概要
QuickSight案件の導入として基本的な使い方をまとめました
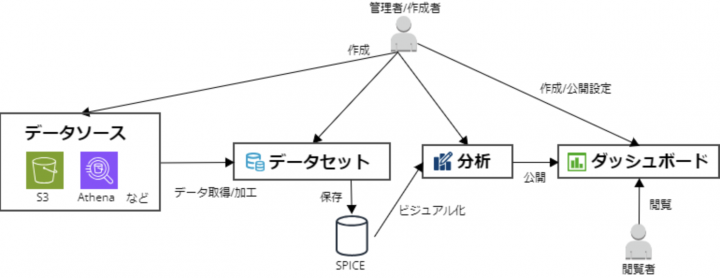
用語
| 用語 | 説明 |
|---|---|
| データソース | 分析対象となる外部のデータおよびデータにアクセスするための接続情報 |
| データセット | 分析を行うための基となるデータの集まり データソースを加工して作成する |
| SPICE | データセットの内容を保存する領域。高速なアクセスが可能 ※SPICEに保存しない設定も可能 |
| 分析 | データセットに対して分析や視覚化の定義を行ったもの |
| ダッシュボード | 分析を公開設定したもの。閲覧者が参照できるようになる |
| 管理者 | QuickSightユーザーのロール。分析の作成やQuickSight全体の設定が実施できる |
| 作成者 | QuickSigthユーザーのロール。分析の作成が実施できる |
| 閲覧者 | QuickSIghtユーザーのロール。ダッシュボードの閲覧のみ可能となる |
各要素の関連イメージ
使い方
案件で行っているAthenaをデータソースにした分析の作成方法を記載する
分析対象はAWSのチュートリアルを参考にする
ユーザー作成
方法はいろいろあるがQuickSightアカウント作成済みのAWSアカウントでIAMからサインアップする場合はマネジメントコンソールログイン後QuickSightのサービスを選択
その後メールアドレス入力が求められるので入力するとユーザー作成される
データソース作成
事前にS3に分析対象のCSVデータを格納し、Athenaでテーブル定義を作成しておく
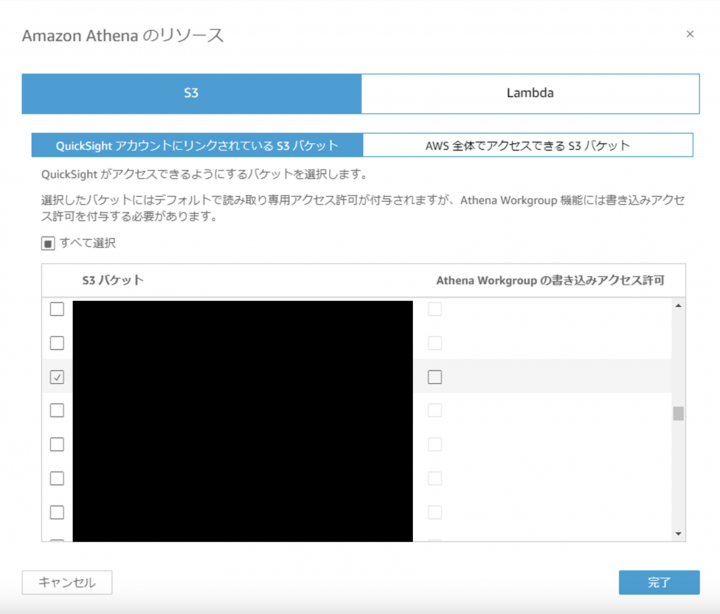
(※初回のみ)QuickSightの管理メニューで「セキュリティとアクセス権限」の「管理」をクリック

(※初回のみ)Athenaにチェックを入れると許可するS3バケットを聞かれるので対象のバケットを指定して完了
QuickSightのデータセット画面から「新しいデータセット」をクリック
![]()
新規データソースから「Athena」を選択

