
先日、CloudWatch Eventを確認するとGlueも追加されていたのでジョブの監視をやってみました。
検証構成
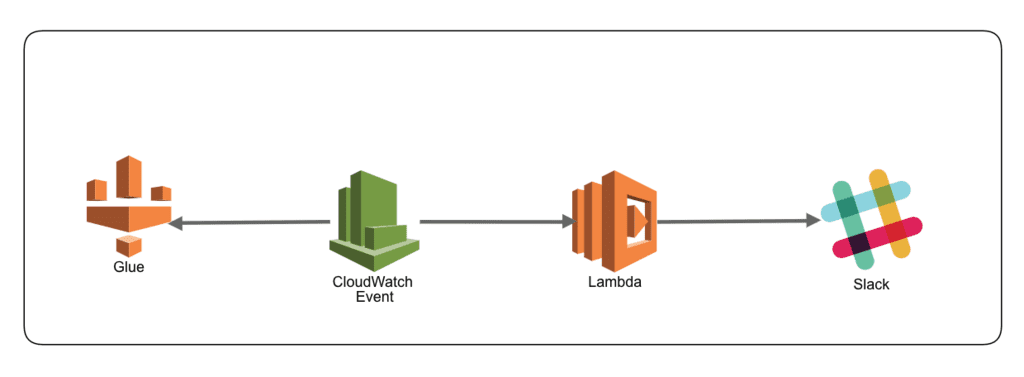
CloudWatch EventでGlueのJobステータスがSucceededもしくはFailedになればSlackに通知しています。
現状、特定ジョブやイベント(Failedのみなど)のみ通知できないので、フィルタをかけれるようにLambdaを利用することにしました。特定イベントのみ通知できるようになればSNSも使えそうです。
今回はLambdaを利用しているので、Slackだけでなく他のAPIを呼び出すなども可能です。
手順
Slack通知用Lambdaの作成
事前にKMSのキーとSlackのチャンネルに通知するためのIncoming Webhookのエンドポイントを作成しておいてください。
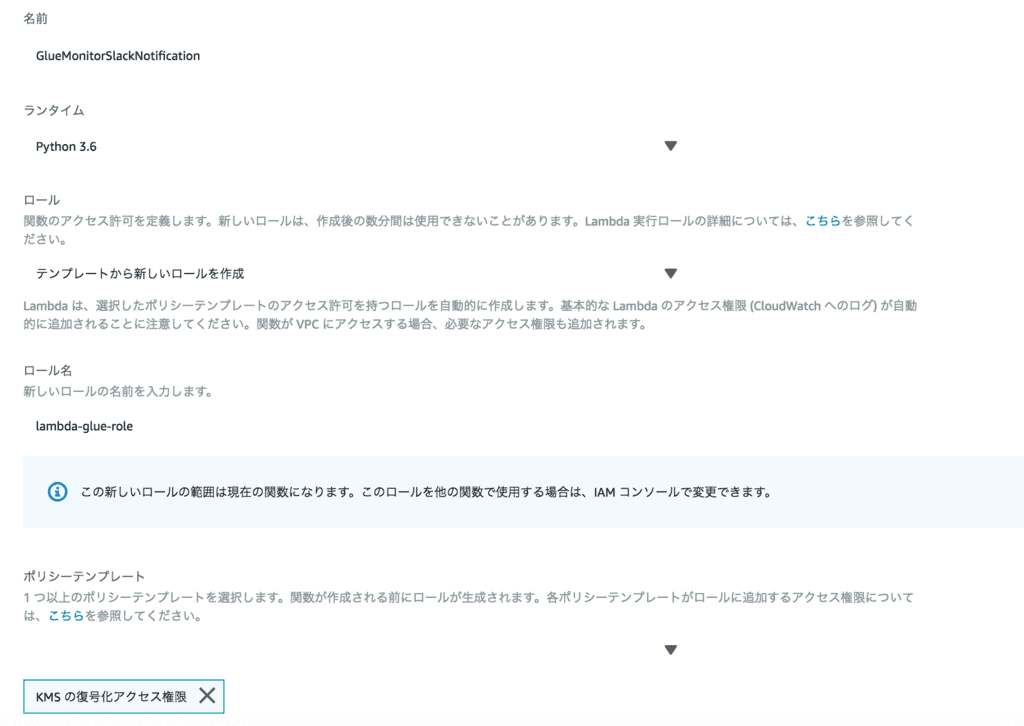
「Lambda」→「関数の作成」をクリックし「一から作成」を選択して以下を入力します。
名前:GlueMonitorSlackNotification
ランタイム:Python3.6
ロール:テンプレートから新しいロールを作成
ロール名:lambda-glue-role
ポリシーテンプレート:KMSの復号化アクセス権限
プログラムは以下に置き換えます。
#coding:utf-8
from __future__ import print_function
import json
import urllib.parse
import boto3
import logging
import os
import sys
from base64 import b64decode
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
logger = logging.getLogger()
logger.setLevel(logging.INFO)
SLACK_CONFIG = {}
def decrypt_environment(encrypt_environment_key):
encrypted_value = os.environ[encrypt_environment_key]
return boto3.client('kms').decrypt(CiphertextBlob=b64decode(encrypted_value))['Plaintext'].decode()
def init():
global SLACK_CONFIG
SLACK_CONFIG = {
"END_POINT": decrypt_environment('SlACK_END_POINT'),
"ICON": ":aws:",
"USERNAME": 'GlueJobBot'
}
def post_message(event):
post_message = {}
post_message["icon_emoji"] = SLACK_CONFIG['ICON']
post_message["username"] = SLACK_CONFIG['USERNAME']
post_message["attachments"]= [0] * 1
post_message["attachments"][0]= {}
