こんにちは、クラウドインテグレーション事業部の佐藤優太です。
本記事は、2025年11月に登場したAWS Application Load Balancerのヘルスチェックログ機能を実際に検証した内容をまとめたものです。
- ALBのヘルスチェックの基本を理解する
- 2025年11月に登場したALBヘルスチェックログ機能を知る
- ALBヘルスチェックログ機能の検証から活用例について知る
上記を本記事のゴールとしています。
ALBのヘルスチェックについて学習したい方、「原因不明のUnhealthy」に悩まされた経験がある方にご覧いただければ幸いです!
アジェンダ
- ALBのヘルスチェックとは?
- 待望のアップデート!ALBヘルスチェックログ機能とは?
- 【検証】ヘルスチェックログの設定
- 【検証】意図的な障害を起こしてログを確認
- まとめ
ALBのヘルスチェックとは?
ALBのヘルスチェックとは、ロードバランサーが登録された各ターゲット(EC2インスタンスなど)に対して定期的にHTTPリクエストを送信し、正常に応答できるかどうかを確認する仕組みです。
ターゲットが指定された回数連続でヘルスチェックに失敗すると Unhealthy と判定され、そのターゲットへのトラフィックのルーティングが自動的に停止されます。その後、指定された回数連続で成功すると Healthy に復帰し、再びリクエストが転送されるようになります。
設定項目の詳細については、公式ドキュメント(ヘルスチェック)をご参照ください。
待望のアップデート!ALBヘルスチェックログ機能とは?
これまで、ALBのターゲットが Unhealthy になった際、ターゲット側のアプリケーションログを確認しようにも、リクエストが届いていなかったり、Auto Scalingによってインスタンスがすでに終了していたりと、原因特定が困難なケースが少なくありませんでした。
2025年11月21日、この課題を解消するアップデートとして、ALBにヘルスチェックログ機能が追加されました。
AWS Application Load Balancer がヘルスチェックログのサポートを開始