データソース名とAthenaワークグループを指定して「データソースを作成」

ここまででデータソースは作成される。引き続きデータセット作成の画面が表示される。
※作成したデータソースは「データセットを作成」の「既存のデータソースから」で確認できる。2回目以降は既存のデータソースから作成する。

データセット作成
今回はAthenaのクエリ実行結果に対して分析を行いたいため、「カスタムSQLを使用」を選択する
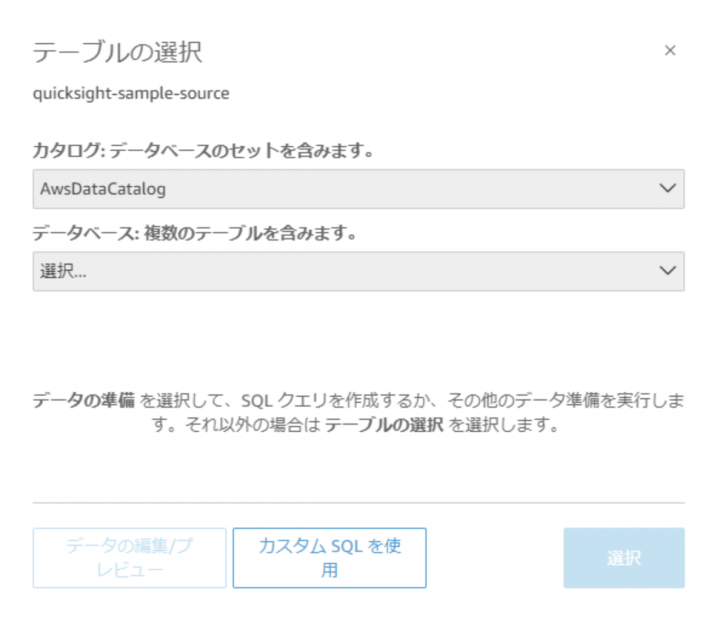
「データの編集/プレビュー」でデータセットの編集画面を開く
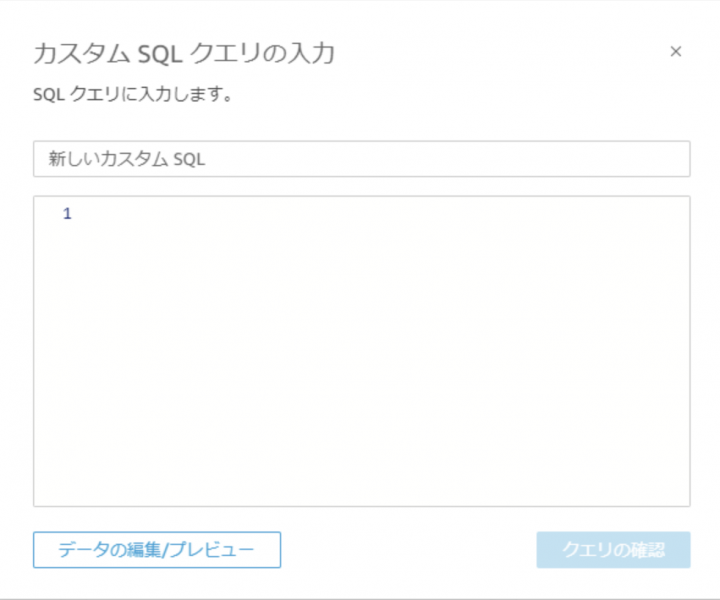
データセット名/カスタムSQL名/カスタムSQLを入力、クエリモードに「SPICE」を選択して「適用」をクリック
簡単な計算はQuickSight上でもできるため、単一テーブルだとAthenaを使う意義は少ないが、複数のテーブルをまとめて一つの分析対象を作りたい場合はAthenaは有用
また、SPICEに格納するデータ量を削減するために必要な情報のみに絞り込む用途も考えられる

