目的
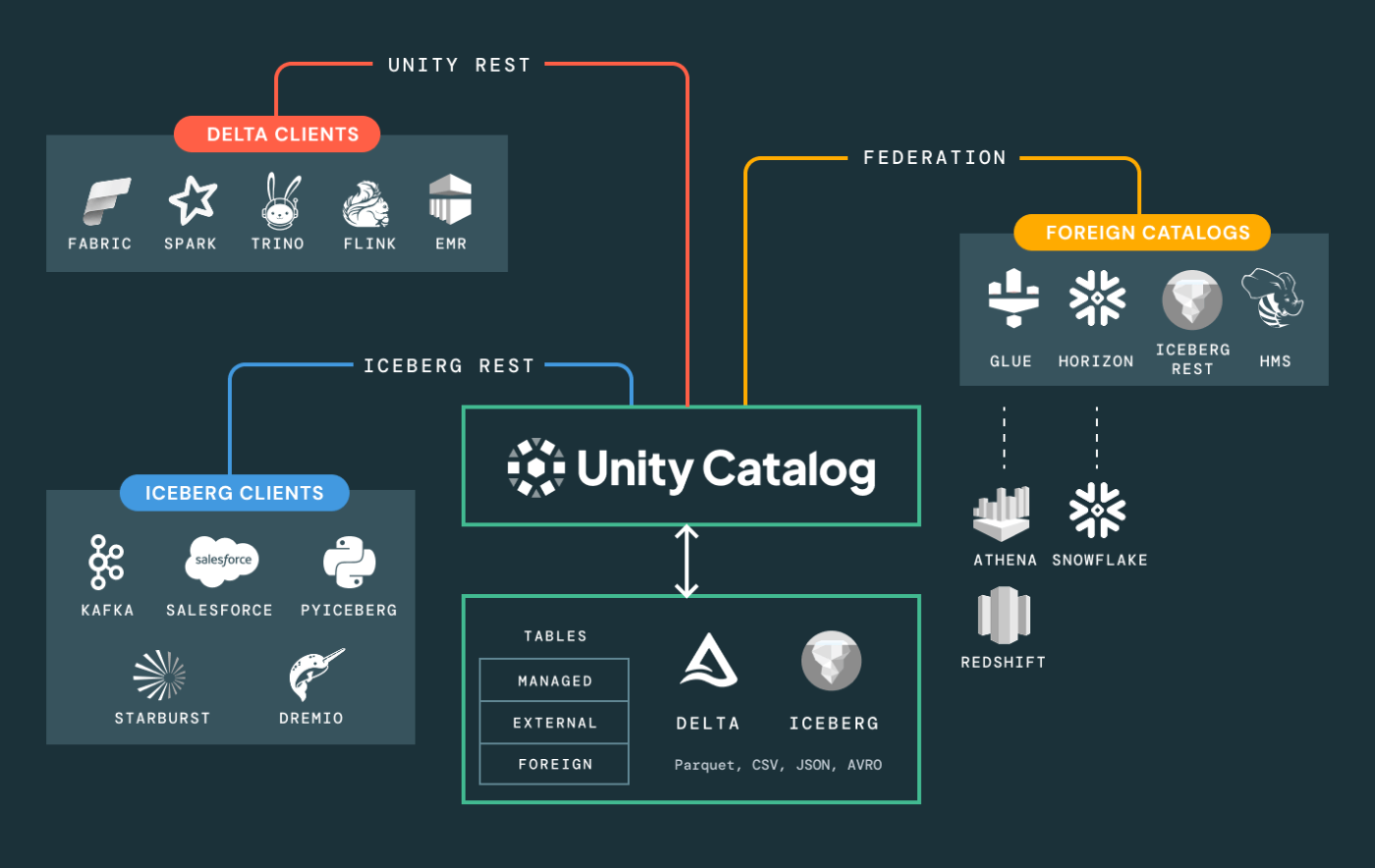
Databricksはセキュリティを内部のカタログでマッピングする仕組みが便利かつ有名です。
これはいわゆるUnity Catalogという機能がデータに対するセキュリティのきめ細かい管理を可能とします
今回はその仕組みのデモを行います。
記事の流れ
以下の流れとなります。
ステップ1:マスターテーブル(マッピング表)の登録
できたファイルの中身確認
ステップ2:フィルタ用関数(UDF)の作成
ステップ3:ターゲットテーブルへの適用
検証
データを変えるコマンド
終わりに
補足
S3バケット名など、画像の一部項目は白抜きしています。
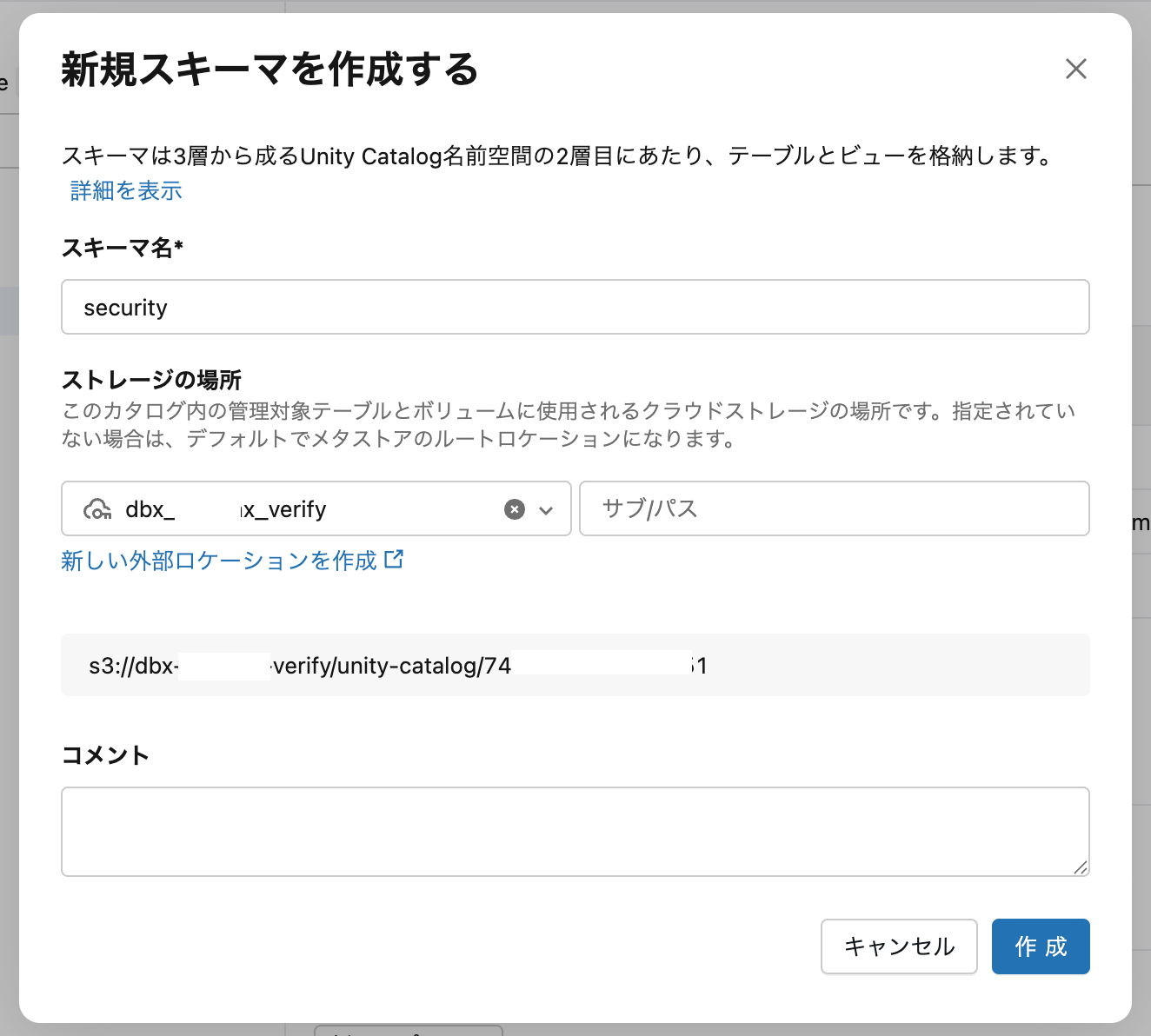
(任意)セキュリティ用のスキーマを作成します
ここは任意ですが、スキーマを作っておくとわかり良いです。
コンソール上でカタログの画面にて以下のように設定して作成できます
ステップ1:マスターテーブル(マッピング表)の登録
コンソール上でSQLエディタにて以下のコマンドでマスターテーブルを作成できます。
下記のように
CREATE SCHEMA IF NOT EXISTS security;
を打つことでもスキーマの作成は可能です。
-- 1. 管理用スキーマの作成(既存なら不要)
CREATE SCHEMA IF NOT EXISTS security;
-- 2. マスターテーブルの作成
CREATE TABLE IF NOT EXISTS security.user_auth_master (
user_email STRING, -- ユーザーのメールアドレス
allowed_value STRING -- 閲覧を許可する値(例:部門コードや配送モード)
