この記事について
みなさん、ECS利用していますか!?
AWSでコンテナを使うのなら、ECSですよね!?(kubernetesわからない勢)
ECSはタスクという単位で、アプリケーションを実行させます。
そして、タスクの中にコンテナが1つ以上稼働します。
タスクはタスク定義から作成されます。タスク定義はタスクの金型的な存在です。
また、タスク定義はJSONファイル(以後taskdef.json)として運用することが一般的です。
このtaskdef.jsonを実運用する際に迷うポイントがあります。
それは以下のどちらの方法にするかです。
– 方法① : 各環境ごとにtaskdef.jsonを用意する
– 方法② : 各環境でtaskdef.jsonを共用する
①,②について、それぞれの詳細/メリット・デメリットについて洗い出しをして、どちらを採用すべきかについての見解を述べていきます。
あくまで個人的見解なので、そちらはご了承の上でご参照お願いいたします!
(おさらい)ECSについて
前提知識として、ECSの構造について説明します!
また、本記事の内容と関連のあるCodeシリーズによるCI/CDについても説明します!
ECS
ECSは主に以下の4つの要素により構成されています。
- クラスター
- タスク
- タスク定義
- サービス
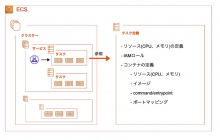
クラスター
箱です。
- サービスとタスクを分離するための論理グループ
- 実行環境やIAM権限の境界線
タスク
アプリケーションを実行するコンテナ群です。
- アプリケーションの実行単位
- 1つ以上のコンテナから構成される(同じタスクのコンテナは同じホスト上で稼働する)
タスク定義
タスクの金型です。
- タスクを構成するテンプレート
- アプリケーションを構成する1つ以上のコンテナを定義する
- JSON形式で記述される
ウェブサーバーのタスク定義のサンプルは以下の通りです。
{
"family": "sample-fargate-test",
"networkMode": "awsvpc",
"executionRoleArn": "arn:aws:iam::123456789012:role/ecsTaskExecutionRole",
"containerDefinitions": [
{
"name": "fargate-app",
"image": "nginx",
"portMappings": [
{
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
}
],
"essential": true,
"entryPoint": [
"sh",
"-c"
],
"command": [
"df -h && while true; do echo \"RUNNING\"; done"
],
"environment": [
{
"name": "ENV",
"value": "prd"
}
]
}
],
"requiresCompatibilities": [
"FARGATE"
],
"cpu": "256",
"memory": "512"
}
containerDefinitionsがタスク内に属するコンテナを定義する箇所です。この中に各コンテナのパラメータを記述します。
containerDefinitions以外の箇所は、タスク自体のパラメータになります。
サービス
タスクの管理人です。
- タスクをタスク定義から起動する
- タスク数を維持する
- ELBと連携する
CodeシリーズによるCI/CD
ECSで稼働しているアプリケーションを運用する場合、大半の場合はCI/CDを実装することになると思います。
Codeシリーズを利用してECSのCI/CDを実行する場合、以下のような構造になります。
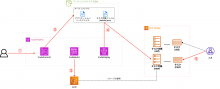
① Code Commitのレポジトリに変更をPUSH
② レポジトリ内のファイルがアーティファクトストアにコピーされる
③ Code Buildにてコンテナイメージのビルドが行われ、イメージがECRにPushされる
④ Code Deployがアーティファクトのtaskdef.jsonをもとに、新しいタスク定義を作成する
⑤ 古いタスクから新しいタスクに入れ替わる(Blue/Greenデプロイメント)
※ こちらのイメージは本記事説明に必要な情報を抜粋して簡略化しています。
ポイントはレポジトリ内のtaskdef.jsonによりタスク定義が作成されるということです!
想定ケース
割とおさらいに割いてしまったので、改めて本記事の主題について説明します!
