
目次
1.はじめに
2.Remote Subagentsとは
3.Remote Subagentの作成
4.Gemini CLIのRemote Subagents設定と実行
5.Remote Subagentのモデル変更とGemini CLIのRemote Subagents実行
6.おわりに
1.はじめに
Gemini CLI で使用できるモデルは Gemini です。
ですが、ユーザー側としてはタスクに応じて別の LLM(e.g.,Anthropic Claude モデルや Meta Llama モデルなど)を使いたいケースもあるかと思います。
Gemini CLI の Remote Subagents を使えば、それが実現できます。
Remote Subagents として使用するエージェントに Gemini 以外のモデルを設定し、それを Gemini CLI の Remote Subagents として登録します。
Gemini CLI の特定の処理や指示において、その Remote Subagents が稼働すれば、その Remote Subagents に設定した Remote Subagent の LLM ベースの処理が実行され、実行結果が Gemini CLI 側に返されます。
本ブログでは、Remote Subagents に関する簡単な説明から、Google Cloud 上に Remote Subagents として使用する Remote Subagent のデプロイと Gemini CLI での Remote Subagents 設定と実行結果、最後に Remote Subagent のモデルを Mistral AI モデルに変更して使用する方法を紹介します。
※ Remote Subagents(複数形)は仕組みの総称とし、個別の実体は Remote Subagent と記載しております。
環境情報
作業環境については以下です。
- macOS:Tahoe 26.2
- Node.js のバージョン(
node --version):24.11.1 - Gemini CLI のバージョン(
gemini --version):0.29.5
2.Remote Subagentsとは
Remote Subagents とは、エージェントが A2A(エージェント間プロトコル)経由で外部のエージェントと連携し、タスク委譲と結果統合を通じてエージェントの機能を拡張する仕組みです。
これにより、異なるモデルを組み合わせたマルチモデル構成や、クラウド上に配置した共通エージェントを組織横断的に共有することが可能となります。
Gemini CLI での Remote Subagents の利用設定について、本ブログ執筆時点では experimental 版のため、settings.json に下記の設定が必要となります。
〜〜省略〜〜
"experimental": {
"enableAgents": true
}
〜〜省略〜〜
Markdown ファイルの作成と配置も必要となります。
プロジェクトレベルであれば、.gemini/agents/*.md、ユーザーレベル(グローバルに使用可能)であれば、~/.gemini/agents/*.md に配置します。
Markdown ファイルの中身について、kind として remote、name に Subagent の名前、そして、agent_card_url に Remote Subagent の A2A カードエンドポイントへの URL を設定します。
(A2Aカードエンドポイントとは、Remote Subagent が提供する機能情報などを定義したメタ情報を取得するための URL です)
--- kind: remote name: my-remote-agent agent_card_url: https://example.com/agent-card ---
Remote Subagents の説明は以上となります。
Gemini CLI で Remote Subagents を使うにあたり、外部 AI エージェント(Remote Subagent)を作成する必要があるので、続いては Google Cloud への外部 AI エージェントのデプロイについて記述していきます。
3.Remote Subagentの作成
ADK Samples (Python) を使用します。
(Agent Development Kit (ADK):Google Cloudが提供する、AIエージェントを構築・デプロイするためのオープンソースフレームワーク)
サンプル集の中から、LLM Auditor という文章の内容ファクトチェック機能を持つエージェントを今回は使用します。
このサンプルのコードをコンテナ化し、Google Cloud の Cloud Run 上で A2A サーバーとして動かします。
事前準備
ローカルでの設定について、gcloud CLI をインストール済み、gcloud auth でのログインも実施し、使用するプロジェクトを設定しています。
(YOUR_PROJECT_ID は仮の値です。実際に使用するプロジェクト ID に置き換えてください)
# インストール済みか確認 gcloud --version # ログイン gcloud auth login # 使用するプロジェクトを設定 gcloud config set project YOUR_PROJECT_ID # 設定確認 gcloud config list
ADK をインストールします。
$ pip install google-adk Collecting google-adk Downloading google_adk 〜〜省略〜〜 $ pip show google-adk Name: google-adk Version: 1.25.1 Summary: Agent Development Kit 〜〜省略〜〜
Cloud Run、Artifact Registry、Vertex AI の API を有効化します。
gcloud services enable run.googleapis.com gcloud services enable artifactregistry.googleapis.com gcloud services enable aiplatform.googleapis.com
サービスアカウントに Vertex AI を呼び出す権限を付与します。
今回は Gemini CLI の Remote Subagents を使ってみる事が主題なので、 Cloud Run についてはデフォルトサービスアカウントを使用します。
実運用においてはデフォルトサービスアカウントではなく、Cloud Run 用に権限を絞ったサービスアカウントを作成、使用することを推奨します。
# プロジェクト番号を確認 gcloud projects describe YOUR_PROJECT_ID --format="value(projectNumber)" # 権限を付与(YOUR_PROJECT_NUMBER は上で確認した番号に置き換える) gcloud projects add-iam-policy-binding YOUR_PROJECT_ID \ --member="serviceAccount:YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com" \ --role="roles/aiplatform.user"
ADK がローカルおよびデプロイ時に Google Cloud へ認証できるよう、ADC を設定します。
gcloud auth application-default login
続いてサンプルコードを入手します。
$ git clone https://github.com/google/adk-samples.git Cloning into 'adk-samples'... remote: Enumerating objects: 8246, done. remote: Counting objects: 100% (20/20), done. remote: Compressing objects: 100% (15/15), done. remote: Total 8246 (delta 11), reused 5 (delta 5), pack-reused 8226 (from 2) Receiving objects: 100% (8246/8246), 167.26 MiB | 12.90 MiB/s, done. Resolving deltas: 100% (4533/4533), done.