);
-- 3. データの登録(例:AさんはAIRのみ、BさんはTRUCKのみ)
INSERT INTO security.user_auth_master VALUES
('a_san@example.com', 'AIR'),
('b_san@example.com', 'TRUCK'),
('admin@example.com', '*'); -- 管理者用ワイルドカード
データができていることが確認できます(Databricksのコンソール上で場所は確認可能)
本当にS3上にファイルができていますね
unity-catalog/7474649950822451/__unitystorage/schemas/0ae94695-dfbc-46da-9f4d-c87ac2c9a3fa/tables/614c56e4-400e-41b4-bb5d-bb3625cef1bc
できたファイルの中身確認(気になる方のみ)
parquetファイルの中身を確認してみましょう
以下の手順で確認できます。
1. 仮想環境を作成
python3 -m venv .venv
2. 仮想環境を起動
source .venv/bin/activate
3. インストール
pip install parquet-tools
4. 実行
以下がデータの中身です
コマンド例:
parquet-tools show [[part-00000-232e1942-a5c7-4b20-81b3-10652c95cc6f.c000.zstd.parquet ]]
<br />+-------------------+-----------------+ | user_email | allowed_value | |-------------------+-----------------| | a_san@example.com | AIR | | b_san@example.com | TRUCK | | admin@example.com | * | +-------------------+-----------------+
以下がメタデータの中身です
コマンド例:
parquet-tools inspect part-00000-232e1942-a5c7-4b20-81b3-10652c95cc6f.c000.zstd.parquet
############ file meta data ############ created_by: parquet-mr compatible Photon version 0.2 (build 17.3) num_columns: 2 num_rows: 3 num_row_groups: 1 format_version: 1.0 serialized_size: 801 ############ Columns ############ user_email allowed_value ############ Column(user_email) ############ name: user_email path: user_email max_definition_level: 0 max_repetition_level: 0 physical_type: BYTE_ARRAY logical_type: String converted_type (legacy): UTF8 compression: ZSTD (space_saved: 