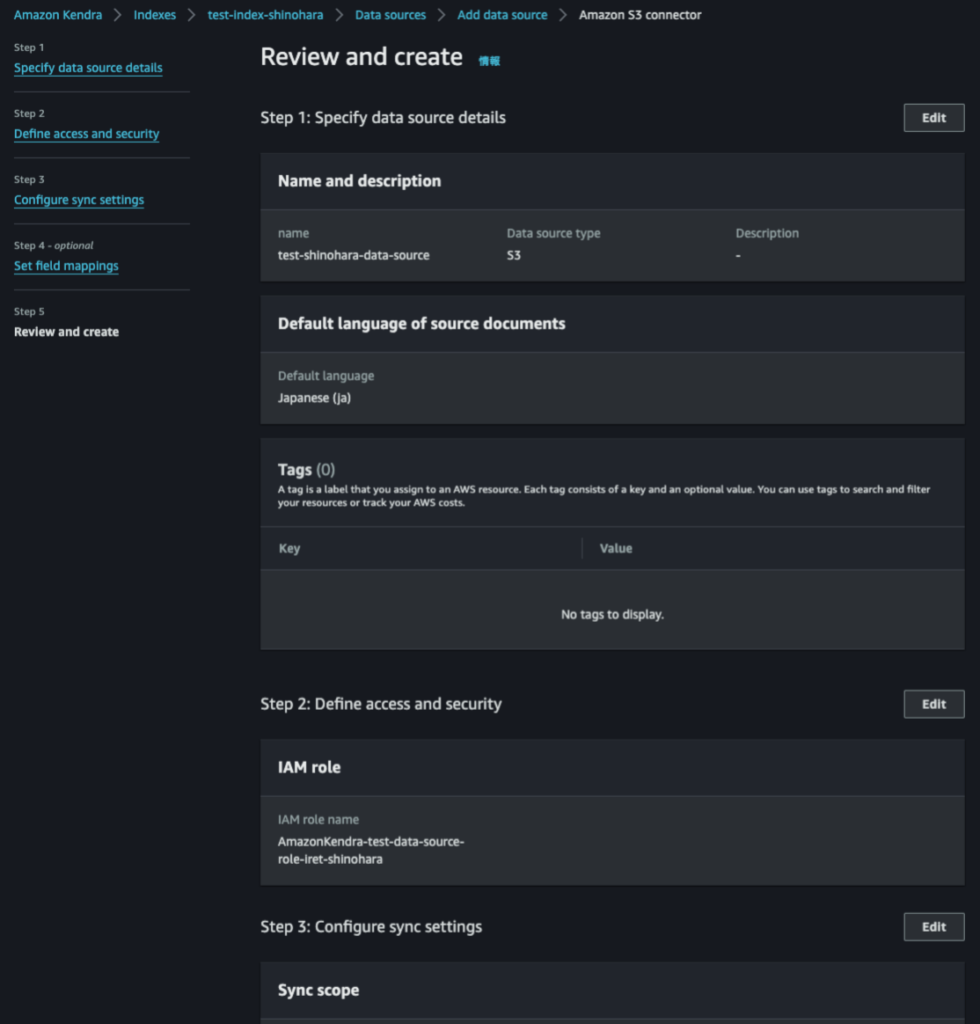
無事にData Sourceの設定ができました。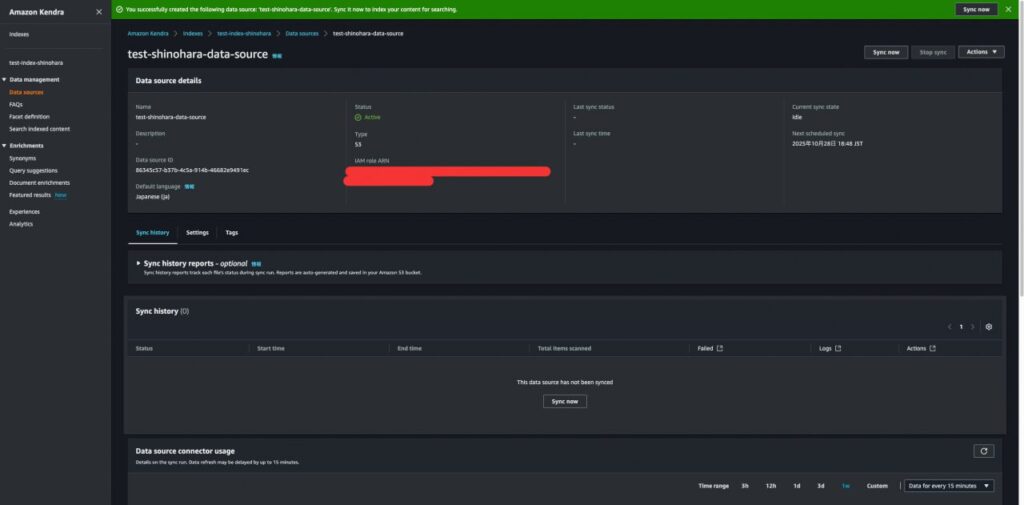
【ステップ13】
Sync nowを押下してクロールします。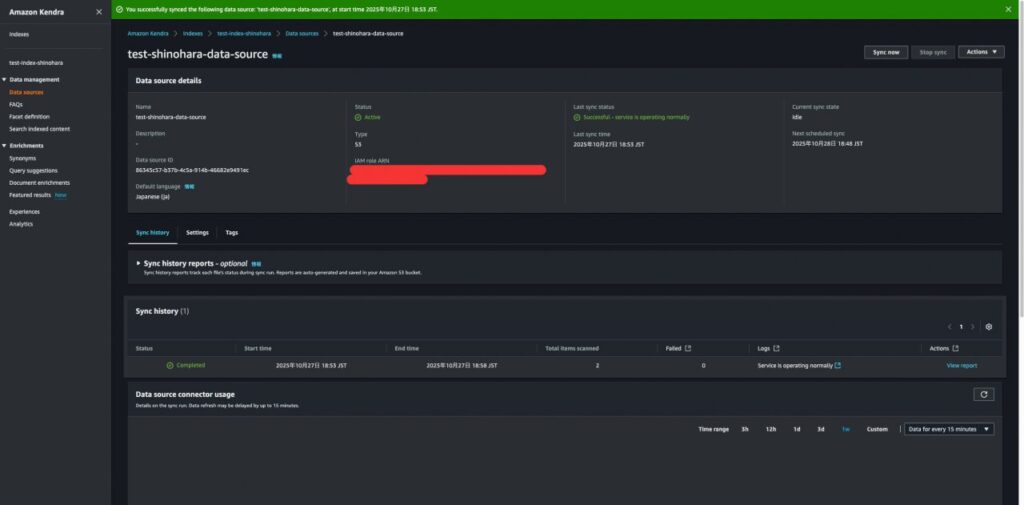
【ステップ14】
今回はすでに設定されている、Amazon Kendra Search consoleを使用してファセット検索を行います。Data sourceは日本語の資料なのでデフォルトのEnglishからJapaneseに変更します。そして「SAAの試験時間を教えて」と検索すると設定したAmazon S3から情報を探してきて検索結果を表示してくれます。しかし、この状態ではまだmetadataを活用したファセット検索ができていません。そこで次のステップが必要になります。
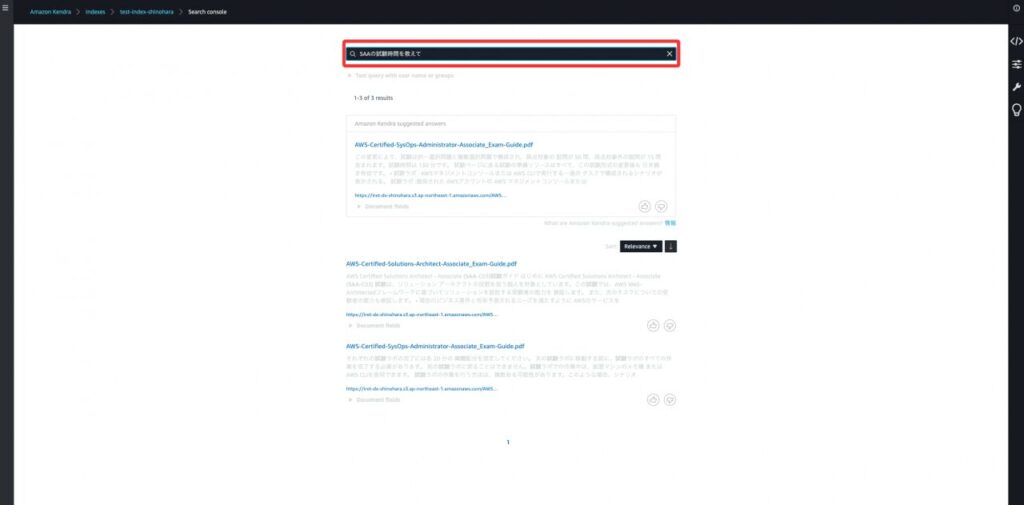
【ステップ15】
カテゴリによる検索結果の絞り込みを行うために、左側のサイドバーの『Facet definition』で『_category』の『Facetable』にチェックをつけます。そうすることで、Amazon Kendra Search consoleでファセット検索を行うことができます。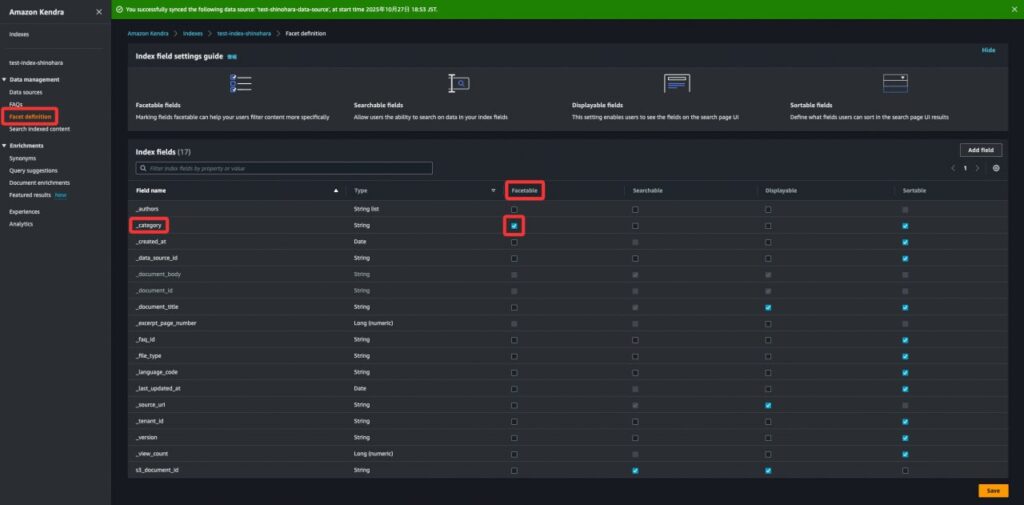
