
ベクトルデータベース(Vector Database)とは
「データの『意味の近さ』を計算して、似たものを探し出すことに特化したデータベース」です
特に、RAG(検索拡張生成)の基盤技術として広く活用されています
なぜ「ベクトルデータベース」が必要なのか?
- 従来のDBの限界
例えば「スパイシーなカレー」と検索した場合、「スパイシー」という文字が入っていないとヒットしません
たとえ「激辛」や「辛口」という商品があっても、キーワードが違えば無視されてしまうのです - 人は「ニュアンス」で探したい
「言葉は違うけれど、なんとなく意味や雰囲気が似ているもの」を探す
この「あやふやな検索」を可能にするのが、ベクトルデータベースです
例を用いた「ベクトル化」のイメージ
言葉の「意味」をどうやって数字にするのか、カレーを例に考えてみます
ここでカレーを「辛さ」と「とろみ」の2軸で図面上に配置します
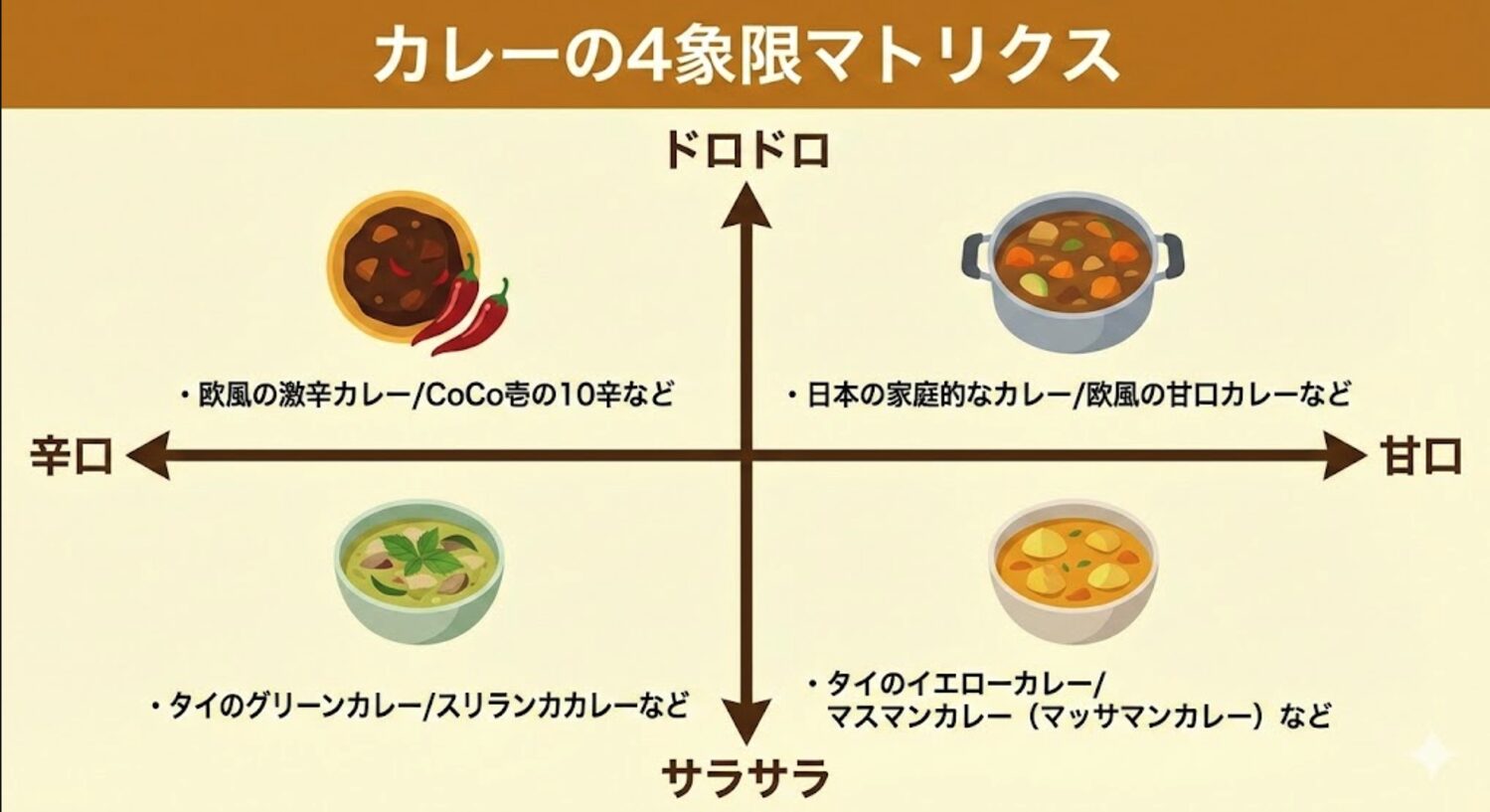
世の中のあらゆるカレーは、この図面上のどこかに「点(座標)」として存在することになります
- 欧風の激辛カレー/CoCo壱の10辛: 「辛口」かつ「ドロドロ」なので 左上のエリア
- タイのグリーンカレー/スリランカカレー: 「辛口」かつ「サラサラ」なので左下のエリア
- 日本の家庭的なカレー/欧風の甘口カレー: 「甘口」かつ「ドロドロ」なので 真ん中の少し右上のエリア
- タイのイエローカレー/マスマンカレー(マッサマンカレー): 「甘い」かつ「サラサラ」なので 右下のエリア
このように、「グリーンカレー」という言葉を図面上の座標という「数字の並び」に変換する
これを「ベクトル化」と呼びます
ベクトルデータベースは何がすごいのか?
- 従来のDB: 「文字列が完全に一致するものを探す」
- ベクトルDB: 「図面上で距離が近いものを探す」
AIとベクトルデータベースの深い関係
実際のAI(ChatGPT、Claudeなど)は、「辛さ・とろみ」の2軸だけでなく、数千もの複雑な「意味の軸」を使って言葉を配置しています
この膨大な多次元データを高速に検索・処理することに特化したのが「ベクトルデータベース」です
まとめ
「ベクトル」と聞くと難しそうで身構えてしまいますが、例を用いて考えることですんなりと理解を深めることができました。
今後は、代表的なベクトルデータベースである「Pinecone」というサービスを使って、実際にベクトルデータベースを構築してみたいと思います!


