
目次
1.はじめに
環境情報
2.Browser Agentについて
3.Browser Agentを使ってみた
ローカルでの書き込みブラウザ操作
外部Webサイトへのアクセスとブラウザ操作
4.おわりに
1.はじめに
Gemini CLI の組み込み Subagents には Browser Agent (experimental) という、Web ブラウザ操作を自然言語で実行できる Subagent があります。
本ブログ執筆時点では experimental 版(開発途中の先行公開機能)でありますが、実際に使ってみた結果を紹介します。
やってみたことは以下の2つです。
- ローカル環境でのブラウザ操作:操作検証用に作成した HTML ファイルをローカルサーバで表示し、Browser Agent にてフォームへの入力・ボタンの押下・結果画面のスクリーンショットの取得まで実行する。
- 外部 Web サイトへのアクセスとブラウザ操作:本オウンドメディア(iret.media)にアクセスし、人気の記事ランキングセクションまでスクロール。その画面のスクリーンショットの取得までを実行する。
※ 実在する Web サービスに対して自動操作を行う場合、その Web サービスの利用規約に抵触する可能性があるので、書き込み系作業に関しては検証用の HTML ファイルをローカルに用意し、それを操作する形をとっております。
環境情報
- macOS:Tahoe 26.3.1
- Node.js のバージョン(
node --version):24.11.1 - Gemini CLI のバージョン(
gemini --version):0.35.3 - Chrome のバージョン:146.0.7680.81
2.Browser Agentについて
Browser Agent を使うことで、Web ブラウザ操作を AI に実行させることができます。
ユーザープロンプトの指示をもとに AI がブラウザを立ち上げ、アクセシビリティツリー(画面の構造)を読み解きながら指示内容の実現をはかります。
利用可能状態にするには設定ファイル(settings.json)に以下を追加する必要があります。
{
"agents": {
"overrides": {
"browser_agent": {
"enabled": true
}
}
}
}
オプションとしてセッションモードの設定も可能です。
{
"agents": {
"overrides": {
"browser_agent": {
"enabled": true
}
},
"browser": {
"sessionMode": "persistent"
}
}
}
セッションモードは3種類です。
- persistent:デフォルト。~/.gemini/cli-browser-profile/ に保存されたプロファイル(Cookieや履歴など)を使用して Chrome を起動する。AI による操作だが、プロファイルを保存しているのでセッションが残った状態での操作となる。
- isolated:セッション終了後に削除される一時プロファイルを使用してChrome を起動する。(persistent とは逆のシークレットモードでの操作イメージです)
- existing:すでに起動中のChrome に接続して操作する。例えば人が立ち上げた、すでに起動中の Chrome に対して操作をさせたい場合に使用する。
本ブログでの Browser Agent 使用時のセッションモードは persistent としています。
他にも Visual agent というオプションがあります。(本ブログではこのオプションは使用いたしません)
Visual agent を有効化すると、視覚的な識別、たとえば、「黄色のボタンをクリックする」または「赤いエラーメッセージを見つける」のような指示にも Browser Agent が対応できるようになります。
注意事項として、Visual agent の使用には API キーか Vertex AI での認証を使用している必要があります。

3.Browser Agentを使ってみた
ローカルでの書き込みブラウザ操作
Browser Agent での書き込み操作を試す準備として、あらかじめローカルに HTML ファイル(test_page.html)を作成、その HTML ファイルを配置しているディレクトリにて python3 -m http.server 8000 を実行し、ローカルでシンプルなウェブサーバーを起動できる状態を作っております。
$ ls test_page.html $ python3 -m http.server 8000 Serving HTTP on :: port 8000 (http://[::]:8000/) ...
