
連載の軌跡
〜実践!Google Cloud × Geminiで作るナレッジ自動化〜
| # | テーマ | ひとことで言うと |
|---|---|---|
| 1 | 開発の背景と全体アーキテクチャの展望(統括編) | 課題・理想・企画・結果の共有 |
| 2 | Zendesk × Gemini × BigQuery で完全自動のナレッジ蓄積パイプラインを構築 | Zendeskチケットを Gemini で要約させ スプレッドシート 経由で BigQuery へ流すまでの自動化 |
| 3 | Gemini × Agent Development Kit (ADK) × Slackで作る「人とAIが対話して決める」業務自動化パイプライン | ADK のマルチエージェントと Slack で記事の自動作成 & 人による承認フロー |
| 4 | 本記事 | 承認後の本文自動生成と Cloud Run + Scheduler での 24/7 運用 |
はじめに:何ができるようになるか
ここまで作ってきた仕組みの全体像はこんな感じです。
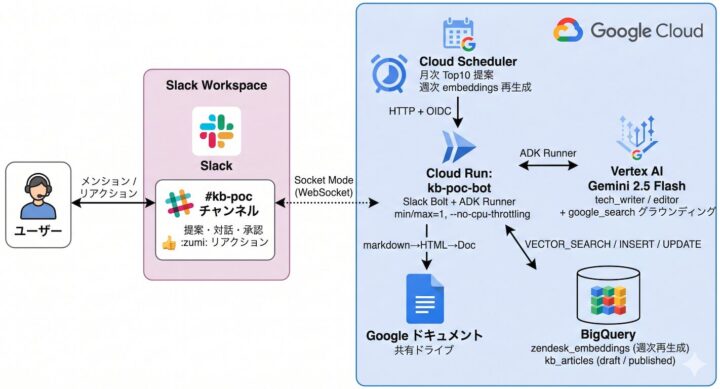
この記事では、前回の続きとして以下を全部作ります:
- 承認された Top 10 トピックから 記事本文を自動生成(Tech Writer エージェントの作成)
- 校正エージェントで表記揺れや冗長を整える
- 実在の Google ドキュメント URLを関連リソースとして引用(Google Search Grounding)
- 生成した記事を Google ドキュメント に自動保存(Drive API)
- 過去に書いた記事との 重複を検知(BigQuery Embeddings + VECTOR_SEARCH)
- 公開フラグ を Slack のリアクション 1 つで管理
- Cloud Run に乗せて 24/7 稼働、Cloud Schedulerで月次自動分析
全体の流れ
承認後の処理は、Slack 上だとこう見えます。
[ユーザー] 「全て承認」 / 「2 番だけ承認」 ↓ [Bot] 承認受理メッセージ + 書き出しボタン ↓ [ユーザー] ボタン押下 or 「2 だけ作成」など ↓ [Bot] 1 番目「タイトル」を生成中… ↓ 各記事ごとに以下を直列実行 [BigQuery] 類似チケットをセマンティック検索 (グラウンディング) ↓ [Tech Writer Agent] gemini + google_search で本文 markdown 生成 ↓ [Editor Agent] 校正 + <editor_notes> ↓ [Drive API] markdown → HTML → Google ドキュメント を共有ドライブに作成 ↓ [BigQuery] kb_articles に status='draft' で INSERT ↓ [Bot] 校正メモ + Google ドキュメント URL を Slack スレッドに返信 ↓ [ユーザー] Google ドキュメント を確認 → 公開判断 → :zumi: リアクション ↓ [BigQuery] kb_articles の status を 'published' に更新 → 重複検知の対象に
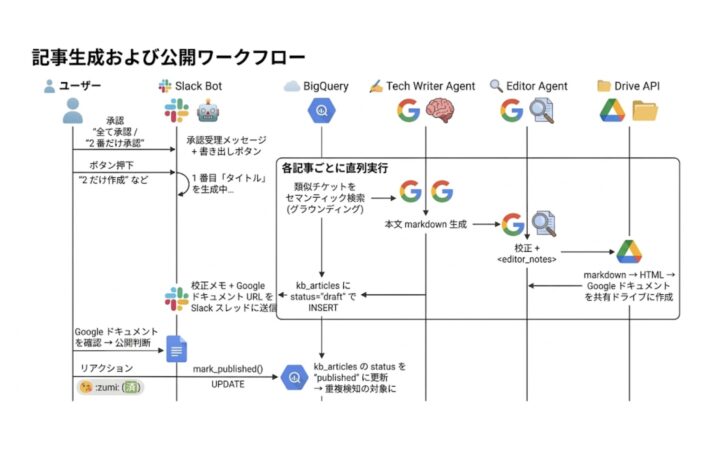
文字にするとシンプルですが裏では5 つのエージェント / APIが連携しています。
ただ、各ステージの責任が分かれていることで、デバッグはしやすかったです。検証中、Google ドキュメントの URL が空っぽだったことがありましたが、それを「Tech Writer の問題か、Drive API の問題か、Slack 投稿の問題か」を 3 分で切り分けられたのは、責任分離していたおかげです。マルチエージェント構成でなければ、問題点の特定にかなりの時間を費やしていたと思います。
Tech Writer エージェント設計
ツールは google_search だけ
Tech Writer は 承認されたタイトルと概要から記事本文を Markdown で生成する 役割です。シンプルな 1 ステップなので、ADK の LLM Agent を 1 つだけ用意しています。
# agents/<your_writer>/agent.py
from google.adk.agents import LlmAgent