- 方法① : 各環境ごとにtaskdef.jsonを用意する
- 方法② : 各環境でtaskdef.jsonを共用する
これを比較する際のアプリケーションの想定を以下とします。
- アプリケーションは本番環境と開発環境の2環境構成
- ECSでアプリケーションを稼働させている
- Codeシリーズ(Code Commit/Code Build/Code Deploy/Code Pipeline)でCI/CDパイプラインを実装している
- ECSのデプロイはBlue/Greenデプロイメント(Code Deployを利用する場合、Blue/Greenデプロイしか利用することはできない)
では、方法①と方法②の特徴およびメリット/デメリットについて解説していきます。
方法① : 各環境ごとにtaskdef.jsonを用意する
こちらは方法②に比べてシンプルな方法です。単純に環境分のtaskdef.jsonをレポジトリに用意します。本番と開発環境であれば、taskdef-prd.jsonとtaskdef-dev.jsonのようにファイル名をつける形になります。そして各環境のパイプラインにてタスク定義ファイルの名前を異なるように定義するだけです。
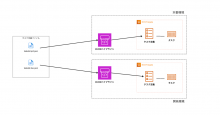
この方法のメリットとデメリットをまとめます。
メリット
- 実装が楽
- パイプライン構成がシンプル
各環境のパイプライン内のCodeDeploy設定でタスク定義ファイルをtaskdef-(環境名)と指定するだけなので、実装が楽です。パイプラインの構成もシンプルになるため、第三者が見ても理解しやすいです。
デメリット
- 運用が大変
各環境ごとにtaskdef.jsonを用意するということは、taskdef.jsonファイルを多重管理しなくてはいけないということです。環境間でタスク定義の差分はないケースが多いので、同じ内容のtaskdef.jsonを多重管理するのは運用上の負担になります。環境間のtaskdef.jsonにデグレが生じる可能性もありますし、環境が多ければ多いほど管理しなくてはいけないtaskdef.jsonも増えてしまいます。
方法② : 各環境でtaskdef.jsonを共用する
各環境にて利用するtaskdef.jsonを共用して、1つのtaskdef.jsonのみレポジトリに用意する方法です。
この方法を実現するには少し工夫が必要です。
タスク定義において、コンテナに渡す環境変数はcontainerDefinitions.environmentにてプレーンテキストで定義します。これだけだと動的にパラメータを指定することができません。
containerDefinitions.secretsを利用すると、環境変数に渡す値をシークレットマネージャーもしくはパラメータストアにセットすることができます。
"containerDefinitions": [
...省略...
"environment": [
{
"name": "ENV",
"value": "prd"
}
],
"secrets": [
{
"name": "DB_PASSWORD",
"valueFrom": "arn:aws:secretsmanager:ap-northeast-1:123456789012:secret:/rds:password::"
},
}
]
各環境のシークレットマネージャーにて同じシークレットを定義して異なる値をセットすることで、同じtaskdef.jsonを利用しながら各環境で異なる環境変数を渡すという動的な指定をすることが可能です。
例えばconfig:envというシークレットを本番環境と開発環境のどちらにも用意して、それぞれの環境で値にprdとdevを登録するといったものです。
(なお、これは環境が異なるAWSアカウントもしくはリージョンにある場合のみ可能で、同一アカウントの同一リージョン内で環境を分けている場合はタスク定義のみだとパラメータを動的に指定することはできません。)
しかし、コンテナに渡す環境変数以外は動的に指定することができません。環境ごとにタスクに渡すリソース値を変更したい場合もあります。
タスク実行ロールはその一連です。タスク実行ロールはtaskdef.jsonの中で以下のように定義されます。
"executionRoleArn": "arn:aws:iam::123456789012:role/ecsTaskExecutionRole",
値の中にはAWSアカウントIDとリージョンが入っています。これだと、異なるAWSアカウントもしくはリージョンで同一のtaskdef.jsonを利用することは難しそうです。
しかし、パイプライン上で工夫をすればtakdef.jsonを複数の環境で共用することができます。
では、これをどのように実現するのか解説します。
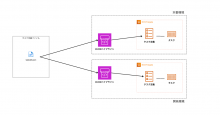
実現方法
具体的な方法はCI/CDパイプラインの中でtaskdef.jsonを置換するアクション(もしくはステージ)を設けるです。
CodeBuildにてsedコマンドを実行して、taskdef.jsonの内容を置換します。
置換処理がない場合のパイプライン構成は以下の通りです。
ですが、これにtaskdef.jsonを置換するアクション(ステージでも可能)を差し込みます。
Replace-Taskdefアクションにてtaskdef.jsonの置換処理を行います。
以下はパイプラインの構成イメージです。
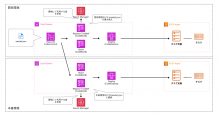
以下がポイントになります。
- 本番環境の発火ブランチ : mainブランチ、開発環境の発火ブランチ : developブランチ
- Replace-Taskdefアクションにてtaskdef.jsonをsedコマンドで置換する
