
はじめに
多くの方が望んでいたであろう、Aurora のライターを冗長化できるサービスがGAされました!

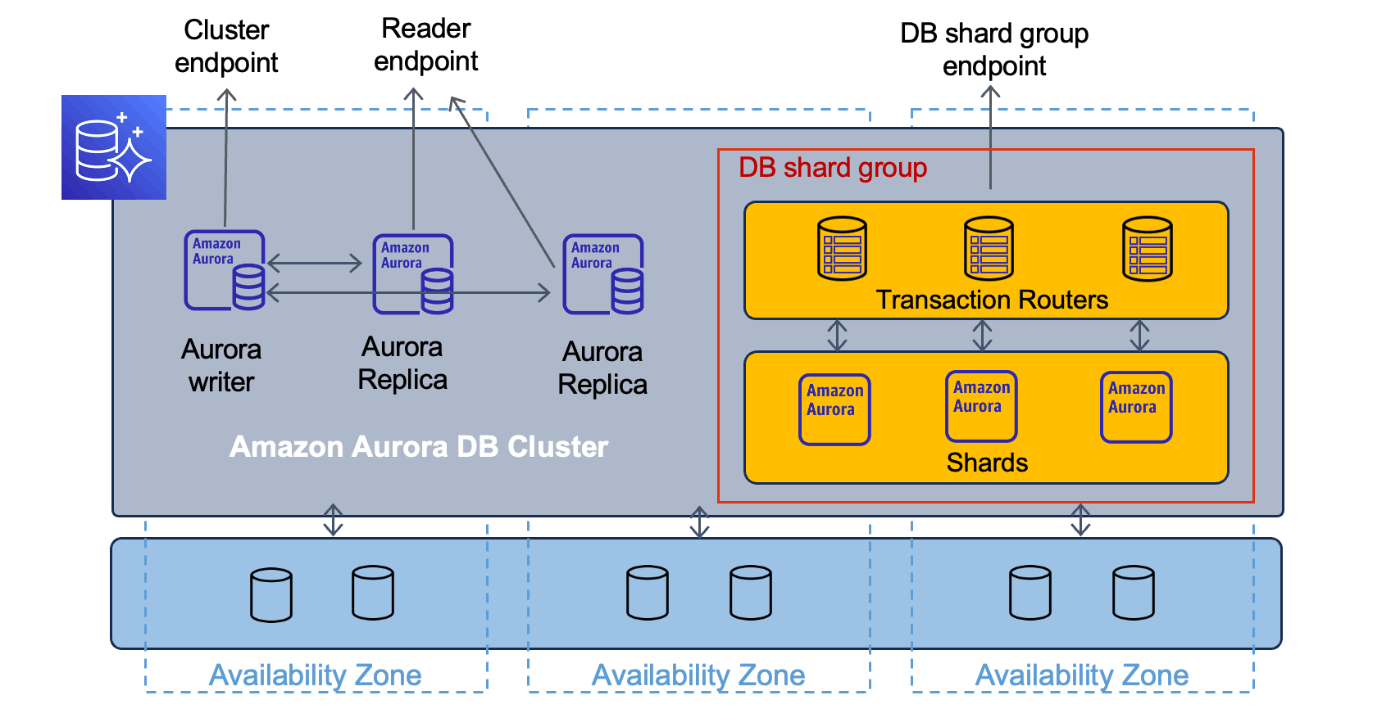
概要としては以下の図となり
引用:https://aws.amazon.com/jp/blogs/aws/join-the-preview-amazon-aurora-limitless-database/
Amazon Aurora のスケールアウトでは、基本リードのみ柔軟にできる形で、
リードレプリカを追加して読み込み性能をスケールできました。
しかし書き込み性能をスケールアウトは柔軟には行えず、
インスタンスサイズに制限を受けていました。
しかし
Aurora Limitless Database では トランザクションルータとシャードの2階層に分かれることでライターインスタンスの冗長化に成功した形となります。
以下session時のスライドと共に情報の共有となります。
データベースのスケールは時間とともに等比級数的に必要となります。

まず前提として、データベースのデータは一般的には等比級数的に拡大していくものです。
既存のAuroraでは、readerインスタンスに関してはリードレプリカの追加ということで、
スケールアウトが容易でしたが、writerインスタンスに関しては、スケールアップでの対応がメインという課題がありました。
シャード:
各々データベースのサブセットを保存するインスタンスを指す、下記のトランザクションルータと組み合わせることでwriter処理の並列化を可能としている
トランザクションルータ
データの保存場所に関するメタデータを保持、SQL コマンドを解析
それらのコマンドをシャードに送信し、シャードからデータを集約して単一の結果をクライアントに返して、分散トランザクションを達成する
以下具体例を用いたAmazon Aurora Limitlessテーブル作成例