from google.adk.tools import google_search
root_agent = LlmAgent(
name="<your_writer>",
model="gemini-2.5-flash",
description="承認済みタイトル+概要から Markdown 形式の 記事本文を生成する",
instruction=_INSTRUCTION,
tools=[google_search],
)
ポイントは tools=[google_search] の 1 行です。これを入れるだけで、ADK が裏でVertex AI Gemini の Google Search groundingを有効化してくれます。LLM が記事を書く前に検索結果を参照できるので、引用するURLを実在のものに保てます。
google_search ツールのありがたさは、1 行追加するだけでグラウンディングが有効になる という、絶妙な抽象化のされ方にあると思います。「Vertex AI 側の Google Search grounding を有効化して、レスポンスにグラウンディング情報を注入して、引用 URL を抽出して……」みたいな実装を全部自分でやるとなると、それだけで丸 1 日かかるような作業量です。それを 1 行で済ませてくれるのは本当にありがたいです。
関連リソース URL の罠
最初は「URL は推測で書かないでね」とプロンプトにしっかり書いていたのですが、LLM は「もっともらしい URL を平気で生成」 します。
最初に生成された記事を Google ドキュメント で開いて、関連リソースのリンクをクリックしたらすべて404でした。LLM の ハルシネーション 問題を実体験したシーンでした。自分の中で、「LLM 出力が必ずしも正しいわけではない」 と改めて感じた瞬間でした。
最初に試したのは「Google 検索 URL に逃がす」案でした。
[公式ドキュメント名](https://www.google.com/search?q=site:cloud.google.com+IAM+概要)
これは 404 にはならないものの、クリックしたら検索結果ページが開くだけで、目的のドキュメントには直接たどり着けませんでした。
LLM がもっともらしい URL を作ってしまうのは構造的な問題で、プロンプトをいじっても限界がある気がしていました。
そんなときに思いついたのが 「書く前に検索させる」 というやり方でした。
プロンプトにこう書きます。
- 関連リソースの URL は必ず google_search ツールで実在性を確認した URL を使う - 検索結果に出てきた cloud.google.com/... の 実 URLを 2〜3 件控えてから記事を書く - 検索ツールを使わずに具体パスを推測で書かない (404 のリスク) - 適切な公式ドキュメントが検索でヒットしなかった場合は、関連リソース章自体を省略してよい
これに変えてからは、関連リソースが 実在の Google Cloud ドキュメント URL に変わりました。
## 関連リソース - [Cloud 請求先アカウントを管理する](https://cloud.google.com/billing/docs/how-to/manage-billing-account) - [予算を作成、編集、削除する](https://cloud.google.com/billing/docs/how-to/budgets) - [費用とお支払い履歴を表示する](https://cloud.google.com/billing/docs/how-to/view-cost-history)
クリックしたら本物のドキュメントが開きます。「LLM に ハルシネーション させない一番手っ取り早い方法は、答えを検索させてからそれを引用させること」 でした。
このとき、AI 開発って 「LLM をどう信じるかではなく、どう信じなくていいかを設計するゲーム」 に近いんだなと思いました。素の LLM は頼りないし、何でも信じてしまうとシステムがすぐ壊れます。それでも「ここは正確じゃなくていい」と「ここは絶対正確であってほしい」を区別して、後者には外部の真実 (検索 / DB / ツール) を当てる、という設計を意識すると、LLM が頼れるものになります。
Markdown 構造をプロンプトで固定する
記事の章立てもブレないよう、プロンプトで型を決めています。
