
はじめに
データ分析に興味はあるけれど、「なんだか難しそう」「環境構築が面倒」と足踏みしていませんか?実は、Google Cloudの「BigQuery」を使えば、手元のブラウザひとつで、世界中の膨大なデータを手軽に分析を始められるんです!
本記事では、これからBigQueryを触ってみたい方に向けて、基本の特徴をサクッと解説しつつ、実際に「一般公開データ」を使って色々な分析をやってみた様子をお届けします!
目次
- BigQueryとは?その特徴と魅力
- 一般公開データセットを活用しよう
- BigQueryの料金体系と注意点
- BigQueryの基本的な使い方(3ステップ)
- 実際にやってみた!データ分析3選
- まとめ:データを用意しなくても、すぐに分析は始められる
BigQueryとは?その特徴と魅力
BigQuery(ビッグクエリ)は、Google Cloudが提供するフルマネージドのデータウェアハウス(大量のデータを保管・分析するためのシステム)です。
一番の魅力は、「サーバーの構築や管理が一切不要」という点です。通常、大量のデータを分析しようとすると、専用のサーバーを用意し、性能を調整し、メンテナンスし続ける…といった手間が発生します。BigQueryはこうした裏側の作業をすべてGoogleが引き受けてくれるため、私たちは「分析すること」だけに集中できます。
しかも、ただ手軽なだけではありません。数テラバイトという途方もないサイズのデータであっても、SQL(データベースを操作する言語)を書くだけで、数秒から数十秒という驚異的なスピードで結果を返してくれます。この速さの秘密は、BigQueryが裏側で数千台規模のサーバーに処理を自動的に分担させているから。普通なら何時間もかかるような集計を、力技で一気に片付けてくれるイメージです。
従来のデータベースとの違い
ここで「普段使っているMySQLなどのデータベースと何が違うの?」と疑問に思う方もいるかもしれません。ざっくり言うと、両者は得意分野が違います。
MySQLのような一般的なデータベースは、「ユーザー情報を1件追加する」「在庫数を1つ減らす」といった、細かいデータの読み書きを高速にこなすのが得意です。一方でBigQueryは、こうした細かい更新は苦手な代わりに、「何億行というデータをまとめて集計・分析する」ことに特化しています。
たとえば「過去5年分の全注文データから、月別の売上トレンドを出す」といった大規模な集計こそ、BigQueryの真骨頂です。日々の細かな処理は通常のデータベースに任せ、溜まった大量のデータをドカッと分析したい時にBigQueryを使う、というのが基本的な棲み分けになります。
一般公開データセットを活用しよう
「手軽に試してみたいけど、肝心のデータがない…」という方に朗報です。BigQueryには「一般公開データセット(パブリックデータセット)」が豊富に用意されています。
Wikipediaのページビュー履歴や、GitHubのソースコード情報、PyPI(Pythonライブラリ)のダウンロード履歴など、Google Cloudが提供している巨大なデータを使って、すぐにデータ分析の実践練習を始めることができます。
BigQueryの料金体系と注意点
「そんなすごいシステム、お高いんでしょう?」と思うかもしれませんが、BigQueryは初期費用なしで、使った分だけ支払う「従量課金制」(クエリでスキャンしたデータ量に応じた課金)となっています。
しかも、毎月最初の1TB(テラバイト)まではクエリ処理が無料という太っ腹な「無料枠」が用意されているため、個人の学習やちょっとした検証であれば、実質0円で十分遊ぶことができます。
ただし、1TBの無料枠があるとはいえ、注意も必要です。何度も繰り返しクエリを実行したり、自動化ジョブなどに組み込んで本格的に運用し始めると、気づかないうちに無料枠を消費し、意図せず高額請求に繋がるケースもあります。
本格的な運用を見据えてコストを抑えるコツについては、弊社の過去記事「Google Cloud BigQueryのコスト最適化を考える」で解説していますので、あわせて参考にしてみてください。
「まずは安全に試したい!」という方は、「BigQuery Sandbox」モードを利用するのが一番おすすめです。クレジットカードの登録すら不要なので、「うっかり使いすぎて高額請求が来たらどうしよう……」といった心配は一切無用です。まずはコストを気にせず、データ分析の面白さを思いっきり体験してみましょう!
ただし、今後のためにも以下の基本的な「防衛策」は最初から癖をつけておくのがおすすめです!
