
こんにちはアイレット後藤です。先日の AWS Summit 備忘録に引き続き、Google Cloud Day で印象に残った話題を備忘録としてまとめておこうと思います。
とりあえず基調講演はスキップし、ライブで見たブレイクアウトセッションで気になったところを書き出します。選んだセッションが偏っているのかもしれないですが、めちゃくちゃサービス使いたおしているユーザー企業が多くて驚きました。早速いってみましょう。
【Mobility Technologies社】AI を用いたタクシー配車における BigQuery 徹底活用術
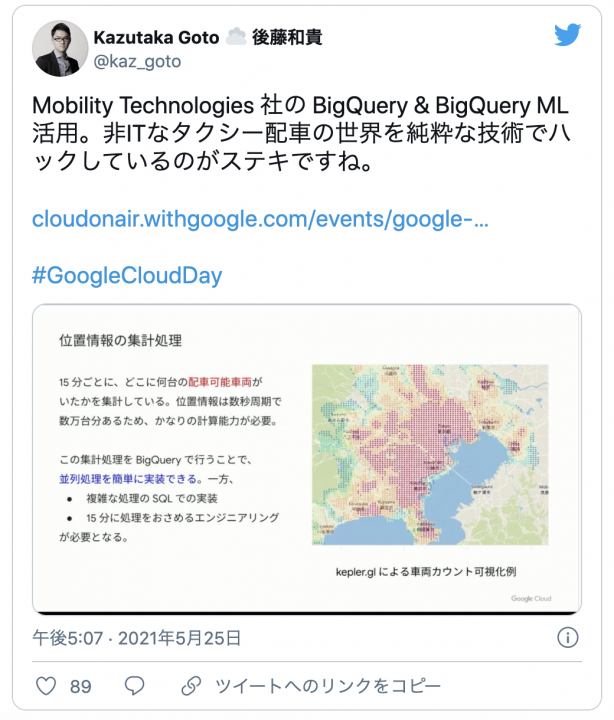
タクシーアプリ GO で BigQuery を利用しているのですが、まず数万車タクシー位置から予約への配車、最適な配車のためのAI学習・推論処理に力を注いでいます。
サービス全体として、15分ごとにどこへ何台配車可能か集計処理と予測が必要になる側面で、BigQuery GIS 利用、そしてテンプレ機能使って生成したSQL処理で、できる限り並列処理化を試みている。
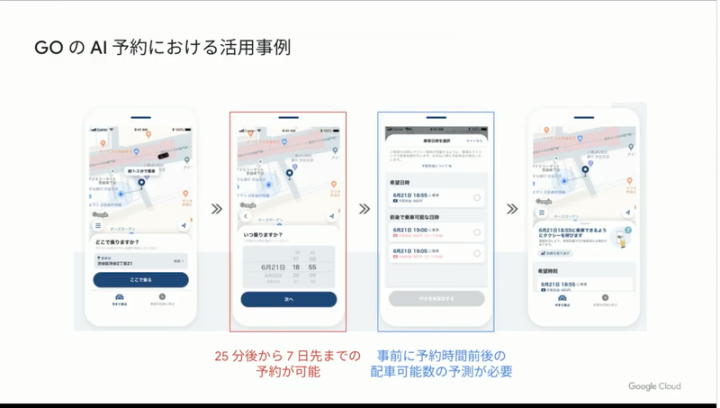
また指定日時の配車予約に対して、非効率な事前予約では無く、できる限り直前に配車できるよう BigQuery ML を用いて独自予測モデルを作り配車制度高めるしかけなど、Twitter にも書いたのですが、非ITエリアの課題をクラウドサービス使い倒して問題解決している辺りにインパクトを感じました。
その他、さまざまな課題解決方法についても面白いので、動画を見てみてください。
【ファーストリテイリング社】世界中のお客様の声を収集・AI で分析し、日々全社員が意思決定!Customer Driven の新しい経営の形
「情報製造小売へ。」の言葉に有るとおり、すべてのプロセスでデジタルデータを利用、「世界で一番良い仕組み」を作ると標榜している有明プロジェクトのお話がありました。(というか、久々に大谷さんみて驚いてました)