これにより、詳細なターゲットヘルスチェックログデータ(ターゲットヘルスチェックステータス、タイムスタンプ、ターゲット識別データ、失敗理由)をAmazon S3 バケットに直接送信できるようになりました。
ログデータを可視化できるため、AWS サポートに連絡しなくてもトラブルシューティングを迅速に行うことができます。
ログは 5 分ごとに自動的に S3 バケットに配信され、標準の S3 ストレージコスト以外に追加料金はかかりません。
【検証】ヘルスチェックログの設定
ここから、実際にヘルスチェックログを設定していきます。
用意するリソースは下記です。
- ALB(ヘルスチェックログ有効)
- EC2×1台(Apache インストール済み・
/healthcheck.htmlを配置) - S3(ヘルスチェックログ保存先)
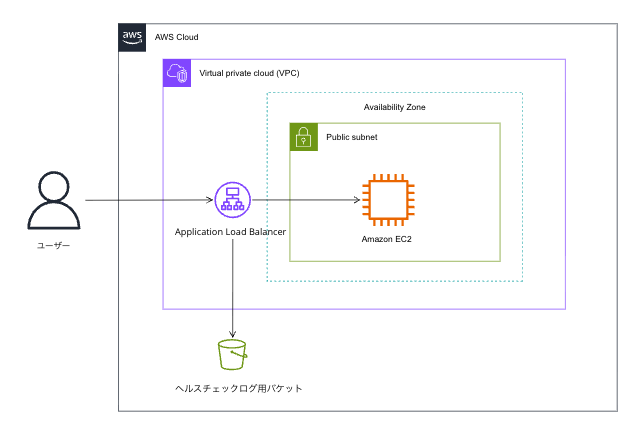
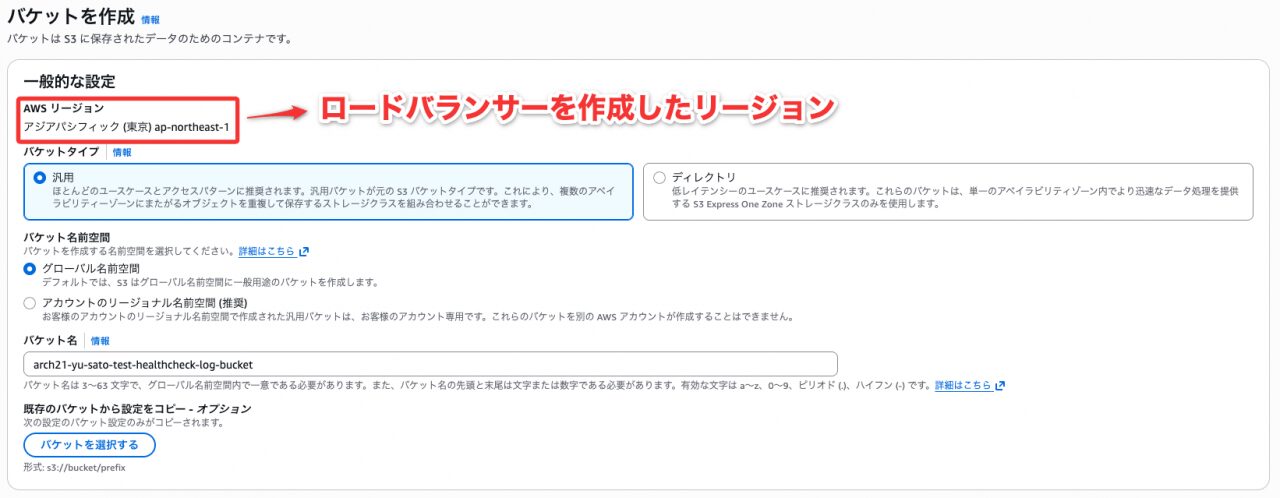
ステップ1:S3 バケットを作成する
- リージョン:ALBと同じリージョン(東京)を選択
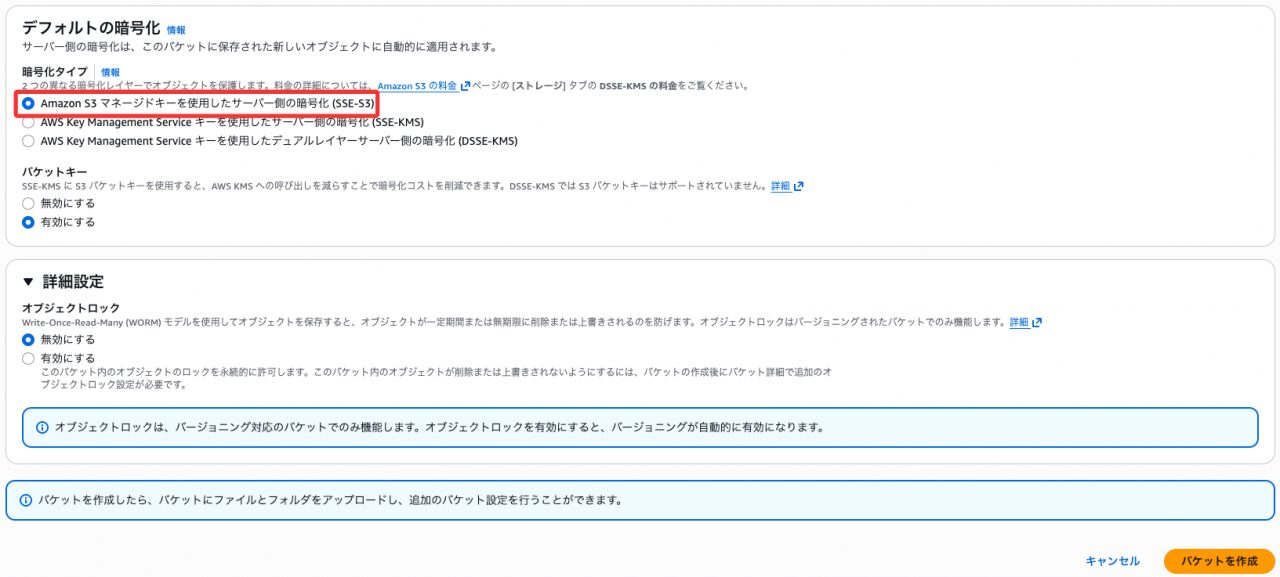
- 暗号化:Amazon S3 マネージドキー(SSE-S3)を選択(SSE-KMSは非対応)
ステップ 2:S3 バケットにポリシーをアタッチする
「ALBサービスが、このS3バケットにログファイルを書き込むことを許可する」という内容のバケットポリシーをアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logdelivery.elasticloadbalancing.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::{バケット名}/{プレフィックス}/AWSLogs/{AWSアカウントID}/*"
}
]
}
| 項目 | 設定値 |
|---|---|
{バケット名} |
作成したS3バケット名 |
{プレフィックス} |
任意のプレフィックス(不要な場合は削除) |
{AWSアカウントID} |