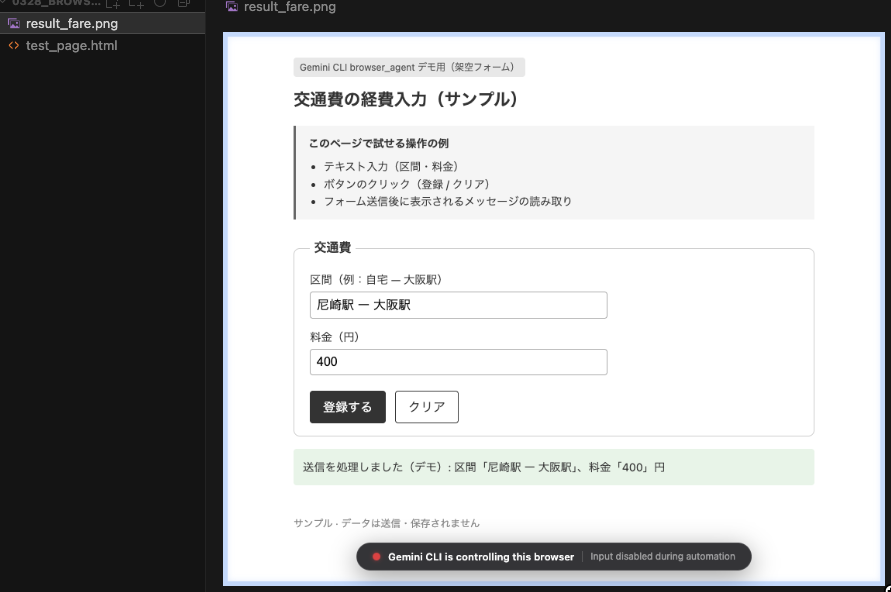
この状態でブラウザに http://localhost:8000/test_page.html を入力すると以下のページが表示されます。
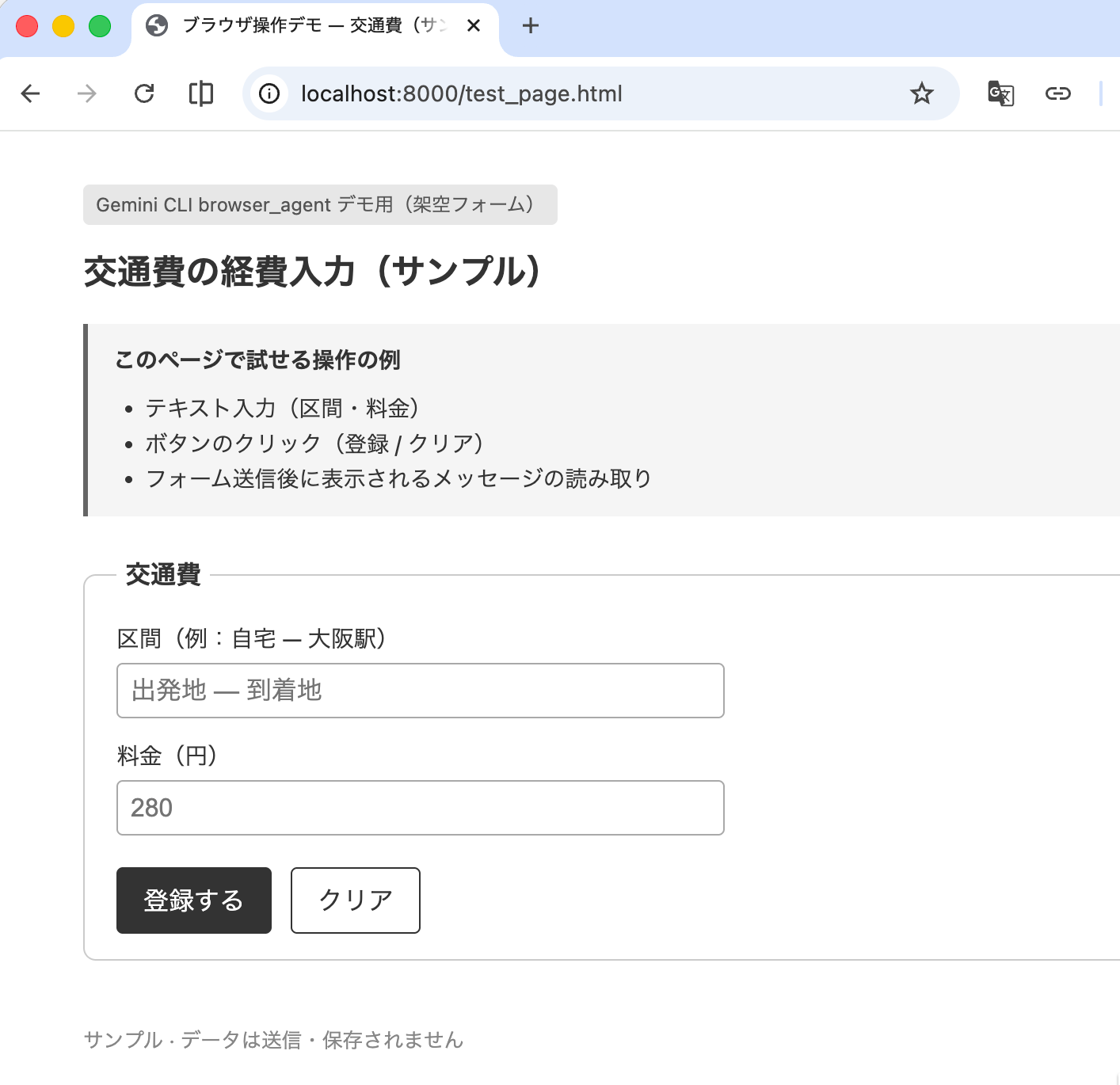
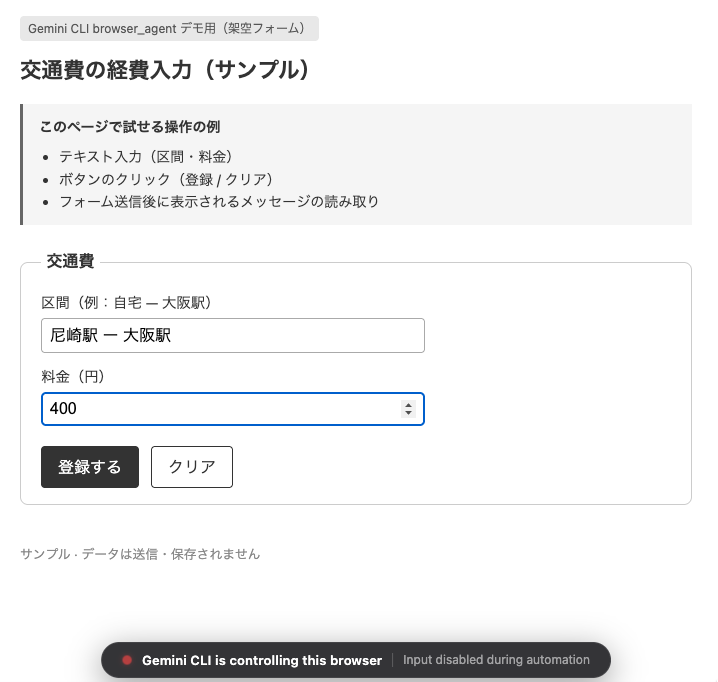
作成した HTML ファイル(test_page.html)の中身ですが、交通費フォームの体裁で、区間と料金の入力箇所があり登録するボタンとクリアボタンを置いています。
Browser Agent の利用にあたってのユーザープロンプトの内容ですが、まずは指定区間の料金を Google 検索で調べさせ、その後に、http://localhost:8000/test_page.html にアクセスし、区間と料金を入力。登録するボタンを押下し、最後にスクリーンショットを撮るような指示とします。
Gemini CLI を起動し、以下の内容を入力します。
まずGoogle検索で尼崎駅から大阪駅のJR往復運賃を調べて控えておいてください。その後、browser_agent で http://localhost:8000/test_page.html を開き、区間に『尼崎駅 ー 大阪駅』、料金に先ほど調べた運賃を入力して登録してください。最後に、その画面のスクリーンショットを撮り、現在のディレクトリに result_fare.png という名前で保存してください。