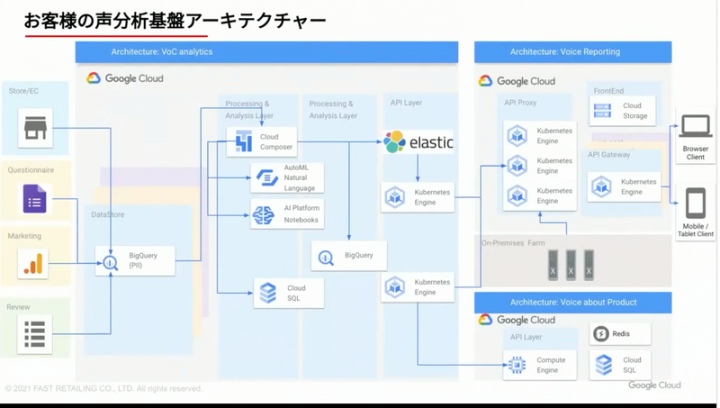
SNS含むすべての接点データを集め、それを全社員が見れるというお客様の声分析基盤を6ヶ月で実装と。

見れるだけじゃなく、当然プライバシーに配慮してマスキング処理などデータの扱いなどもケアされている仕組みのようで、尋常じゃないスピードで、安全かつ信頼性高いシステムを構築を内製でやっているのですね。スゴイな。
【DeNA】DeNA ゲーム基盤における Google Cloud Spanner の活用事例
全世界、複数のプラットフォームでゲーム提供をしている DeNA さんにとって必要な共通ゲーム基盤サービス構築の話です。まず LCX。
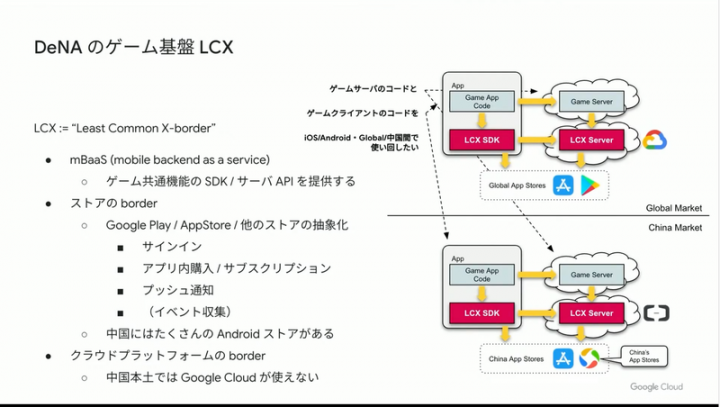
LCX は単純に DeNA にとっての共通APIというか mBaaS の位置づけですが、驚くのは共有基盤の下になっているプラットフォーム。上の図の例では、Google Cloud(および Play)と中国のクラウドとストア(例えば Alibaba Cloud)を共通化して扱えるようにする野心的なプロジェクトなんです。
これまでもゲーム系の会社とのお話してますが、このレイヤーを一つにしたいというのははじめて聞きました。ゲームサーバーや課金のみ・ユーザー登録のみなどはありましたが…
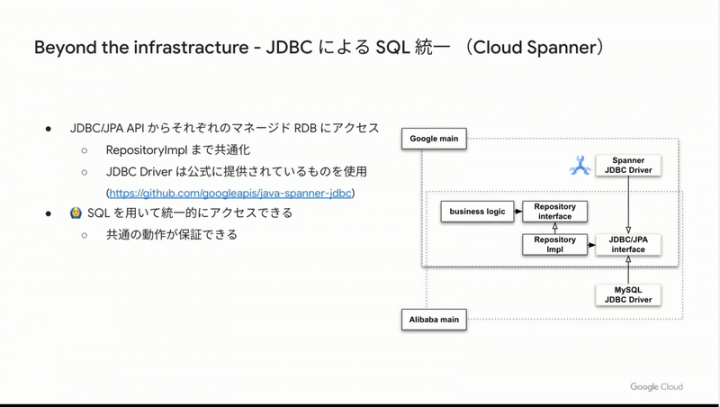
データストレージに関しては、クラウド毎に用意されているストレージタイプも違うため、吸収するレイヤーの実装は非常に面倒なはず。その課題に対し、他のクラウドに合わせる形で、Google Cloud では Spanner へ JDBC ドライバによるアクセスで共通化をクリアするというストーリー。もちろんその他 Spanner ならではのメリットも。
