
まえがき
cloudpackサポートの奥村です。
私は、cloudpackサポートの技術サポートの窓口にてお客様からの問い合わせを担当しております。今回は、cloudpackサポートで生成系AIを用いてサポートへの問い合わせデータの効率化を実施した事例についてご紹介させていただきます。
cloudpackサポートとは
cloudpackサポートとは、「請求代行をご契約のお客様で、監視・運用保守サービスに加入されてないお客様がご利用いただけるテクニカルサポートデスク」です!
主に、弊社請求代行サービスをご契約のお客様で対応が不可能な作業範囲における作業代行や、cloudpack のノウハウの提供、必要に応じてクラウドベンダーサポートへの問い合わせを実施することでお客様が抱える課題解決のご支援を実施しております。
目的
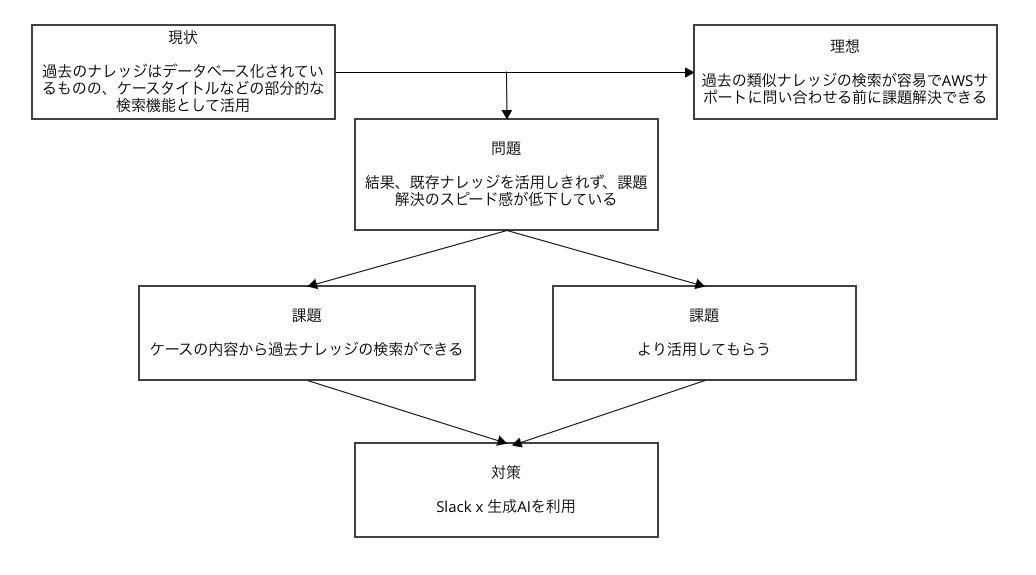
まず、概念実証にあたり今回のプロジェクトの目的を定めました。
お客様の課題解決には、過去にサポートに問い合わせをした内容が役立つことが非常に多いです。過去の問い合わせを活用することで、新たなサポートへの問い合わせによるタイムラグをなくし、迅速に解決へのサポートを行えることがあります。
現状は、過去のサポートへの問い合わせのナレッジを十分に保有しているものの、部分的な検索機能しかもっておらず、関連度の高い過去の問い合わせの発見に時間がかかるため、十分に活用できておりませんでした。一方で理想とする状況は、過去の類似した事例の検索を容易にすることで、お客様の課題解決を迅速化したいと考えております。
また、効果的にナレッジを活用するためには、普段の業務での利用頻度が高いSlackの活用が望ましいと考え開発に取り組みました。