リポジトリのクローンができたら、adk-samples/python/agents/llm-auditor の環境変数設定をします。
GOOGLE_CLOUD_PROJECT と GOOGLE_CLOUD_LOCATION の値を自身が使用するものに編集し保存します。
(ローカルでこのエージェントを動かす際に参照されます。Vertex AI 経由で LLM を呼ぶが、どの Google Cloud プロジェクトのどのリージョンからとするかを定義します)
$ cp .env.example .env $ vi .env GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_PROJECT_NAME> GOOGLE_CLOUD_LOCATION=<YOUR_PROJECT_LOCATION>
ここまで出来たらローカルでの動作確認をします。
$ pwd /Users/名前/Documents/adk-samples/python/agents/llm-auditor $ adk web 〜〜省略〜〜 INFO: Started server process [15720] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+
adk web コマンドを実行し、表示された URL をブラウザに入力すると以下の Web UI が立ち上がります。
サンプルのエージェントを動かします。Cloud Run に関する誤った情報を入力してみます。
Cloud Runは常に1インスタンス以上が起動しているため、アイドル状態でも課金が発生します。また、Cloud RunはVPC接続が必須であり、インターネット公開はできません。
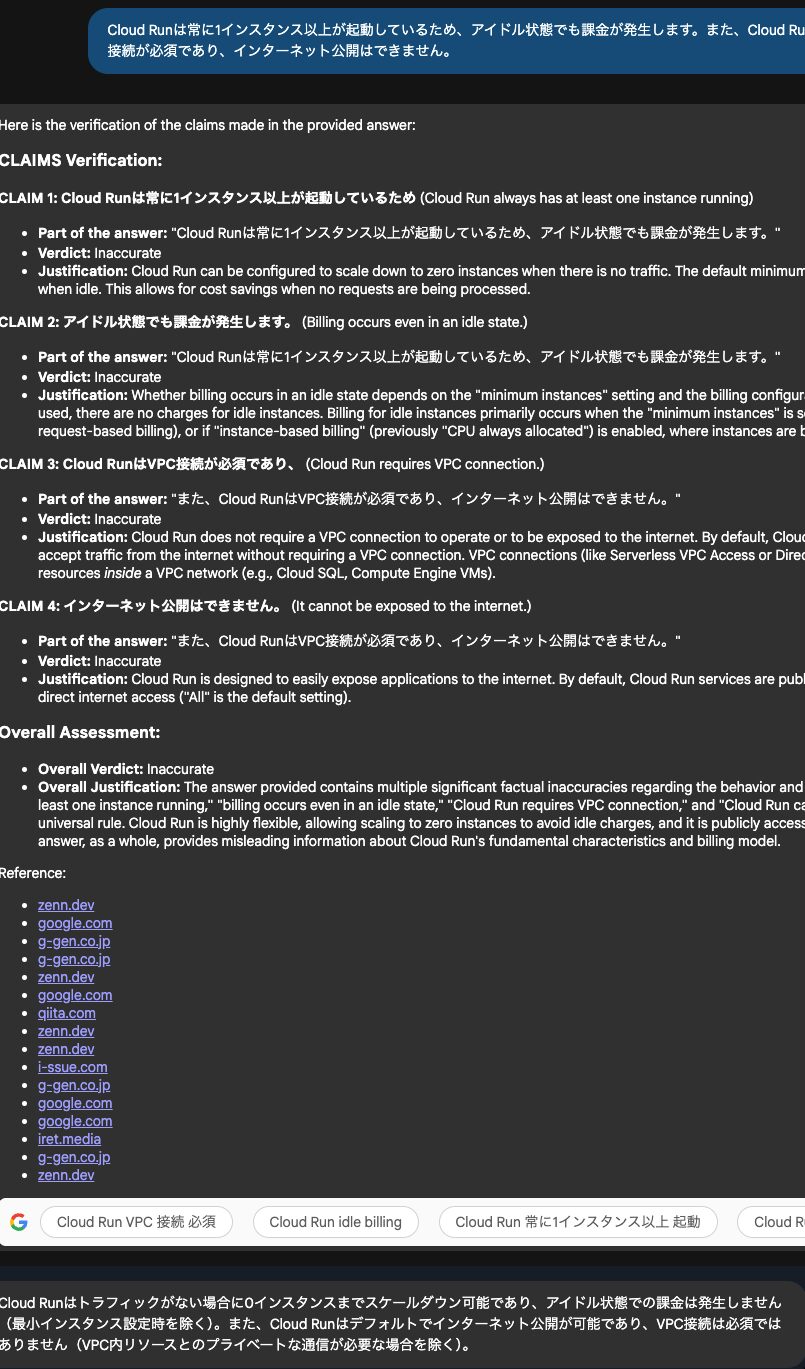
入力内容の正否を調査した上で、調査結果に基づく Cloud Run に関する情報を出力してくれています。
Cloud Runへのデプロイについて
※筆者検証環境での事象です。
adk deploy cloud_run コマンドを使ったデプロイを試みましたが、筆者の検証時点(2026年2月)では pyproject.toml の依存関係がコンテナに反映されない問題が発生しました。
そのため本ブログでは gcloud run deploy + 自前 Dockerfile を使う方法としています。
また、gcloud run deploy を2回実行しているのですが、__main__.py の AgentCard に設定する SERVICE_URL がデプロイ前には確定しないためです。
同じプロジェクト・リージョン・サービス名であれば URL は固定されるため、2回目以降は1回のデプロイで済みます。
本ブログの主題は Gemini CLI の Remote Subagents を使うことなので、Cloud Run のデプロイ周りはとりあえず動く状態を作ることを優先しています。
そのため、デプロイ方法の詳細については参考程度にご覧ください。
追加ファイルの作成
requirements.txt を作成します。
cat > agents/llm-auditor/requirements.txt << 'EOF' google-adk[a2a]>=1.0.0 google-cloud-aiplatform[adk,agent-engines]>=1.93.0 google-genai>=1.9.0 pydantic>=2.10.6 python-dotenv>=1.0.1 a2a-sdk>=0.3.0 uvicorn>=0.34.0 EOF
続いて __main__.py を作成。
SERVICE_URL は環境変数から受け取る形とします。
cat > agents/llm-auditor/llm_auditor/__main__.py << 'EOF'
import os