続いてゲームサーバー・フレームワークの Takasho の説明もありました。LCX と連携しつつ、運用オペレーションの共通化する仕組みです。
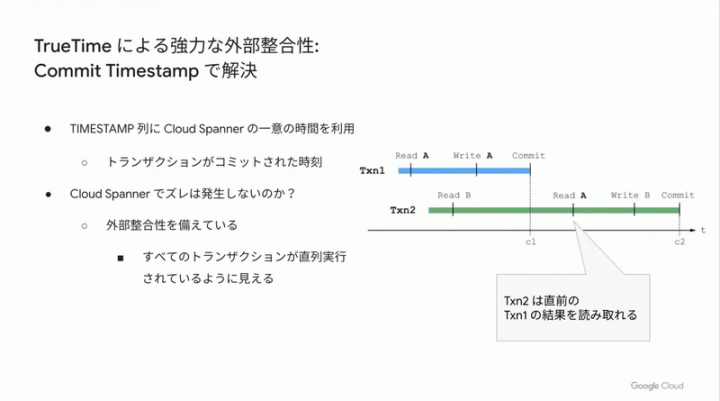
大きな課題としてオートスケーリングの課題や、ミリ秒単位でのトランザクション整合性担保がありましたが、OSS のオートスケーラー autoscaler 利用+バッチで増減する仕組みを作ったり、Spanner の Commit Timestamp 利用で解決。
自社でそこまでやるか、という事例でした。
【テレビ東京コミュニケーションズ】無料広告型動画配信サービスにおける機械学習の取り組み
無料の見逃し配信サービス「ネットもテレ東」でのCM配信を機械学習を使い倒して、効率化・高収益化していくお話でした。
動画配信のしくみ、特に広告動画を入れるしくみとしては、以下に表示回数を増やすかという課題があります。しかも本編の前後および中盤で入れるタイミングの中で同カテゴリのCMが入るのは広告主にとっては望ましくないため、この取り組みの中では Google の AI サービスを利用して、CM挿入ポイントを探るトライが行われてます。
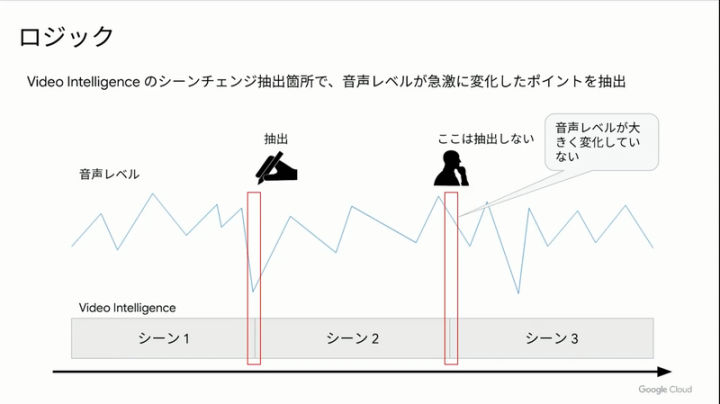
動画と音声分析によるシーンチェンジ自動抽出。人間がすべてやるのではなく、機械化することで省力化ができると。今後はさらに、音声から文章化して、文章の発話開始タイミングやテロップ表示タイミングも加味したシーンチェンジ予想する仕組みを作りたいとのことでした。
【フジテレビ】AI アプリ「メタロウ」による番組メタ情報の取得と検証
動画をリアルタイム解析して、メタデータをつける取り組み。動画に出ている人物特定から、何を放送していたかテロップなどをヒントに取り出す仕組みなど、テレビ局ならではの仕組み構築の話。
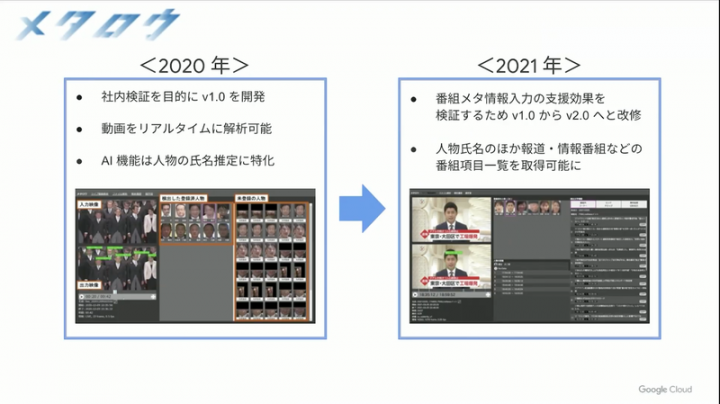
