
はじめに
みなさんは、Google Compute Engine (GCE) でNATインスタンスを運用する際、通信の追跡を行う「conntrack」の管理で困ったことはありませんか?
大量の通信を捌く環境では、カーネルパラメータの net.netfilter.nf_conntrack_max(conntrackの上限値)を適切に引き上げることが安定運用の要となります。しかし、「設定したはずなのに再起動すると値が元に戻ってしまう」「デフォルトのメトリクスとして用意されていないため、監視するには独自の仕組みを構築しなければならない」といった、課題に直面することがあります。
本記事では、再起動のたびに設定がリセットされてしまう初期化問題の根本解決と、Google Cloud 標準の「Opsエージェント」を活用した監視体制の構築、この2点を軸に、実機検証で得られた知見とハマりポイントを詳しくご紹介します。
第1章: 再起動で設定が消える?sysctl設定の問題
通常、Linuxでカーネルパラメータを永続化するには /etc/sysctl.conf を編集します。しかし、今回の検証では上限値を引き上げるためにnet.netfilter.nf_conntrack_max = 32768 と記述しても、再起動後に値がデフォルト値である8192などに戻ってしまう現象が発生しました。
■ 原因:OS起動時におけるモジュールのロードタイミング
調査の結果、この原因はOS起動プロセスにおける「読み込み順序」の不整合にあることが分かりました。
- sysctlの読み込み: OS起動の初期段階で
/etc/sysctl.confが読み込まれます。 - 設定の空振り: この時点では、コネクション追跡を担う
nf_conntrackモジュールがまだカーネルにロードされていません。そのため、OSは「設定対象の項目がまだ存在しない」と判断し、設定を無視されてしまいます。 - デフォルト値での初期化: その後、ネットワーク機能が立ち上がるタイミングでモジュールがロードされますが、その瞬間にモジュール自身が保持しているデフォルト値で上書きされてしまうのです。
■ 解決策:モジュールの先行ロードを強制する
この問題を解決するためには、sysctlが設定ファイルを読み込むよりも前の段階で、先回りしてモジュールを準備しておく必要があります。
# OS起動時にnf_conntrackモジュールを強制的に読み込ませる設定を追加 echo "nf_conntrack" | sudo tee /etc/modules-load.d/nf_conntrack.conf
この一行を /etc/modules-load.d/ 配下の設定ファイルに追記することで、再起動後も設定値が確実に維持される「永続化」を実現することができました。
第2章: Opsエージェントによる監視構築と「権限・構文」の罠
今回の構成では、監視環境を Google Cloud の標準機能(Cloud Monitoring)に集約するため、ログやメトリクスの収集に Opsエージェントを採用しました。しかし、conntrack はCPUやメモリと異なりデフォルトの収集対象に含まれていないため、シェルスクリプトで数値をログに出力し、それをエージェントに読み込ませる構成をとりました。
具体的には、以下の3つのステップで仕組みを構築しました。
1. 数値抽出スクリプトの作成(/usr/local/bin/conntrack_logger.sh)
現在のセッション数と上限値を取得し、使用率(%)を計算してJSON形式で出力します。
#!/bin/bash
COUNT=$(cat /proc/sys/net/netfilter/nf_conntrack_count 2>/dev/null || echo 0)
MAX=$(cat /proc/sys/net/netfilter/nf_conntrack_max 2>/dev/null || echo 0)
# 消費割合(%)を計算(小数点第2位まで)
USAGE=$(awk "BEGIN {printf \"%.2f\", (${COUNT} / ${MAX}) * 100}")
echo "{\"conntrack_count\": ${COUNT}, \"conntrack_max\": ${MAX}, \"conntrack_usage_pc\": ${USAGE}}" >> /var/log/conntrack.log
2. cronへの登録(1分ごとに実行)
echo "* * * * * root /usr/local/bin/conntrack_logger.sh" | sudo tee /etc/cron.d/conntrack_logger
3. Opsエージェントの設定(/etc/google-cloud-ops-agent/config.yaml)
出力されたログファイルを監視し、JSONとしてパースして転送します。
logging:
receivers:
conntrack_log:
