
先日幕張メッセで開催されたAWS Summit Japanに参加してきました。
そこでハルシネーションを抑制した生成 AIについてパートナーセッションがあったため、一部ご紹介します。
生成AIの活用が叫ばれて久しい昨今、テキスト生成AI導入の大きな障害になっていることのひとつが、平然と嘘をつくこと(=ハルシネーションの発生)ですよね。
それがかなり抑制できる!とのこと。その方法とは?大変興味深いセッションでした。
参加したセッション
セッションタイトル:ハルシネーションを抑制した生成 AI が生み出す顧客事例とそのアーキテクチャ解説
スピーカー:有馬 幸介 氏(ストックマーク株式会社 取締役 CTO)
セッションより一部抜粋
ハルシネーションが主な原因で、生成AIの普及が進んでいない→解決できないか?という着眼点から事業スタートしたところ、例えば下記のような成果が出たとのこと。
- (あるビジネスドメインに関して)正答率40%→90%
- 回答できない、知らない、と回答できること

言語やドメインに特化すると、より正確に、より速く回答できる(ハルシネーションが起きにくい)ということがわかった:この結果が大事である、と、何度も強調していました。
それにより、下記のユースケースへの活用が期待できるとのこと。
Stockmark LLMのユースケース:
- エンタープライズサーチ(社内に長年蓄積されてきたノウハウ・実績の共有)
- 用途探索(アイデア出しの支援)
上記を実現したアーキテクチャも公開してくださっていました。
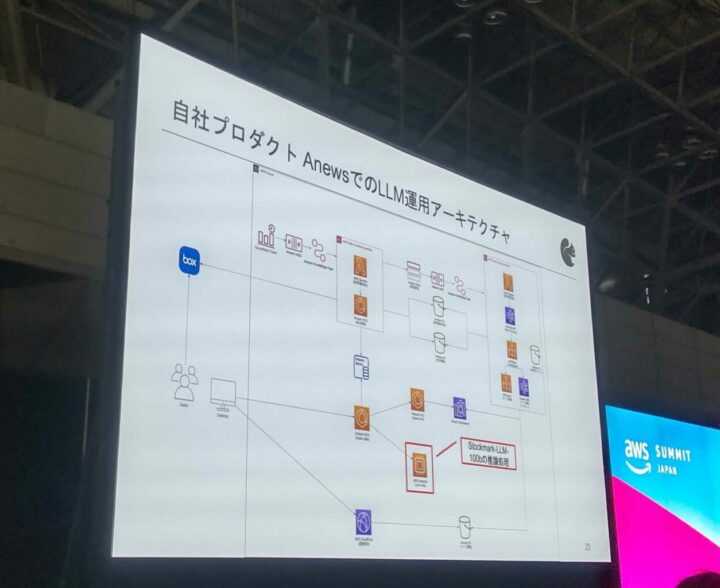
特に強調していたのがAWSの下記サービス
- 学習:AWS Trainium
- 運用:AWS Inferentia2
- 並列処理するとその分速度が上がる
どちらもLLM用に振り切ってる(=特化している)ため、コストパフォーマンスが高いとのこと。
今後活かせること
「何でも答えられるテキスト生成AI」は、回答が遅いし嘘もつくが、「限られた分野に特化したテキスト生成AI」は、回答もより速く正確(誠実、とも言えるかも)という性質は、さながら人間のようで非常に興味深いですね。
ハルシネーションが看過できないシステムでは、上記の「特定の分野に特化した」LLMを検討することは有効のようです。
また、AWSを用いてLLMを扱う際は、それに特化しているサービスを使うことで成果を得やすい、ということも大きな学びでした。
以上、最後まで読んでくださってありがとうございました!!