そもそも人物特定するための学習データがすでに約16000名分あって、このシステムを使うと連続ドラマ出演者 26名中24名特定可能ということで、それだけでも膨大な動画データへのメタデータ付与とデータベースの検索性に寄与していますが、それ以外にも誰がいつ(いつからいつまで)登場したか、何のニュースを話していたかなど、あたかもテキストデータを検索するかのように容易に動画を検索できるようになる夢のシステム。
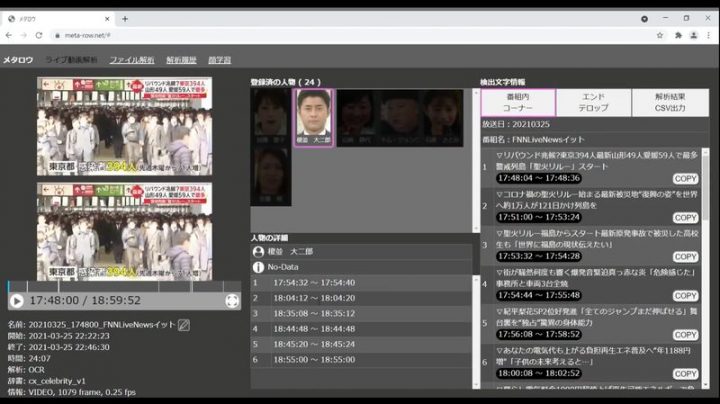
アイレットの streampack でも Azure の Vision 系のサービス使いながら同様な機能を作ったりしてますが、YouTube を始めとする動画サービスの盛り上がり、また企業が蓄積していく重要データとして動画が扱われる中で、このような仕組みは今後あたり前になると思わせる活動事例でした。
最後に
以上、気になるセッション内容のまとめでした。
ユーザー企業が Google Cloud および OSS などのサービス使い倒して、自社向けに特化したシステムを作り上げているさまが印象的でした。今はおそらく、課題が先行して存在した先進的な企業が実践している状態かと思いますが、今後さまざまな場面で使えるような課題解決手法だったのではないでしょうか。
クラウドベンダーから提供される機能そのままでも十分メリットはあるかも知れないですが、自社ならではの課題をクラウドサービスを使い倒し、時には要求を伝えて実装してもらうくらいの勢いで活用するのは、ディベロッパーとして一番楽しいのではと、改めてそう思えるセッションたちでした。面白かったー。ちなみに各社エンジニア募集してましたよw (アイレットも募集中です)
明日もセッションやハンズオンがあるのでどうぞ。オンデマンド動画はしばらく見れるはずです。
そういえばアイレット、スポンサーです。セッション登壇もしました!