type: files
include_paths:
- /var/log/conntrack.log
processors:
parse_json:
type: parse_json
service:
pipelines:
conntrack_pipeline:
receivers: [conntrack_log]
processors: [parse_json]
■ ハマりポイント1:アクセススコープと IAM ロールの違い
GCEインスタンスの設定で「アクセススコープ」を logging-write や monitoring-write に設定しているにもかかわらず、エージェントが権限不足によるログ送信エラーを吐き出すことがありました。
解決策:
アクセススコープは VM インスタンスから外部 API へ「通信して良いか」の窓口設定に過ぎません。それとは別に、インスタンスに紐づくサービスアカウント自体に roles/logging.logWriter および roles/monitoring.metricWriter という IAM ロールを付与しなければ、実際にデータを書き込む権限が得られず、API側で拒絶されてしまいます。
■ ハマりポイント2:Logging クエリの厳密な構文ルール
Cloud Logging の画面で届いたログを確認する際、logId("conntrack_log") と指定すると構文エラーになります。
解決策:
正解は、すべて小文字でアンダースコアを用いた log_id("conntrack_log") です。Google Cloud のクエリ言語の厳密なルールには注意が必要です。
第3章: Terraform によるメトリクス化を阻む「DISTRIBUTION型」とバケット上限の制約
収集したログを Cloud Monitoring でグラフ化するために、Terraform で「ログベースの指標」を作成しました。ここでは、Google Cloud のメトリクス仕様に起因する2つの大きな壁が立ちはだかりました。
■ 壁1:単純な数値型(GAUGE)としての作成が許可されない
本来、conntrack の使用率はその瞬間の値であるため、シンプルな数値型である GAUGE として定義するのが自然です。しかし、以下のエラーで却下されました。
Error 400: A value extractor can only be specified for a DISTRIBUTION value type.
ログから特定の数値を抽出する機能である value_extractor を使う場合、データ型は必ず DISTRIBUTION(分布データ) でなければならないという仕様上の強い制限があります。これに伴い、metric_kind にはログの性質に合わせて DELTA を選択しました。
■ 壁2:試行錯誤の末に辿り着いた「バケット分割」の限界
型を DISTRIBUTION に修正すると、分布データとして扱う以上、数値を仕分ける箱(バケット)の設定(bucket_options)を明記するよう求められます。
当初、より高い精度で数値を測るためにバケット数を「1,000個」程度で設定してデプロイを試みました。しかし、ここで Google Cloud API の「ログベースメトリクスにおけるバケット数は最大200個まで」という制限 に引っかかり、エラーとなってしまいました。
この制限をクリアしつつ最大限の精度を確保するため、「幅 0.5% 刻みで、箱を 200 個用意する(0 〜 100% を完全にカバー)」 を採用することで解決しました。
【最終的な Terraform コード(抜粋)】
resource "google_logging_metric" "conntrack_usage" {
name = "conntrack_usage_pc_${var.environment}"
project = var.project_id
filter = "log_id(\"conntrack_log\")"
metric_descriptor {
metric_kind = "DELTA"
value_type = "DISTRIBUTION"
unit = "%"
}
value_extractor = "EXTRACT(jsonPayload.conntrack_usage_pc)"
# 当初1,000個でエラーが出たため、API上限の最大200個で0.5%刻みの設計に変更
bucket_options {
linear_buckets {
num_finite_buckets = 200 # API上限の最大数
width = 0.5 # 0.5%刻み
offset = 0
}
}
}
第4章: 運用のゴール:上限の 80% 超過を検知するアラート設定と型不一致の罠
グラフ化による可視化の次は、実際の運用におけるゴールである「アラート通知」の実装です。