import uvicorn
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from a2a.types import AgentCard, AgentCapabilities
from .agent import root_agent
service_url = os.environ.get("SERVICE_URL", "http://localhost:8000")
agent_card = AgentCard(
name="llm_auditor",
description="Evaluates LLM-generated answers, verifies actual accuracy using the web, and refines the response to ensure alignment with real-world knowledge.",
url=service_url,
version="1.0.0",
capabilities=AgentCapabilities(),
skills=[],
defaultInputModes=["text/plain"],
defaultOutputModes=["text/plain"],
supportsAuthenticatedExtendedCard=False,
)
a2a_app = to_a2a(root_agent, port=8000, agent_card=agent_card)
if __name__ == "__main__":
uvicorn.run(a2a_app, host="0.0.0.0", port=8000)
Dockerfile を作成。
YOUR_PROJECT_ID は自身が使用するものに編集し保存します。
(環境変数について、Cloud Run 上でエージェントが動作する際に参照されます。Vertex AI 経由で LLM を呼ぶが、どの Google Cloud プロジェクトのどのリージョンとするかを定義します)
cat > agents/llm-auditor/Dockerfile << 'EOF' FROM python:3.11-slim WORKDIR /app RUN adduser --disabled-password --gecos "" myuser USER myuser ENV PATH="/home/myuser/.local/bin:$PATH" ENV GOOGLE_GENAI_USE_VERTEXAI=1 ENV GOOGLE_CLOUD_PROJECT=YOUR_PROJECT_ID ENV GOOGLE_CLOUD_LOCATION=asia-northeast1 RUN pip install google-adk[a2a] uvicorn a2a-sdk COPY --chown=myuser:myuser . /app/agents/llm-auditor/ RUN pip install -r /app/agents/llm-auditor/requirements.txt WORKDIR /app/agents/llm-auditor EXPOSE 8000 CMD ["uvicorn", "llm_auditor.__main__:a2a_app", "--host", "0.0.0.0", "--port", "8000"] EOF
Cloud Runデプロイの実行
Service URL 確認のための1回目のデプロイです。
(YOUR_PROJECT_ID は仮の値です。実際に使用するプロジェクト ID に置き換えてください)
※本ブログでは簡略化のため –allow-unauthenticated を使用していますが、実運用においては認証設定を推奨します。
認証なしの場合、URL を知っていれば LLM を呼び出せてしまい意図しない課金が発生するリスクがあります。