入力すると指示通りまずは指定区間の運賃情報を Google 検索し、その次にローカルサーバーを起動、browser_agent を使った処理が始まりました。
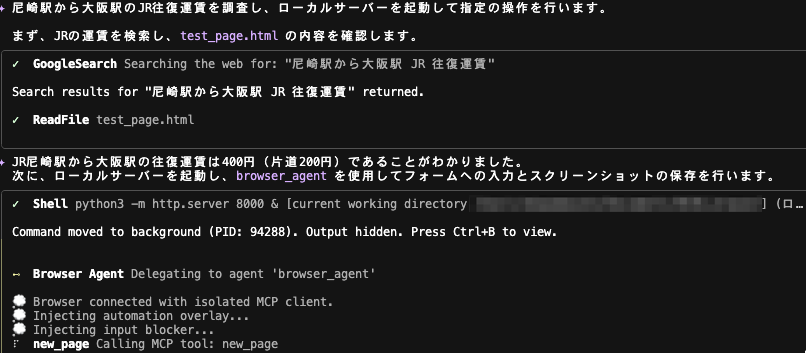
browser_agent の処理にあたりツールの実行承認を進めていきます。
new_page の実行を承認すると、ブラウザにて指定 URL のページが表示されました。
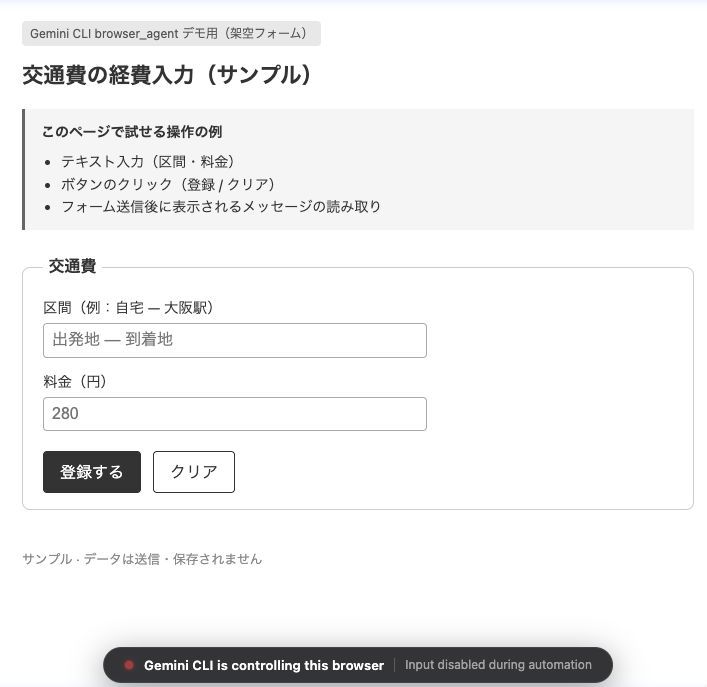
順次ツール実行を要求されるので承認していきます。
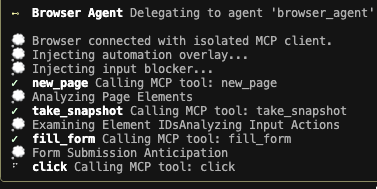
fill_form でフォーム入力が実行。区間と料金が入力されました。
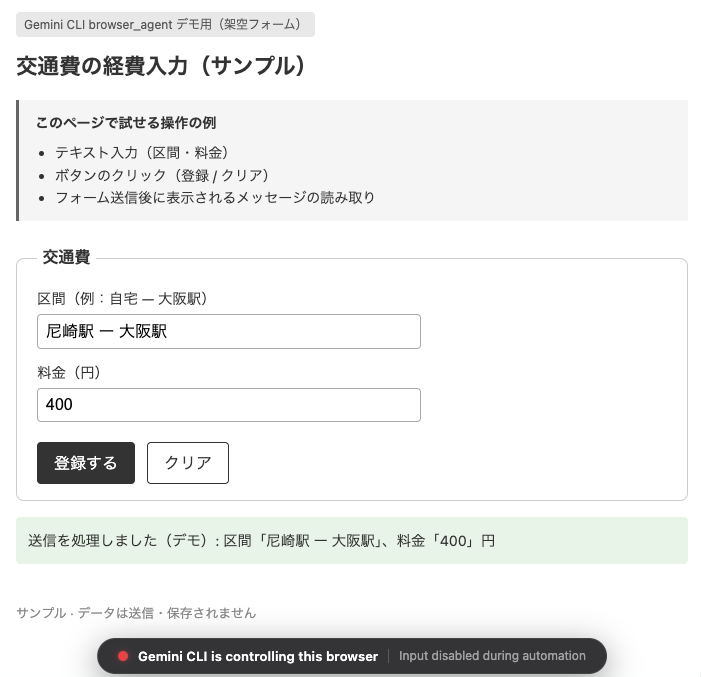
click で登録するボタンを押下。登録するボタンを押下すると送信を処理しました〜という文言が表示されるのですが、それが表示されています。
take_screenshot でスクリーンショットが取得され、browser_agent による全処理完了後、実行結果と実行内容のサマリが出力されました。