【ステップ16】
ステップ15の設定のおかげで検索結果の横でmetadataで付与した_categoryによる絞り込みができるようになります。これがAmazon Kendraのファセット検索機能です。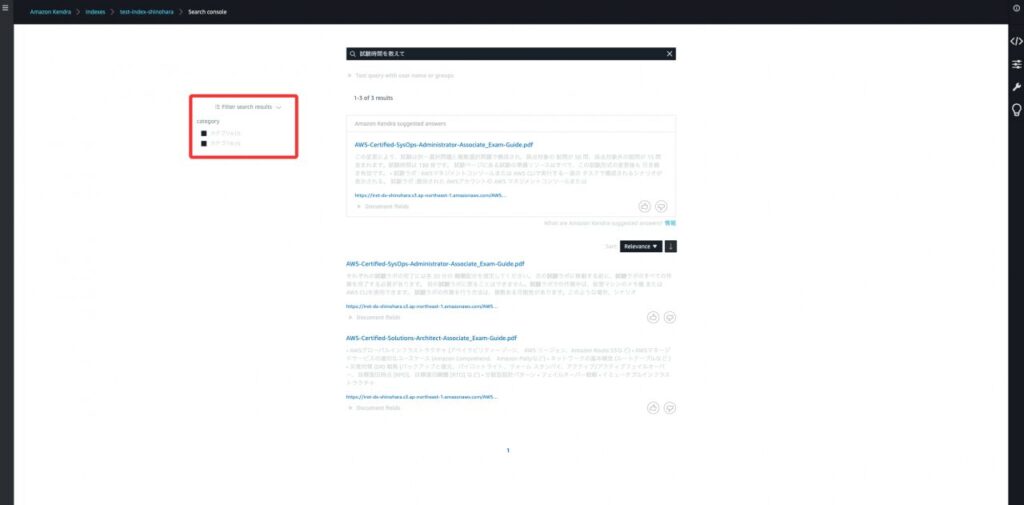
【ステップ17】
実際に絞り込んでみます。カテゴリAで絞り込むとSAAが検索結果に表示され、カテゴリBで絞り込むとSOAが検索結果に表示されるのを確認できます。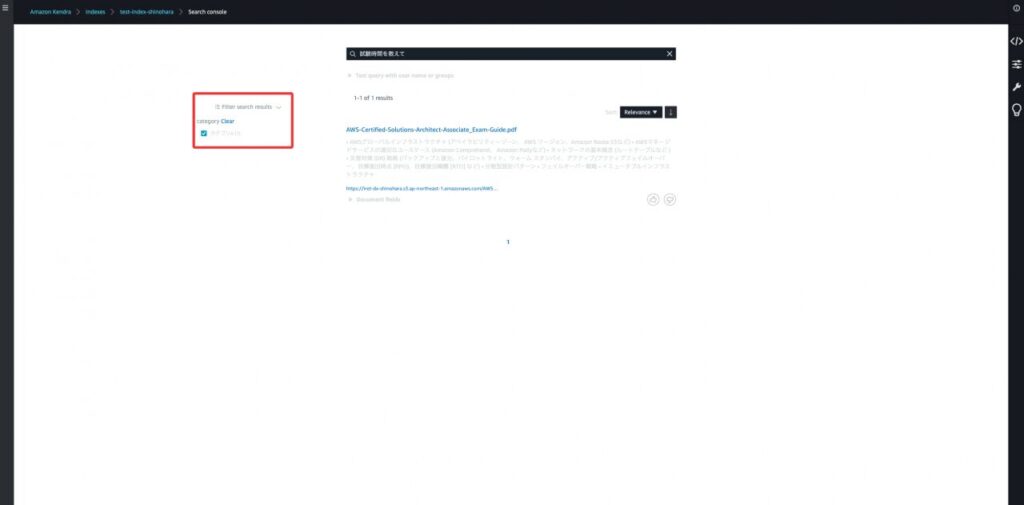
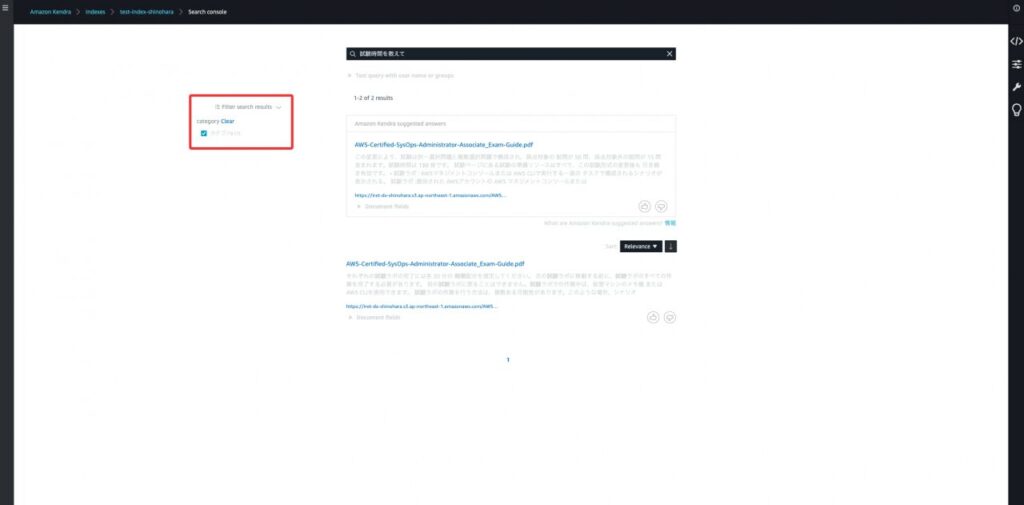
【ステップ18】
最後に検証が完了したので、無駄な課金を防ぐためにインデックスを削除するのを忘れないようにしましょう。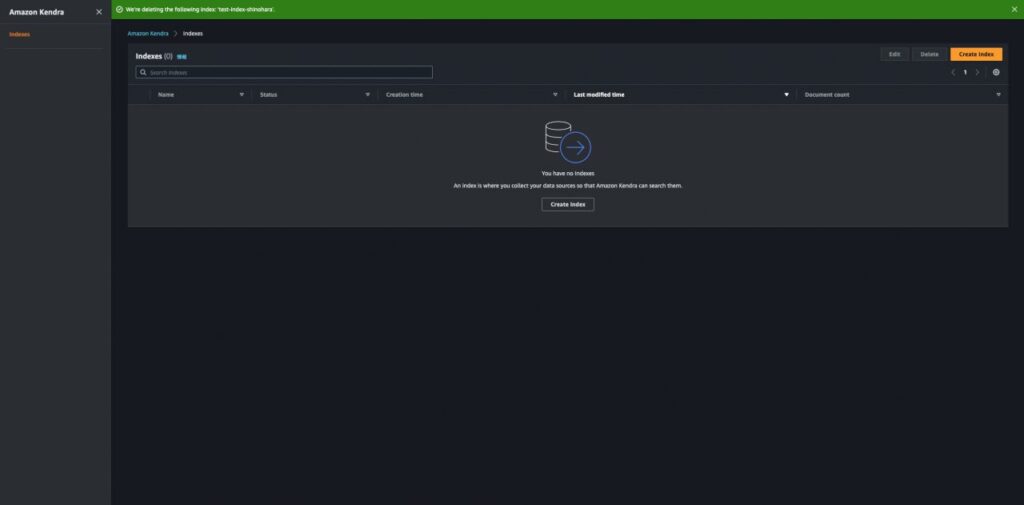
所感
今回初めてAmazon KendraとAmazon S3を触ってみて苦戦した点と考察についてまとめます。
苦戦した点