gcloud run deploy my-adk-agent-2026 \ --source agents/llm-auditor \ --project=YOUR_PROJECT_ID \ --region=asia-northeast1 \ --allow-unauthenticated \ --port=8000
デプロイが完了すると Service URL が出力されます。
(URL はマスキングしております)
Done. 〜〜省略〜〜 Service URL: https://my-adk-agent-2026-xxxxxxxxxxxx.asia-northeast1.run.app
この Service URL を環境変数指定し2回目のデプロイをします。
gcloud run deploy my-adk-agent-2026 \ --source agents/llm-auditor \ --project=YOUR_PROJECT_ID \ --region=asia-northeast1 \ --allow-unauthenticated \ --port=8000 \ --set-env-vars SERVICE_URL=https://my-adk-agent-2026-XXXXXXXXXX.asia-northeast1.run.app
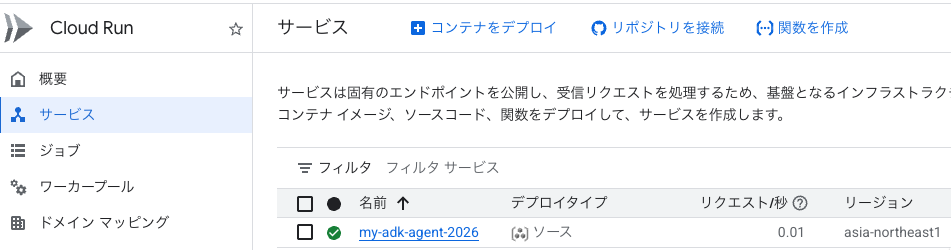
デプロイ完了後、Google Cloud のプロジェクトに入り、Cloud Build、Cloud Run を見てみます。
(Cloud Run のサービスの他にコンテナイメージの保存先として Artifact Registry のリポジトリも作成されます。デプロイの成否は Cloud Build と Cloud Run で確認できるため、本ブログでは Artifact Registry のキャプチャは省きます)
ビルドが成功しています。

以下の通りサービスが作成されています。

Cloud Run のデプロイはこれで以上です。続いて Gemini CLI 側の設定に進みます。
4.Gemini CLIのRemote Subagents設定と実行
外部 AI エージェント(Remote Subagent)の用意ができたので、これを Gemini CLI で使えるよう設定していきます。
まず agent_card_url に設定する URL ですが、 Service URL に /.well-known/agent-card.json を付与したものになります。
https://my-adk-agent-2026-xxxxxxxxxxxx.asia-northeast1.run.app/.well-known/agent-card.json
.gemini/agents/ に Markdown ファイル作成します。
$ vi my-adk-agent.md --- kind: remote name: my-adk-agent-2026 agent_card_url: https://my-adk-agent-2026-xxxxxxxxxxx.asia-northeast1.run.app/.well-known/agent-card.json ---
my-adk-agent.md が作れたので、Gemini CLI を立ち上げます。
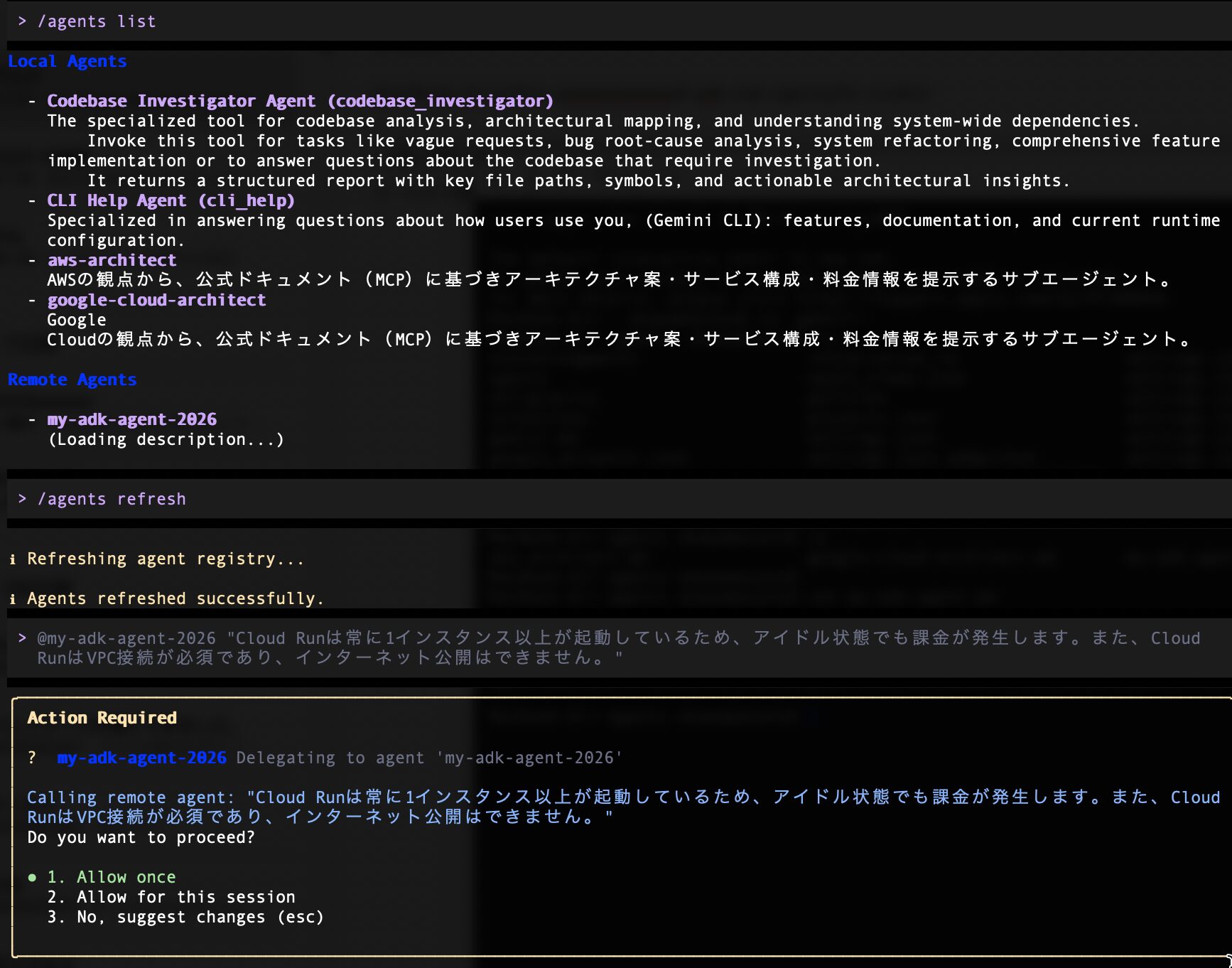
/agents list コマンドを実行すると Remote Agents が1つ表示されています。
> /agents list 〜〜省略〜〜 Remote Agents - my-adk-agent-2026 > /agents refresh ℹ Refreshing agent registry... ℹ Agents refreshed successfully.