一例として、レストランでの注文DBで説明をします。
・customerテーブル
・orderテーブル
・tax_rate
作成例;シャードテーブルの作成SQL

SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key='{"cust_id"}';
CREATE TABLE customer (
cust_id INT PRIMARY KEY NOT NULL,
name TEXT
email VARCHAR(100)
);
SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key='{"cust_id"}';
SET rds_aurora.limitless_create_table_collocate_with='customer';
CREATE TABLE order (
order_id INT NOT NULL,
cust_id INT NOT NULL,
amount DOUBLE NOT NULL,
tax_rate_id DOUBLE,
PRIMARY KEY (order_id, cust_id)
);
SET rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE tax_rate ( tax_rate_id INT PRIMARY KEY NOT NULL, city TEXT NOT NULL, state TEXT, country TEXT NOT NULL, tax_rate DOUBLE NOT NULL ); SET rds_aurora.limitless_create_table_mode='standard';
作成例;Limitless Databaseによるデータ格納構造

上記のデータ分散構造はこの図が最も伝えやすいと思います。
やりたいこととしてはシャードでの分散となるので、
シャードキーのユニーク性による分散を行う形となります。
よって、
customerテーブルと、orderテーブルは、cust_idが同一な限り同一のシャードに格納される形となります。
また、tax_rateテーブルはreferenceテーブルという別枠として、全シャードに分散されて格納される形となります。
referenceテーブルに関しては、高い一貫性を保持するものの、このテーブルへの書き込みを頻繁に行う設計は望ましくないでしょう。
シェアードテーブルに格納するという設定が以下となり、
SET rds_aurora.limitless_create_table_mode='sharded';
シェアードテーブルのキーの設定が以下、
SET rds_aurora.limitless_create_table_shard_key='{"cust_id"}';
複数あるシェアードテーブルを同一の場所に格納する命令文が以下となります。
SET rds_aurora.limitless_create_table_collocate_with='customer';
また、referenceテーブルとして格納する命令文が以下となります。
SET rds_aurora.limitless_create_table_mode='reference';
ここまでの情報があれば上記のqueryが理解できると思います。
参照テーブル

リファレンステーブルは頻繁なreadやjoin処理に対応した構造となっています。
比較用:既存のAuroraアーキテクチャ

ここで既存のAuroraアーキテクチャを比較で見てみましょう。
writerインスタンスのスケーリングに課題があることがわかります。
new:Aurora Limitless Databaseアーキテクチャ

マルチシャードによる並列処理の実現

代表的な上記4つなどはパラレルにデータが格納されていることで並列処理の恩恵を得やすいです。
データを集約させたテーブルの作成コマンド

こちらは先述の通り。
水平スケーリングの実施;collocated tableは一緒のスライスとして移動する


クエリーのトランザクションフロー

こういったトランザクションフローによって、実行の順序性が保たれます。
また、独立したクエリーリフレッシュ機能もその順序性の維持をサポートします。

データアクセスの責務を担うシャード層とは

DBマニアには垂涎ものの、DBの処理分散アーキテクチャです。
簡単なところとしては、シャード層はライターの処理を分散させるためにデータの保持をシャード単位で分けるよというところ。
※上記のシャードグループの作成コマンド例が以下です

redundancyは2で冗長性が2つに分かれているということです。
acuはACU(Aurora Capacity Unit)で、aurora独自のvCPUと似ている概念です。
メタデータとoptimizationの責務を担うトランザクションルーター層

トランザクションルーター層は、メタデータ実行予定クエリーの処理順序を整理し、各シャードに実行命令を行います。(optimization)
他にも面白い処理の内容が記載されていますので、ぜひ翻訳して読んでみてください。
※トランザクションルーター層は断片化されたメタデータは持つが、実データは所持しない

終わりに
Auroraを実際にプロジェクトで使用した方々は、readerしかスケールアウトできないことに
少なからずの悲しみを覚えていたと思います。
しかしここでwriterについても正しくデータ分割さえ行えばスケールアウトが容易になったことは、
柔軟なクラウドDB開発における大きな一歩の一つだと思います。
create文も理解してしまえばそこまで複雑なものでもないと思いますので、
GAが待ち遠しいですね。