# <タイトル> ## 概要 ## 想定読者 ## 前提条件 ## 手順 / 設定方法 ## よくあるトラブルと対処 ## 関連リソース ## 更新履歴
記事として読みやすさを揃えるには型がある方が良い という判断です。
最初は「LLM の自由度を尊重して、章立ても任せた方がクリエイティブな記事になるかも」と思っていたのですが、実際にやってみると 章のばらつきが大きくて読みにくい ことが分かりました。
Editor エージェントによる校正
なぜ二段にしたか
最初は Tech Writer 1 つで完結させていました。生成された記事を Google ドキュメント で読むと、内容は悪くないものの
- 「Vertex AI」と「VertexAI」が混在する
- 「です・ます調」と「だ・である調」が同じ記事内で入り混じる
- 同じ説明が章を跨いで繰り返される
- 章見出しの粒度がチグハグ
といった 表面品質の問題が目立ちました。
最初に校正前の記事を読んだとき、「うん、悪くはないけど……」くらいのレベルでした。「出来てるけど出せない」 状態です。
プロンプトをいじって Tech Writer に直接「校正もしてね」と依頼すると、今度は内容が薄くなることが判明しました。「校正のことを考えながら書く」のと「校正だけする」のでは LLM の集中するポイントが違うようで、両方を 1 つのプロンプトに詰め込むと両方が中途半端になる感触でした。
これに気付いた時は、人間がレポート書くときも全く同じだなと思いました。書きながら校正しようとすると、書く方も校正する方も中途半端になって、結局後でもう一回読み直すことになります。LLM も同じです。「最初は書ききる、後で別の頭で見直す」 が人間の書き方の基本ですが、LLM もそれと同じ役割分担にした方が良い結果が出る、ということに気付きました。
そこで Tech Writer (執筆) → Editor (校正) の二段構成に切り替えました。実装としては Runner を 2 つ用意して連続で呼ぶだけなので、コード量はほとんど増えません。
Editor は構造を変えない
Editor のプロンプトで重要なのは 「構造を勝手に変えない」 という制約です。
- 構造・意味を勝手に変えない: 章立てを増減しない、内容を勝手に削らない、新しい情報を追加しない - 根本的な書き直しではない: 著者の意図を尊重しつつ、表面的な品質だけを上げる - 文字数を 2 倍にも 1/2 にもしない。±10% 程度に収める - リンクの URL は絶対に変更しない (タイトル文言が冗長でも URL を書き換えない)
これがないと Editor が 勝手に章を増やしたり、内容を別の言い回しに置き換えたりするので、Tech Writer の意図が壊れます。「校正」というタスクの境界線をプロンプトで明確に引かないと、LLM はすぐ「執筆者」になってしまうのが面白いところです。
最初に Editor のプロンプトを書いたときは制約を緩く書いていて、結果として 元の記事よりむしろ長く、内容が薄くなった記事 が出力されました。Editor が校正しすぎて作家になってしまいました。LLM は何かを依頼すると 120% で応えようとする傾向があるので、「やりすぎないでね」を明示的に書く必要があるんだと学びました。
ちなみに「リンクの URL は絶対に変更しない」も最初は入れていなくて、Editor が「タイトルが冗長」と判断して URL ごと書き換えたことがあります。せっかく google_search で取った実在 URL が、校正で 404 URL に書き換えられる悲劇でした。それ以来、URL という機械可読なものは 「触らないリスト」 として明示するようにしました。
校正メモを Slack に出す
Editor の出力にはeditor_notesブロックを必ず含めてもらい、Slack に返します。
# <タイトル> (本文 ...) <editor_notes> - 「Vertex AI」と「VertexAI」が混在していたので「Vertex AI」に統一 - 「概要」セクションの最後の文を簡潔化 - 「手順」セクションの番号付きリストの体裁を整えた </editor_notes>
editor_notesを slack_app 側で抽出して、Slack スレッドには:
:memo: 1 番目 校正メモ: - 「Vertex AI」と「VertexAI」が混在していたので「Vertex AI」に統一 - ...
