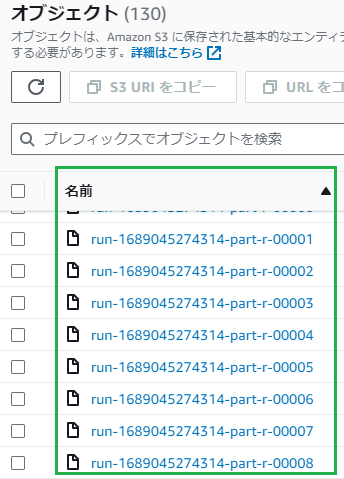
今回はAWS Glue Studioを使用して、RedShiftからデータを取得し、CSVをS3に格納する所までを解説していきたいと思います。
AWS Glue Studioを使用する事で、コードの記述無しにGUIの操作で直感的にジョブを作成する事が出来るので、プログラミング初学者の方でも比較的簡単に進める事が可能です。
新規ジョブ作成
まずGlueのメニューより「Visual ETL」をクリックします。
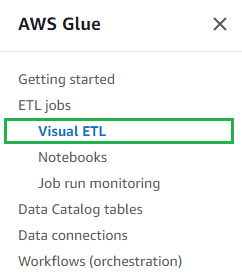
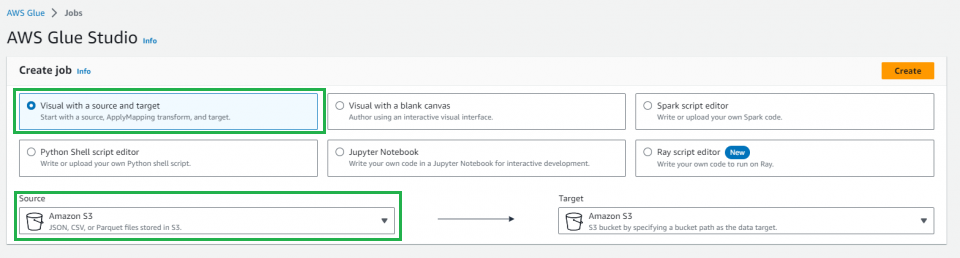
AWS Glue Studioが表示されるので、「Visual with a source and target」を選択します。
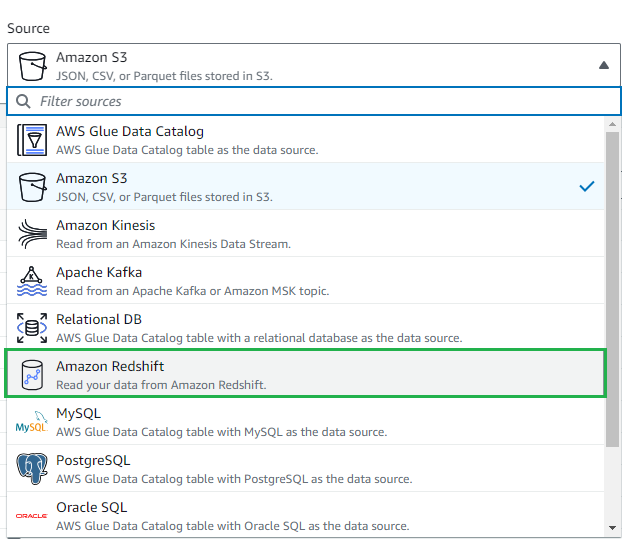
「Source」から今回はAmazon RedShiftを選択します。
「Source」がAmazon RedShift、「Target」がAmazon S3の状態で右上のCreateをクリック
ジョブの設定
新規のジョブが作成されるので、左上の「Untitled job」を変更し、任意のジョブタイトルを設定してください。
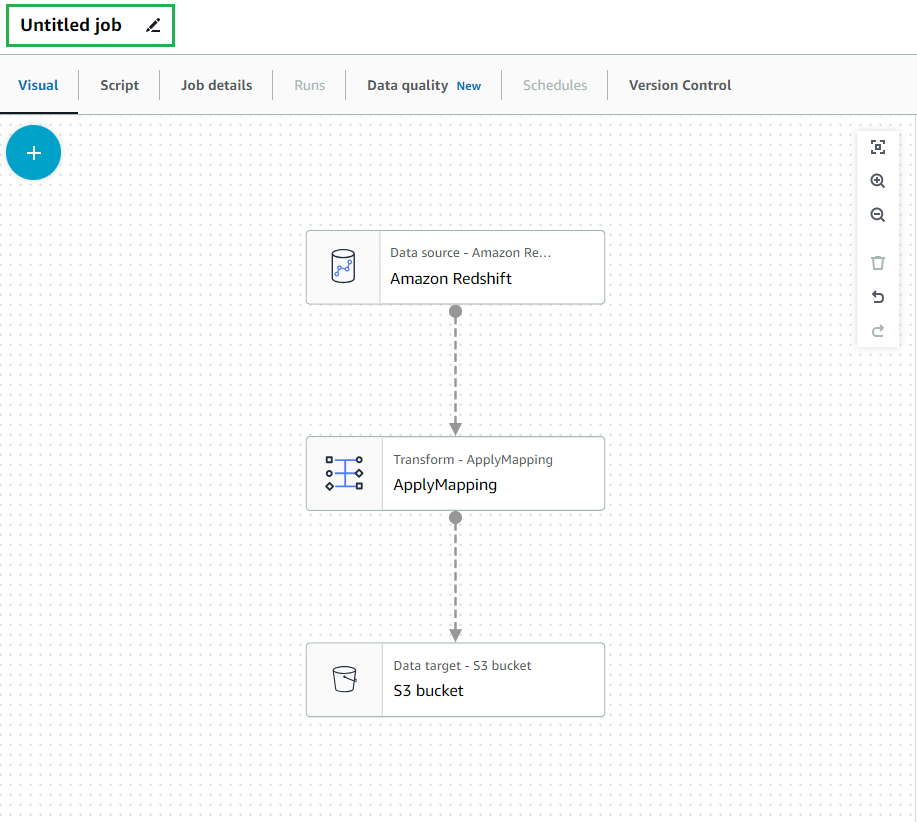
RedShiftの設定
「Redshift access type」はDirect data connection – recommendedを選択、「Redshift source」は今回は一つのテーブルを対象にデータを抽出する為、Coose a single tableを選択し、SchemaとTableで任意のテーブルを指定します。
Enter custom queryを選択する事で自身でクエリを設定する事も可能です。