- 置換する際に参照する値は各環境のSecret Managerに保存する
レポジトリに保存するtaskdef.jsonは以下のように記述します。
{
"family": "sample-fargate-test",
"networkMode": "awsvpc",
"executionRoleArn": "arn:aws:iam::<ACCOUNT_ID>:role/ecsTaskExecutionRole",
"containerDefinitions": [
{
"name": "fargate-app",
"image": "nginx",
"portMappings": [
{
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
}
],
"essential": true,
"entryPoint": [
"sh",
"-c"
],
"command": [
"df -h && while true; do echo \"RUNNING\"; done"
],
"environment": [
{
"name": "ENV",
"value": "<ENV>"
}
]
}
],
"requiresCompatibilities": [
"FARGATE"
],
"cpu": "<task_cpu>:",
"memory": "<task_ram>"
}
置換対象の文字を<>で囲っています。
そしてReplace-Taskdefアクションの処理をbuildspec-taskdef.jsonとして定義します。
version: 0.2
env:
secrets-manager:
ACCOUNT_ID: /my_value:ACCOUNT_ID
ENV: /my_value:ENV
task_cpu: /my_value:task_cpu
task_ram: /my_value:task_ram
phases:
build:
commands:
- sed -i -e "s#<ENV>#${ENV}#" taskdef.json
- sed -i -e "s#<ACCOUNT_ID>#${ACCOUNT_ID}#" taskdef.json
- sed -i -e "s#<task_cpu>#${task_cpu_client}#" taskdef.json
- sed -i -e "s#<task_ram>#${task_ram_client}#" taskdef.json
artifacts:
files:
- taskdef.json
このアクションではSecret Managerから値を参照して、sedコマンドでtaskdef.jsonを置換するという処理を行なっています。
CodeBuildもしくはCodePipelineの環境変数に登録しておけば、Secret Managerに保存しなくても置換処理に利用する値を参照することは可能です。
ただし、以下の理由で全ての値をSecret Managerに保存します。
- 機密情報を安全に扱う
- 機密情報をSecret Manager、それ以外をCodeBuild or CodePipelineの環境変数に定義していると、どの値がどこにあるかは把握しずらいため運用性が低くなる
CodePipelineの環境変数
CodeBuildの環境変数
それではこのtaskdef.jsonを共用する方法のメリット/デメリットについて説明します。
メリット
- 運用しやすい
方法①に比べると、運用がしやすいです。複数の環境があっても一つのtaskdef.jsonに変更を加えるだけで、全ての環境に変更が適用されます。
特に環境の数が増えれば増えるほど、このメリットが強調されるようになります。
デメリット
- 環境ごとのタスク定義が大きく異なることがあれば、実現が難しい
- 実装が大変
- 第3者が理解しにくい
デメリット以前の話な気もしますが、そもそも環境間におけるタスク定義の差分が置換処理だけで吸収できない場合は、この方法②を実現することはできません。
そして、方法②は方法①に比べて構成が複雑なため実装が大変です。構成が複雑ということは、第3者が理解しにくいということです。
結局、どうするべき?
では方法①と方法②について、どちらを採用すべきか?
この問いについて私の見解を述べさせていただきます。
私は実現可能であれば方法②を採用するべきだと思います。
方法②は方法①に比べて、構成が複雑であり実装が大変というデメリットがあります。ただしこのデメリットは実装段階だけであり、運用保守は方法①に比べて格段に楽です。構成が複雑なのもドキュメンテーションをきっちりやっておけば、デメリットらしいデメリットではなくなります。
方法①は逆のパターンで、実装が簡単だけれど、運用保守が大変です。環境の数が多ければ多いほど、運用保守が大変になります。
実装の楽さ、運用保守の楽さ、どちらを取るかと問われたら間違いなく運用保守の楽さを取った方が良いです。
運用保守する機関のほうが、実装する期間に比べて格段に永くなります。
だだし方法②を採用可能かは確認が必須です。置換処理だけ各環境のタスク定義の違いを吸収できるかは事前にしっかり確認しておきましょう。
まとめ
| 方法 | メリット | デメリット |
|---|---|---|
| 方法① : 各環境ごとにtaskdef.jsonを用意する | – 実装が楽 – 構成がシンプル |
– 運用保守が大変 |
| 方法② : 各環境でtaskdef.jsonを共用する | – 運用保守が楽 | – 実装が大変 – 構成が複雑 |
- 実装の楽さよりも、運用保守の楽さを重視するべきなので方法②がおすすめ
- 特に環境の数が多ければ、なおさら方法②がおすすめ
- ただし方法②は実現可能かは注意する
- 方法②は構成が複雑になってしまうため、ドキュメンテーションをしっかりやる(このブログを参考文献に載せてくれたら嬉しい)
