
はじめに
第1回ではサーバーレス設計とリアルタイム同期を、第2回ではネットワーク・セキュリティ設計を解説しました。
本稿では最終回として、残る2つのテーマを取り上げます。
- データ分析基盤:Firebase Extensions による Firestore → BigQuery のゼロ運用データパイプラインと、Looker Studio ダッシュボード
- オブザーバビリティ:Cloud Monitoring・Cloud Logging・Error Reporting を使った、Google Cloud ネイティブな監視スタック
本連載を通じて一貫してきた設計方針は「ゼロメンテナンス」です。
本稿で紹介するデータ分析基盤もオブザーバビリティも、この方針に沿って「外部 SaaS に頼らず、Google Cloud の仕組みの中で完結させる」ことを優先しています。
データ分析基盤
なぜデータ分析基盤が必要か
会議室予約システムを運用していくうえで、「どの会議室が空予約されやすいか」「何時間帯の稼働率が低いか」といった問いに答えられることが重要です。
しかし Firestore は OLTP 向けのデータストアであり、集計・分析クエリには向きません。
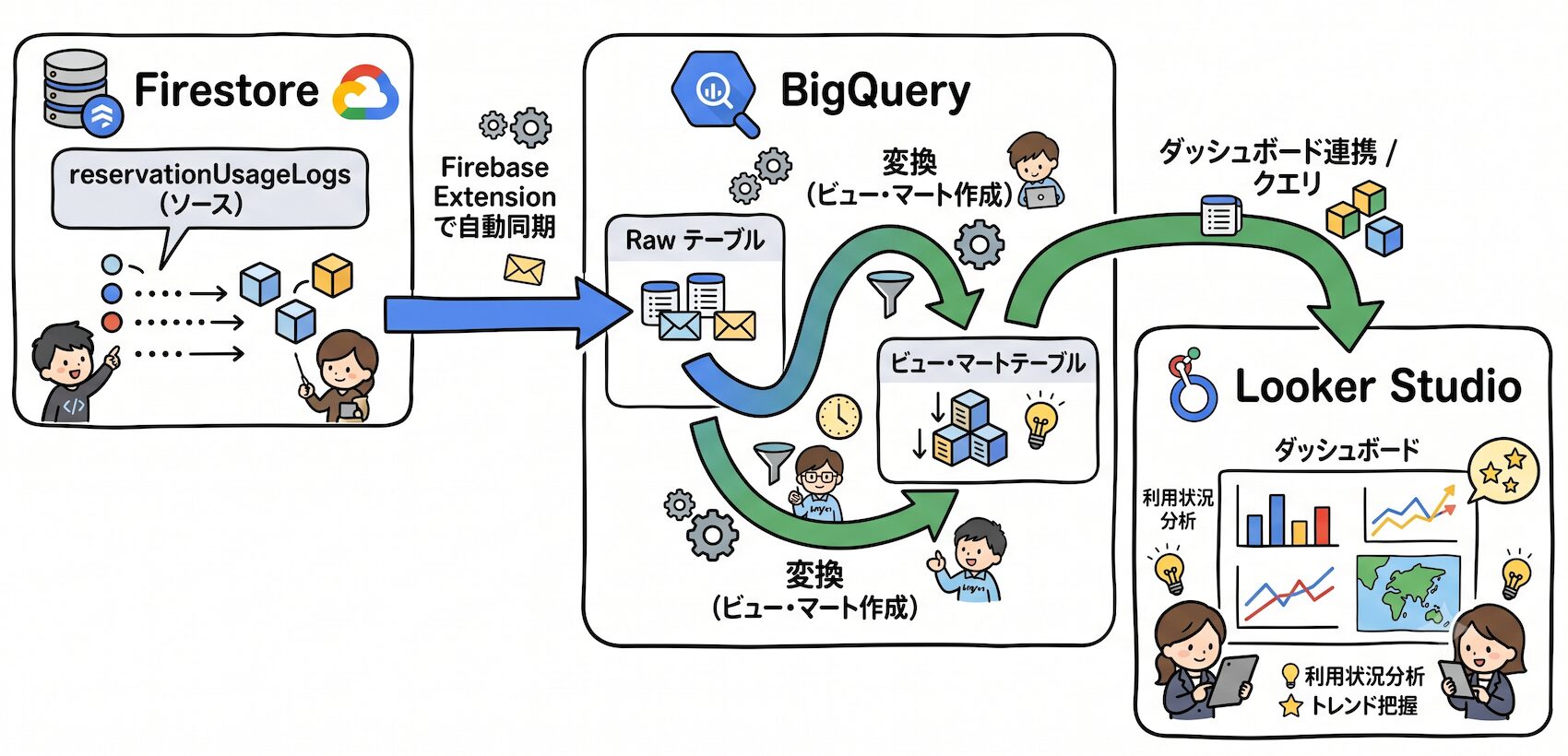
そこで Firestore のデータを BigQuery に流し込み、Looker Studio でダッシュボードとして可視化する分析基盤を構築しました。
Firebase Extensions
分析基盤の肝は、Firestore から BigQuery へのデータ連携をどう実現するかです。
選択肢として Cloud Functions を自前実装する方法もありますが、本システムでは Firebase Extensions(firebase/firestore-bigquery-export) を採用しました。
Firebase Extensions とは、Firebase が公式に提供するアドオン機能です。