- 「SELECT *」は使わない
全カラムをスキャンするとコストがかさみます。必要なカラム(列)だけを指定しましょう。 - 実行前にスキャン量を確認する
画面右上に出る「このクエリを実行すると〇〇MBが処理されます」という見積もりを、実行ボタンを押す前に必ず確認する癖をつけてください。
BigQueryの基本的な使い方(3ステップ)
BigQueryの操作は、とてもシンプルです。専用ソフトのインストールや面倒な環境構築は不要で、すべてブラウザ上で完結します。基本的な流れは、たったの3ステップ。さっそく見ていきましょう。
1. Google CloudコンソールからBigQueryを開く
Google Cloudのコンソール画面にアクセスし、上部の検索窓で「BigQuery」と検索して選択します。専用のソフトをインストールする必要はありません。画面が開いたら「SQLクエリ」をクリックして、新しいクエリ作成画面を立ち上げましょう。

2. エディタにSQL(クエリ)を入力する
クエリ作成画面が開いたら、エディタ領域に、集計したいデータの内容を指示する「SQL」を入力します。
SQLが分からなくても大丈夫。このエディタに表示されている「Gemini を使用して SQL を生成」から日本語で指示するだけで、AIが自動でSQLを書いてくれます(この後の実践パートで実際に使っています)。
3. 実行して結果を確認する
SQLを入力したら、エディタ上部の「実行」ボタンをクリックするだけ!数秒後には、画面下部に集計結果の表(テーブル)が表示されます。
たったこれだけです!それでは、次からはこの手順を使って、実際に一般公開データセットを分析してみましょう。
実際にやってみた!データ分析3選
ここからは、実際に一般公開データセットを使って分析してみた結果をご紹介します。今回は、SQLひとつでどのようなデータが抽出できるのか、3つのテーマで実際に試してみました。
なお、今回ご紹介する3つのクエリをすべて実行しても、合計のスキャン量は約61.73 GBです。毎月の無料枠(1TB=約1,000GB)のわずか6%程度しか消費しませんので、ぜひ安心して一緒に手を動かしてみてください!
やってみた1:今川焼きの呼び方分析
日本全国で「大判焼き」「回転焼き」「御座候」など様々な呼び方がある、あのお菓子の名称論争。今回は、Wikipediaのページビューデータ(2025年1月)を使って、どれが一番調べられているのかを分析してみました。
SQLの作成には、BigQueryに搭載されたAIアシスタント「Gemini」を活用しました。エディタの「Gemini を使用して SQL を生成」から、日本語で指示するだけでSQLを自動生成してくれます。
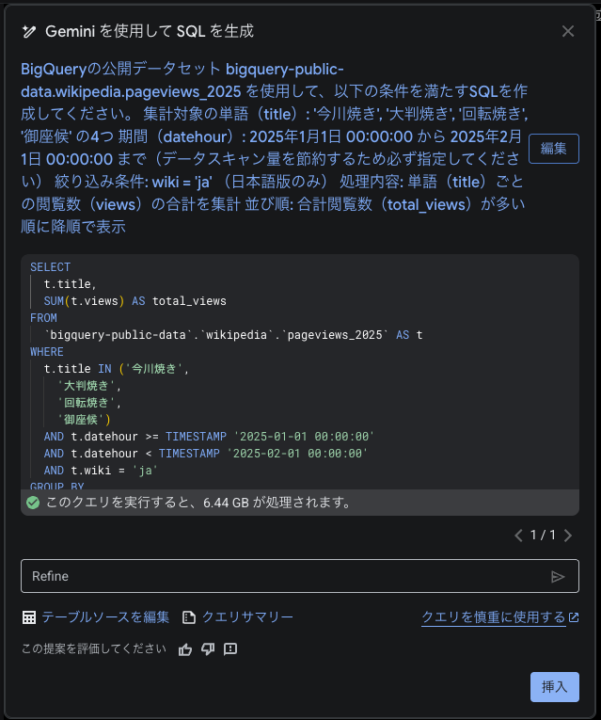
図1:GeminiでのSQL生成の様子
AIが作ってくれたSQLはこちらです。
SELECT title, SUM(views) AS total_views
FROM `bigquery-public-data.wikipedia.pageviews_2025`
WHERE
datehour >= '2025-01-01 00:00:00'
AND datehour < '2025-02-01 00:00:00'
AND wiki = 'ja'
AND title IN ('今川焼き', '大判焼き', '回転焼き', '御座候')
GROUP BY title
ORDER BY total_views DESC;
(※このクエリを実行した際のスキャン量は 約6.44 GB です。毎月1TBの無料枠に対してわずか0.6%ほどですので、安心して実行できます。)
これを実行してみると……集計結果は以下の通りです!