苦戦した点としては、Amazon Kendraで利用するS3ドキュメントの属性(Attribute)を登録する際です。理由としては、作成したJSONファイルのDocumentIdに入れる値を誤っており、_categoryの付与ができていなかったからです。実際に私は、DocumentIdにs3://iret-dx-shinohara/metadata/というAmazon S3プレフィックスを入力していました。では、なぜこれでは_categoryが付与されないのでしょうか。調査の結果、DocumentIdは属性を紐づけるための個々のドキュメント(Amazon S3オブジェクト)のURIを指定する必要があり、フォルダ(プレフィックス)を指定すると、システムが属性を適用する単一のオブジェクトを特定できないためエラーとなることがわかりました。言い換えるとAmazon S3はドキュメント単位(オブジェクト)で属性登録を行うのでフォルダを指定するのではなくドキュメントの完全なURIを指定する必要があるということです。
考察
検証をしていて、どうしてJSONファイルでメタデータを管理する必要があるのか不思議に思いました。Amazon S3にもタグ機能がありますが、今回はJSONファイルで属性を定義する必要がある理由について、S3タグとの違いに焦点を当てて調査し、その結果をまとめます。結論から言うと、Amazon S3のタグ機能には扱える属性の数とデータの形式に制限があることがわかりました。具体的には、JSONファイルは10個以上の属性を設定できますが、Amazon S3のタグの場合は10個までという制約がありました。※詳しくはこちら
