
12月14日に大阪のコングレコンベンションセンターで開催された「Generative AI Summit Osaka」に参加してきました!
セッションの内容など他の方の参考になればいいな。との思いで書かせて頂きます!
【セッション】Vertex AI で始める Google の大規模言語モデルの活用

Googleの生成AIの歴史から紹介!
2015年からあったんや!!とびっくりしました!
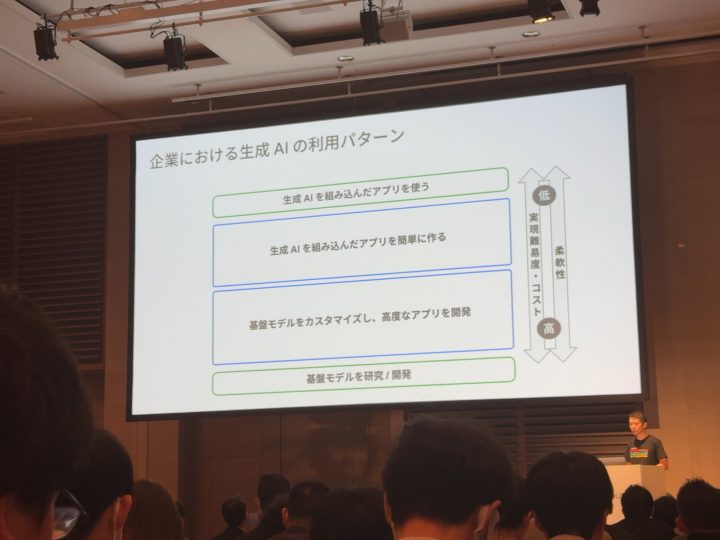
AIを利用すると言っても企業によっていろいろなAIの利用パターンがあるんだな!と勉強になりました!

「Vretex AI」の立ち位置は「Gemini」などの基盤のモデルを利用して開発できるらしいです。

LLMのカスタマイズ手法:「グラウンディング」を紹介します!