ユーザープロンプトは以下を入力しました。
ローカルでの動作確認で使用したものと同じ内容です。
> @my-adk-agent-2026 "Cloud Runは常に1インスタンス以上が起動しているため、アイドル状態でも課金が発生します。また、Cloud RunはVPC接続が必須であり、インターネット公開はできません。"
実行結果は以下です。
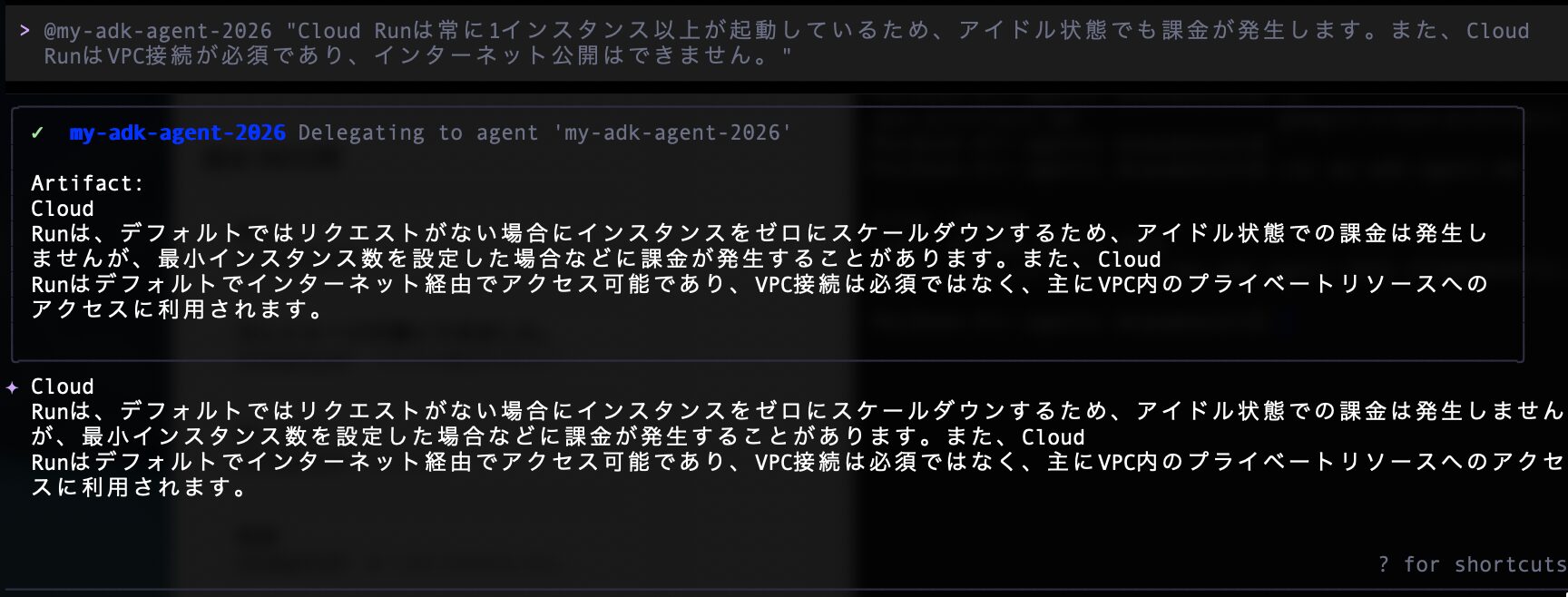
Gemini CLI の動作として メインエージェント が Remote Subagent の返答(Artifact)を受け取り、それをメインエージェント側の回答として出力しているので、同じ内容が2回表示しているものと思われます。
╭──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ │ ✓ my-adk-agent-2026 Delegating to agent 'my-adk-agent-2026' │ │ │ │ Artifact: │ │ Cloud │ │ Runは、デフォルトではリクエストがない場合にインスタンスをゼロにスケールダウンするため、アイドル状態での課金は発生し │ │ ませんが、最小インスタンス数を設定した場合などに課金が発生することがあります。また、Cloud │ │ Runはデフォルトでインターネット経由でアクセス可能であり、VPC接続は必須ではなく、主にVPC内のプライベートリソースへの │ │ アクセスに利用されます。 │ │ │ ╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ ✦ Cloud Runは、デフォルトではリクエストがない場合にインスタンスをゼロにスケールダウンするため、アイドル状態での課金は発生しません が、最小インスタンス数を設定した場合などに課金が発生することがあります。また、Cloud Runはデフォルトでインターネット経由でアクセス可能であり、VPC接続は必須ではなく、主にVPC内のプライベートリソースへのアクセ スに利用されます。
Gemini CLI の実行は一旦これで以上ですが、そもそも Remote Subagent で使われたモデルは何でしょうか。
llm-auditor の critic/agent.py と reviser/agent.py をみてみると、gemini-2.5-flash が指定されています。
## critic/agent.py
critic_agent = Agent(
model="gemini-2.5-flash",
name="critic_agent",