12%) ############ Column(allowed_value) ############ name: allowed_value path: allowed_value max_definition_level: 0 max_repetition_level: 0 physical_type: BYTE_ARRAY logical_type: String converted_type (legacy): UTF8 compression: ZSTD (space_saved: -16%)
ステップ2:フィルタ用関数(UDF)の作成
CREATE OR REPLACE FUNCTION security.auth_filter(column_value STRING)
RETURN EXISTS (
SELECT 1 FROM security.user_auth_master
WHERE user_email = current_user() -- 今ログインしている人のメールアドレスを取得
AND (allowed_value = column_value OR allowed_value = '*')
);
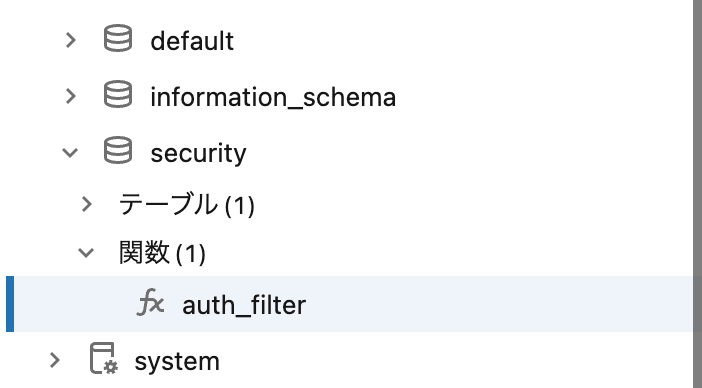
その後、コンソールの画面を見ると関数(1)の項目ができていることがわかります
ステップ3:ターゲットテーブルへの適用
テーブルに関数を適用する手順です
-- 自分のカタログにデータをコピーしてテーブル作成 CREATE TABLE IF NOT EXISTS default.secure_lineitem AS SELECT * FROM samples.tpch.lineitem; -- 行フィルタを適用(l_shipmodeカラムの値で判定) ALTER TABLE default.secure_lineitem SET ROW FILTER security.auth_filter ON (l_shipmode);
