
実際にETLで処理するケースとしては、1日1回定期的に処理するなどのケースが多いと思います。
この場合、追加分のみを抽出してETL処理をする必要があります。
Glueには、前回どこまで処理したかを管理するJob Bookmarksという機能があります。
今回はこのJob Bookmarksを使ってみたいと思います。
確認用のETL処理
S3に配置したapacheのアクセスログをparquet形式に変換します。
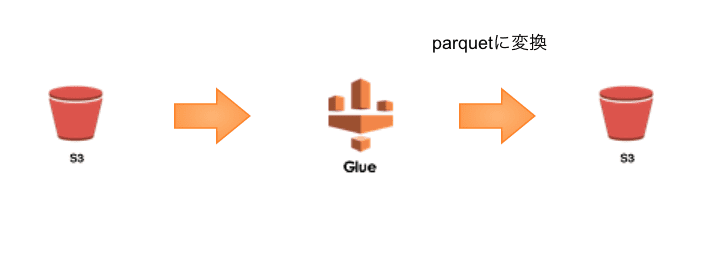
手順概要
①S3にapacheのアクセスログを配置
②Crawler設定、実行
③Job作成、実行
④変換データ確認
⑤S3に追加のログをアップロード
⑥Job再実行
⑦変換データ確認
準備
以下のようなフォーマットのapacheログをそれぞれ10行程度ずつ2ファイル用意します。
200.69.224.58 - - [16/Jan/2018:18:34:42 +0900] "GET /item/computers/2216 HTTP/1.1" 200 65 "/item/games/643" "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)" 40.66.156.206 - - [16/Jan/2018:18:34:42 +0900] "GET /item/games/4918 HTTP/1.1" 200 73 "/item/games/2145" "Mozilla/5.0 (iPad; CPU OS 5_0_1 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A405 