conntrack 使用率が 100% に達するとパケットロス(NAT枯渇)が発生するため、対応の猶予を持たせるための閾値として、使用率 80% を超過した際に通知するよう設定しました。
ここでも最後の罠が待っていました。
■ 壁:最大値(ALIGN_MAX)指定による型の不一致エラー
アラートの監視条件として、シンプルに最大値を監視しようと ALIGN_MAX を指定したところエラーが発生しました。
原因は、今回作成したメトリクスが DISTRIBUTION 型であるためです。DISTRIBUTION は「分布データ全体」を保持する型であるため、単一のスカラー値を返す ALIGN_MAX のようなアライナーを適用しようとすると、型の不一致により処理できません。
解決策:
分布データから数値を抽出して監視するためには、分布型に対応しているアライナーである 99パーセンタイル(ALIGN_PERCENTILE_99) を指定する必要がありました。
(※補足: 今回の構成では1分に1回しかログを出力しないため、集計期間内のサンプルは実質1つです。分布型(DISTRIBUTION)の仕様上、バケットによる近似計算は行われますが、意図した閾値監視において実用上十分な精度で最大値付近を捉えることができます。)
【Terraform によるアラート定義】
resource "google_monitoring_alert_policy" "conntrack_high_usage" {
depends_on = [google_logging_metric.conntrack_usage]
display_name = "NAT Conntrack High Usage Alert over 80%(${var.environment})"
combiner = "OR"
conditions {
display_name = "Conntrack usage exceeds 80%"
condition_threshold {
filter = "metric.type=\"logging.googleapis.com/user/conntrack_usage_pc_${var.environment}\" AND resource.type=\"gce_instance\""
comparison = "COMPARISON_GT"
threshold_value = 80 # 80%を超えたら
duration = "60s" # 1分間継続した場合
aggregations {
alignment_period = "60s"
# DISTRIBUTION型の型不一致を避けるため、99パーセンタイルを選択
per_series_aligner = "ALIGN_PERCENTILE_99"
}
}
}
}
第5章: 設定の永続化確認
一連の対策を反映した後、Cloud Monitoring のグラフを通して最終的な動作確認を行いました。
第3・4章では「使用率(%)」の監視設定を解説しましたが、ここでは第1章の「再起動による設定初期化問題」が根本から解決したことを証明するため、上限値(nf_conntrack_max)の推移を確認します。
以下のグラフは、その上限値の推移を表しています。(縦軸:conntrack の上限値、横軸:時間)
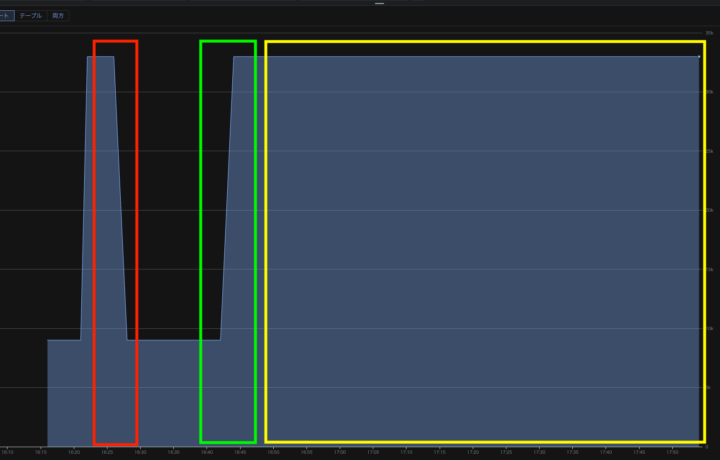
図: Cloud Monitoring による nf_conntrack_max の推移
検証タイムライン(日本時間:JST)
* 赤枠 16:26頃: 設定追記のみで再起動した時点です。上限値がデフォルトの8192に初期化され、手動で32768に設定し、また再起動で戻る、という初期化問題の再現を行っている様子です。
* 緑枠 16:45頃: 対策として用意した先行ロード設定(modules-load.d への追記)を反映し、再度インスタンスを再起動しました。
* 黄枠 16:47以降: 対策反映後の再起動、およびこれ以降再起動を経ても初期化されず、上限値が設定通りの32768で維持されていることを確認できました。
グラフの推移からも、再起動による初期化問題が解決し、Opsエージェントによる監視が正常に稼働していることが視覚的に証明されました。
おわりに
今回の検証を通して、OSの再起動時における設定の初期化問題を解決し、Opsエージェントを用いた監視環境を構築することができました。
一方で、Terraformで監視を自動化する過程では「DISTRIBUTION型やバケット数のAPI上限」という制約に直面し、クラウドネイティブな監視アーキテクチャならではの仕様に合わせる難しさを痛感しました。また、OSのモジュール起動順序やIAM権限の違いなど、レイヤーの異なるエラーを一つずつ紐解いていく過程は、クラウドインフラを構築する上で非常に良い学びになりました。
本記事で紹介したハマりポイントや解決策が、同じように Google Cloud の監視設定で悩んでいる方や、インフラの安定稼働に取り組むみなさまの参考になれば幸いです。