以下がイメージ図となります。
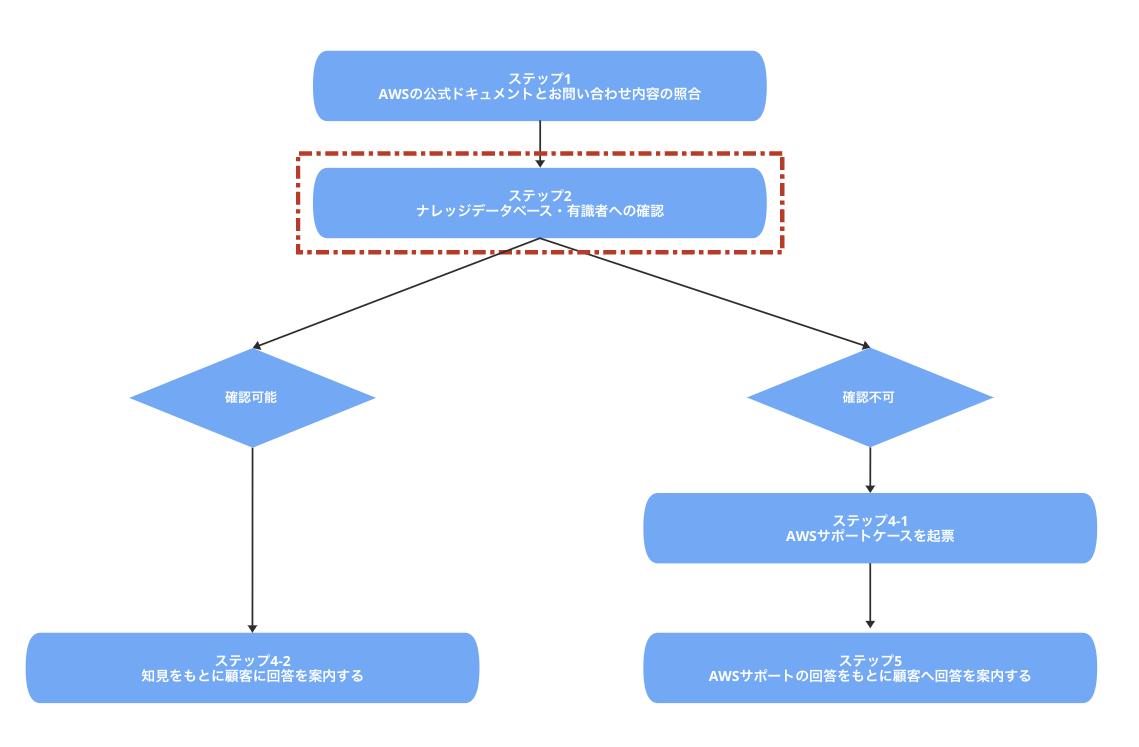
現状のフローの確認
弊社ではお客様から技術サポートにお問い合わせを頂いた後、サポートエンジニアは以下のステップにて対応を実施しています。本プロジェクトとしては、ステップ2の効率化が目的となります。
理想とするフロー
目的と現状のフローを踏まえた上で、理想とするフロー作成から着手しました。
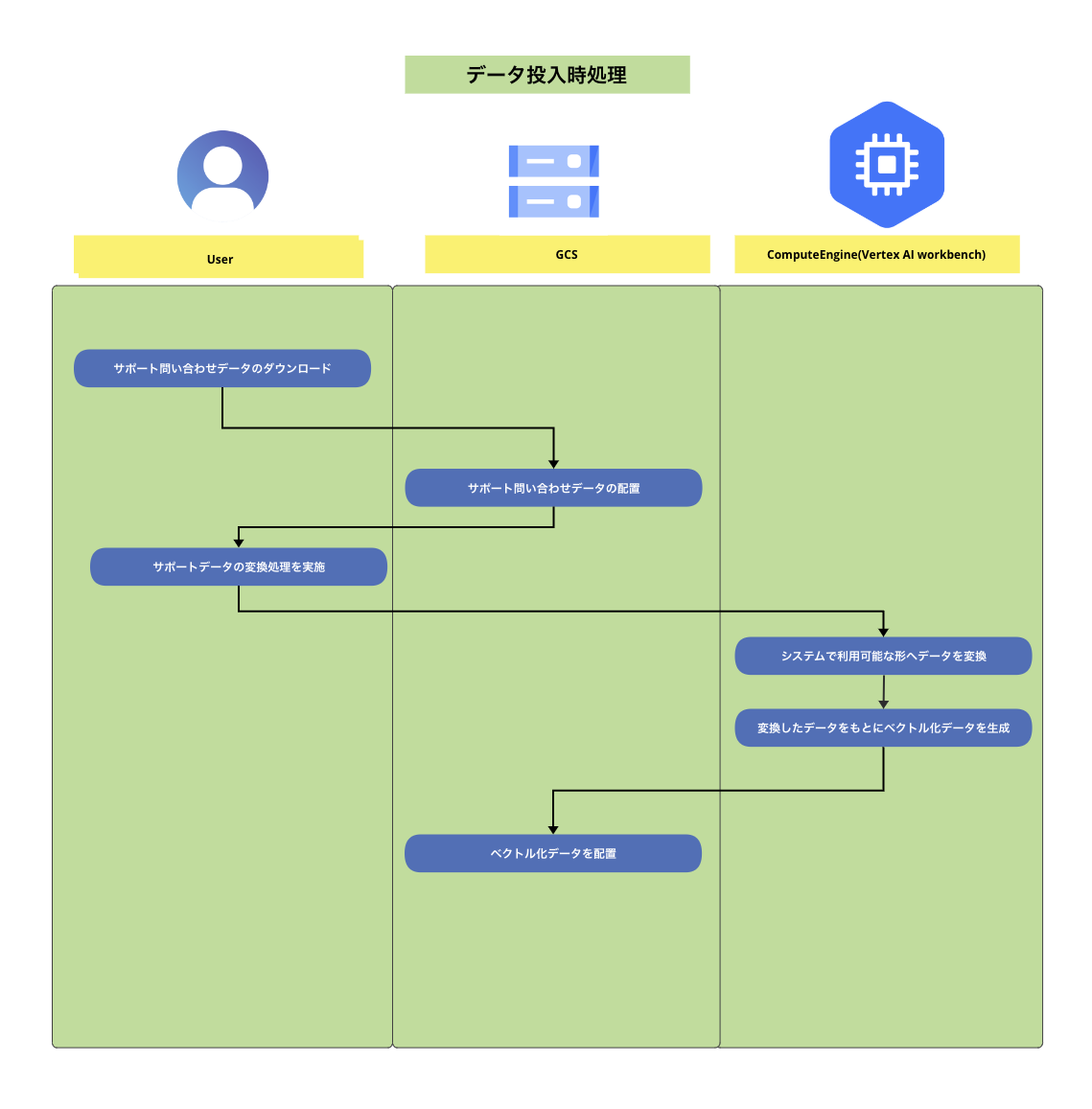
「データ投入時処理」と「ユーザー利用時処理」の2つに分割されそれぞれの特徴は以下となります。
- データ投入時処理
- 新規に問い合わせデータを追加し、実際にユーザーが利用できる形の生成を目的とした処理です
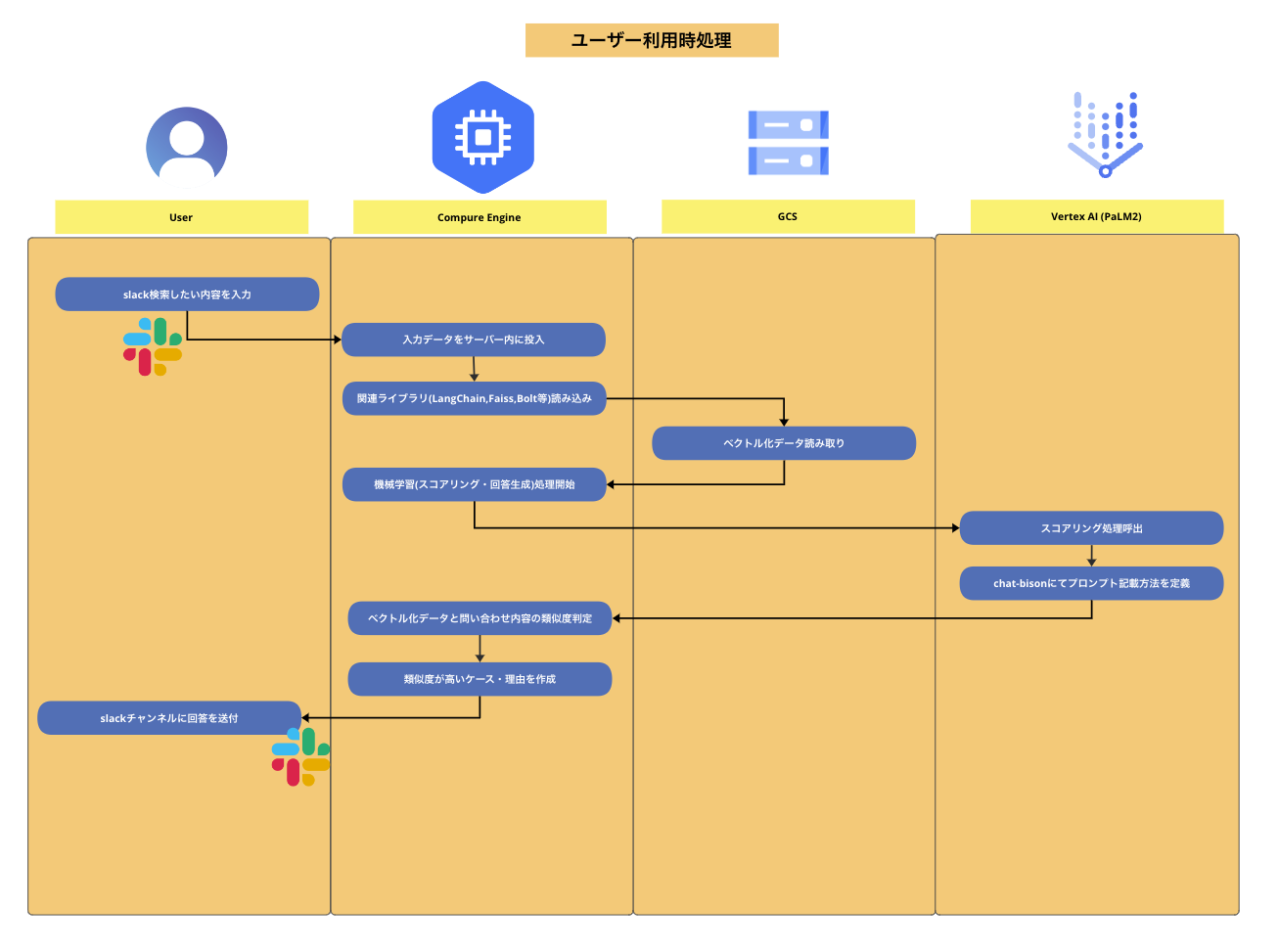
- ユーザー利用時処理
- 実際に情報を検索したいユーザーが、Slackに情報を入力して関連度の高い問い合わせデータを返すまでの処理を記載しています。
今回実施した内容
LangChain
基本のフレームワークとしてはLangChainを用いて、ライブラリとしては以下を利用しました。
- RecursiveCharacterTextSplitter
- サポートへの問い合わせデータをチャンクに分割するために使用します。
- Faiss
- Meta(Facebook)製の近似最近傍探索ライブラリで、過去の問い合わせデータを検索するためのインデックスとして使用します。
VertexAIEmbeddings
エンベディング処理についてはVertex AIを利用しました。
- chat-bison(PaLM 2)
