
streampack の Tana です。
概要
今回は Athena によるログ解析です。
動画を扱っていると、CDN(CloudFrontなど)で配信するので CloudFront のログから再生状況を確認することがたまにあります。
ローカルに s3 からアーカイブされたログをダウンロードして grep, sort, uniq してやるのも楽ではありますが、みにくく解析しにくい時があります。
その際に AWS Athena を使うとSQLクエリで条件を絞ったり、ソートしたりできるので便利です。
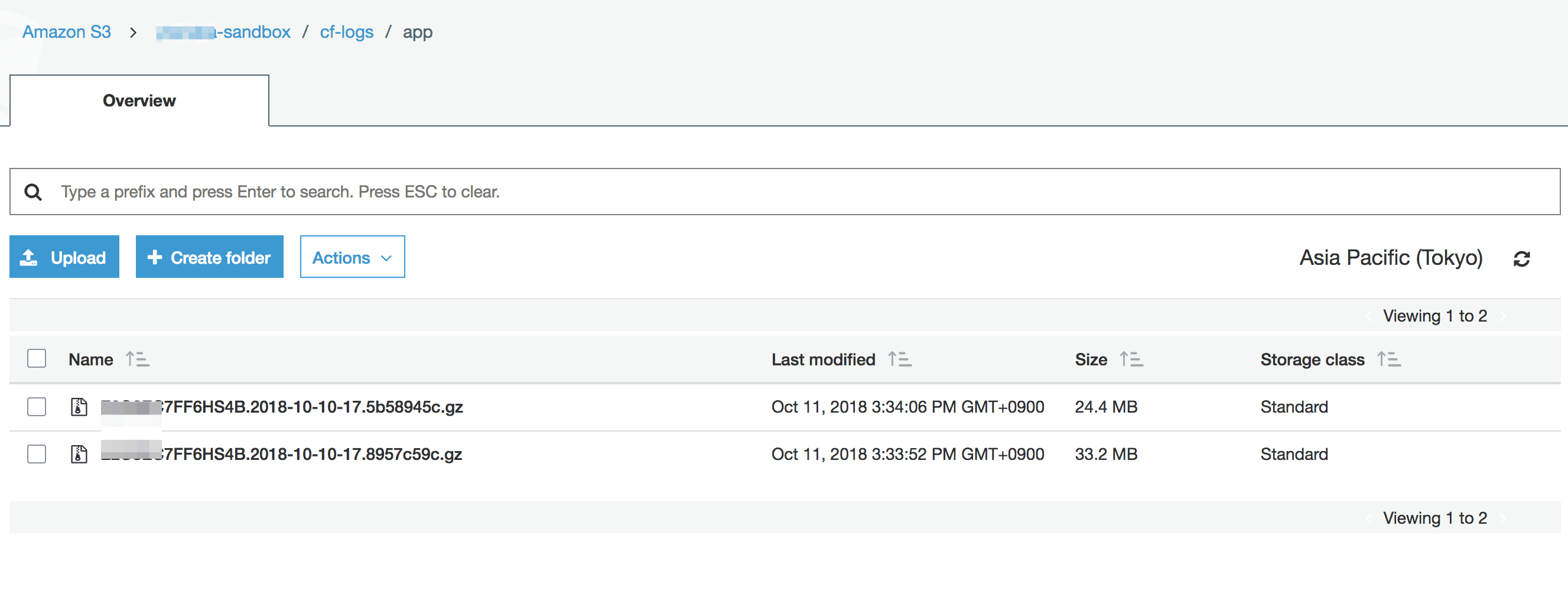
S3 に CloudFront のログ置く
Athena にてテーブルを作成
今回はすでに準備している下記のクエリからテーブルを作成します。
- テーブル名: app_log
- s3 bucket & path: s3://xxxxxx-sandbox/cf-logs/app
https://ap-northeast-1.console.aws.amazon.com/athena/home?force®ion=ap-northeast-1#query
下記のクエリを Query Editor にてセットし、”Run query” を実行します。
CREATE EXTERNAL TABLE `app_log`(
`request_date` string,
`request_time` string,
`x_edge_location` string,
`sc_bytes` int,
`client_ip` string,
`cs_method` string,
`cs_host` string,
`cs_uri_stem` string,
`sc_status` string,
`cs_referer` string,
`user_agent` string,
`uri_query` string,
`cookie` string,
`x_edge_result_type` string,
`x_edge_request_id` string,
`x_host_header` string,
`cs_protocol` string,
