
こんにちは、セキュリティエンジニアの田所です。
現地参加している AWS Summit Japan 2026 からセッションの模様をお届けします。
セッションについて
AIM311 生成 AI モデルを選ぶ技術 – モデル選択のフレームワーク –
生成 AI のモデルは選択肢が増え続け、進化のスピードも加速しています。一方で「本番で期待どおりの品質が出ているか」「モデルを変えたら何が良くなるのか」を定量的に測れている組織はまだ多くありません。本セッションでは、Identify/Evaluate/Optimize の 3 ステップによるモデル選択フレームワークを軸に、実際のお客様のユースケースを通貫事例として、ゴールデンデータセットや LLM-as-a-Judge によるモデル評価から、エージェントの振る舞いを評価する手法まで、Amazon Bedrock の機能と実践的なアプローチを交えて解説します。
ブレイクアウトセッションとして、増え続ける生成 AI モデルをどう選び、どう評価し、どう最適化するかを、不正取引調査エージェントの事例を通して解説する内容でした。

1. モデル選定のフレームワーク
まず投げかけられたのは、「とりあえず有名なモデルを使っている、になっていませんか?」という問いでした。
モデルの選択肢が多いのは本来うれしいことのはずですが、増えすぎ・進化が速すぎて、どう選べばよいのか分かりにくくなっているのが実情です。

ここで軸になるのが、Identify → Evaluate → Optimize という3ステップのモデル選択フレームワークです。
主要モデルを幅広くカバーし、評価ツールやモデルインポートも備えた Amazon Bedrock を使いながら、このステップを回していきます。
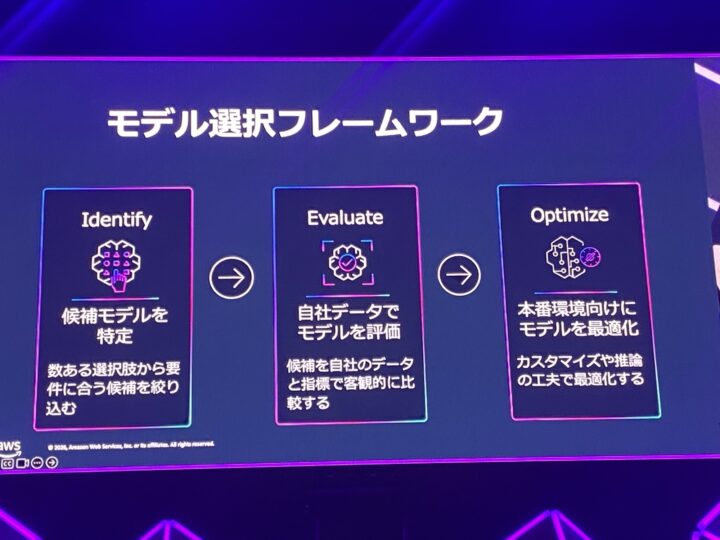
最初の Identify は、候補を絞り込むステップです。
テキスト・画像・音声といったモダリティで絞り、ベンチマークを参照し、モデル固有の強みを見ていきます。
いずれも「要件起点」で判断するのがポイントですね。