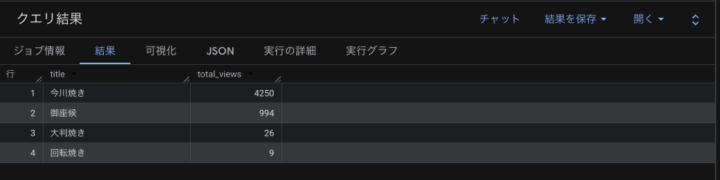
図2:今川焼きの呼び方集計結果
【分析結果(閲覧数)】
* 今川焼き:4,250
* 御座候:994
* 大判焼き:26
* 回転焼き:9
Wikipedia上では「今川焼き」が圧倒的多数という結果になりました!次いで「御座候」が健闘しています。身近な疑問も、BigQueryならSQLひとつで白黒つけられますね。
やってみた2:世界遺産の閲覧数比較
次に、日本の世界遺産がグローバルでどれくらい閲覧されているのかを、日本語版と英語版のWikipedia閲覧数で比較してみました。今回は、2025年8月のデータを対象に集計しています。
比較には日本語のタイトルと英語のタイトルを紐付ける必要があるため、以下のようなクエリを実行しました!
WITH
heritage_mapping AS (
SELECT '屋久島' AS ja_title, 'Yakushima' AS en_title
UNION ALL
SELECT '白神山地', 'Shirakami-Sanchi'
UNION ALL
SELECT '知床', 'Shiretoko'
UNION ALL
SELECT '小笠原諸島', 'Ogasawara_Islands'
UNION ALL
SELECT
'奄美大島、徳之島、沖縄島北部及び西表島',
'Amami-Ōshima_Island,_Tokunoshima_Island,_Northern_part_of_Okinawa_Island,_and_Iriomote_Island'
UNION ALL
SELECT '法隆寺', 'Hōryū-ji'
UNION ALL
SELECT '姫路城', 'Himeji_Castle'
UNION ALL
SELECT
'古都京都の文化財',
'Historic_Monuments_of_Ancient_Kyoto_(Kyoto,_Uji_and_Otsu_Cities)'
UNION ALL
SELECT '白川郷', 'Historic_Villages_of_Shirakawa-gō_and_Gokayama'
UNION ALL
SELECT '原爆ドーム', 'Hiroshima_Peace_Memorial'
UNION ALL
SELECT '厳島神社', 'Itsukushima_Shrine'
UNION ALL
SELECT '古都奈良の文化財', 'Historic_Monuments_of_Ancient_Nara'
UNION ALL
SELECT '日光の社寺', 'Shrines_and_Temples_of_Nikkō'
UNION ALL
SELECT
'琉球王国のグスク及び関連遺産群',
'Gusuku_Sites_and_Related_Properties_of_the_Kingdom_of_Ryukyu'
UNION ALL
SELECT
'紀伊山地の霊場と参詣道',
'Sacred_Sites_and_Pilgrimage_Routes_in_the_Kii_Mountain_Range'
UNION ALL
SELECT '石見銀山', 'Iwami_Ginzan_Silver_Mine'
UNION ALL
SELECT '平泉', 'Hiraizumi'
UNION ALL
SELECT '富士山', 'Mount_Fuji'
UNION ALL
SELECT '富岡製糸場', 'Tomioka_Silk_Mill'
UNION ALL
SELECT
'明治日本の産業革命遺産',
"Sites_of_Japan's_Meiji_Industrial_Revolution:_Iron_and_Steel,_Shipbuilding_and_Coal_Mining"
UNION ALL
SELECT '国立西洋美術館', 'National_Museum_of_Western_Art'
UNION ALL
SELECT
'宗像・沖ノ島と関連遺産群',
'Sacred_Island_of_Okinoshima_and_Associated_Sites_in_the_Munakata_Region'
UNION ALL
SELECT
'長崎と天草地方の潜伏キリシタン関連遺産',
'Hidden_Christian_Sites_in_the_Nagasaki_Region'
UNION ALL
SELECT '百舌鳥・古市古墳群', 'Mozu_Tombs'
UNION ALL
SELECT
'北海道・北東北の縄文遺跡群',
'Jōmon_Prehistoric_Sites_in_Northern_Japan'
UNION ALL
SELECT '佐渡金山', 'Sado_mine'
),
raw_data AS (
SELECT wiki, title, views
FROM `bigquery-public-data.wikipedia.pageviews_2025`
WHERE
datehour >= '2025-08-01 00:00:00'
AND datehour < '2025-09-01 00:00:00'
AND wiki IN ('ja', 'en')
)
SELECT
m.ja_title AS heritage_name,
SUM(IF(d.wiki = 'ja' AND d.title = m.ja_title, d.views, 0)) AS ja_views,
SUM(IF(d.wiki = 'en' AND d.title = REPLACE(m.en_title, ' ', '_'), d.views, 0))
AS en_views
FROM heritage_mapping m
LEFT JOIN raw_data d
ON (
d.wiki = 'ja' AND d.title = m.ja_title)
OR (d.wiki = 'en' AND d.title = REPLACE(m.en_title, ' ', '_'))
GROUP BY heritage_name
ORDER BY ja_views DESC;
(※このクエリのスキャン量は約54.23 GBです。少し大きめに見えますが、1TBの無料枠に対してはわずか5%程度です)
クエリを実行すると、以下のようにデータが集計されます。
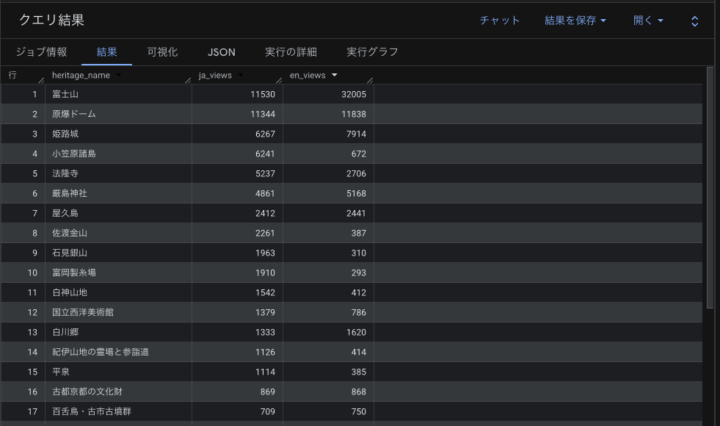
図3:世界遺産の閲覧数集計結果(表データ)
無事に集計できましたが、数字の羅列だと少し直感的に捉えづらいですよね……。
そんな時は、集計したデータをシームレスに連携できるBIツールデータポータル(旧Looker Studio)の出番です!