post_message["attachments"][0]["fallback"] = 'Glue Jobが実行しました'
post_message["attachments"][0]["color"] = '#36a64f'
if event['detail']['state'] == 'FAILED':
post_message["attachments"][0]["color"] = '#E51616'
post_message["attachments"][0]["pretext"] = ''
post_message["attachments"][0]["author_name"] = ''
post_message["attachments"][0]["author_link"] = ''
post_message["attachments"][0]["title"] = 'Glue Job ' + event['detail']['jobName'] + ":" + event['detail']['state']
post_message["attachments"][0]["text"] = 'JobID:' + event['detail']['jobRunId']
payload_json = json.dumps(post_message)
data = urllib.parse.urlencode({"payload": payload_json})
req = Request(SLACK_CONFIG['END_POINT'], data.encode('utf-8'))
try:
response = urlopen(req)
response.read()
logger.info("Message posted!! %s", post_message["attachments"][0]["title"])
except HTTPError as e:
logger.error("Request failed: %d %s", e.code, e.reason)
except URLError as e:
logger.error("Server connection failed: %s", e.reason)
def lambda_handler(event, context):
init()
post_message(event)
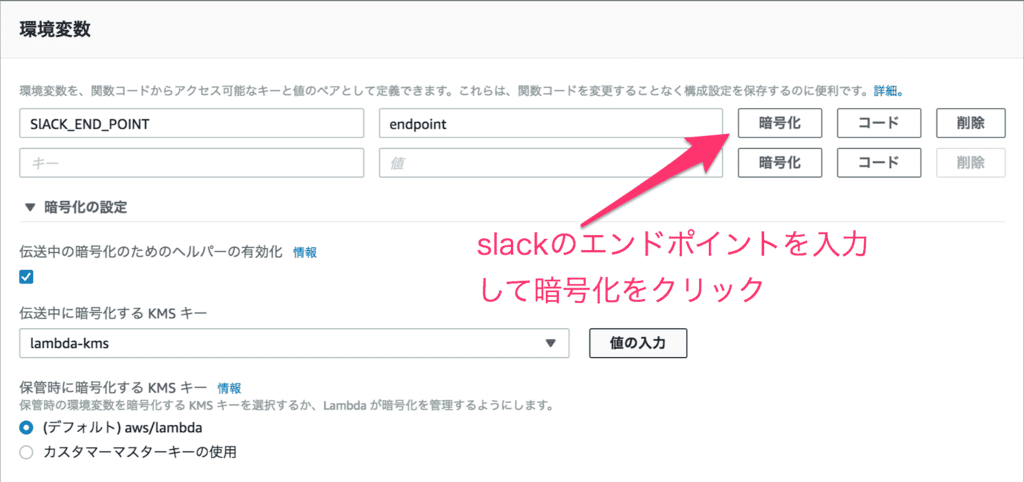
関数を作成後、環境変数にSlACK_END_POINTとIncoming Webhookのエンドポイントを入力します。
「伝送中の暗号化のためのヘルパーの有効化」をチェックし、「伝送中に暗号化する KMS キー」に作成したKMSキーを選択して、環境変数欄にある「暗号化」をクリックします。
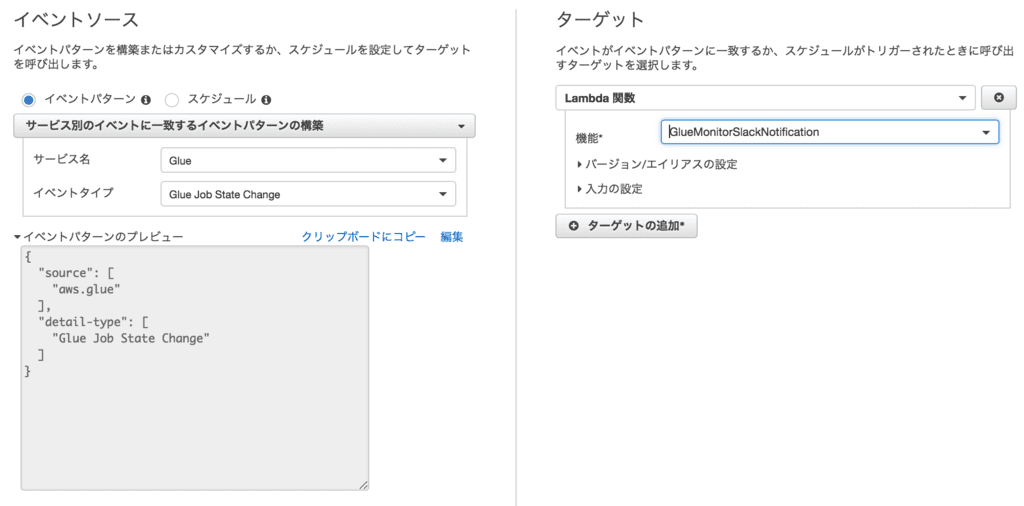
CloudWatch Eventの作成
サービス名:Glue
イベントタイプ:Glue Job State Change
ターゲット:Lambda関数
機能:GlueMonitorSlackNotification ←作成したLambda関数を選択
Glue Jobの作成
作成済みのジョブがあればそれを利用してください。
なければ、左メニュー下のチュートリアルのジョブの追加に従ってジョブを追加してください。