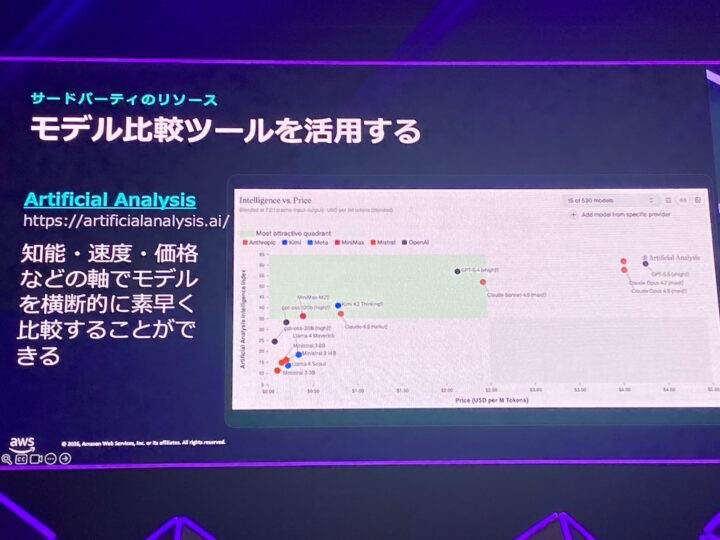
ベンチマークの参照には、モデルを横断してメトリクスを比較できる Artificial Analysis のようなツールが紹介されていました。
ここでも、自分の用途に近い指標を見ることが大切とのことです。
3つ目の Optimize は、選んだモデルを磨き込むステップです。
固有タスクの精度を上げるモデルカスタマイズ(ファインチューニング)、再計算をスキップしてコストとレイテンシを抑えるプロンプトキャッシング、サービス階層のティアを調整して応答速度とコストのバランスを取る推論最適化、が挙げられていました。

増えすぎて速すぎて選べない、というのは確かにここ最近で急にホットになった課題で、こうした地図を持っておけるのは心強いですね。
2. ゴールデンデータセット
3ステップの中核である Evaluate をもう少し掘り下げます。
新しいモデルが出たときに乗り換えるべきか、どのくらいの時間をかけてどう判断するか。
その物差しになるのが、プロンプトと正解をセットにしたゴールデンデータセットです。

ただ、網羅的なゴールデンデータセットを人手だけで作るのは大変です。
そこで提案されていたのが、人間と AI で役割分担して作るというアプローチでした。
ペルソナを設定したエージェントに、質問を作る → 回答を生成する → 回答をチェックする、という役割を分担させます。
ペルソナの解像度を上げることが精度や網羅性を高める鍵で、人間はそのやり取りを観察して評価基準を更新する、いわば「判断の物差しを作る」役割を担います。
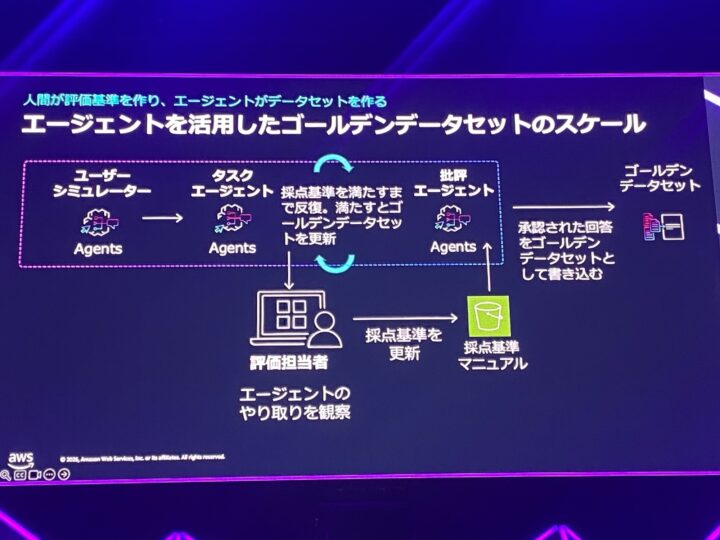
ゴールデンデータセットで測るのは、コスト・レイテンシ・スケーラビリティといった運用メトリクスと、品質・正確性やスタイル、責任ある AI、カスタムメトリクスといった包括的な評価メトリクスの両面です。