設定するだけで、Firestore の指定コレクションへの書き込みをトリガーに BigQuery へ自動的にストリーミングする仕組みが展開されます。
そのため、コードを一切書かずにデータパイプラインが完成します。
BigQuery
Extension が BigQuery に書き込むのは Firestore の生データです。このままでは2つの問題があります。
1つ目はデータ型の問題です。Firestore の Timestamp 型は BigQuery では JSON 構造として格納されるため、分析クエリのたびに変換が必要になります。
2つ目はコストの問題です。ビューを Looker Studio に直接接続すると、ダッシュボードを開くたびに生データからフルスキャンが走りコストが積み上がります。
これを解決するため、BigQuery 内に3層のレイヤーを設けています。
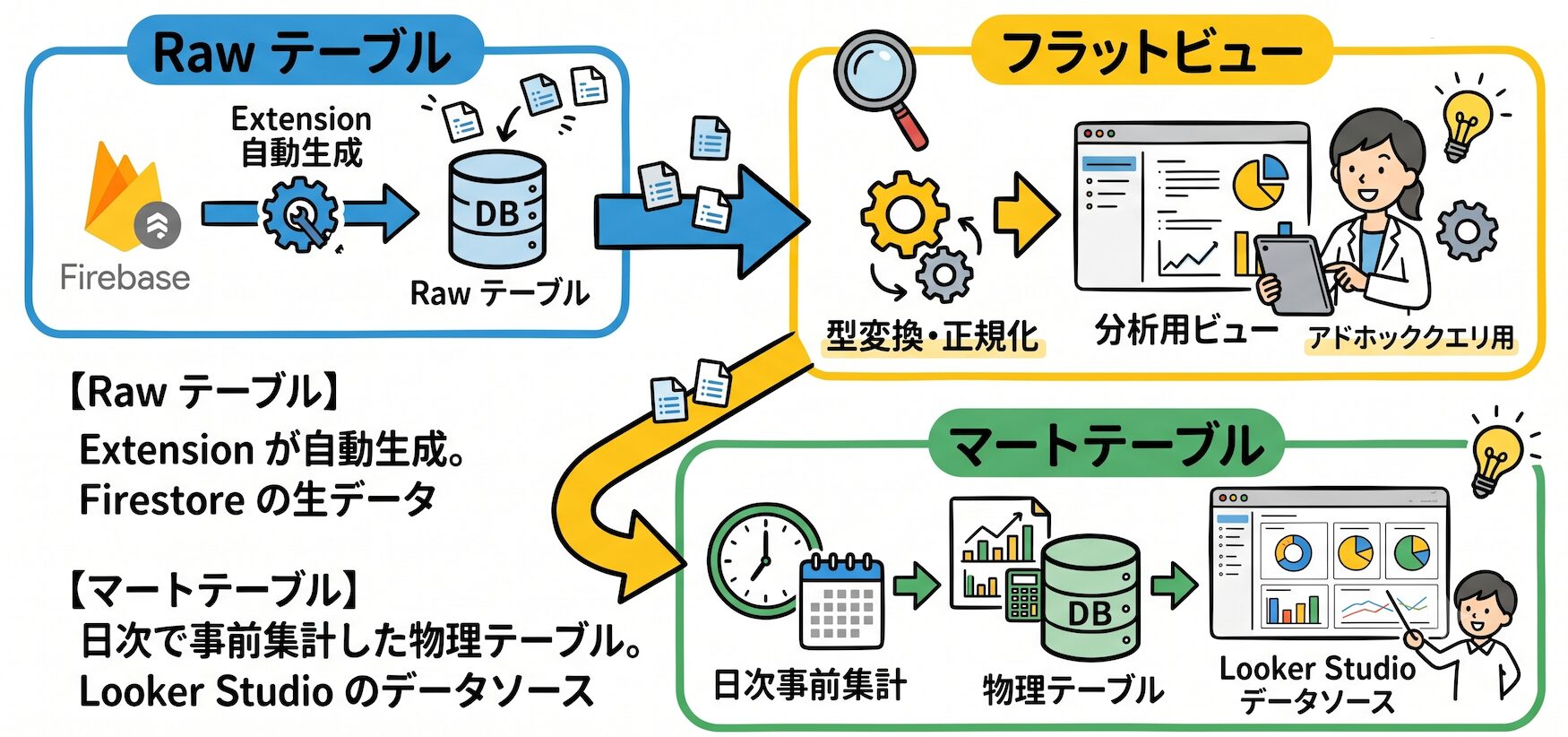
フラットビューは Firestore 特有の型変換や派生フィールドの計算(利用率・入室遅延など)をまとめて行うレイヤーです。
このビューを挟むことで、Looker Studio 側のカスタムフィールドを最小限に抑えられます。
マートテーブルはダッシュボード向けに事前集計した物理テーブルです。BigQuery のスケジュールクエリで毎日深夜に更新します。
| 項目 | フラットビュー | マートテーブル |
|---|---|---|
| クエリ速度 | 遅い(毎回集計) | 高速(事前集計済み) |
| スキャン量 | 大(全生データ) | 小(集計済みデータのみ) |
| データ鮮度 | リアルタイム | 日次更新(最大1日遅延) |
| 主な用途 | アドホック分析 | ダッシュボード・定例レポート |
ダッシュボードは「前日までのデータを見る」用途であり、1日の遅延は許容できます。
鮮度よりもコストと速度を優先した判断です。
Looker Studio
Looker Studio では以下の4ページ構成でダッシュボードを構築しています。
| ページ | 内容 |
|---|---|