として投稿します。Google ドキュメント 本体にはeditor_notesは入らないようにしているので、Google ドキュメント は綺麗な状態で残ります。
これは作って良かった機能のひとつで、「AI が何を直したか」が分かると、「ちゃんと校正されてるんだ」と納得して読めます。
実装してみて初めて気付いたのは、「AI が裏で何をしたか分からない」 ことが業務利用での最大の不安要素になるということでした。 AI への信頼は『中身の質』ではなく『プロセスの可視性』で生まれる んだなと感じました。これは今後の AI 機能開発でも意識したい観点です。
BigQuery Embeddings
なぜグラウンディングが要るか
承認されたタイトルと概要だけを Tech Writer に渡すと、過去のサポートチケットの傾向 とは無関係に「一般論の記事」を書いてしまうことがあります。
例えば「予算アラート設定ガイド」を書かせるとき、過去のチケットに「予算アラートのメール通知が遅れる」みたいな具体的な困りごとが多発していたとして、それが本文に反映されないと 「ナレッジ記事として薄い」 ものになってしまいます。
最初の生成記事を読んだとき、「Google 検索の上位に出てくるブログ記事と区別がつかないな」と感じました。社内ナレッジの価値は 「うちのチームが実際にハマったポイント」が反映されていること なのに、それが入ってないと存在意義が薄れます。当然のことなのですが、「会社の知見ってこういう細かいところに宿るんだなぁ」と感じました。
そこで本文生成の前に、過去チケットの中で類似するものを 5 件取ってきて Tech Writer の入力に含める というグラウンディングを入れました。
BigQuery ML.GENERATE_EMBEDDING + VECTOR_SEARCH
BigQuery には Vertex AI のテキスト埋め込みモデルを呼び出せる ML.GENERATE_EMBEDDING があります。これでチケットを 768 次元のベクトル に変換し、zendesk_embeddings テーブルに保存しておきます。
CREATE OR REPLACE TABLE `<dataset>.zendesk_embeddings` AS
SELECT
id, status, subject, ai_summary, updated_at,
ml_generate_embedding_result AS embedding
FROM ML.GENERATE_EMBEDDING(
MODEL `<dataset>.text_embedding_model`,
(
SELECT id, status, subject, ai_summary, updated_at,
CONCAT(IFNULL(subject, ''), ' ', IFNULL(ai_summary, '')) AS content
FROM `<dataset>.<source_table>`
),
STRUCT(TRUE AS flatten_json_output)
);
検索時は同じモデルでクエリテキストもベクトル化し、cosine 距離で類似上位を取ります。
WITH q AS (
SELECT ml_generate_embedding_result AS embedding
FROM ML.GENERATE_EMBEDDING(
MODEL `<dataset>.text_embedding_model`,
(SELECT @query_text AS content),
STRUCT(TRUE AS flatten_json_output)
)
)
SELECT
base.id, base.subject, base.ai_summary,
ML.DISTANCE(base.embedding, q.embedding, 'COSINE') AS distance
FROM `<dataset>.zendesk_embeddings` AS base
CROSS JOIN q
ORDER BY distance ASC
LIMIT @top_k
これで「コスト最適化」と入れても「予算アラート」のチケットがちゃんと類似度 0.85 とかでヒットします。「文字一致じゃなくて意味一致」 という体験を初めて自分のシステムで動かすことができました。
Embeddings の鮮度を保つ
zendesk_embeddings は静的なテーブルなので、新しいチケットが Sheets 側に追加されても自動的には embedding が増えません。「毎週月曜の朝に再生成」を Cloud Scheduler に組み込んでいます。
最初これを忘れていて、「先週分のチケットがグラウンディングで全くヒットしない…」となって気付きました。AI システムは「データの鮮度を保つジョブ」を別途設計する という当たり前を、運用フェーズになって初めて実感しました。
AI も結局は データパイプラインの一部 で、データの鮮度・整合性・可用性という、伝統的なデータエンジニアリングの問題から逃げられません。「AI 開発は最終的にデータエンジニアリングに帰結する」ということを身をもって理解した瞬間でした。
Google ドキュメント への保存(Drive API)
markdown → HTML → Google ドキュメント
Tech Writer + Editor が出した Markdown を、Google ドキュメント として保存します。
最初は Google ドキュメント API で 1 ブロックずつ insertText/style 指定するつもりでしたが、これが想像以上に大変でした。h1, h2, h3, リスト、コードブロック、リンク、すべてに API リクエストが必要で、コードが面倒なことになりそうでした。
ドキュメントを少し読み始めて 30 分くらいで「これ、続けたら本当に半日以上溶けるな……」と感じました。Google ドキュメント API は強力ですが、カジュアルな利用には向かないと感じました。
ふと思いついて試したのが、Google Drive の自動変換に乗っかる 方法です。Markdown をいったん HTML にしてから、Drive API の files.create で mimeType を application/vnd.google-apps.document にして HTML をアップロード すると、Google Drive 側が勝手に Google ドキュメント に変換してくれます。
