
Google Cloud Next Tokyo ’24に参加し、「大規模言語モデル(LLM)をビジネス アプリケーションで活用するための基礎知識と現実的なアプローチ」を聴講してきました!
そのセッションの概要をまとめたいと思います。
セッション概要
タイトル:大規模言語モデル(LLM)をビジネス アプリケーションで活用するための基礎知識と現実的なアプローチ
登壇者:Google Cloud 中井 悦司 グーグルクラウド AI ソリューション アーキテクト
大規模言語モデル(LLM)をビジネスに活用する際は、LLM を単体で使うのではなく、他の機能と組み合わせた「アプリケーション」を構築する必要があります。LLM の仕組みをわかりやすく説明した上で、LLM を組み込んだビジネス アプリケーションのアーキテクチャー、ユースケース、評価方法など、「やってみた」で終わらないための現実的なアプローチを解説します。
セッション内容

生成AIを活用する上でのポイントが複数ある中、このセッションでは「既存のビジネスプロセスの中で生成AIを有効活用できるポイントを発見する」という所に焦点を当てて話が進められました。
「業務のどの部分に生成AIを使って効率化を実施するのか、逆にどの部分は生成AIを利用しないのか」ということです。

放送局がお客様の事例が紹介されていました。
従来、膨大な動画のアーカイブデータに対して検索をかけられるようにするため、下記の作業が行われていたようです。
- 社員が動画を視聴しながら、その内容をテキストに書き起こす
- 他の社員がその内容をダブルチェックする
- そのテキストと動画を一緒に保存する(動画データに対するメタ付けみたいな)
そんな文字起こし作業には沢山の時間を要するため生成AIを使って自動化しようとなったようです。
ですが、生成AI利用に対する懸念がありました、、、「ハルシネーション」です。
確かに、報道される内容は必ず正しいものでないといけないので、生成AIに任せていいのかと不安に思ってしまいますね。。
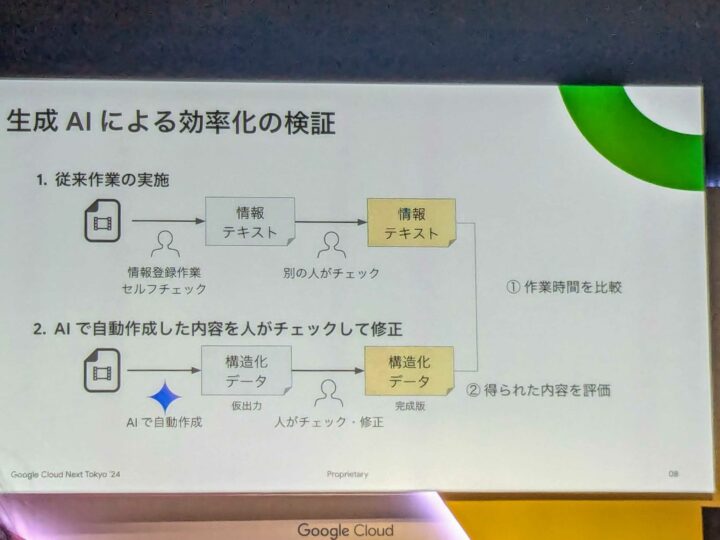
そこで、一次作業のテキスト作成のみを生成AIによって自動化させ、その後のダブルチェックは人が実施するとなったようです。
まさにこの記事の最初に触れた、生成AIを活用する上でのポイント「業務のどの部分に生成AIを使って効率化を実施するのか、逆にどの部分は生成AIを利用しないのか」ですね。
その結果として、一時作業の時間が大幅に削減することが出来たそうです。
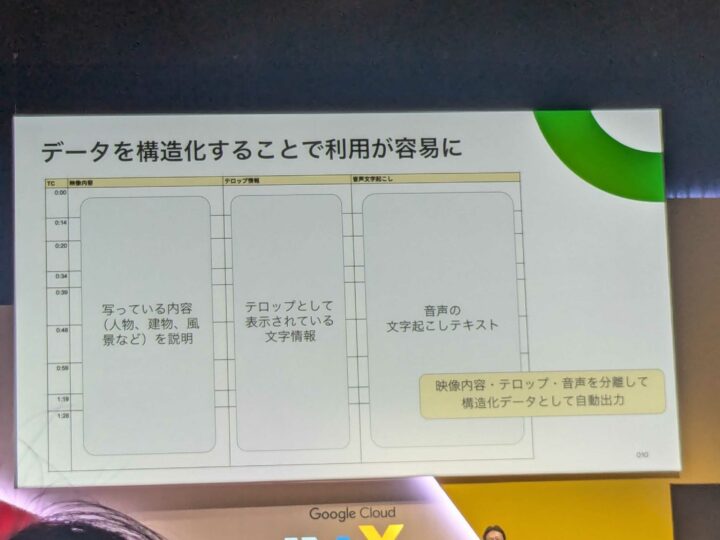
また、人が作成したテキスト情報よりも、生成AIが作ったデータの方が内容がリッチで、品質にもばらつきがなかったようです。同時に生成AIは動画の内容を構造化データとしてまとめていたため、より検索しやすくなったとのことです。
少し前に「ハルシネーション」という言葉を挙げましたが、生成AIを利用する中で「どのように生成AIの間違いを軽減していくか」という点も重要になってきます。
有名な方法として「RAG」や「グラウンディング」がありますが、スピーカーの方は「プロンプトエンジニアリング」も大切になってくると説明されていました。
1つ目の方法は「丁寧で詳細な要望をプロンプトに入力する」ということです。(根幹となるところですね)

上記のようなシンプルなプロンプトだと、期待する出力結果とは程遠いものとなってしまい使い物になりません。

期待に一致するような出力にするには、プログラミング的な考えを用いながら上記くらいの詳細なプロンプトを設定する必要があるそうです。。。
生成AIの間違いを軽減する2つ目の方法は「Many shot example」です。

例えば、テキストメッセージの内容に対して、生成AIにポジネガ判定をしてもらうとします。
そのメッセージにはポジティブな言葉が入っておらず生成AIがポジでないと判断しても、担当者独自の判断基準的にポジティブと判定したい場合があったりすると思います。
そのような判断基準を生成AIに考慮させるために、「入力内容」と「期待する出力内容」の具体例を用意してプロンプトに埋め込むというテクニックが「shot example」になります。
これによって、LLM はこれらの例を参考に期待する判断基準を類推します。
沢山のexampleを投入すればするほど、その精度は上がってきますね。
まとめ
今回のセッションで学んだポイントやテクニックを実施し、生成AIを適切に利用していきたいと思います。
この内容に関する詳細は下記の記事に書かれているそうです!
【Zenn】Gemini 1.5 のロングコンテキストを活かして AI を育てるアプローチ 〜 RAG の限界を軽やかに突破するために
当記事をご覧いただき、ありがとうございました。