- テキスト エンベディング処理をコールし、類似した問い合わせの検索を可能にします。また、言語理解・言語生成・会話を得意とする大規模言語モデル (LLM)であり、ユーザーからの質問型の定義を実施します。
slackbot
生成された回答をslackbotへ返答する処理はboltにて実装しました。
- bolt for python
- slackアプリの設定に使用します。
環境構築にあたり
プロダクトの選定
Google Cloudを利用してインフラ環境の構築を実施しました。
選定の決め手としてはVertex AIの存在がありました。
他のクラウドベンダーに比べ機能の拡張性が高く、利用可能な機能の幅が広いということが理由です。具体的には以下となります。
- Vertex AI Generative AI Studioにて、豊富な言語モデルより選択が可能
- Vertex AI Search and Conversationにて、将来的に社内で検索を可能な形にできる
- Vector Searchなどを用いて、より管理しやすい形でのベクトル化処理を実装できる
構成図
利用したプロダクトに関する役割
- Compute Engine(Notebook instance)
- クラウドベンターのサポート問い合わせデータに対して前処理を実施し、機械学習に必要な処理の形に整える
- Cloud Storage
- 前処理を実施したデータを、格納
- Compute Engine
- LangChainを用いた機械学習処理を実装
- boltを用いてslackBotの受け口として利用
実際の挙動
Slackでメンションをすると、回答が返ってきます。以下指標を見てユーザーは情報の活用可否を判断します。
