
はじめに
今回は、以前から興味があったAWSの機械学習サービスに触れてみようと思い、
各機械学習サービスの中でも比較的ハードルが低そう(※個人的イメージです)なAmazon Comprehendの使い方を調査し、試してみました。
Amazon Comprehendを使ったことがない方向けの内容になります。
概要
- Amazon Comprehendは、自然言語処理を使用して、ドキュメントの内容に関するインサイトを抽出します。
ドキュメント内のエンティティ、キーフレーズ、言語、感情などの要素を認識することでインサイトを作ります。
※インサイトの種類についてはこちらを参照。 - Amazon Comprehend コンソールまたは Amazon Comprehend APIを使用して分析機能にアクセスできます。
※今回はコンソールでの操作のみ紹介します。 - テキストの文字数に応じて課金されます。
※料金については、こちらを参照。 - 主なユースケースは以下。
- 顧客アンケートや商品への口コミの内容を分析し、商品の改善を行う
- 法的文書の内容を分析してレビューを行う
※導入事例はこちらに載っていますので、興味のある方はぜひ覗いてみてください。
使ってみる
基本の使い方として、以下の2つの方法があります。
- リアルタイム分析(テキストをAmazon Comprehend コンソールに直接入力して分析を行う)
- 分析ジョブ(S3にドキュメントを格納して、ドキュメント内のテキストに対して分析を行う)
それぞれの手順について紹介します。
リアルタイム分析
まずは簡単そうなリアルタイム分析の方法から。
- コンソール画面にサインインし、検索ボックスでAmazon Comprehendを検索して開きます。
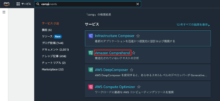
- Amazon Comprehendの画面に遷移したら、左メニューから「Real-time analysis」を選択します。

- リアルタイム分析の画面が開きます。
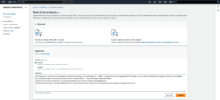
- Input dataのAnalysis typeで「Built-in」を選択します。
Input textに初期値のテキストが入っているので、「Clear text」でテキストボックスをクリアします。
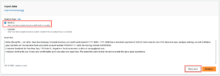
- Input textに分析したい文章を入力し、「Analyze」をクリックします。