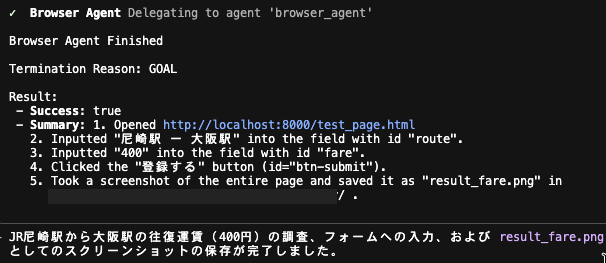
ローカルに指定の名前でスクリーンショットが保存されていることも確認できました。
外部Webサイトへのアクセスとブラウザ操作
外部の Web サイトを指定する形で Browser Agent を実行します。
本ブログ記事を掲載している iret.media を対象に、AI に人気の記事ランキングを表示しているところへスクロールしてもらい、その画面のスクリーンショットの取得までを実行させます。
Browser Agent での外部 Web サイトへのアクセスにあたり、アクセス先サイトのドメインを設定ファイル(settings.json)で許可していなければ、そのサイトにアクセスすることができません。
設定ファイルは以下としています。
"agents": {
"overrides": {
"browser_agent": {
"enabled": true
}
},
"browser": {
"sessionMode": "persistent",
"allowedDomains": [
"iret.media"
]
}
}
browser の項目に allowedDomains の配列を作り、そこに iret.media (アクセスしたい Web サイトのドメイン)を設定しました。