Safari/7534.48.3" 48.201.76.35 - - [16/Jan/2018:18:34:42 +0900] "GET /category/toys HTTP/1.1" 200 85 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; YTB730; GTB7.2; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET4.0C; .NET4.0E; Media Center PC 6.0)"
①S3にapacheのアクセスログを配置
S3にbucketを作成し、準備で作成したファイルの一つ目をアップロードします。
②Crawler設定、実行
①で作成したS3用のクローラーを設定して実行します。
③Job作成、実行
左ペインのJobsを選択し「Add Job」をクリックしてJobを追加します。
この時、Job BookmarkをEnableに変更します。それ以外については環境に応じて設定してください。
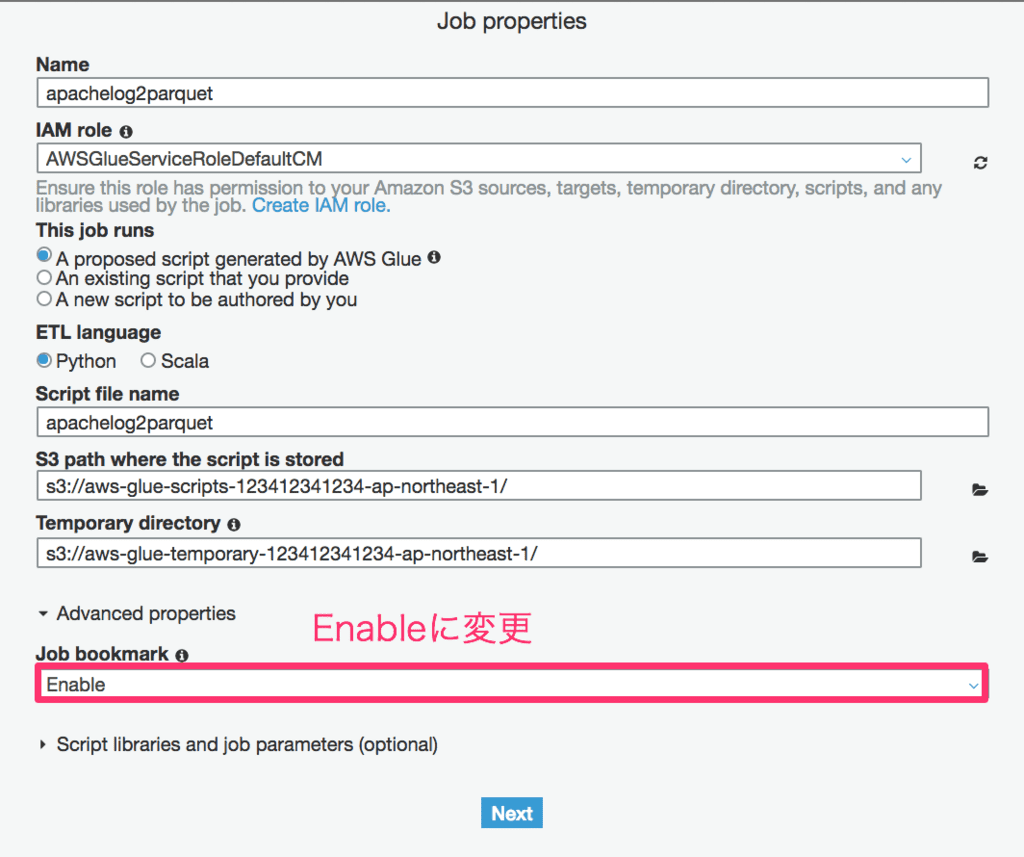
Job bookmarkについては、以下の設定値があります。
デフォルトはDisableになります。
| Job bookmark | 説明 |
|---|---|
| Enable | 前回実行した以降のデータを処理 |
| Disable | 常に全データを処理 |
| Pause | 前回実行した以降のデータを処理するが、状態を更新しない |
※Pauseはどういう時に使えばいいかが分かっていません。
Jobの設定が完了したら、実行してください。
④変換データ確認
上記でJobが正常に実行されたら、変換後のデータを確認します。