実行確認
準備ができればジョブを実行し、Slackの該当チャンネルに通知されているか確認します。
ジョブが成功した時

ジョブが失敗した時

正しく設定できていれば上記のように通知されるはずです。
現時点でCloudWatch Eventではジョブの指定や失敗時のみなどの細かい設定ができないため、Lambda側でフィルタして通知する必要があります。
これでジョブの成功失敗を監視することができそうです。
Glueのメトリクス
また、Glueにジョブのプロファイリング機能が追加されています。
ジョブのプロファイリング機能を有効にすると以下のメトリクスが取得できます。以下は簡単ですが日本語に訳した内容となります(By Google翻訳)
各メトリクスの詳細については、以下を参照してください。
Monitoring AWS Glue Using CloudWatch Metrics – AWS Glue
これらのメトリクスはジョブの中長期的な処理傾向に問題がないかどうかを確認できると思うので、ジョブの内容に合わせて必要なメトリクスを定期的にモニタリングもしくは監視していけばいいかと思います。
| * メトリクス | * 詳細 |
|---|---|
| glue.driver.aggregate.bytesRead | すべてのエグゼキュータで実行されているすべての完了したSparkタスクによって、すべてのデータソースから読み取られたバイト数。 |
| glue.driver.aggregate.elapsedTime | ETL経過時間(ミリ秒単位)(ジョブのブートストラップ時間は含まれません) |
| glue.driver.aggregate.numCompletedStages | ジョブの完了段階の数 |
| glue.driver.aggregate.numCompletedTasks | ジョブ内で完了したタスクの数 |
| glue.driver.aggregate.numFailedTasks | 失敗したタスクの数 |
| glue.driver.aggregate.numKilledTasks | killされたタスクの数 |
| glue.driver.aggregate.recordsRead | すべてのエグゼキュータで実行されているすべての完了したSparkタスクによって、すべてのデータソースから読み取られたレコードの数 |
| glue.driver.aggregate.shuffleBytesWritten | 以前のレポート(AWS Glue Metrics Dashboardによって集計されたデータで、前の1分間にこの目的で書き込まれたバイト数として集計されたもの)以降、すべてのエグゼキュータがデータをシャッフルするために書き込んだバイト数 |
| glue.driver.aggregate.shuffleLocalBytesRead | 以前のレポート(AWS Glue Metrics Dashboardによって集計されたバイト数)で、すべてのエグゼキュータがそれらの間でデータをシャッフルするために読み込んだバイト数 |
| glue.driver.BlockManager.disk.diskSpaceUsed_MB | すべてのエグゼキュータで使用されるディスク容量のメガバイト数 |