Amazon Kendraなどの高精度な検索サービスでは、カテゴリの他にも文書の形式、部署、作成者、有効期限、機密レベルなど、柔軟かつ多数の属性を付与することが一般的です。また、Amazon S3のタグは単なる文字列でしか値を表現できないため、以下の表のように複数の情報を連結して格納した場合、個々の要素での検索・フィルタリングが困難になります。
| key | value | 説明 |
| TeamMembers | Bob-Nick-Mike | チームメンバー |
一方、JSONファイルでは以下のように配列として表現できるため、個々のメンバーでの正確な検索が可能です。苗字を含めることで、より検索精度を向上させることもできます。
{
"DocumentId": "オブジェクトのURI",
"Attributes": {
"_category": "カテゴリA",
"TeamMembers": [ // ここに配列を定義
"Bob Miller",
"Nick Davis",
"Mike Wilson"
]
}
}
結論として、Amazon Kendraなどの高度な検索サービスを活用する際は、属性の数やデータ型に柔軟性があるJSONファイルでのメタデータ管理がベストプラクティスであると確認できました。
終わりに
今回は、_categoryのみで絞り込みましたが、実際は膨大な資料を取り扱うのでユースケースに応じて、_sub_categoryのようなユーザーが独自の属性を定義し、検索結果を絞り込みすることもできます。このように、Amazon Kendraのファセット機能はユーザーの検索をより効率化するのに役立っています。また、Amazon Kendraではコンソールでの操作で設定ができるのでAWS初心者の私でも扱うことができます。さらに、ファセット機能を検証する上でAmazon S3も触ることができ、非常にいい学びととなりました。皆さんもぜひ、機会があればAmazon Kendraに触れてみてください。
最後まで読んでいただき、ありがとうございました。
参考資料
– https://aws.amazon.com/jp/kendra/
– https://aws.amazon.com/jp/kendra/features/
– https://aws.amazon.com/jp/kendra/pricing/
– https://docs.aws.amazon.com/kendra/latest/dg/s3-metadata.html