なお、Slackに返された情報を通じてユーザーはクラウドベンターのサポートに問い合わせするかどうかを決定します。
もし、類似の内容がSlackから返された場合は過去のナレッジを活用できる可能性があると判断します。
項目
- index
- 実際の問い合わせID
- score
- 関連度を(1〜5のランクにて評価、5が一番関連度が高い)
- reasoning
- 関連度が高い理由を示す

課題
- ベクトル化処理を高速化して、より早く回答をSlackにて生成できるようにする
- 回答精度を向上する
- 質問とは無関係・関連のないデータが入っていたときに相応しくない応答(ハルシネーション)をすることがあるため、関連度の高い応答をするようにチューニングを継続する
本システムに関するグループメンバーからのコメント
- メリット
- 高頻度なお問い合わせについて類似のサポート問い合わせ内容を確認することで、回答時の文章の作成の参考になる
- 業務で常時利用するSlackにてナレッジ検索が可能となり、業務をしながら手軽にナレッジの検索が可能
- 大規模言語モデルでの検索ルールはあるが、対話式で質問が容易に可能
- 要望
- 過去問い合わせデータだけではなく、関連性の高い公式ドキュメントを案内してくれるツールになれば、ドキュメント検索の手間が省けて活用できそう
- 〇〇はどこに掲載されているなど社内のwikiなどを誘導してくれるツールとなれば活用の幅が広がりそう
今後について
本プロジェクトはまだ検証段階であり、より最適なプロダクトがあれば議論しながら進めていく想定です。今回の検証作業にて、課題となったSlackで回答を生成するまでの速度と回答精度については、今後改善に努めて参ります。以後、実践的な活用ができるよう検証に取り組んでいきます。