# app/<your_doc_writer>.py
import io
import markdown as md
from googleapiclient.discovery import build
from googleapiclient.http import MediaIoBaseUpload
import google.auth
def create_kb_doc(title, body_markdown, folder_id):
body_html = md.markdown(body_markdown, extensions=["extra", "sane_lists", "nl2br"])
html = f"""<!DOCTYPE html><html><head><meta charset="utf-8"></head><body>{body_html}</body></html>"""
creds, _ = google.auth.default()
drive = build("drive", "v3", credentials=creds, cache_discovery=False)
media = MediaIoBaseUpload(
io.BytesIO(html.encode("utf-8")),
mimetype="text/html",
)
file = drive.files().create(
body={
"name": title,
"mimeType": "application/vnd.google-apps.document",
"parents": [folder_id],
},
media_body=media,
fields="id, webViewLink",
supportsAllDrives=True,
).execute()
return {"id": file["id"], "url": file["webViewLink"], "title": title}
これで 1 API コール で markdown が綺麗な Google ドキュメント になります。
kb_articles テーブルに記事メタを保存
Drive API を作るたびに、メタ情報を BigQuery に蓄積しています。
CREATE TABLE IF NOT EXISTS `<dataset>.kb_articles` ( id STRING NOT NULL, -- UUID title STRING NOT NULL, overview STRING, doc_id STRING, doc_url STRING, channel STRING, thread_ts STRING, rank INT64, rev_seq INT64, approved_by STRING, status STRING, -- 'draft' or 'published' created_at TIMESTAMP NOT NULL, embedding ARRAY<FLOAT64>, -- 768 次元 published_at TIMESTAMP, published_by STRING );
INSERT する際に、タイトル+概要の embedding も同じ文中で ML.GENERATE_EMBEDDING で生成して 1 INSERT にまとめています。これで 作った瞬間からセマンティック検索できる 状態になります。
最初は別テーブルに分けようかと思いましたが、1 行 1 記事として完結させる ほうが扱いがシンプルでした。あとで集計クエリを書くときも、JOIN しなくていいのは楽です。
後で困ったら分割すればいい話で、最初から複雑に作ると保守も大変です。「最初は素直に、必要に応じて分割する」 ほうが良いかと思います。
公開フラグ管理(Slack リアクション)
「作っただけ」と「公開した」を区別する
ここがいちばん運用感のある機能です。
書き出した Google ドキュメント は、ドラフト状態で BigQuery に入ります。これは「とりあえず作ってみた」状態であり、人がレビューして「これは公開しよう」と判断したものだけ が、後の重複検知の対象になるべきです。
仕組みは単純で、Slack の Google ドキュメント URL メッセージに :zumi: (済) リアクションを付けると published に昇格するだけです。
この機能、最初の段階では作るつもりがありませんでした。「全部の Google ドキュメント を重複検知の対象にすればいいじゃん」と単純に考えていたからです。ですが途中で、「作っただけで採用しない記事もたくさんあるはず。それを重複検知の対象にされると、ノイズになる」と気付きました。
Slack のリアクションイベント
@slack_app.event("reaction_added")
async def on_reaction_added(event, client, logger):
if event.get("reaction") != "zumi":
return
item = event.get("item") or {}
channel = item.get("channel")
ts = item.get("ts")
user = event.get("user", "")
# 対象メッセージから Doc URL を抽出
urls = await _resolve_doc_urls_from_message(client, channel, ts)
for url in urls:
result = mark_published(url, published_by=user)
if result:
await client.chat_postMessage(
channel=channel, thread_ts=ts,
text=f":zumi: <@{user}> さんがこの記事を *公開* としてマークしました → <{url}|{result['title']}>"
)
