
この記事は Japan AWS Top Engineers であるアジャイル事業部IoTセクションBグループの北野 涼平さんに監修していただきました。
初めに
日々の中で意図せず個人情報を投稿してしまうユーザー。さらに、管理者が手動で個人情報を特定し、削除する作業には時間がかかり、見落としのリスクも高い。
そこでAmazon Comprehendを使った匿名化システムを作成したので作成手順なども踏まえて共有します。
※個人情報の検出は2025年10月段階では日本語対応をしていません。
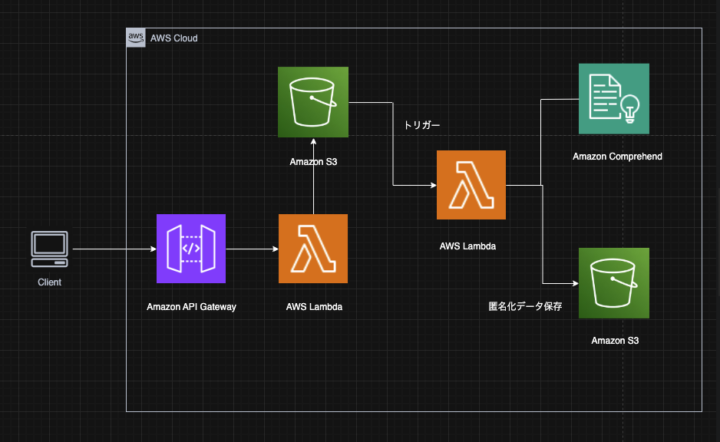
ユーザーがテキストデータを保存するとデータの中に個人情報(名前や電話番号)などが含まれていないか分析します。含まれている場合は匿名化して別のS3にも保存されます。
作成手順
1. S3バケットを2つ作成
匿名化前のデータ保存用S3バケット
匿名化後のデータ保存用S3バケット
2. API Gatewayからデータを受け取るLambda作成
API Gatewayから受け取ったテキストをS3に保存するLambda
import json
import boto3
import os
import uuid
s3_client = boto3.client('s3')
def lambda_handler(event, context):
try:
# S3バケット名を環境変数から取得
raw_text_bucket = os.environ['RAW_TEXT_BUCKET']
# API Gatewayからのリクエストボディを取得
body = json.loads(event['body'])
text_data = body['text_data']
# ユニークなファイル名を生成
file_name = f"{uuid.uuid4()}.txt"
# S3にテキストデータをアップロード
s3_client.put_object(
Bucket=raw_text_bucket,
Key=file_name,
Body=text_data.encode('utf-8'),
ContentType='text/plain'
)
print(f"Successfully uploaded {file_name} to {raw_text_bucket}")
return {
'statusCode': 200,
'body': json.dumps({'message': 'Text uploaded successfully', 'file_name': file_name})
}
except Exception as e:
print(f"Error: {e}")
return {
'statusCode': 500,
'body': json.dumps({'message': 'Failed to upload text to S3', 'error': str(e)})
}
次に環境変数を追加します。
キー RAW_TEXT_BUCKET
値 匿名化前のデータ保存用S3パケット名
S3に対してのポリシーを付与しておく必要があります。
次はAPI Gatewayトリガーの設定です。
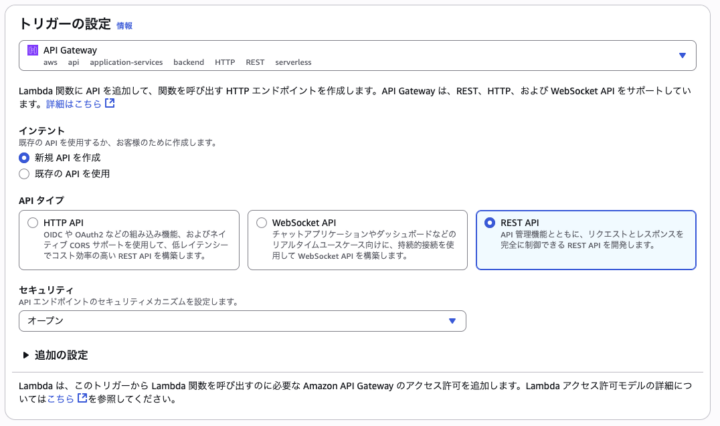
画像のような設定をします。
これでAPI Gatewayから受け取ったテキストをS3に保存するLambdaが完成です。
3. 匿名化するLambda作成
S3に保存されたテキストファイルを匿名化するLambda
import json
import boto3
import os
s3_client = boto3.client('s3')
comprehend_client = boto3.client('comprehend')
def lambda_handler(event, context):
try:
# S3バケット名を環境変数から取得
raw_text_bucket = os.environ['RAW_TEXT_BUCKET']
anonymized_text_bucket = os.environ['ANONYMIZED_TEXT_BUCKET']
# S3イベントからファイル名(キー)を取得
file_name = event['Records'][0]['s3']['object']['key']
# S3からテキストファイルを読み込む
response = s3_client.get_object(Bucket=raw_text_bucket, Key=file_name)
text_data = response['Body'].read().decode('utf-8')