ユーザーの質問をLLMだけが回答を作成するのではなく、質問内容に関連する回答を外部データなどから検索しその得た情報を回答するようです。
では、どうやって関連する回答を外部データを取得するのか?
それは「ベクトル形式のデータ」で実現できる!
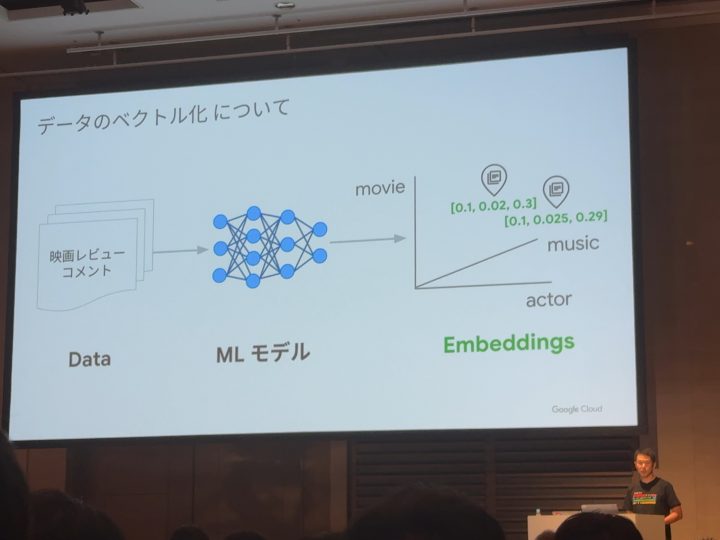
テキストなどのデータを機械学習モデルが三次元の空間に写像(数字)する。
そのベクトル化したもの同士のベクトル間の距離を測って類似する外部データを取得する。
理解はできましたがすごすぎてイメージが分からないw←再度展示ブースで聞いてみると
「データを数字にして保存し似たような数字の位置のものを取得する」イメージだそうです!
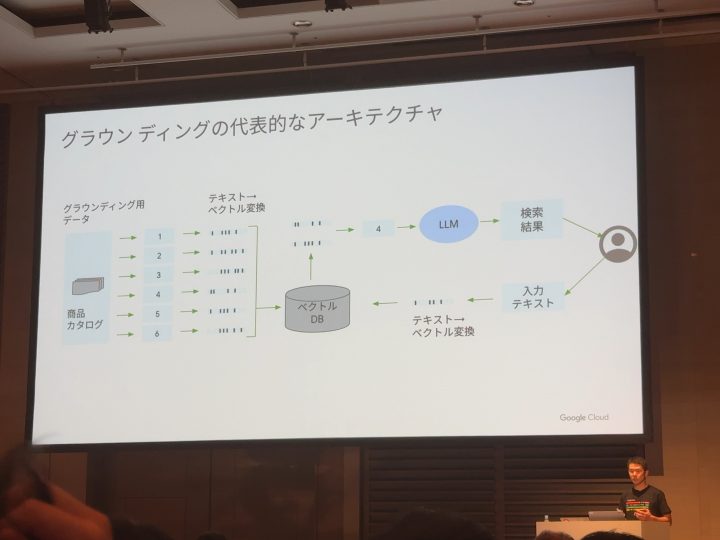
このグラウンディングの流れをGoogle Cloudの機能を活用すると
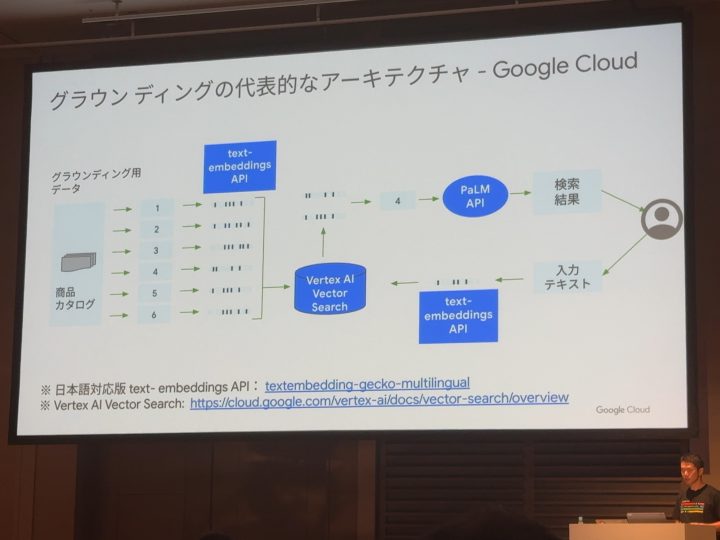
青色の部分がGoogle Cloudの機能の関連する要素になります!
これらはAPI経由で利用可能!
ただこのアーキテクチャ全体を0からアプリケーションに落とし込んでいくのは難しいので以下のフレームワークなどが利用できるらしいのでご紹介!
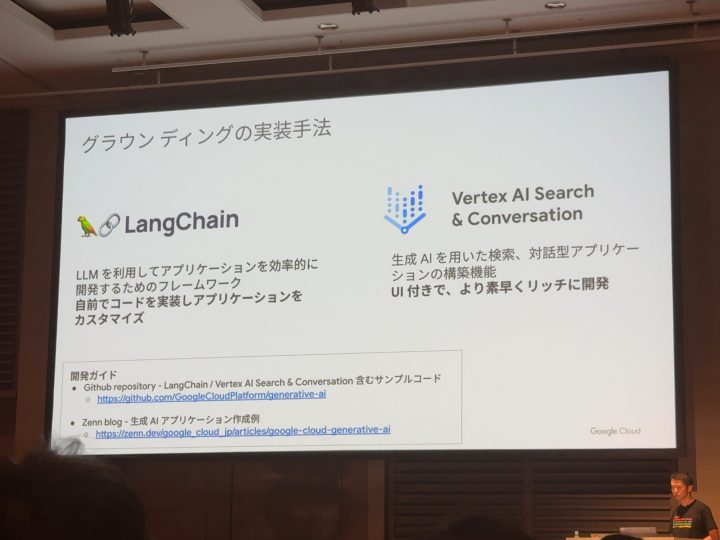
さいごに
つい最近のことの印象があったので、Googleの生成AIの歴史が2015年からあったとはびっくりしました!
特に「グラウンディング」の技術はびっくりしました!
「ベクトル化したもの同士のベクトル間の距離を測って類似する外部データを取得」は言っていることは理解できましたが、イメージがわからなく質問をしてみると丁寧にわかりやすく噛み砕いて説明頂きイメージすることができました!
ありがとうございました!
最後まで見て頂きありがとうございました!