reaction_removed イベントを使えば「フラグ削除」もできるので、間違って付けた人も簡単に取り消せます。
設計しているとき、最初は「ボタンを置こうかな」と思ったのですが、Slack のリアクションは マウス操作 1 つ で完結するので、ボタンより速いです。「人の判断は最小タップで終わらせる」 という方針をこの機能でも踏襲しました。
リアクションでの対応は、「カジュアル」な印象もあり「業務システムでこれ使うのアリかな?」と迷いましたが、Slack 内で完結する小さな操作 だからこそ気軽に使えるという効果がありました。
重複検知の実装
Slack に :warning: で通知
Top 10 提案を投稿した直後に、各トピックを kb_articles の published 記事とセマンティック比較しています。類似度が閾値(cosine distance ≤ 0.30、つまり類似度 70% 以上)を超えると、Slack に警告を投げます。
:warning: 過去に類似のナレッジ記事があります。重複作成を避けるなら、書き出しから外すか、 更新の意図で新規 Doc を作る方針にしてください。 • *2 番目「Cloud SQL のメンテナンス手順」* — 類似度 91%: <doc_url|Cloud SQL SQL Server のメンテナンス適用とダウンタイム最小化戦略> (2026-04-30)
最初に重複警告が出たとき、テスト用に作った記事と新提案がちゃんとセマンティック一致して 91% で繋がっていて「お、ちゃんと検知してる!」と感動しました。「自分が作った仕組みが、ちゃんと意図通りに動いている」 という実感が一番の達成感です。
published のみが対象
status='draft' の記事は重複検知の対象に入れない ようにしています。
理由は、ユーザーが書いた記事すべてが「採用」されるとは限らないから。draft も対象にすると、「使わないけど作っただけ」の記事までヒットしてしまい、警告がノイズになります。:zumi: で 明示的に「公開した」とマークされた記事だけ が母集団になるので、警告に意味が宿ります。
実装は find_similar_existing 関数の SQL に WHERE a.status = 'published' を入れるだけです。
Cloud Run デプロイ
Events API bot を Cloud Run に乗せる
ここまでローカル PC で動かしていた bot を、24/7 動く Cloud Run に乗せます。Slack からは Events API
経由で /slack/events に HTTPS POST されるので、aiohttp の受け口を立てるだけで動きます。
from slack_bolt.async_app import AsyncApp
from slack_bolt.adapter.aiohttp import to_aiohttp_response, to_bolt_request
from aiohttp import web
slack_app = AsyncApp(
token=os.environ["SLACK_BOT_TOKEN"],
signing_secret=os.environ["SLACK_SIGNING_SECRET"],
)
async def _slack_events(request):
bolt_req = await to_bolt_request(request)
bolt_resp = await slack_app.async_dispatch(bolt_req)
return await to_aiohttp_response(bolt_resp)
async def main() -> None:
app_http = web.Application()
app_http.router.add_get("/", lambda _: web.json_response({"status": "ok"}))
app_http.router.add_post("/slack/events", _slack_events)
runner = web.AppRunner(app_http)
await runner.setup()
site = web.TCPSite(runner, "0.0.0.0", int(os.environ.get("PORT", "8080")))
await site.start()
await asyncio.Event().wait()
AsyncApp に signing_secret を渡しておくと、Slack からのリクエストに付いてくる X-Slack-Signature
(HMAC-SHA256) の検証を bolt が自動でやってくれます。これで Cloud IAM 認証を入れなくても、Slack以外からのリクエストは弾けます。
Cloud Run のデプロイ設定で重要なのは:
--min-instances=1 --max-instances=1(常時 1 つ起動しっぱなしで、スケールアウトしない)--allow-unauthenticated(Slack はアノニマスで POST してくるので IAM 認証は外す。正当性は HMAC
署名検証で担保する)
「呼ばれたときだけ CPU が動く」設計なので、アイドル時のコストはほぼゼロです。Socket Mode のようにWebSocket を張りっぱなしにする方式だと CPU を常時回す必要があり、Cloud Runのスケールトゥゼロを打ち消してしまうので、サーバーレス前提では HTTP webhook が定石です。
Slack トークンは Secret Manager 経由で
SLACK_BOT_TOKEN と SLACK_SIGNING_SECRET は Secret Manager に保存して、Cloud Run の
--set-secrets で注入しています。
gcloud run deploy <service-name> \
--set-secrets="SLACK_BOT_TOKEN=slack-bot-token:latest" \
--set-secrets="SLACK_SIGNING_SECRET=slack-signing-secret:latest" \
...