| 会議室利用概要 | KPI スコアカード・日別推移・会議室別比較 |
| カラ予約分析 | カラ予約率の高い主催者ランキング・曜日×時間帯のヒートマップ |
| 利用効率分析 | 予約時間 vs 実利用時間の散布図・時間帯別稼働率 |
| トレンド | 週次/月次の利用率推移・前月比較 |
データソースはページの用途によって使い分けています。
個人別・予約単位の分析にはフラットビューを、集計値の表示やトレンドにはマートテーブルを接続しています。
ただ、データ分析全般は実際に運用してデータが蓄積されてから、「どの指標が現場で使われているか」「追加で見たい切り口はないか」を見直す余地があると考えています。
オブザーバビリティ
方針:外部 SaaS を使わない
ツール選定にあたり、New Relic や Datadog といった外部 SaaS は採用しませんでした。
理由は2つあり、ランニングコストの増加と、Google Cloud ネイティブの機能で十分カバーできるという判断です。
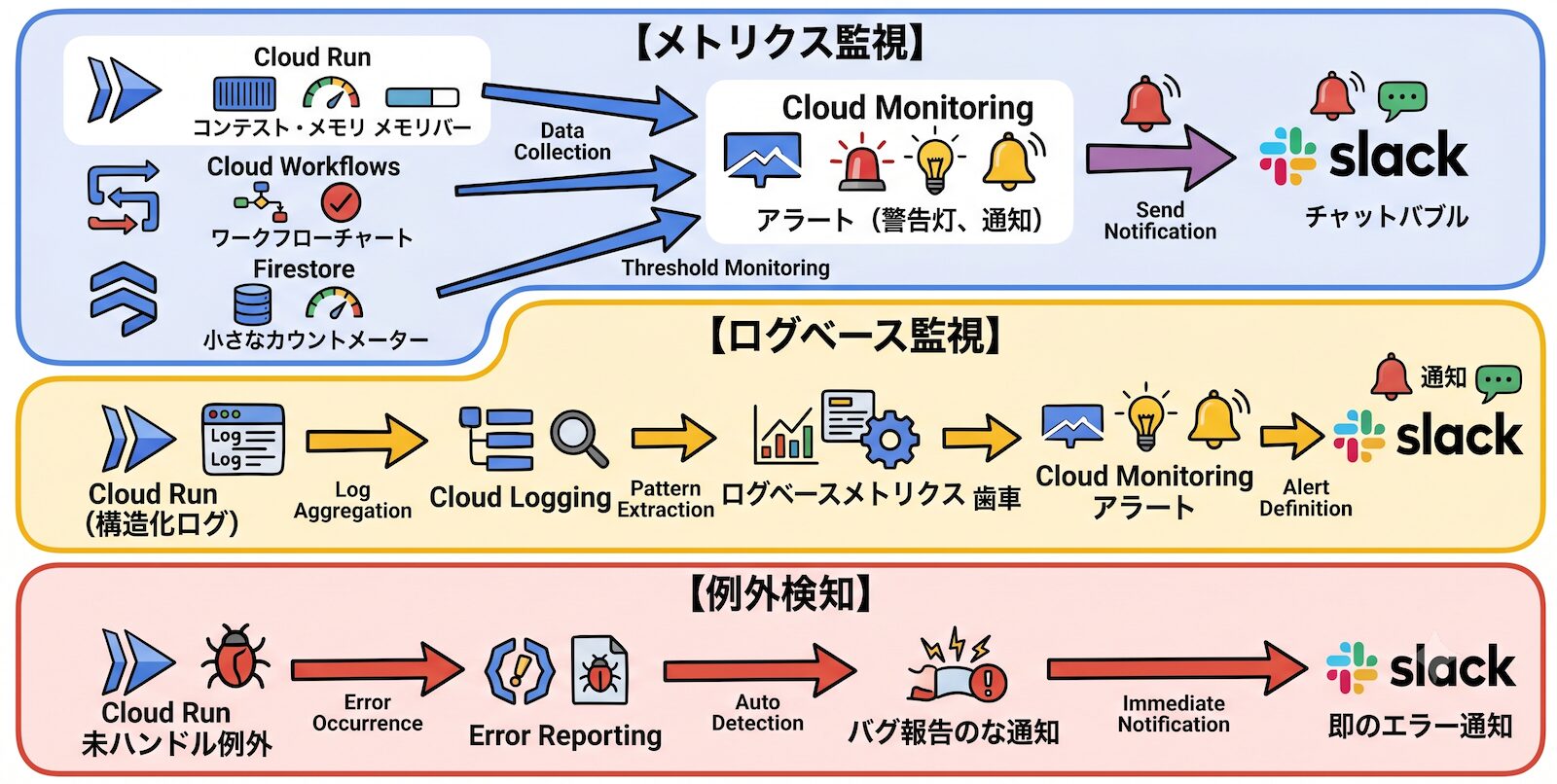
本システムのオブザーバビリティは Cloud Monitoring・Cloud Logging・Error Reporting の3つで完結しています。
なお、Cloud Trace などの Application Performance Monitoring(APM) は今回採用していません。
本システムはアクセスピークや重い処理のないシステムであり、現時点でパフォーマンスのボトルネックが問題になる場面が想定しにくいためです。
障害検知に絞ったシンプルな監視スタックで、現状は十分と判断しました。
もう一つの方針が「一時的なエラーにはアラートを出さない」です。
Google Calendar API の一時的なタイムアウトや Cloud Run のコールドスタートは、次回のバッチ実行(最大1分後)で自動復旧します。
そのため、連続失敗のように自動復旧でカバーしきれない状態のみをアラート対象としています。
Cloud Monitoring
