
はじめに
以前、こちらの記事でAmazon Comprehendの基本的な使い方を試してみました。
その時は分析結果をJSON形式のファイルで出力するまでで終わっていましたが、
このままではどのように活用したらいいのかイメージしづらいので、
今回はQuickSightを使って分析結果を可視化してみました。
概要
以下の流れで、ドキュメントの分析・分析結果の可視化を行いました。
- データ準備(Amazon S3にドキュメントを格納)
- 分析ジョブ実行(Amazon Comprehendの分析ジョブでS3のドキュメントを分析)
- 可視化のためのデータ整形(AWS Glue Data Catalogにロード+Amazon Athenaでデータ整形)
- データの可視化(QuickSightでデータをグラフ化)
※公式のチュートリアルを元にしています。
サンプルとして、ある飲食店の口コミ5件のcsvファイルを作成しました。
(口コミの作成は、ChatGPTにお願いしてみました)
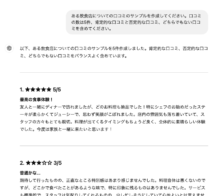
作成したCSVは以下です。
肯定的な口コミが2件、否定的な口コミが2件、どちらでもない口コミが1件という構成になっていました。

やってみた
1. データ準備
S3にバケットを作成し、入出力データを格納するためのinput、outputフォルダを作成します。
inputフォルダに、分析対象のcsvファイルをアップロードします。
2. 分析ジョブ実行
Amazon Comprehendコンソールを開き、左側のメニューから「Analysis jobs」を選択します。
「Create job」をクリックします。
![]()
Name(ジョブの名前)、Analysis type(分析タイプ)、Language(言語)を選択します。
今回は日本語の文章で、感情分析を行うので、Analysis typeは「Sentiment」、Languageは「Japanese」を選択しました。
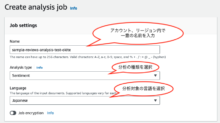
※Analysis type(分析タイプ)で選択できる種類は以下の通りです。
- ビルドイン(標準で用意されている分析タイプ) (※詳細はこちら)
- エンティティ(Entity recognition)
- イベント(Events)
- キーフレーズ(Key phrases)
- 主要言語(Primary language)
- 個人を特定できる情報(PII)
- 感情(Sentiment)
- ターゲット感情(Targeted sentiment)
- トピックのモデリング(Topic modeling)(※詳細はこちら)
- カスタム(ユーザーがカスタマイズできる分析タイプ)
InputとOutputの設定で、分析対象のファイル、入力フォーマット、結果を格納する場所を選択します。
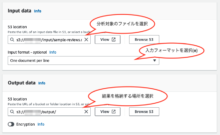
※Input formatは、今回は各行に1つの口コミを記載したファイルなので、「One document per line」を選択します。
新聞記事や論文など、ファイル全体で一つのまとまりになっている場合は、「one document per file」を選択します。(詳細はこちらを参照)
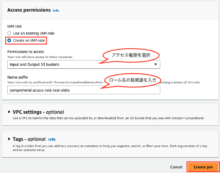
Access permissionsの設定で新たにIAMロールを作成します。
「Create an IAM role」を選択し、アクセス権限では「Input and Output S3 buckets」を選択し、
Name suffixにはロールの接尾語を入力します。
(※作成済みのロールがある場合は、Use an existin IAM roleを選択して既存のロールを選択します。)
その後、「Create job」をクリックします。
Statusが「Completed」になるまで待ちます。
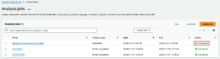
ジョブの名前をクリックして詳細画面を開き、Output data locationのリンクをクリックします。
S3の出力結果ファイルの詳細画面に遷移するので、「ダウンロード」をクリックします。
![]()
「output.tar.gz」という名前でダウンロードされるので、解凍&わかりやすい名前に変更しておきます。
(複数のジョブを実行した場合、全て同じファイル名で出力されるため、ファイル名を変えておく方が無難です)
今回は「sentiment-output」にしました。
![]()
S3に解凍後のファイル格納用のフォルダを作成し、アップロードします。