画面下部にプレビューが表示されるため、問題ないことを確認して「保存して公開」をクリック

分析作成
分析画面で「新しい分析」をクリック
![]()
対象のデータセットを選択
「分析で使用」をクリック

データセットに対象のデータセットが選択されていることを確認してビジュアルから追加したい視覚化のフォーマットを選択
今回は折れ線グラフを選択
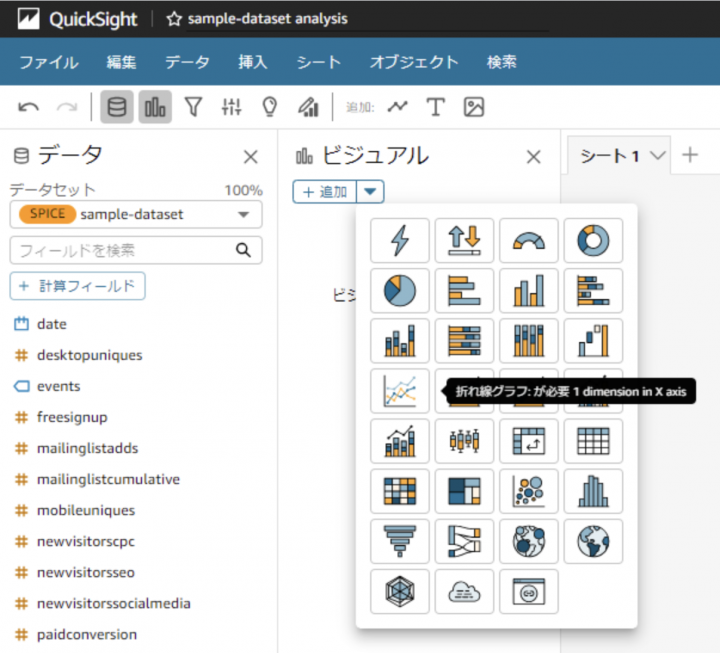
選択すると以下のような空のフォーマットが生成される
X軸や値に分析対象としたいデータセット上の値を設定する
ディメンション:データをグループ化して分析する際、グループ化の指標となる属性
測定:データをグループ化して分析する際、グループ化の計算対象となる属性

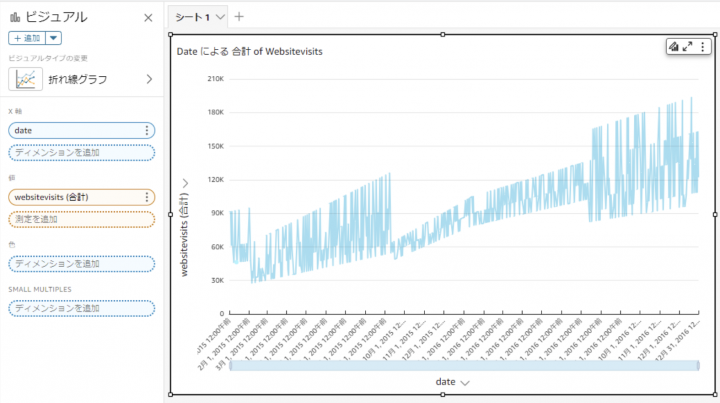
X軸にdate、値にwebsitevisitsを選択すると以下のような日付別の折れ線グラフとなる
分析は作成時に自動保存される。以降も変更を行った際に随時自動保存される
自動保存したくない場合は設定を変更する
ダッシュボード作成
分析の右上の「公開」をクリック
![]()
ダッシュボード名を設定して「ダッシュボードの公開」で作成される

デフォルトでは所有者しか閲覧できないため、「ダッシュボードの共有」から共有先を設定する

※データソース、データセット、分析も最初は所有者しか閲覧権限が無いため、複数ユーザーで共有したい場合は共有設定が必要
その他
以下もまとめたい
- データセットの増分更新
- データセットの行レベルのセキュリティ設定
- 分析の設定いろいろ
以上