12桁のAWSアカウントID |
ステップ 3:ヘルスチェックログを設定する
- 対象ALBを選択し、「属性」タブ を「編集」
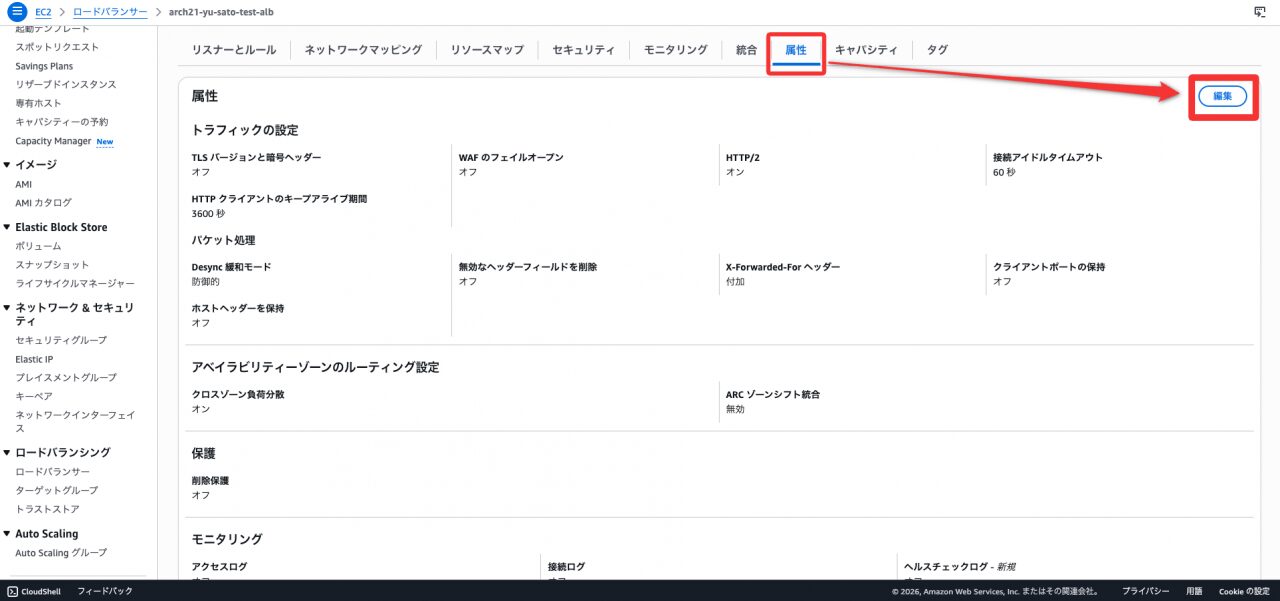
- 「ヘルスチェックログ」 を有効化し、S3バケットを指定
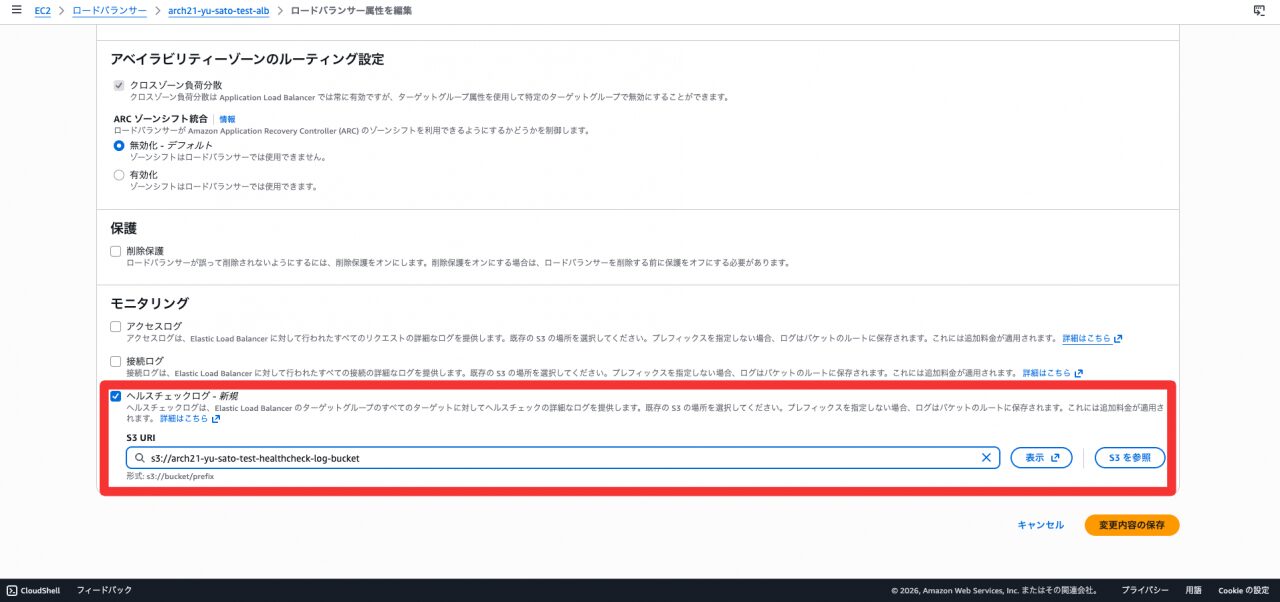
ステップ 4:バケット許可を確認
ヘルスチェックログを有効にするとALBがS3バケットを検証し、テストファイルを自動的に作成します。このファイルが作成されていれば、バケットポリシーが正しく設定されていることが確認できます。
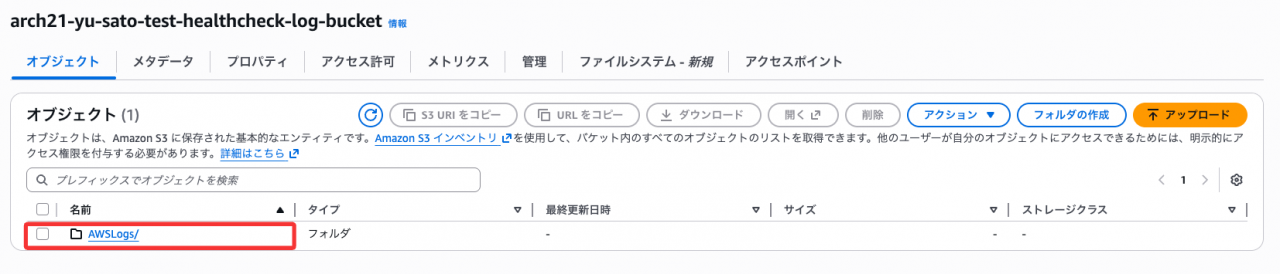
【検証】意図的な障害を起こしてログを確認
ヘルスチェックが失敗した場合、ログの reason_code に以下のいずれかが記録されます。
RequestTimedOut:レスポンス待機中にタイムアウトConnectionTimedOut:TCP接続の試行がタイムアウトConnectionReset:接続リセットによる失敗ResponseCodeMismatch:レスポンスのHTTPステータスコードが設定値と不一致ResponseStringMismatch:レスポンスボディに設定した文字列が含まれていないTargetError:ターゲットが5xxエラーを返したInternalError:ロードバランサー内部エラーGRPCStatusHeaderEmpty:gRPCレスポンスのgrpc-statusヘッダーが空GRPCUnexpectedStatus:gRPCターゲットが予期しないステータスを返した
今回は、以下の2パターンを検証します。
これらは実際の運用でも発生しやすく、かつEC2 + Apacheの構成で手軽に再現できるパターンとして選定しました。
| 障害パターン | 再現方法 | 期待するreason_code |
|---|---|---|
| Apacheを停止する | sudo systemctl stop httpd |
TargetError |