instruction=prompt.CRITIC_PROMPT,
tools=[google_search],
after_model_callback=_render_reference,
)
## reviser/agent.py
reviser_agent = Agent(
model="gemini-2.5-flash",
name="reviser_agent",
instruction=prompt.REVISER_PROMPT,
after_model_callback=_remove_end_of_edit_mark,
)
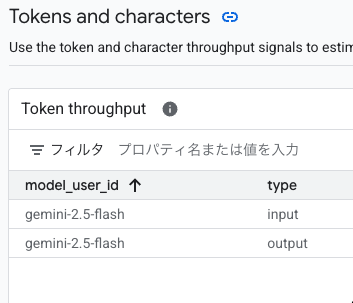
Vertex AI Model Garden の モニターを見てみます。
Token throughput から gemini-2.5-flash が使われていたことが確認できました。
Gemini CLI のメインエージェント、Remote Subagent のどちらも Gemini モデルを使っている状態です。
続いては 本ブログのタイトルにもある通り、Gemini 以外のモデルを使う形に変えます。
Remote Subagent でモデル指定している箇所を Gemini 外のモデル、今回は Mistral AI のモデルに変更してみます。
5.Remote Subagentのモデル変更とGemini CLIのRemote Subagents実行
Remote Subagentのモデル変更
Mistral AI のモデルに変更しますが、Mistral AI とはフランスのスタートアップ企業で、ヨーロッパ最大級の AI 企業の一つです。
顧客事例を見ると、ASML(世界的な半導体装置メーカー) や Stellantis(自動車メーカー)、Cisco や SAP といった大手企業での活用事例が紹介されています。
このモデルを使用できるよう、Vertex AI の Model Garden で有効化します。
Mistral Small 3.1 (25.03) を有効化します。
(Mistral AI のサイトによると Mistral Small 3.1 (25.03) は Gemma 3 や GPT-4o Mini を上まわる性能とのことです)

念の為、割り当てとシステム上限を確認しておきます。

値が設定されています。
もし、値が0のモデルを使うと以下のような429エラーが出力されるので事前に確認しておくことをお勧めします。
Error code: 429 - {'error': {'code': 429, 'message': 'Resource has been exhausted (e.g. check quota).'