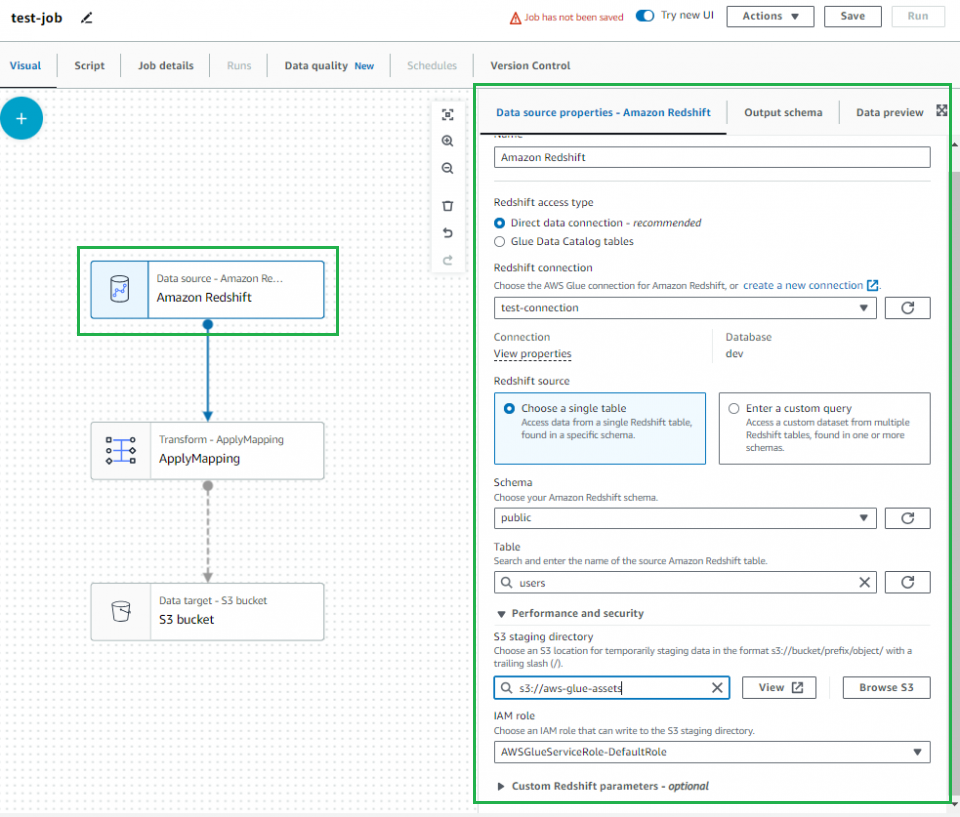
ApplyMappingの設定
「drop」にチェックを入れると任意のカラムをクエリから削除する事が出来ます。
今回は特に変更無しで、チェックを入れずに進めていきます。
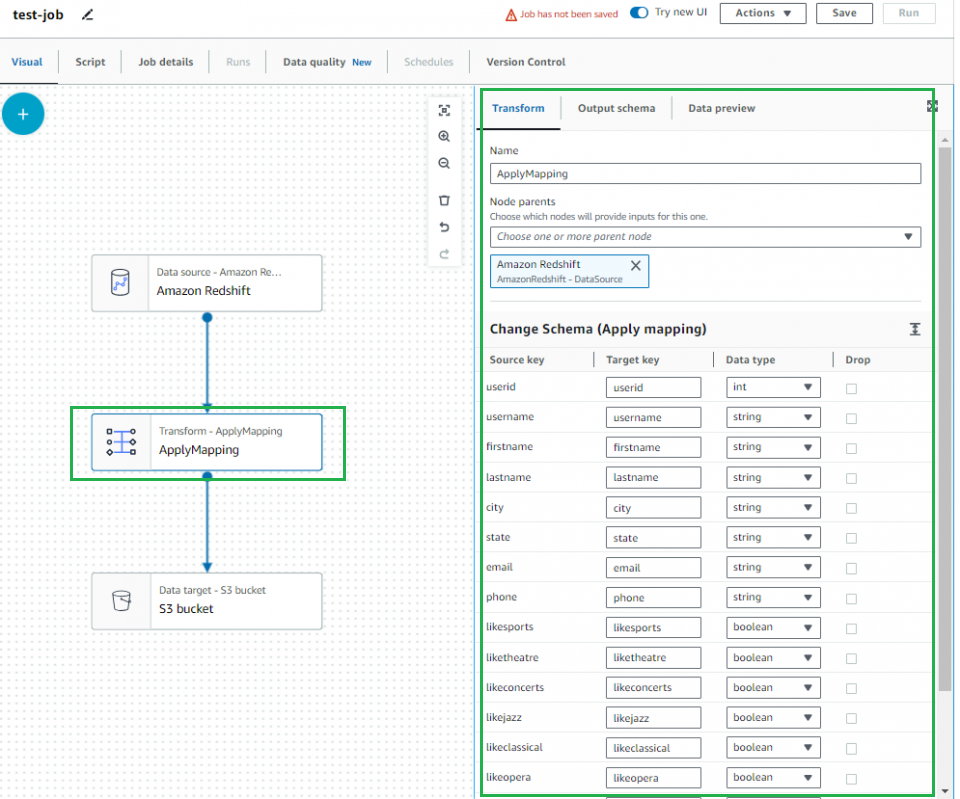
S3の設定
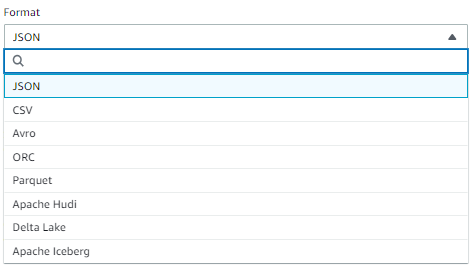
「Format」はCSVを選択し、「S3 Target Location」はCSVを保存したいS3バケットのパスを指定してください。
また今回はCSV形式を選択しましたが、他形式でも出力が可能です。
「Job details」タブを選択し、Glueジョブの実行に必要なIAM Roleを設定します。
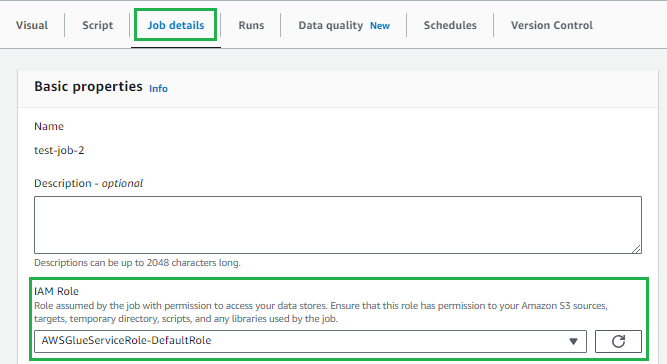
この状態で右上の「Save」ボタンをクリック、ジョブ設定の保存が成功すると以下画像が表示されます
![]()
スクリプト確認
Scriptタブをクリックすると、先ほど設定をした内容で自動生成されたスクリプトを確認する事が出来ます。
デフォルトではLockedとなっており、解除してスクリプトを編集する事も可能ですが、編集を行うと
ビジュアルモードが解除されGUIでGlueジョブが設定出来なくなる為、それを踏まえた上で行ってください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node Amazon Redshift
AmazonRedshift_node1 = glueContext.create_dynamic_frame.from_options(
connection_type="redshift",
connection_options={
"redshiftTmpDir": "s3://glue-test",