| glue.driver.ExecutorAllocationManager.executors.numberAllExecutors | 実行中のジョブ実行者の数 |
| glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors | 現在の負荷を満たすために必要な最大(実行中のジョブおよび実行中のジョブ)エグゼキュータの数 |
| glue.driver.jvm.heap.usage glue.executorId.jvm.heap.usage glue.ALL.jvm.heap.usage | ドライバ、executorIdによって識別されるエグゼキュータ、またはすべてのエグゼキュータのJVMヒープによって使用されるメモリの割合(スケール:0-1) |
| glue.driver.jvm.heap.used glue.executorId.jvm.heap.used glue.ALL.jvm.heap.used | ドライバのJVMヒープで使用されるメモリバイト数、executorIdによって識別されるエグゼキュータ、またはすべてのエグゼキュータ |
| glue.driver.s3.filesystem.read_bytes glue.executorId.s3.filesystem.read_bytes glue.ALL.s3.filesystem.read_bytes | ドライバによってAmazon S3から読み込まれたバイト数、executorIdによって識別されたエグゼキュータ、または前回のレポート以降のすべてのエグゼキュータ(AWS Glue Metrics Dashboardによって前の1分間に読み取られたバイト数として集計) |
| glue.driver.s3.filesystem.write_bytes glue.executorId.s3.filesystem.write_bytes glue.ALL.s3.filesystem.write_bytes | 以前のレポート(AWS Glue Metrics Dashboardによって前の1分間に書き込まれたバイト数で集計されたもの)以来、ドライバ、ExecutorIdによって識別されたエグゼキュータ、またはすべてのエグゼキュータによってAmazon S3に書き込まれたバイト数 |
| glue.driver.system.cpuSystemLoad glue.executorId.system.cpuSystemLoad glue.ALL.system.cpuSystemLoad | ドライバによって使用されたCPUシステム負荷の割合(スケール:0-1)、executorIdによって識別される実行プログラム、またはすべての実行プログラム |
まとめ
Glueが出た当初は、CloudWatch EventからGlueのステータス変更は取得できなかったと思うので、ステータス取得用のLambdaで別途作る必要がありましたが、CloudWatch Eventから拾えるようになったのでジョブの成功・失敗が拾いやすくなりました。もう少しCloudWatch Event側でジョブやステータスの指定など細かく制御できると失敗のみSNSで通知するなどができるので手軽にできるのですが今後の改善に期待です。
また、CloudWatchメトリクスも提供されましたので、これらも含めてGlueのジョブ監視を行なうことができそうですね。