Google Cloud 上での設定は以上です。
続いてコードの編集をします。
Mistral AI のモデルは LiteLLM 経由 で使うので、critic/agent.py とreviser/agent.py を編集します。
両ファイル共通し、LiteLlm の import 文を追加、model 指定部分を書き換えます。
from google.adk.models.lite_llm import LiteLlm
〜〜省略〜〜
agent = Agent(
model=LiteLlm(model="vertex_ai/mistralai/mistral-small-2503"),
)
critic/agent.py に関しては以下を削除します。
(Gemini モデル用のツールなので削除しておきます)
from google.adk.tools import google_search 〜〜省略〜〜 tools=[google_search],
続いて requirements.txt に litellm を追加します。
〜〜省略〜〜 litellm>=1.0.0 〜〜省略〜〜
先ほど確認した割り当てとシステム上限より、Mistral Small 3.1 (25.03) は us-central1 リージョンで利用できるようなので、最後に Dockerfile を編集します。リージョンを us-central1 に編集します。
〜〜省略〜〜 ENV GOOGLE_CLOUD_LOCATION=us-central1 〜〜省略〜〜
ここまでできたらデプロイを実行します。
(YOUR_PROJECT_ID は仮の値です。実際に使用するプロジェクト ID に置き換えてください)
gcloud run deploy my-adk-agent-2026 \ --source agents/llm-auditor \ --project=YOUR_PROJECT_ID \ --region=asia-northeast1 \ --allow-unauthenticated \ --port=8000 \ --set-env-vars SERVICE_URL=https://my-adk-agent-2026-XXXXXXXXXX.asia-northeast1.run.app
デプロイ完了です。
(デプロイ完了の旨のメッセージを確認しているのでGoogle Cloud 環境のキャプチャは省略します)
〜〜省略〜〜 Done. Service [my-adk-agent-2026] revision [my-adk-agent-2026-xxxxx-xxx] has been deployed and is serving 100 percent of traffic. Service URL: https://my-adk-agent-2026-xxxxxxxxxxxx.asia-northeast1.run.app
続いて Gemini CLI を立ち上げ、Remote Subagents を実行してみます。
Gemini CLIのRemote Subagents実行
Gemini CLI を立ち上げ、/agents list コマンドで Remote Agents が表示されていることを確認の上、ローカルでの動作確認で使用したものと同じ内容をユーザープロンプトに入力します。
@my-adk-agent-2026 "Cloud Runは常に1インスタンス以上が起動しているため、アイドル状態でも課金が発生します。また、Cloud RunはVPC接続が必須であり、インターネット公開はできません。"
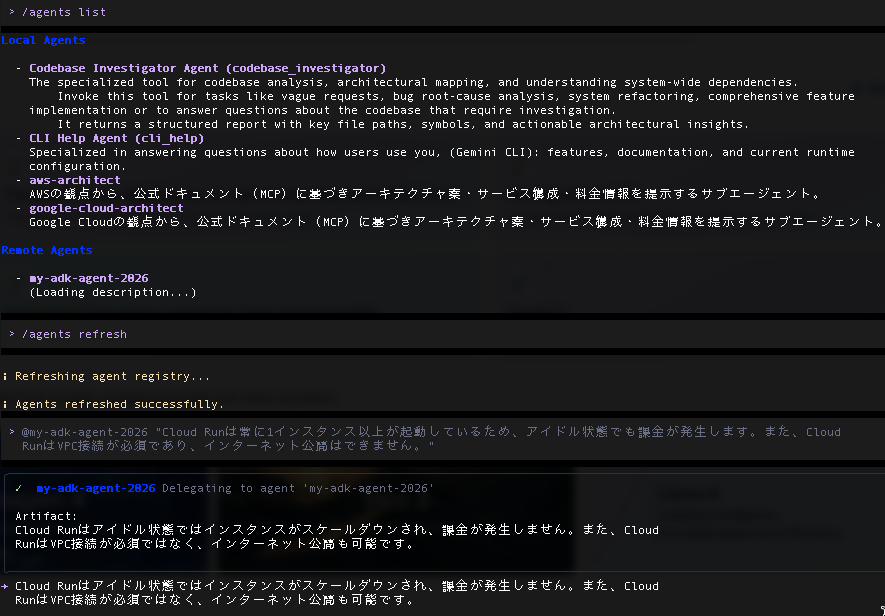
出力結果が Gemini モデルの時と変わっています。