これにより Browser Agent が立ち上げたブラウザから指定ドメインのサイトへアクセスできるようになります。
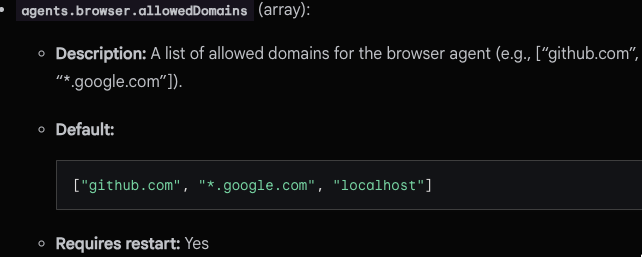
このドメイン許可設定についてですが、Gemini CLI configuration の agents より、デフォルトでは “github.com”, “*.google.com”, “localhost” が許可されています。
これら以外のドメインに対して Browser Agent でアクセスを実現したい場合、agents.browser.allowedDomains で明示的にドメインを指定する必要があるようです。
実行するユーザープロンプトの内容としては iret.media にアクセス、人気の記事ランキング部分までスクロールし、最後にスクリーンショットを撮るような指示とします。
Gemini CLI を起動し、以下の内容を入力します。
@browser_agent iret.mediaにアクセスし、ページの読み込みが完了したら、ページを下方向にスクロールして人気の記事のランキングセクションを見つけてください。見つけたら、1位から5位までがわかる形でランキング部分のスクリーンショットを撮り、現在のディレクトリに result_ranking.png という名前で保存してください。

入力するとローカルでの検証時と同様、browser_agent の処理が始まります。