今回は「sentiment-results」という名前のフォルダを作成し、その中に「sentiment-output」をアップロードしました。
3. 可視化のためのデータ整形
3-1. AWS Glue Data Catalogにロード
AWS Glueの画面を開き、メニューから「Crawlers」を開きます。
「Create crawer」をクリックします。
![]()
クローラー名を入力して「Next」をクリックします。
「Add a data source」をクリックします。
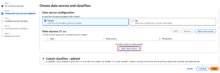
データソース追加の画面が表示されますので、以下のように入力して「Add an S3 data source」をクリックします。
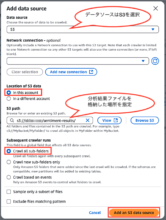
一覧にデータソースが追加されます。「Next」をクリックします。
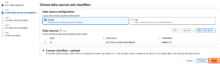
「Create new IAM role」をクリックします。
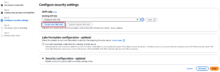
以下のようなダイアログが表示されるので、IAMロール名を入力し、「Create」をクリックします。
(デフォルトでプレフィクス AWSGlueServiceRole- が入力された状態になっており、削除できないようになっています。)
作成したIAMロールが選択された状態になりますので、「Next」をクリックします。
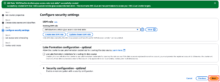
「Add database」をクリックします。
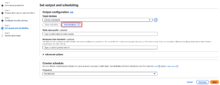
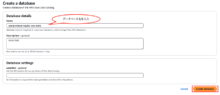
別タブで、データベース作成画面(Create a database)が開きます。
データベース名を入力し、「Create database」をクリックします。
元の画面(Glueのクローラー作成の画面)で、作成したDBを選択します。
クローラースケジュールは「On demand」を選択します。「Next」をクリックします。
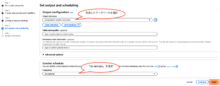
入力した内容が表示されます。内容を確認し、「Create crawler」をクリックします。
クローラー作成が成功したメッセージが表示されます。
![]()
「Run crawler」をクリックします。
![]()
クローラーが実行されるので、数分待ちます。
以下のように、StatusがCompletedになります。これで、分析結果がDBに保存されました。
![]()
3-2. Amazon Athenaでデータ整形
DBに保存された結果はネストされた状態になっているので、Athenaでネストを解除し、QuickSightで読み取れるようにします。
Athenaの画面に遷移し、「クエリエディタ」をクリックします。

設定タブを開き、「管理」をクリックします。
![]()
クエリ結果の場所に、結果を格納したいバケット+任意のフォルダ名(query-results/)を入力し、
「保存」をクリックします。
エディタタブを開き、データベースのプルダウンで先ほどGlueで作成したデータベースを選択し、
テーブル名横のメニューから「テーブルをプレビュー」をクリックします。
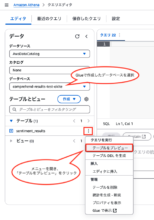
クエリ結果にて、データがあることが確認できます。
このままでは「sentimentscore」がネストされているため、ネストを解除します。
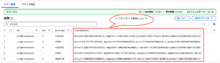
以下のクエリを実行します。
CREATE TABLE sentiment_results_final AS SELECT file, line, sentiment, sentimentscore.mixed AS mixed, sentimentscore.negative AS negative, sentimentscore.neutral AS neutral, sentimentscore.positive AS positive FROM sentiment_results
「sentiment_results_final」テーブルが作成されます。
同様にプレビューを見てみると、以下のようにネストが解除されていることがわかります。
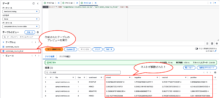
最終的なデータは以下のようになりました。口コミごとに感情分析結果の割合が出力されています。