| ヘルスチェックパスを存在しないパスに変更する | TGのヘルスチェックパスを /dummy.html に変更 |
ResponseCodeMismatch |
検証1「Apacheを停止する」
以下のコマンドでApacheの停止・起動を実施します。
# Apacheの停止 sudo systemctl stop httpd # Apacheの起動 sudo systemctl start httpd
ターゲットグループのステータスがUnhealthyになっていることを確認し、起動を実施します。
Apacheを停止後、ターゲットグループのステータスが Unhealthy に変わったことを確認しました。
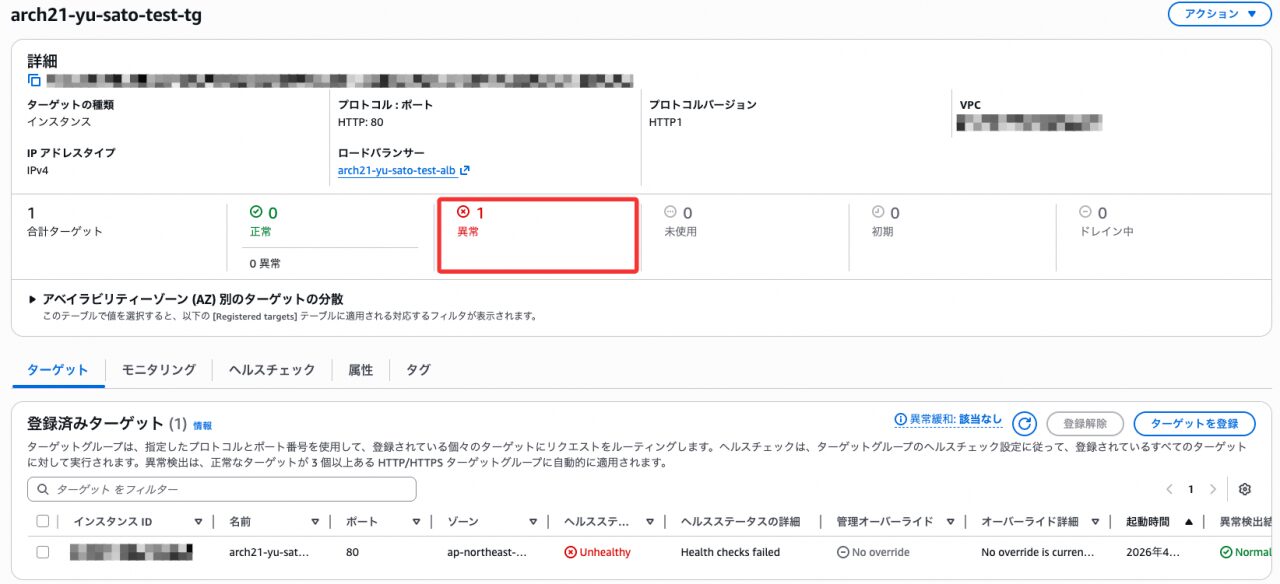
その後Apacheを起動し、S3に出力されたログを確認しました。
- Apache起動中→停止(PASS→FAIL)
http 2026-04-14T09:55:15.111025Z 0.004642163 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T09:55:45.141644Z 0.003151466 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:56:15.168902Z 0.002673123 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:56:45.198630Z 0.002744459 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:57:15.229337Z 0.002693225 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:57:45.244918Z 0.002645385 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:58:15.269034Z 0.00266448 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:58:45.284979Z 