
2026年2月24日、AWSからKiro Powerとして「AWS Observability Power」がリリースされました。これにより、我々はKiroのAIエージェント支援ワークフローを使用して、インフラストラクチャとアプリケーションの健全性の問題をより迅速に調査できるようになります。
公式発表によると、このPowerは「発生中のインシデントの平均解決時間 (MTTR) の短縮」と「オブザーバビリティスタックの予防的改善」という2つの重要なニーズに対応するために設計されたとのこと。
「本当にAIエージェントでMTTRは短縮できるのか?」
「現場の泥臭い調査業務を AI が自律的に代行し、エンジニアはより高度な意思決定に集中できるのか?」
今回は、MSPの現場で実際に起こり得る「EC2のIAM権限エラーに伴うASG(Auto Scaling Group)の無限ループ障害」をシナリオとし、MCPを設定したKiro-CLIと、未設定(デフォルト)のKiro-CLIで、トラブルシューティングの精度とスピードにどのような差が出るのかを徹底検証しました。結論から言うと、MCPの有無は「アシスタントとしてのAI」と「自律的(Agentic)なインシデント対応パートナー」ほどの決定的な違いを生み出します。
1. AWS Observability Powerがもたらす4つのMCPと8つのガイド
検証に入る前に、今回追加された機能を簡単におさらいします。AWS Observability Powerは、対象を絞った4つの専用MCP(モデルコンテキストプロトコル)サーバーをパッケージ化しています。
- CloudWatch MCP サーバー(オブザーバビリティデータ用)
- Application Signals MCP サーバー(アプリケーションパフォーマンスモニタリング用)
- CloudTrail MCP サーバー(セキュリティ分析とコンプライアンス用)
- AWS Documentation MCP サーバー(コンテキスト参照アクセス用)
さらに、インシデント対応、アラート、パフォーマンス監視、セキュリティ監査、ギャップ分析を網羅する8つの包括的なステアリングガイドが含まれており、AIエージェントにAWSの専門知識を直接注入します。検証を通じて、これらがセットアップ系、分析系、データソース選択系といった実践的な構成になっていることがわかりました(詳細は後述します)。
2. 検証シナリオとアーキテクチャ
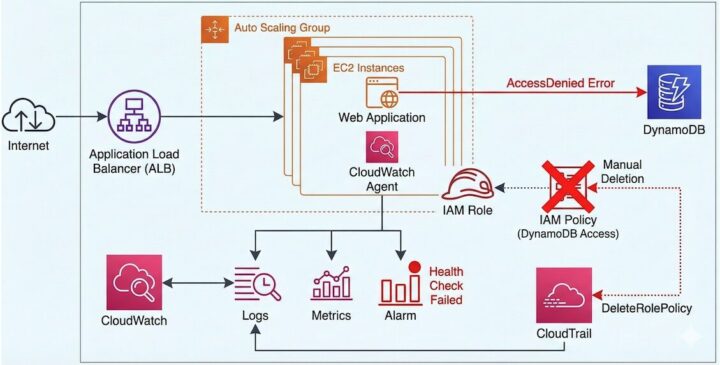
今回の検証環境は、Webアプリケーションの構成です。
- アーキテクチャ: ALB → EC2 (Auto Scaling Group) → DynamoDB
- 障害シナリオ:
- 正常稼働中のEC2インスタンスロール(
app-scenario1-ec2-role)から、DynamoDBへのアクセス権限(ポリシー)が手動で誤って削除される。 - アプリケーションのヘルスチェックエンドポイント(
/health)がDynamoDBへのScanを実行できず、HTTP 503エラーを返す。 - ALBのヘルスチェックに失敗し、ASGがインスタンスの終了と新規起動を無限に繰り返す。
- 正常稼働中のEC2インスタンスロール(
この状況に対し、Kiro-CLIに「根本原因の特定と修復手順の提案」を指示しました。
指示プロンプト
shinji-ezaki-incident-test-scenario1-healthcheck-alarmで障害が発生しています。以下の観点で根本原因を特定してください
- 現在の状態確認(メトリクス、ログ、ヘルスチェック)
- CloudTrailで障害発生前24時間の変更イベントを確認
- 関連するAWSリソースの設定変更履歴
- 依存サービスの状態確認
- 根本原因の特定と修復手順の提案
3. 【検証1】デフォルト状態の Kiro-CLI(MCPなし)の場合
まずは、従来のデフォルト状態で調査を依頼しました。
【調査のプロセスと技術的限界】
- メトリクス・状態の確認:
describe-alarmsなど基本的なCLIの組み合わせで、UnHealthyHostCountの上昇と、ASGによるインスタンスの頻繁な入れ替えを正しく検知しました。 - イベント検索の限界:
lookup-eventsを使用してCloudTrailからリソース変更を検索しましたが、属性ベースの単純検索であるため、大量のRunInstances/TerminateInstancesログに埋もれ、原因となったポリシー削除の特定に時間を要しました。 - 泥臭いログ取得: SSM Session Manager経由で