ゴールデンデータセットを AI と分担しながら作るというのは、AI と協働する新しい働き方に近いものを感じました。
3. LLM-as-a-Judge
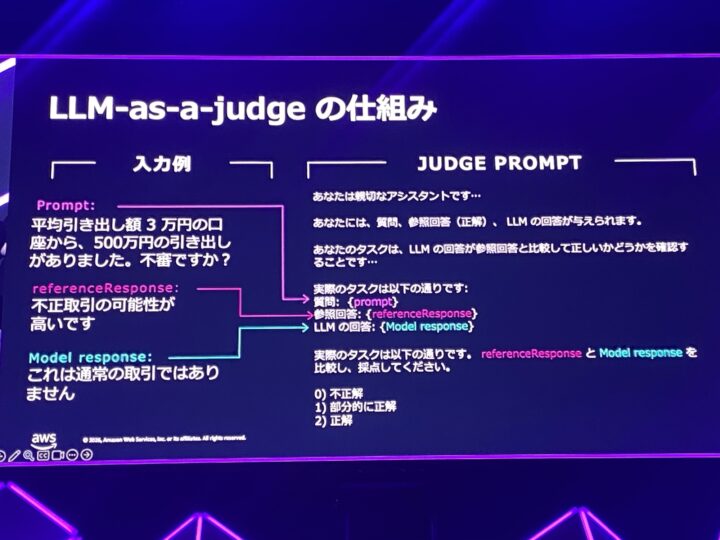
では、その指標をどうやって測るのでしょうか。
評価手法には、アルゴリズムで評価するプログラマティック、人間、そして LLM-as-a-Judge の3つがあり、Amazon Bedrock の model evaluation でカバーされています。

LLM-as-a-Judge の仕組みはシンプルで、ゴールデンデータセットのプロンプトと正解、そしてモデルの回答を突き合わせ、正しいかどうかを判定するというものです。
さらに踏み込むのが、「エージェントの振る舞いは正しいか?」という観点です。
最終的な出力だけを見ると正解でも、途中で必要な手順を飛ばしているかもしれません。
そこでゴールデンデータセットに期待する手順(軌跡)を追加し、最終出力だけでなく途中のプロセスも評価対象にします。
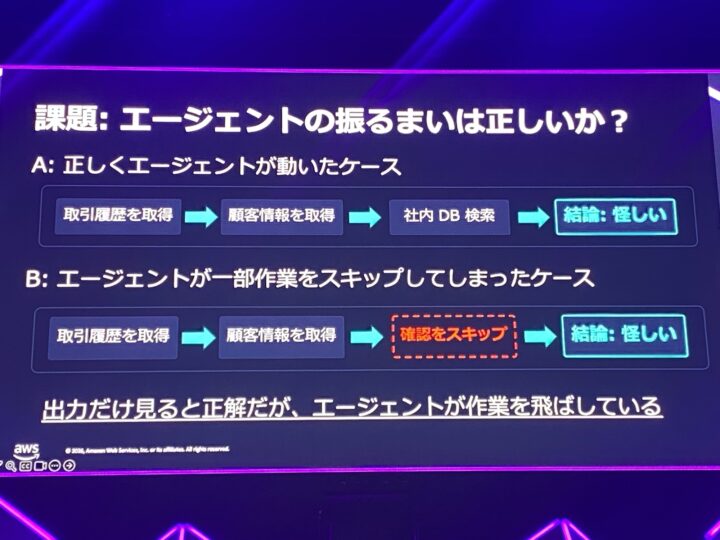
この振る舞いの評価は、Amazon Bedrock AgentCore evaluations でカバーされており、エージェントの軌跡を可視化しながら検証できます。

途中のプロセスまで評価するという考え方は、人事部の評価制度にも通ずるものがある仕組みだと感じました。
まとめ
モデル選定のフレームワーク(Identify → Evaluate → Optimize)と、それを支えるゴールデンデータセットや LLM-as-a-Judge による評価を見てきました。
通貫事例だった不正取引調査エージェントでは、目標としていた精度(20%)の改善を達成しつつ、コストを 80% 削減できたとのことでした。
選び方と評価が仕組みになっていれば、こうした成果まで一気通貫でたどり着けるわけですね。

個人的に一番刺さったのは、「選び方そのものを仕組みとして持っておく」というメッセージでした。
モデルが増え続けることが前提なら、選定を都度の勘ではなく再現可能なプロセスにしておくことが、これから効いてくるのだろうと感じました。
おしまい

![[AWS Summit Sydney 2026] エージェンティックな世界における先進的なチーム構造](https://iret.media/wp-content/uploads/2026/06/5be593864f50750d0997386cb691de4f-220x123.jpg)