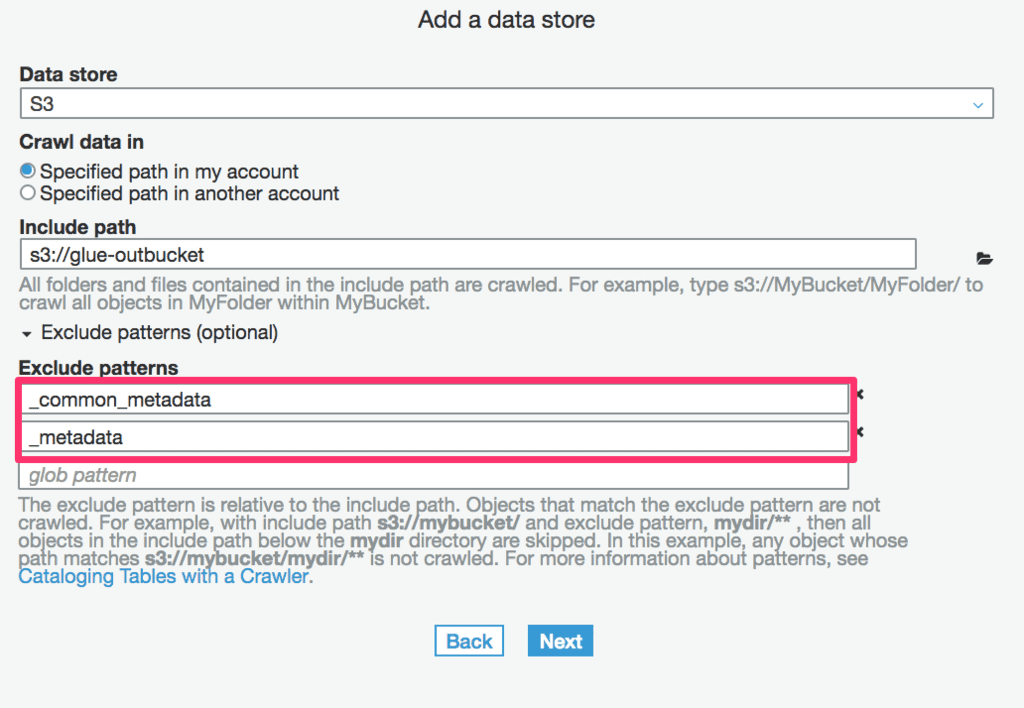
まずは、変換先のS3用のクローラーを設定します。
以下のようにクロール対象から_common_metadataと_metadataを除外するようにセットします。
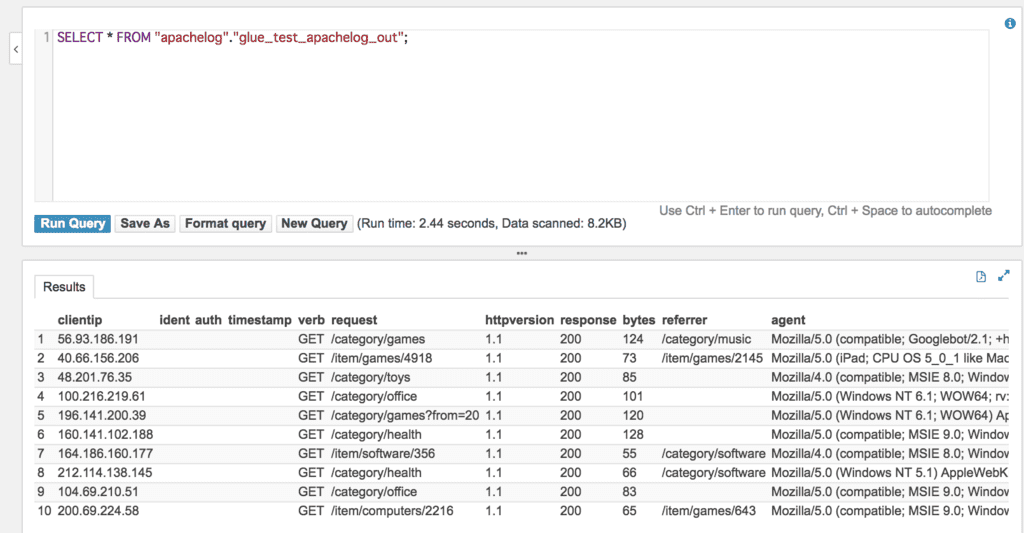
クローラーを実行後、AthenaからSQLを実行してデータが変換されていることを確認します。
今回は1つ目のファイルにはアクセスログを10行用意しました。
⑤S3に追加のログをアップロード
準備で作成したapacheログファイルの二つ目をソースとなるS3にアップロードします。
⑥Job再実行
再度、同一Jobを実行します。
⑦変換データ確認
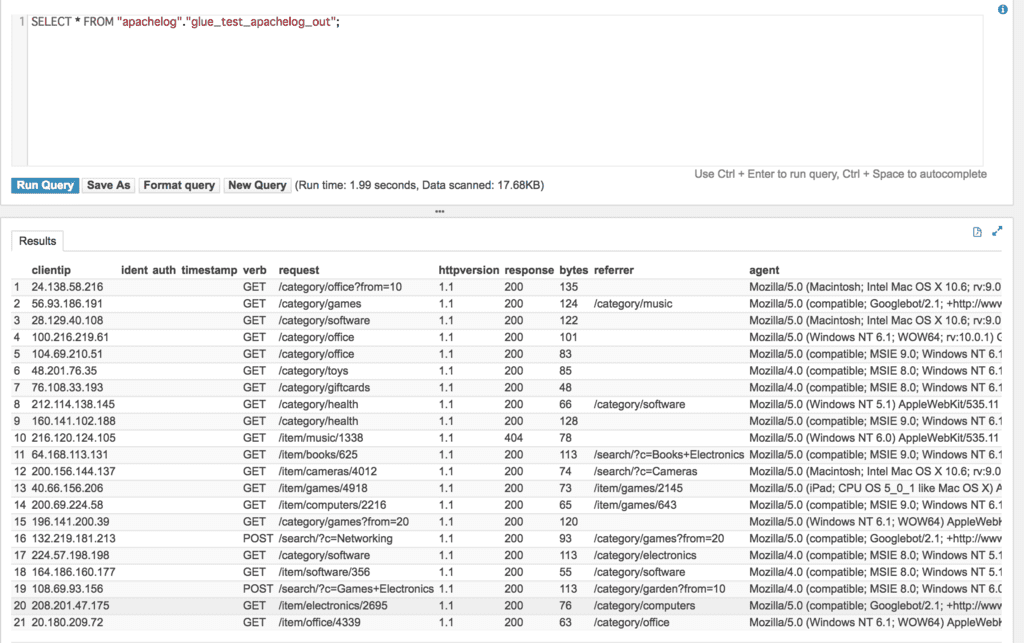
上記Jobが正常終了したら、Athenaから④で確認したの同様のSQLを実行して増分のみ追加されていることを確認してください。Job BookmarkがDisableの場合は、再実行時に全件処理されてしまいます。
もし想定通りの結果とならないようであればJob Bookmarkの設定値を再確認してください。
2つ目のファイルにはアクセスログを11行用意しているので、以下のとおり全部で21行となり増分データのみ追加されました
現状、このJob Bookmarkについては、ソースがS3のときのみ利用可能となっています。
RDSなどのDBの場合については、処理のなかでフィルタする必要があります。
実際にBookmarkを本番で使うには、ジョブがエラーとなった場合などどのようにリトライするかをしっかり想定しておく必要がありそうですね。