# Amazon ComprehendでPII(個人情報)を検出
pii_entities = comprehend_client.detect_pii_entities(Text=text_data, LanguageCode='en')
# 検出されたPIIエンティティが存在するかチェック
if pii_entities['Entities']:
# 個人情報が含まれている場合のみ匿名化処理と保存を実行
anonymized_text = text_data
for entity in pii_entities['Entities']:
entity_type = entity['Type']
begin_offset = entity['BeginOffset']
end_offset = entity['EndOffset']
pii_text = text_data[begin_offset:end_offset]
anonymized_text = anonymized_text.replace(pii_text, f'[{entity_type}]')
# 匿名化されたテキストを別のS3バケットに保存
s3_client.put_object(
Bucket=anonymized_text_bucket,
Key=file_name,
Body=anonymized_text.encode('utf-8'),
ContentType='text/plain'
)
print(f"Successfully anonymized and uploaded {file_name} to {anonymized_text_bucket}")
else:
# 個人情報が含まれていない場合はログを出力するだけで何もしない
print(f"No PII detected in {file_name}. Skipping upload to {anonymized_text_bucket}.")
return {
'statusCode': 200,
'body': json.dumps({'message': 'Text anonymized successfully', 'file_name': file_name})
}
except Exception as e:
print(f"Error: {e}")
return {
'statusCode': 500,
'body': json.dumps({'message': 'Failed to process text', 'error': str(e)})
}
次に環境変数を追加します。
キー RAW_TEXT_BUCKET
値 匿名化前のデータ保存用S3バケット名
キー ANONYMIZED_TEXT_BUCKET
値 匿名化後のテキストデータを保存するS3バケット名
付与するポリシーはComprehendとS3に対するポリシーです。
次はS3トリガーの設定です。
匿名化前のデータ保存用のS3バケット選択してください。
4. 動作確認
トリガーとして設定したAPI GatewayのエンドポイントURLを準備します。
ターミナルで以下のコマンドを実行します。
curl -X POST 'YOUR_API_GATEWAY_URL' \YOUR_API_GATEWAY_URLに先ほどのエンドポイントURLを入力してください。
-H 'Content-Type: application/json' \
-d '{"text_data": "My name is John Smith. My phone number is 1-800-555-0123."}'
コマンド実行後S3にアップロードされているか確認
アップロードされていることを確認後ファイルを開きます。
My name is [NAME]. My phone number is [PHONE].
このように個人情報が匿名化されていました。
まとめ
今回作成したシステムでは、Amazon ComprehendとS3、Lambdaを組み合わせることで、個人情報の検出と匿名化を完全に自動化するシステムを構築しました。
ただし、Comprehendは日本語の解析が十分にできない場合があるため、英語のテキストを使用しました。 もし日本語の個人情報を検出する場合は、ComprehendよりもLambdaで個人情報検出のライブラリや、Amazon Textractを使うなどが最適だと思います。
またAmazon EventBridgeなどのイベント駆動型サービスを組み合わせることでデータ処理の自動化範囲をさらに広げたり、他システムとの連携も柔軟に行えると考えているので、時間があれば拡張していきます。
以上です。最後までお読みいただきありがとうございます。
参考になれば幸いです。