"useConnectionProperties": "true",
"aws_iam_role": "arn:aws:iam::123456789012:role/AWSGlueServiceRole-DefaultRole",
"dbtable": "public.users",
"connectionName": "test-connection",
},
transformation_ctx="AmazonRedshift_node1",
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=AmazonRedshift_node1,
mappings=[
("userid", "int", "userid", "int"),
("username", "string", "username", "string"),
("firstname", "string", "firstname", "string"),
("lastname", "string", "lastname", "string"),
("city", "string", "city", "string"),
("state", "string", "state", "string"),
("email", "string", "email", "string"),
("phone", "string", "phone", "string"),
("likesports", "boolean", "likesports", "boolean"),
("liketheatre", "boolean", "liketheatre", "boolean"),
("likeconcerts", "boolean", "likeconcerts", "boolean"),
("likejazz", "boolean", "likejazz", "boolean"),
("likeclassical", "boolean", "likeclassical", "boolean"),
("likeopera", "boolean", "likeopera", "boolean"),
("likerock", "boolean", "likerock", "boolean"),
("likevegas", "boolean", "likevegas", "boolean"),
("likebroadway", "boolean", "likebroadway", "boolean"),
("likemusicals", "boolean", "likemusicals", "boolean"),
],
transformation_ctx="ApplyMapping_node2",
)
# Script generated for node S3 bucket
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="csv",
connection_options={"path": "s3://glue-test", "partitionKeys": []},
transformation_ctx="S3bucket_node3",
)
job.commit()
ジョブの実行
それでは早速右上の「Run」をクリックしてジョブを実行してみましょう。
Successfully started jobと表示されれば正常にジョブが実行されています。
「View details」をクリックするとジョブの詳細を確認する事も出来ます。
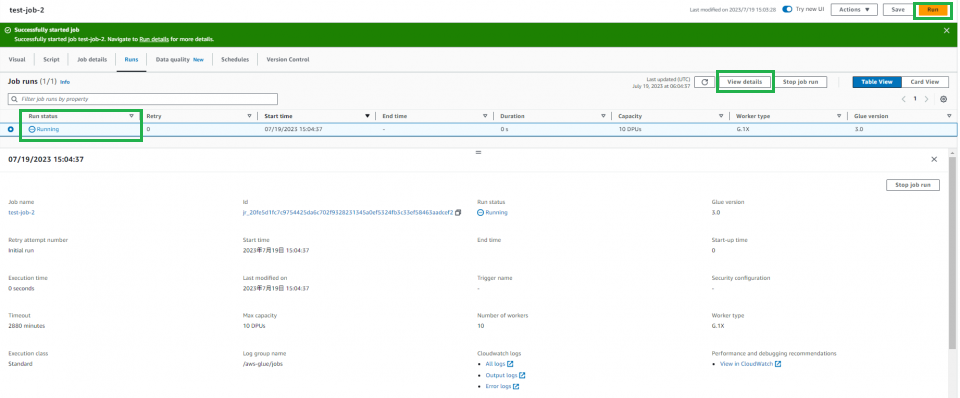
RunStatusがSucceededに変わればジョブが正常終了となります。

最後にS3にアクセスし、データが出力されている事を確認し終了となります。