クエリ結果の画面にある「開く」ボタンから「データポータル」を選択するだけで、ブラウザ上で簡単に連携できます。
図4:「開く」ボタンからデータポータルへ連携
データポータルの画面では、表計算ソフトのように直感的な操作でグラフの見た目を整えることができます。実際にデータをグラフにしてみたのがこちらです。
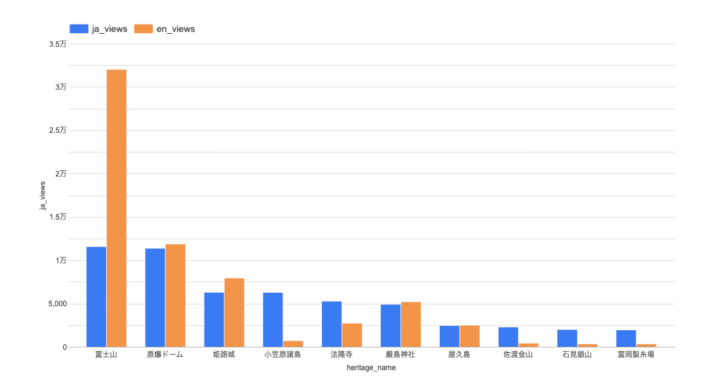
図5:データポータルで作成した世界遺産の閲覧数比較グラフ
一目でトレンドが分かるようになりましたね!「富士山」は英語版での閲覧数が日本語版を圧倒的に上回っており、ほかにも「姫路城」や「厳島神社」などが英語版の方が多く調べられているなど、海外からの関心の高さが伺えます。
やってみた3:BigQueryライブラリのダウンロード数調査
最後の分析は、エンジニアにとって身近な「開発ツール」に関するデータです。今まさに私たちが使っているBigQueryをPythonから操作する公式ライブラリが、世界中でどれくらいダウンロードされているのかをPyPI(Pythonパッケージインデックス)のデータから調べました。
実行したSQLはこちら。直近1週間の確定済みデータを厳密に抽出しています。
SELECT COUNT(*) AS total_weekly_downloads FROM `bigquery-public-data.pypi.file_downloads` WHERE file.project = 'google-cloud-bigquery' AND DATE(timestamp) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND DATE(timestamp) < CURRENT_DATE();
(※このクエリのスキャン量は約1.06 GBです)
集計した結果……なんと、約3,723万回(37,231,204回)でした!

図6:BigQueryライブラリの1週間のダウンロード数
1週間で約3,700万回!
世界中の開発環境やCI/CDパイプラインにおいて、1秒あたり約60回のペースで pip install google-cloud-bigquery が実行されている計算になります。
今まさに使っているこのBigQueryが、世界中の現場で日常的に動いている技術であることが、数字から伝わってきますね。
まとめ:データを用意しなくても、すぐに分析は始められる
今回はBigQueryの一般公開データセットを使って、Wikipediaの閲覧数やPyPIのダウンロード数など、まったく異なるジャンルのデータを集計してみました。
データ分析において「大量のデータを用意する」のは意外とハードルが高いですが、公開データセットを使えば、自分でイチからデータを用意しなくても、すぐに実践的なデータ分析ができるのは大きな魅力です。
Google Cloudのアカウントさえあれば、ブラウザからすぐに実行できます。ぜひ皆さんも、一般公開データセットを活用して、気になるデータの分析に挑戦してみてください!