SLACK_SIGNING_SECRET は Slack App 管理画面の “Basic Information” → “Signing Secret”
からコピーできる文字列です。これが漏れると bot を偽装したリクエストを送れる可能性があるので、Secret
Manager 経由で渡すのが必須です。
Cloud Scheduler で月次/週次自動化
月次の Top 10 提案
毎月 1 日 09:00 JST に Cloud Scheduler が /scheduled-analysis を叩き、bot が指定 Slack チャンネルに「Top 10 提案」を自動投稿します。
gcloud scheduler jobs create http kb-poc-monthly \
--schedule="0 9 1 * *" \
--time-zone="Asia/Tokyo" \
--uri="${CLOUD_RUN_URL}/scheduled-analysis" \
--http-method=POST \
--oidc-service-account-email="${SA}" \
--oidc-token-audience="${CLOUD_RUN_URL}"
--oidc-service-account-email を指定することで、Cloud Run の IAM で SA に run.invoker を持たせれば認証付きで呼び出せます。
/scheduled-analysis は呼ばれた瞬間に 200 を返してから、バックグラウンドで分析を始めます:
async def _scheduled(_request):
target_channel = os.environ.get("SCHEDULER_TARGET_CHANNEL", "").strip()
asyncio.create_task(_run_scheduled_analysis(target_channel))
return web.json_response({"status": "started", "channel": target_channel})
asyncio.create_task で投げっぱなしにすることで、Cloud Scheduler がタイムアウトせずに済みます。
週次の Embedding 再生成
zendesk_embeddings を毎週月曜 06:00 JST に再生成します。月次提案より早い時間に走らせて、提案時点で embedding が最新になっているようにしています。
gcloud scheduler jobs create http kb-poc-embedding-refresh \
--schedule="0 6 * * 1" \
--time-zone="Asia/Tokyo" \
--uri="${CLOUD_RUN_URL}/refresh-embeddings" \
...
実行は約 12 秒で 1100 行強を再生成。コストも数十円程度で運用できます。「週次の自動メンテナンスが組めると、データ鮮度の心配から解放されます」。
観測性
何が起きたかを追えるよう、Cloud Logging に 構造化イベント を出しています。
def event(name: str, **fields):
payload = {"event": name, **fields}
_logger.info(name, extra={"json_fields": payload})
主なイベント:
kickoff_clicked— 「Top 10 提案して」ボタン押下proposal_approved— 承認確定doc_created— Doc 生成成功doc_failed— 生成失敗article_published— :zumi: で公開マークembeddings_refresh_completed— 週次再生成完了
これを Cloud Logging で集計したり、後で BigQuery にシンクして月次レポートを作る、ということができます。「ログを構造化しておくと、後で分析しやすい」 のは AI システムでも普通の業務システムでも同じだと感じました。
まとめ
今回の連載をここまで書いてきて、PoC 全体を通して 「AI を業務で動かす」というのは、AI そのものの実装より周辺のインフラ・UI・運用の整備が大きいことを痛感しました。Gemini や ADK は本当によくできていて、プロンプト 1 枚で驚くほど多くのことができます。一方で、それを チームが日常的に使えるツールにするまでには、Slack 連携・Drive 統合・Cloud Run 運用・IAM・観測性といった、地味だけど沢山の階段がありました。
あらためて思うのは、AI 時代の開発者の仕事は 「AI の能力を引き出す環境を作る人」 に近づいてきているということです。これは決して華やかではないですが、現場で価値を生むのはまさにこの部分だと思いました。