0.002769089 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:59:15.289666Z 0.002560917 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T09:59:45.320280Z 0.002720617 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError
PASS だったヘルスチェックが、Apacheを停止してから30秒後の FAIL へ切り替わっています。
これはヘルスチェックのインターバルが30秒に設定されているためで、停止後の次のヘルスチェックで即座に検知されたことが分かります。
reason_code には TargetError が記録されており、Apacheの停止によりターゲットが502を返していたことが確認できます。
- Apache停止中→起動(FAIL→PASS)
http 2026-04-14T10:00:15.350937Z 0.002678269 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 502 TargetError http 2026-04-14T10:00:45.380953Z 0.0050302 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:01:15.408916Z 0.005664615 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:01:45.410884Z 0.004905987 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:02:15.440935Z 0.004755723 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:02:45.455429Z 0.004892684 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:03:15.476947Z 0.005185145 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:03:45.504922Z 0.005485126 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:04:15.517349Z 0.004658648 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 - http 2026-04-14T10:04:45.535252Z 0.005072645 10.0.xx.xxx:80 arch21-yu-sato-test-tg PASS 200 -
Apacheを起動後、PASS に復旧していることが確認できます。
検証 2「ヘルスチェックパスを存在しないパスに変更する」
ALBのコンソールからターゲットグループのヘルスチェックパスを変更します。
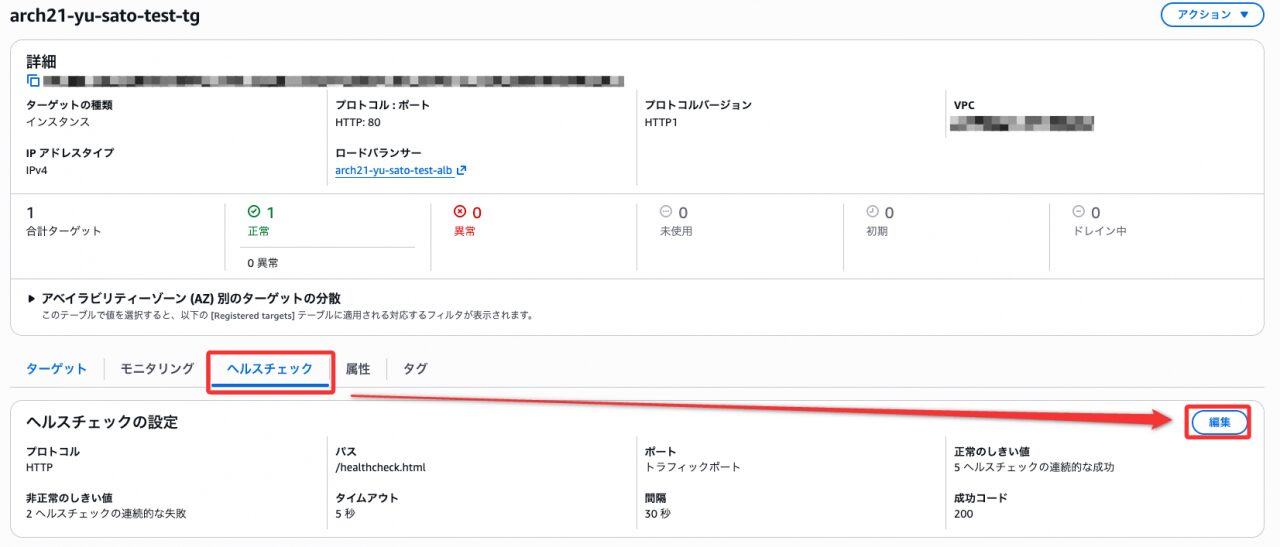
ヘルスチェックパスを /healthcheck.html → /dummy.html(存在しない)に変更します。
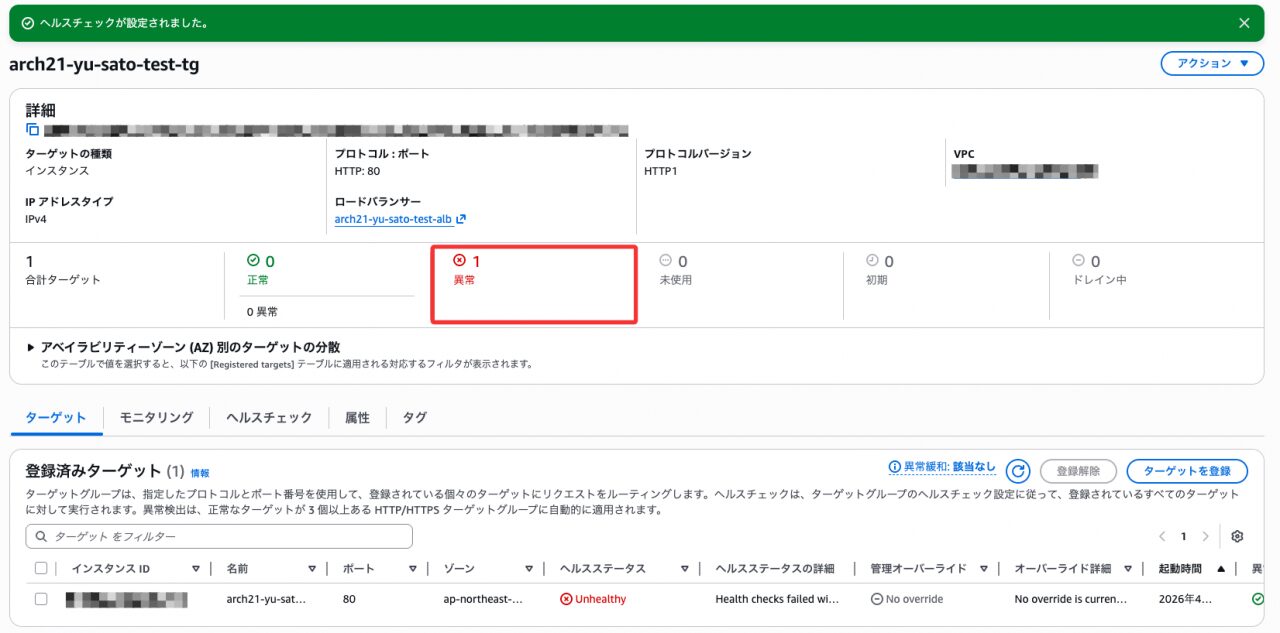
変更後、ターゲットグループのステータスが Unhealthy に変わったことを確認しました。
S3に送信されたログが下記です。
http 2026-04-14T10:30:16.634087Z 0.004634566 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 404 ResponseCodeMismatch http 2026-04-14T10:30:46.660884Z 0.005130905 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 404 ResponseCodeMismatch http 2026-04-14T10:31:16.685579Z 0.00487618 10.0.xx.xxx:80 arch21-yu-sato-test-tg FAIL 404 ResponseCodeMismatch