╭────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ │ ✓ my-adk-agent-2026 Delegating to agent 'my-adk-agent-2026' │ │ │ │ Artifact: │ │ Cloud │ │ Runは、デフォルトではリクエストがない場合にインスタンス数がゼロになり、アイドル状態での課金は発生しません。ただし、最小インスタンス数を設定したり、CPU │ │ 常時割り当てを有効にした場合は課金が発生します。また、Cloud RunはVPC接続が必須ではなく、デフォルトではインターネット公開が可能です。 │ │ │ ╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ ✦ Cloud Runは、デフォルトではリクエストがない場合にインスタンス数がゼロになり、アイドル状態での課金は発生しません。ただし、最小インスタンス数を設定したり、CPU常時割 り当てを有効にした場合は課金が発生します。また、Cloud RunはVPC接続が必須ではなく、デフォルトではインターネット公開が可能です。
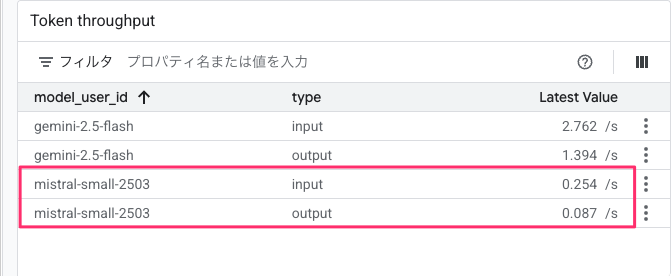
この出力結果が Mistral AI のモデルによるものか、Vertex AI Model Garden のモニターを見てみます。
Token throughput より mistral-small-2503 のトークン消費の存在が確認できました。
モデルの切り替えから Gemini CLI の Remote Subagents 実行はこれで以上です。
作成した Cloud Run サービスと Artifact Registry のイメージは以下のコマンドで削除できます。
(YOUR_PROJECT_ID は仮の値です。実際に使用するプロジェクト ID に置き換えてください)
# Cloud Run サービスの削除 gcloud run services delete my-adk-agent-2026 \ --region=asia-northeast1 \ --project=YOUR_PROJECT_ID # Artifact Registry のイメージ削除 gcloud artifacts docker images delete \ asia-northeast1-docker.pkg.dev/YOUR_PROJECT_ID/cloud-run-source-deploy/my-adk-agent-2026 \ --delete-tags \ --project=YOUR_PROJECT_ID
6.おわりに
Remote Subagents の概要説明から始まり、Google Cloud(Cloud Run)へのデプロイ、Gemini CLI での設定と実行、さらにモデルを Mistral Small 3.1 (25.03) に切り替えて使用する方法を紹介しました。
今回はサンプルエージェント(llm-auditor)を使用しましたが、Google Search ツールの組み込みなど Gemini モデルありきのものでした。
Gemini 以外のモデルを本格活用したいのであれば、使用するモデルに合わせた専用エージェントを実装するのが良いかと思います。
Mistral AI モデルを使用しましたが、Vertex AI では Anthropic Claude モデルや Meta Llama モデルも利用可能です。
(Vertex AI Model Garden でそのモデルが利用可能状態であり、割り当てとシステム上限にて割り当て値がある場合)
Remote Subagents をうまく活用できれば、モデルやエージェントの組み合わせの幅が広がり、AI エージェントツールの可能性をさらに引き出せるかと思います。
本ブログを読んで興味を持った方はぜひ試してみてください。