検証
それでは無事データがフィルタリングされているか
selectで検証しましょう。
select * from default.secure_lineitem ;
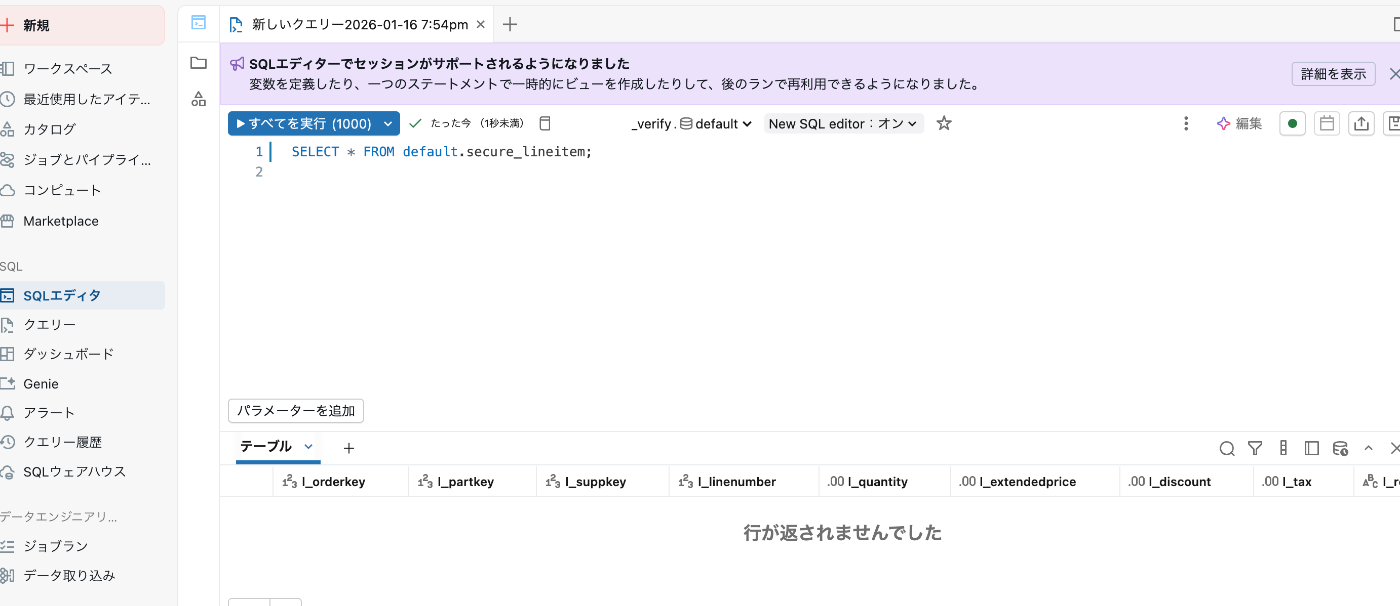
今は自分のメールアドレスがテーブル上にないので、データが返らないことがわかります
これは意図通りの挙動です
データを変えるコマンド
フィルタリングされたデータが見れるかの確認のため
先ほどのテーブルデータの一部を自分のアドレスにします。
[[‘hogehoge.co.jp’]]のところを自分のDatabricksアカウントのメールアドレスにしてコマンドを打ちましょう。
UPDATE security.user_auth_master SET user_email = 'hogehoge.co.jp' WHERE user_email = 'a_san@example.com';
無事値が更新されています
select * from default.secure_lineitem ;

また元のデータをselect見てみましょう。
意図通り、該当した値がちゃんと出ていることがわかります。
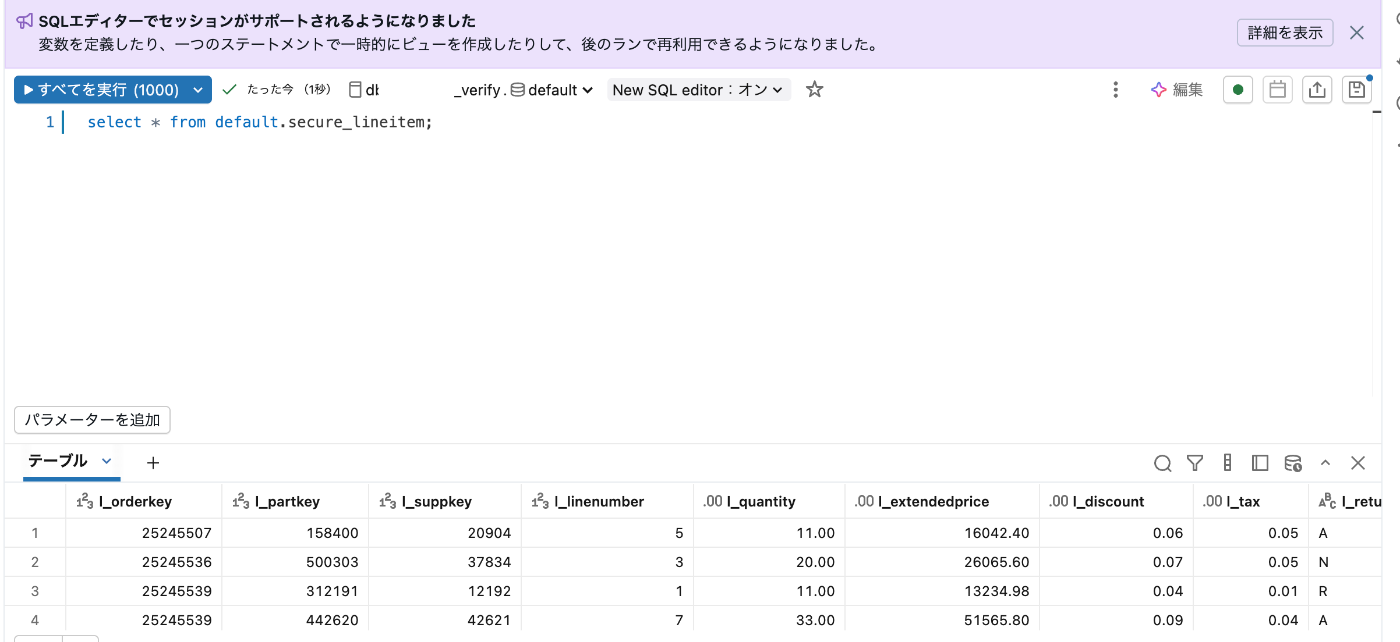
以下はフィルタリング対象のカラムです。

絞り込みもちゃんと効いていそうです。
終わりに
いかがでしたでしょうか。
高いコスト効率でS3にデータを保存し
セキュリティを動的に管理できる仕組みは素晴らしいですね。
