
tl;dr
- 定期的に Elasticsearch に問い合わせを行うバッチスクリプトで Elasticsearch への問い合わせ回数を減らしたい
memo
状況
- Amazon ES に保存されたログを検索するバッチスクリプトで特定の ID 毎に日付を範囲してログの件数を取得する
- 当初は ID が少なかったのであまり意識していなかったけど、テストで ID を増やしていったところ CPU 負荷も上がるし、たまに Amazon ES への接続エラーも発生している(認証辺りも絡んでいるかもしれない)
- ID 毎に Elasticsearch に問い合わせを行う実装にしていた(先に気づけよ的な話ではある)
戦略
www.elastic.co
Multi Search API で実装すれば良さそう。
Multi Search API を使う前
以下のような感じのスクリプトで ID 毎に Elaseticsearch に検索していた。
#!/bin/bash
declare -A _hash
_hash["foo"]="2016-09-19T10:00:00+09:00"
_hash["bar"]="2016-09-19T10:00:00+09:00"
_hash["baz"]="2016-09-19T10:00:00+09:00"
while true;
do
for key in ${!_hash[@]}; do
curl -s -XGET "https://${AMAZON_ES_ENDPOINT}/cwl-*/_search" -w "\n" -d "
{
\"size\": 0,
\"query\" : {\"term\" : { \"param_id\" : \"${key}\" }},
\"aggregations\": {
\"id_name\": {
\"terms\": {\"field\": \"param_id\"},
\"aggregations\": {
\"id_count\": {
\"filter\":{
\"range\": { \"@timestamp\": { \"gte\": \"${_hash[${key}]}\", \"lte\": \"now\" }}
}
}
}
}
}
}" | jq -c '.aggregations.id_name.buckets[0]|{"id": .key, "count": .id_count.doc_count}'
sleep 1
done
sleep 3
done
実行すると以下のような出力が得られる。
{"count":867,"id":"foo"}
{"count":863,"id":"bar"}
{"count":865,"id":"baz"}
Multi Search API を使った場合
以下のような感じで検索する。コードの行数も減らせてイイ感じ。
#!/bin/bash
declare -A _hash
_hash["foo"]="2016-09-19T10:00:00+09:00"
_hash["bar"]="2016-09-19T10:00:00+09:00"
_hash["baz"]="2016-09-19T10:00:00+09:00"
while true;
do
queries=""
for key in ${!_hash[@]}; do
queries+="{\"index\": \"cwl-*\"}\n"
queries+="{\"size\": 0,\"query\" : {\"term\" : { \"param_id\" : \"${key}\" }},\"aggregations\": {\"id_name\": {\"terms\": {\"field\": \"param_id\"},\"aggregations\": {\"id_count\": {\"filter\":{\"range\": { \"@timestamp\": { \"gte\": \"${_hash[${key}]}\", \"lte\": \"now\" }}}}}}}}\n"
done
echo -e ${queries} | curl -s -XGET 'https://${AMAZON_ES_ENDPOINT}/_msearch' --data-binary @- | \
jq -c '.responses[].aggregations.id_name.buckets[0]|{"count":.id_count.doc_count,"id":.key}'
sleep 3
done
実行すると以下のような出力が得られる。
{"count":1778,"id":"foo"}
{"count":1744,"id":"bar"}
{"count":1841,"id":"baz"}
Multi Search API を使う場合、クエリは以下のような内容となる。
{"index": ${インデックス名}}
{"query" : ${実際のクエリ}
{"index": ${インデックス名}}
{"query" : ${実際のクエリ}
Elasticsearch へのリクエストは以下のような内容となる。
echo -e ${queries} | curl -s -XGET 'https://${AMAZON_ES_ENDPOINT}/_msearch' --data-binary @-
で、Multi Search API を使ったらどうなったか
以下のようにバッチを動かしているコンテナの CPU 使用率が少しだけ下がった。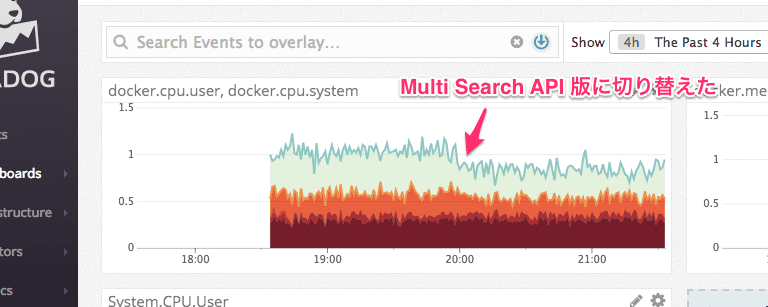
以上
必要に応じて Multi Search API を使いましょう。