- Insightsに分析結果が表示されます。
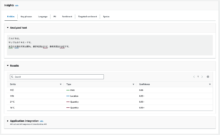
分析結果の各タブの内容を見ていきます。
Entities
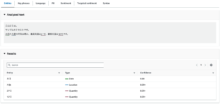
テキストで検出された各エンティティと、そのタイプと信頼度が一覧で表示されます。
(※エンティティについてはこちらを参照。)
以下のように、検出されたエンティティにはラインが引かれていますが、エンティティのタイプ(人物、場所など)によって、色分けされています。
![]()
Key phrases
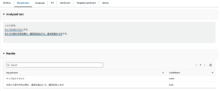
テキスト内のキーフレーズ(名詞句を含む文字列)が抽出され、一覧で表示されます。
(※キーフレーズについてはこちらを参照。)
Language
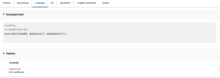
テキストの主要な言語を判断します。
今回は日本語の文章なので、結果は「Japanese」(信頼度0.95)になっています。
PII
個人を特定できる情報を検出します。
ですが、今回の結果では以下のように表示されました。
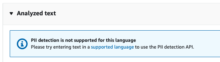
言語が対応していないとのことです・・・。
PIIエンティティの検出は、現在、英語とスペイン語のみの対応のようで、
残念ながら日本語はサポート外でした・・・(2024年11月時点)
(※各機能の対応言語についてはこちらを参照)
初期値で入力されていたサンプルの文章は英語なので、そちらで試すと以下のような結果になりました。
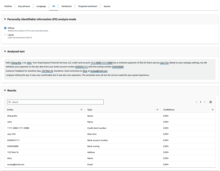
Personally identifiable information (PII) analysis modeという設定がありますが、
デフォルトでのOffsetsの場合は、↑のように文中のPIIの位置が特定されます。
Labelsを選択すると、以下のように特定されたPIIエンティティタイプのラベルが表示されます。
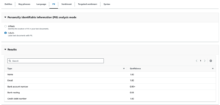
例えば、検出されたPIIエンティティが名前なら”NAME”、住所なら”ADDRESS”といったラベルが返されます。
(※エンティティタイプについてはこちらを参照)
Sentiment
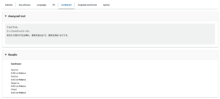
テキストの内容から感情を判別します。
感情の種類は、
・Positive(肯定的)
・Negative(否定的)
・Mixed(肯定的と否定的の両方)
・Neutral(肯定的と否定的のどちらでもない)
の4つです。
今回はただの天気についての文章なので、Neutralの信頼度が0.99という結果になりました。
試しにポジティブな一文を追加してみると、Positiveの数値が一気に上がりました。
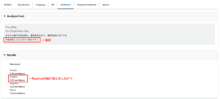
Targeted sentiment
Sentimentではテキスト全体の主要な感情を表していましたが、
Targeted sentimentでは、テキストで言及されているエンティティに対しての感情を判別します。
こちらの機能も現時点では日本語は未対応でしたので、サンプルの英語文で試しています。
以下のように単語をクリックすると、その単語についての情報が表示されます。
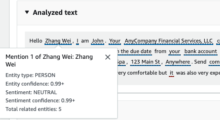
また、文章内ででてくる「your」が「Zhang Wei」と同一であることも認識され、
以下のように関連づけた結果として表示されます。
Syntax
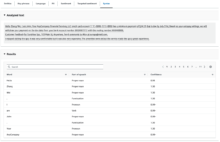
テキスト内の単語の品詞を判別し、その信頼度と共に表示します。
こちらも日本語はサポート外でしたので、英語で試しました。
分析ジョブ
続いて、S3にドキュメントを置いて分析する方法です。
- S3にバケットを作成し、サンプルデータを格納します。
今回は、AWS公式サイトのチュートリアル用に用意されたファイルを使用しました。
※サンプルデータはこちらからダウンロードできます。
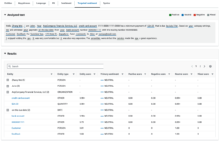
- Amazon Comprehendの左側メニューから、「Analysis jobs」を開き、「Create job」をクリックします。
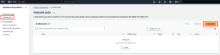
- ジョブの名前、分析タイプ、言語を選択します。
※今回はエンティティの検出を行うため、分析タイプは「Entity recognition」を選択しました。
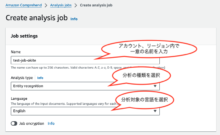
- 入力データ、出力データを設定します。
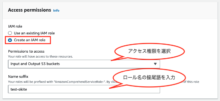
- アクセス許可で、新たにIAMロールを作成します。
「Create an IAM role」を選択し、Permissions to accessを「Input and Output S3 buckets」に設定、
Name Suffixには、作成されるロールの接尾語を入力します。
以下の場合、ロール名は「AmazonComprehendServiceRole-test-okite」になります。
※作成したロールのポリシーの内容は以下のようになります。
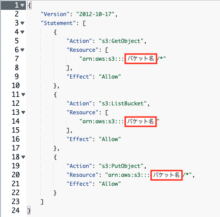
Permissions to accessで「Any S3 bucket」を選択した場合は
以下のようなS3のすべてのバケットへのアクセス権限を持つロールが作成されます。

- 「Create job」をクリックします。
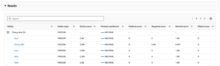
- 以下のようにジョブが一覧に追加されます。
初めは、ステータスが「In Progress」になります。

- しばらく待つと、「Complete」になります。

- ジョブ名をクリックして詳細画面を開き、outputのリンクをクリックします。
- ファイルの詳細画面が開くので、ダウンロードをクリックします。
- 以下のように、JSON形式で分析結果のファイルがダウンロードされます。
今回は分析タイプをエンティティ検出にしたので、
テキストで検出されたエンティティの文字列・タイプ・位置などが出力されました。

感想
- リアルタイム分析はとても簡単にできたので、まずはこちらから試してみるといいかと思います。
- 活用例として、セミナー参加者のアンケート結果を分析したり、商品やお店の口コミを分析するなど、
いろいろ考えられるなと思いました。 - 分析ジョブの手順は、今回は結果を出力するまででしたが、この結果を元にQuickSightを使って可視化することもできます。
可視化の方法についても今後試してみたいと思います。 - まだ日本語が対応されていない機能もありますが、これからのアップデートで対応されることを期待したいと思います!