reason_code に ResponseCodeMismatch が記録されており、存在しないパスへのリクエストに対して404が返されたことが分かります。
検証①と比較すると、同じ FAIL でも reason_code と status_code が異なることで、障害の原因をログから直接特定できることが確認できました。
まとめ
本記事では、2025年11月21日に追加されたALBヘルスチェックログ機能を実際に検証しました。
これまでUnhealthyの原因特定にはAWSサポートへの問い合わせが必要でしたが、本機能により reason_code を通じて障害原因をログから直接確認できるようになりました。
今回の検証でも、Apache停止による TargetError と存在しないパスによる ResponseCodeMismatch を明確に区別できることが確認できました。
常時有効にすべきか、必要なときだけ有効にすべきか
今回の検証を通じて、ヘルスチェックログは常時有効にしておくよりも、必要なときに有効化・調査後に無効化するという使い方が現実的だと感じました。理由は以下の通りです。
- ヘルスチェックは数十秒ごとに実行されるため、常時有効にするとログが際限なく蓄積される
- 通常運用時は PASS ログがほとんどであり、保存しておく意味があまりない
- S3のストレージコストが継続的に発生する
一方で、有効化が特に有効なシーンとしては以下が考えられます。
- Unhealthy が頻発していて原因が特定できないとき
- リリース直後やインフラ変更後の動作確認時
- Auto Scalingでインスタンスが頻繁に入れ替わる環境でのトラブルシュート時
検証を通じ、シンプルな機能ながらトラブルシュートの効率を大きく向上させてくれる機能だと感じました。
最後までお読みいただき、ありがとうございました。