ツールの実行を承認すると、ブラウザにて iret.media のサイトが表示されました。(ここからのツール処理については基本的にローカルでの操作検証時と同様なので省略します)
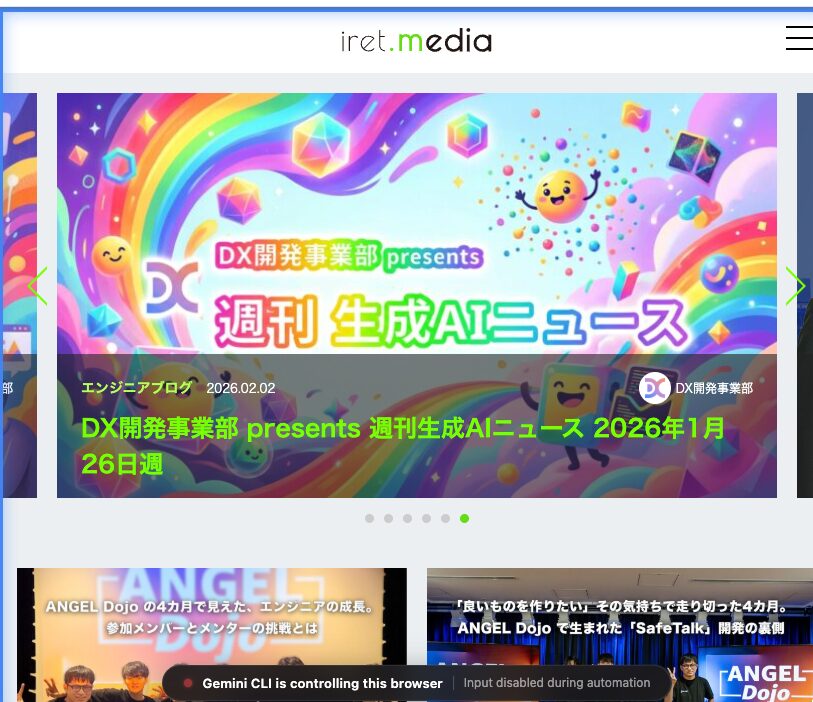
続けてツール実行を承認していくと、ランキング部分を特定、ブラウザの表示がランキング部分を表示する形となりました。
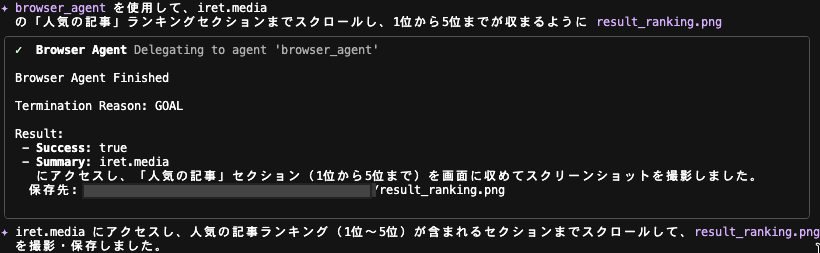
スクリーンショットが取得され、browser_agent による全処理完了後、実行結果と実行内容のサマリが出力されました。
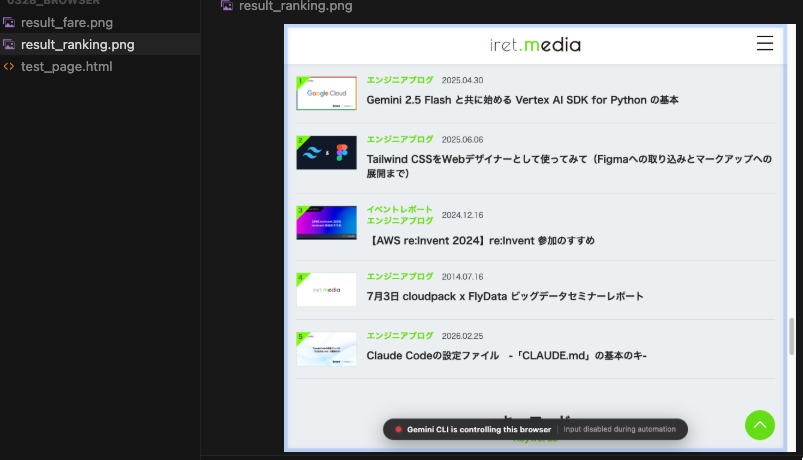
ローカルに指定の名前でスクリーンショットが保存されていることも確認できました。
4.おわりに
Browser Agent にてローカル環境での書き込み操作と外部 Web サイトへの読み込み操作を試してみました。
まだ experimental 版ではありますが、この機能を使うことでブラウザ操作を自然言語ベースで実施できます。
定型作業の自動化や、Visual agent や他の機能も組み合わせればより柔軟な作業の自動化にも応用できるかと思います。
まだ experimental 版ではありますが、興味のある方はぜひ試してみてください。