監視はメトリクス監視とログベース監視の二層で構成しています。
メトリクス監視はシステム全体の傾向を捉えます。
Cloud Run のリクエスト数・メモリ使用率、Workflows の実行結果、Firestore の読み書き回数といった Google Cloud 標準メトリクスをそのまま活用できます。
一般的にレイテンシも監視するケースが多いかと思いますが、前述の理由から意図的に外しています。
ログベース監視はメトリクスでは捉えにくい個別のエラーパターンを検知します。
アプリが出力する構造化ログから特定のフィールドをフィルタリングしてカウントするログベースメトリクスを作成し、Cloud Monitoring のアラートポリシーに接続しています。
Cloud Logging
Cloud Run のログは Cloud Logging に自動で収集されます。
ログを活用しやすくするため、アプリは JSON 形式の構造化ログを出力しています。
構造化ログにしておくと、Cloud Logging 上でフィールド単位での絞り込みが可能になります。
特定の外部サービスのエラーだけを抽出したり、特定の会議室に関するログだけを絞り込んだりといった運用が、条件式一本でできます。
前述のログベース監視も、この構造化ログがあって初めて成立します。
Error Reporting
Cloud Run 上で未ハンドルの例外が発生すると、Error Reporting が自動的に検出・グループ化します。こちらも設定不要で動作する点が選定理由の1つですね。
同じスタックトレースを持つエラーを1つのグループとして集約し、初回・最終発生日時と発生回数を一覧で確認できます。
新規エラーグループを検出した際は Slack へ通知します。
Cloud Monitoring のアラートは「N 分間に N 回以上」という集計ベースの検知です。
一方 Error Reporting は「今まで見たことのない新しいエラーが発生した」という個別の検知が得意です。
この二層でエラーの見落としを防いでいます。
通知パイプライン