こちらをグラフ化していきます。
![]()
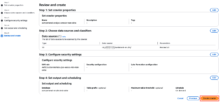
4. データの可視化
Amazon QuickSightでデータを読み取り、グラフを作成していきます。
QuickSightを初めて使用する場合、セットアップが必要になります。
以下のようにメールアドレスの記入、リージョン選択、アカウント名の入力を行います。
オプションのアドオンについては、今回は使用しないので外しておきます。
(デフォルトでONになっているので、注意してください)
「完了」をクリックします。

セットアップ完了画面になりますので、「QUICKSIGHTに移動する」をクリックします。
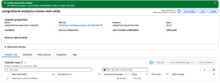
右上のユーザーアイコンをクリックしてメニューを開き、「QuickSightを管理」を開きます。
「セキュリティとアクセス許可」を開き、「管理」をクリックします。
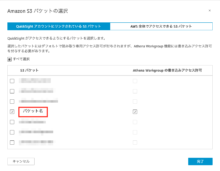
Amazon S3とAthenaにチェックを入れます。
バケットの選択画面で対象のバケットにもチェックをいれ、「完了」をクリックします。
(「Athena Workgroup の書き込みアクセス許可」もONにします)
データセットメニューから、「新しいデータセット」をクリックします。
「Athena」をクリックします。
![]()
データソース名を入力し、「データソースを作成」をクリックします。
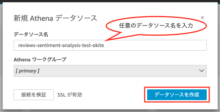
データベース、テーブル(ネスト解消した方)を選択し、「選択」をクリックします。
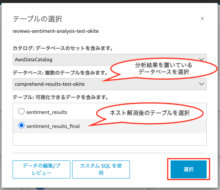
「Visualize」をクリックします。
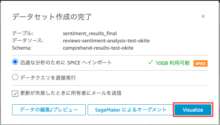
以下のような画面に遷移します。
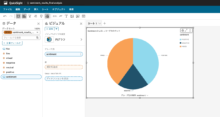
データのところで「sentiment」を選択し、ビジュアルで円グラフのマークを選択します。
感情分析の結果(肯定的、否定的、どちらも含む)の割合を表す円グラフが生成されました。
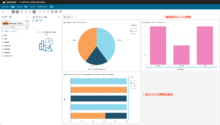
ビジュアルの「追加」ボタンで、他にもいろいろなグラフを追加できます。
以下の例では、感情別の口コミ件数の棒グラフ、各口コミの感情の割合を表す棒グラフを追加してみました。
失敗談
うまくいかなかった部分についても記載します。同じような事象が発生した方の助けになればと思います。
失敗①:Athenaでテーブルのプレビューを行った時、データが1件も表示されなかった
Glueで作成したデータベースのテーブル(sentiment_results)のプレビューを実行した際、
クエリ結果でデータが1件も表示されませんでした。
![]()
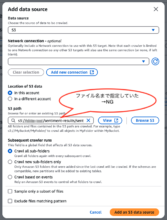
原因は、Glueのクローラー作成時、データソースの追加画面で、S3パスのところにファイル名まで指定していたことでした。
ファイルが格納されているフォルダ名までの指定に直すと、無事プレビューでデータが表示されました。
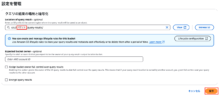
失敗②:QuickSightでグラフを表示させようとした時、データのインポートがエラーになった
QuickSightでデータセットを作成し、「Visualize」をクリックした後にグラフを表示しようとしても、
以下のようにデータが取り込めないという表示になりました。
Athenaで結果を格納する場所のバケットと、QuickSightでアクセス許可したバケットが異なっていたためでした。
Athenaの結果の場所設定:
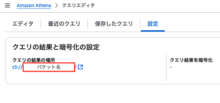
QuickSightのS3バケットへのアクセス許可設定:
まとめ・感想
- 複数の口コミについて、肯定的な意見が多いのか否定的な意見が多いのかを把握するだけなら、比較的簡単にできるなと感じました。
- Amazon Comprehendの出力結果はJSON形式で数値が表示されるだけなので、
そのままでは活用するのが難しいですが、グラフ化することで一気に活用しやすくなったと思います。 - 今回は感情分析のみでしたが、エンティティ抽出でどのようなアイテムが言及されているかを確認したり、
ターゲット感情分析で各エンティティに対する感情を分析するなど、いろいろな活用方法があると思いました。
(例えば、否定的な感情が多い商品を調べて、改善に繋げるなど。)