cat /var/log/app.logなどを実行して強引にログを取りに行きましたが、出力結果にバイナリデータ(ELFヘッダなどの文字化け文字)が混入しました。
実際のCLI出力ログ(一部抜粋・マスクあり)
Starting session with SessionId: user@example.com-xxxxxxxxxxxxxxxx ... ^?ELF^B^A^A^@^@^@^@^@^@^@^@^@^C^@>^@^A^@^@^@M-^@^ ^@^@^@^@^@^@^@^@ M-^H^C^@^@^@^@^@^@^@^P^@^@^@^@^@^@^B^@^@^@^F^@^@^@M-(^@^@^@^@^@^@ ... ERROR:main:Health check failed: An error occurred (AccessDeniedException)
【評価】 最終的に文字化けの海から AccessDeniedException を見つけ出し、IAM権限不足には辿り着きました。しかし、ノイズの多さやロググループ不在時のエラーなど、エンジニアが横についてプロンプトで軌道修正をする必要があり、「高度なCLIラッパー」の域を出ない印象でした。
4. 【検証2】AWS Observability Power(MCPあり)が見せた「自律性」
次に、AWS Observability Powerを有効にして検証しました。ここで、AIエージェントの「Agentic(自律的)」な挙動に驚かされることになります。
プロンプト1つで「SREの思考プロセス」を再現
指示のプロンプトは先ほどと同様です。指示MCPありのAIは、単にコマンドを逐次実行するのではなく、SREが障害調査で行う「仮説構築と検証」のプロセスを自律的に進めました。
- メトリクスからの仮説立案: ヘルスチェックの失敗(503エラー)とASGによるインスタンスの入れ替えループを即座に検知。
- 証拠の収集(SSMの高度な活用):
ssm send-command(AWS-RunShellScript) を自動選択し、Unhealthyなインスタンスと新しく起動したインスタンスの両方にコマンドを並列送信。プロセス状態、ログ、ローカルのcurlテスト結果を一括で取得・比較しました。非MCP時のようにバイナリ文字化けを起こすことなく、必要なログだけを抽出しています。 - 根本原因の特定: CloudTrailの変更履歴とアプリケーションログを突き合わせ、「IAM権限不足」という真因に到達。
高い解像度:生成されたPost-Mortem(事後検証)レポート
最も驚かされたのは、調査完了後にAIが即座に出力したレポートの質です。単なるエラー文の提示ではなく、障害のメカニズム、タイムライン、具体的な修復コード、そして再発防止策まで網羅された、そのままチームに共有できるレベルのドキュメントでした。
以下が、実際にAIが生成したレポートの抜粋です。
[詳細調査レポート – 根本原因の完全特定]
1. 障害の詳細分析 両方のインスタンスの
/var/log/app.logにて以下の共通エラーを確認しました。
- エラー内容:
AccessDeniedException: User: .../app-scenario1-ec2-role/i-0xxxxxxxxxxxxxxxA is not authorized to perform: dynamodb:Scan on resource: arn:aws:dynamodb:...:table/app-scenario1-items- メカニズム: ヘルスチェックエンドポイント(
/health)がDynamoDBへのScan操作を実行しようとしていますが、IAMロールに権限が付与されていないため例外が発生し、HTTP 503を返しています。2. 障害のタイムライン分析 (JST)
- 11:11:05 – ASGが古いインスタンスを終了開始
- 11:12:00 – 新しいインスタンス (
i-0...A) を起動- 11:13:16 – ヘルスチェック失敗(503エラー発生)
- 11:18:08 – 新しいインスタンス (
i-0...B) を起動(ASGによる入れ替えループ)3. 修復手順(即時対応) 以下のインラインポリシーを作成し、対象のIAMロールにアタッチしてください。
{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Action": [ "dynamodb:Scan", "dynamodb:GetItem", "dynamodb:Query" ], "Resource": "arn:aws:dynamodb:ap-northeast-1:xxxxxxxx:table/app-scenario1-items" }] }実行コマンド:
aws iam put-role-policy --role-name app-scenario1-ec2-role --policy-name DynamoDBReadAccess --policy-document file:///tmp/dynamodb-policy.json4. 再発防止策(中長期対応)
- ヘルスチェック設計の改善: DynamoDBへの依存を削除した軽量なヘルスチェックエンドポイント(
/health)と、依存サービスを含めた深いヘルスチェック(/health/deep)を分離することを推奨します。- IaCの改善: CloudFormationテンプレートに必要なIAM権限を明示し、デプロイ前のレビュープロセスを強化してください。
このレポートを見たとき、AIが単にログを検索しただけでなく、「ヘルスチェックの設計不備」というアーキテクチャ上の課題にまで踏み込んでいることに感心しました。
5. 比較検証:MCP設定の効果とエンジニアへの価値
| 比較項目 | デフォルト状態 (MCPなし) | AWS Observability Power (MCPあり) |
|---|---|---|
| 調査の深度 | 基本CLIコマンドの手探りな試行錯誤 | 並列処理と自律的な証拠収集による多角的な分析 |
| ログ取得方法 | 非インタラクティブSSM Session(バイナリ混入等のノイズあり) | send-command による構造化データのスマートな並列取得 |
| レポートの構造 | ログ断片の羅列 | タイムライン・証拠・具体的な修復コマンドを含むRCA形式 |
| 解決へのアプローチ | ユーザーのプロンプトによる追加指示が必要 | アーキテクチャの改善案(ヘルスチェックの分離など)まで自律的に提示 |
専門知識の注入:AIの思考を形作る「8つのステアリングガイド」
MCPありの場合にAIのこうした卓越した思考を支えているのは、背後で機能している8つの包括的なステアリングファイルです。今回の検証を通じて、実際のファイル構成は、単なるマニュアルの羅列ではなく、SREの実務に即した「セットアップ系」「分析・監査系」「データソース選択系」に体系化されていることがわかりました。
【分析・監査系ガイド】
incident-response.md: インシデント対応時のAI行動ガイドラインlog-analysis.md: ログ分析の手法とエラー特定のプロセスobservability-gap-analysis.md: コード内のログ出力不足やトレースIDなどの欠落(ギャップ)分析performance-monitoring.md: パフォーマンス問題の特定と監視手法security-auditing.md: IAM権限エラーなどを含むセキュリティ監査
【セットアップ・データソース選択系ガイド】
alerting-setup.md: アラート設定のベストプラクティスapplication-signals-setup.md: Application Signalsの効果的な導入・設定cloudtrail-data-source-selection.md: CloudTrailをはじめとする最適なデータソースの選択基準
インシデント対応を迅速に行うため、発生中のアラームを調査する際、Powerはこれらのガイドから関連する運用シグナルを動的に読み込みます。 AIエージェントはその時点のトラブルシューティングタスクに「必要なコンテキストのみ」を受け取るため、無駄な試行錯誤を回避し、経験豊富なエンジニアに近い最短経路で原因を特定できるのです。
6. まとめ:次世代のオブザーバビリティワークフローへ
今回の検証を通して、AWS Observability Powerが単なる「CLIツールの拡張」ではなく、AWSの深いドメイン知識をAIエージェントに注入する「専門知識のブリッジ」であることが実証されました。
特に、SREの思考プロセスを模倣し、単なるエラー解消にとどまらず「システムの予防的改善」まで踏み込んだ提案を行うAgenticな振る舞いには、次世代のインシデント対応の可能性を強く感じました。
また、今回はインシデント対応にフォーカスしましたが、このPowerには「自動ギャップ分析(observability-gap-analysis.md)」も含まれています。ログに記録されていないエラー、相関IDの欠落、分散トレースの欠如など、不足しているインストルメンテーション(計装)パターンを特定し、予防的な改善案を提示してくれる機能も備わっています。
全てのクラウドエンジニア、SREの皆様へ。
AIを単なるアシスタントから真の「自律型パートナー」へと変えるこの強力な基盤を、ぜひ体験してみてください。