`cs_bytes` int,
`time_taken` decimal(8,3),
`x_forwarded_for` string,
`ssl_protocol` string,
`ssl_cipher` string,
`x_edge_response_result_type` string,
`cs_protocol_version` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '\t',
'input.regex' = '\t'
)
LOCATION
's3://xxxxxx-sandbox/cf-logs/app'
TBLPROPERTIES (
'has_encrypted_data'='false')
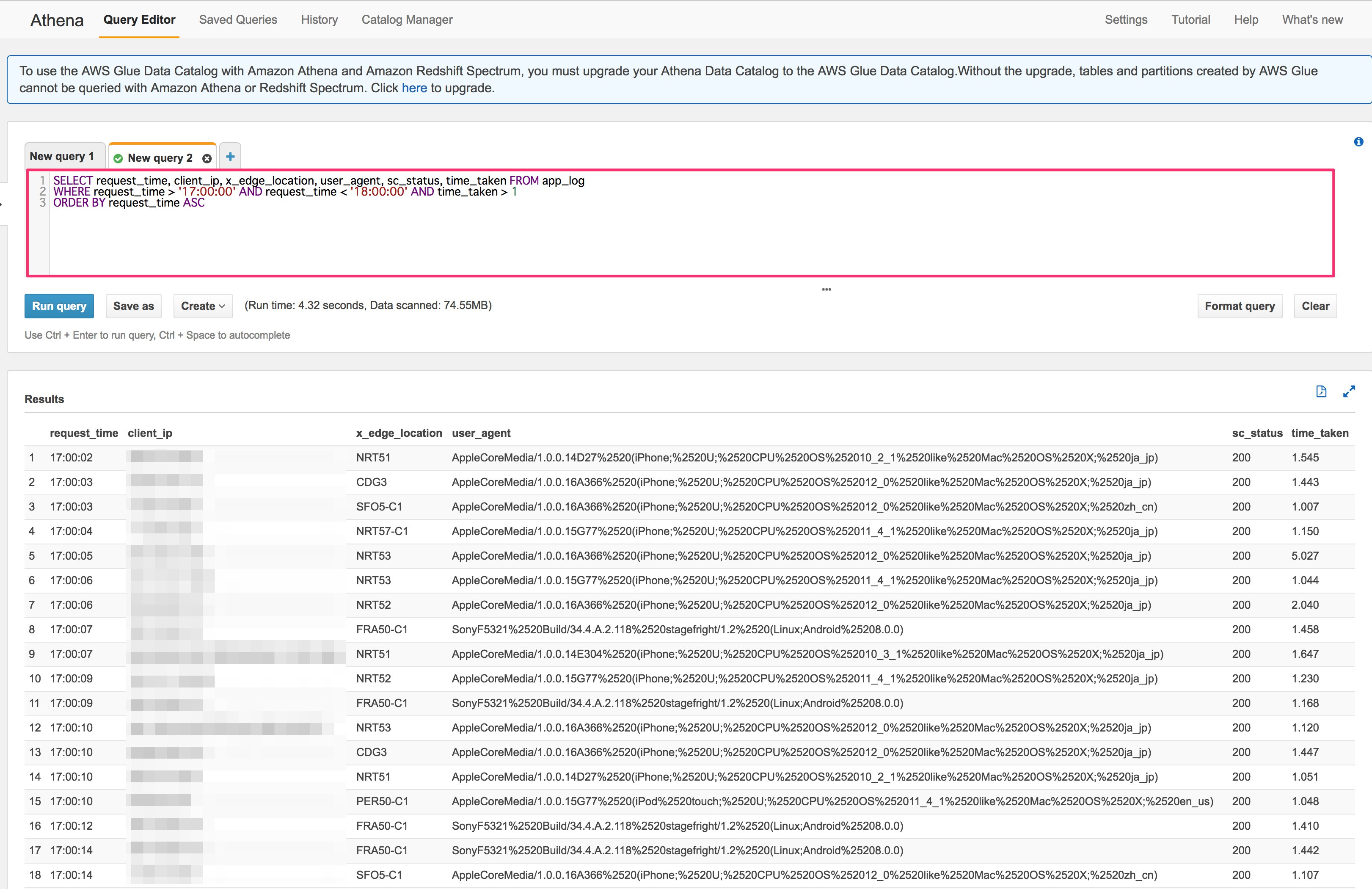
クエリを投げる
シンプルに取得するなら、下記の SQL を実行します。
SELECT * FROM app_log;
フィルターや順序を変更したい場合はSQLと同様なクエリを実行するだけです。
WHERE request_time >= '17:00:00' AND request_time < '18:00:00' AND time_taken > 1 # 1秒以上のレスポンスでかかったもの AND sc_status = '200' # 200 のもの ORDER BY request_time ASC # 処理時間順に表示 LIMIT 10 # 10件のみ
おまけ
AWS-CLI でも生成したり取得したりできるので、オペレーション的には便利そうです。(下記は取得だけ)
$ aws athena get-query-results –query-execution-id xxxxxxxxxx –output table
終わり
実戦で使うようにするには、パーティション設計が必要です。さもなければ、フルスキャンすることになるのでコスト増や時間がよりかかります。Lmabda などで出力されるログにてs3のパスをyear=YYYY/month=mm/day=dd/ などの日付ごとに分割するようにし、対象日付のものだけスキャンするような仕掛けが必要そうです。(まだやれてないですが。。)