アラートの通知先はすべて Slack チャンネルに集約しています。
通知先を一か所にまとめることで、担当者が複数のコンソールを巡回する必要がなくなります。
Slack の通知には Google Cloud コンソールへの直接リンクが含まれるため、アラートから原因調査までの動線が短くなります。
まとめ
3回にわたって、会議室予約システムの Google Cloud アーキテクチャを解説してきました。
本連載全体を通じて登場したサービスと、各サービスが「ゼロメンテナンス」に貢献している役割を整理します。
| カテゴリ | サービス | 運用負荷をゼロにする役割 |
|---|---|---|
| コンピュート | Cloud Run | スケール・トゥ・ゼロ、OS/ランタイム管理不要 |
| バッチ | Cloud Scheduler + Cloud Workflows | 定期実行の宣言的管理、IAP 認証の自動処理 |
| データストア | Cloud Firestore | リアルタイム同期を Snapshot Listener に委ねる |
| 認証 | IAP | 認証ロジックをアプリに書かない |
| ネットワーク | VPC + Private Google Access + Cloud NAT | セキュリティポリシーをインフラ層に閉じ込める |
| 鍵管理 | Workload Identity Federation | サービスアカウントキーのローテーション不要 |
| データ分析 | Firebase Extensions + BigQuery | データパイプラインをコードなしで構築 |
| 監視 | Cloud Monitoring + Cloud Logging + Error Reporting | 外部 SaaS 不要、Google Cloud ネイティブで監視完結 |
フルマネージドサービスを最優先に選び、認証・ネットワーク・データ連携・監視をそれぞれインフラ側で完結させる。
この設計方針を一貫して適用することで、少人数チームでも安心して運用できるシステムが実現できました。


