
Google Cloud Next Tokyo ’24 で行われたセッション「マルチモーダル生成 AI Gemini による映像解析 How-To」のレポートです。
セッション情報
セッションタイトル:マルチモーダル生成 AI Gemini による映像解析 How-To
スピーカー:Google Cloud 段野 祐一郎 様
AI による利活用が進みづらかった動画・映像ファイルも、マルチモーダル AI の進化により今後、より処理の自動化が進むと思われる。
ただし、単純に動画ファイルを生成 AI に解析させても動画という特殊メディアゆえに思うような結果が得られなかったり、動画を解析する以外の利活用のイメージが湧かなかったりすることで、利活用が進まない可能性がある。
このセッションでは、より多くの企業が動画も含めた非構造化データの利活用を推進できるための、Gemini による映像解析におけるベストプラクティスをご紹介します。
映像解析のニーズ
映像解析の主なユースケースは以下になります。

映像解析の難しさ


動画にはシーンごとにテロップ・ナレーション・ストーリー…とさまざまな種類の情報が内包されています。
映像解析の観点から見るとそれらの画と音の同期やデータ間のシームレスな推論能力が必要とされます。
Gemini1.5Proでは最大2Mのコンテキスト長を持って、高度な推論・ニュアンス・理解を必要とする複雑なタスクに渡って最高品質の実現を可能としています。
Gemini 1.5利用上の留意点
映像解析のHow-Toのご説明の前に、Gemini1.5の利用時における留意点のご説明がありました。

Geminiの映像解析時には1fps(1秒1フレーム)ごとにサンプリング処理が行われます。
これは、多くの場合1fps以内に動画内の情報が大きく変化することが少なく、これ以上の粒度でデータ処理にコストを掛けてサンプリング処理を行っても、AIの動画に対する理解度に大きく差がなかったことが理由だそうです。
また、映像解析において文字起こしは句読点が含まれなかったり、音声以外の音の文字起こしは苦手としているそうです。
文字起こしなどが必要となる場合は、Google社が提供している音声認識APIの「Google Speech-to-Text API」の採用がおすすめと仰っていました。
⚠︎高画質な映像を用意しても処理能力が上がるわけではないという点も注意が必要です。
映像解析における効果的なプロンプトの実装ステップ
ここからは、実際にどのようなプロンプトが映像解析にとって効果的となるか解説がございましたのでご紹介いたします。
プロンプトエンジニアリングの重要性

プロンプトエンジニアリングとは、生成AIに期待通りの出力をさせるために指示文(プロンプト)を設計・改良する技術を指します。
プロンプトの書き方で生成AIの性能が大きく変わるという研究結果があるため、生成AI活用において重要な要素となります。
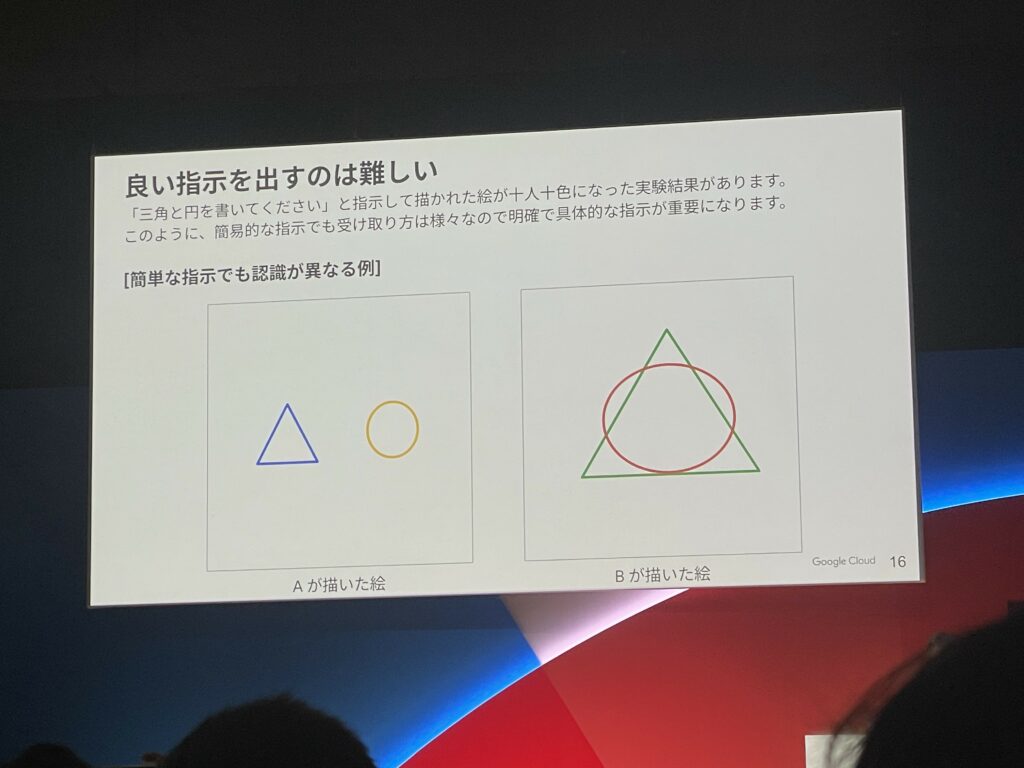
たとえば、有名な例を挙げると、「三角と円を書いてください。」という曖昧な指示を人間に与えても様々な回答が返ってくるように、具体性を持ったプロンプトでないと生成AIのポテンシャルは最大限に発揮することができません。
かといって、複雑な指示を一気に投げてしまっても期待通りの結果が得られなかった場合に原因の特定が難しくなってしまいます。
プロンプトの実装ステップ
では、どのようなステップでプロンプトの作成をしていくべきでしょうか。
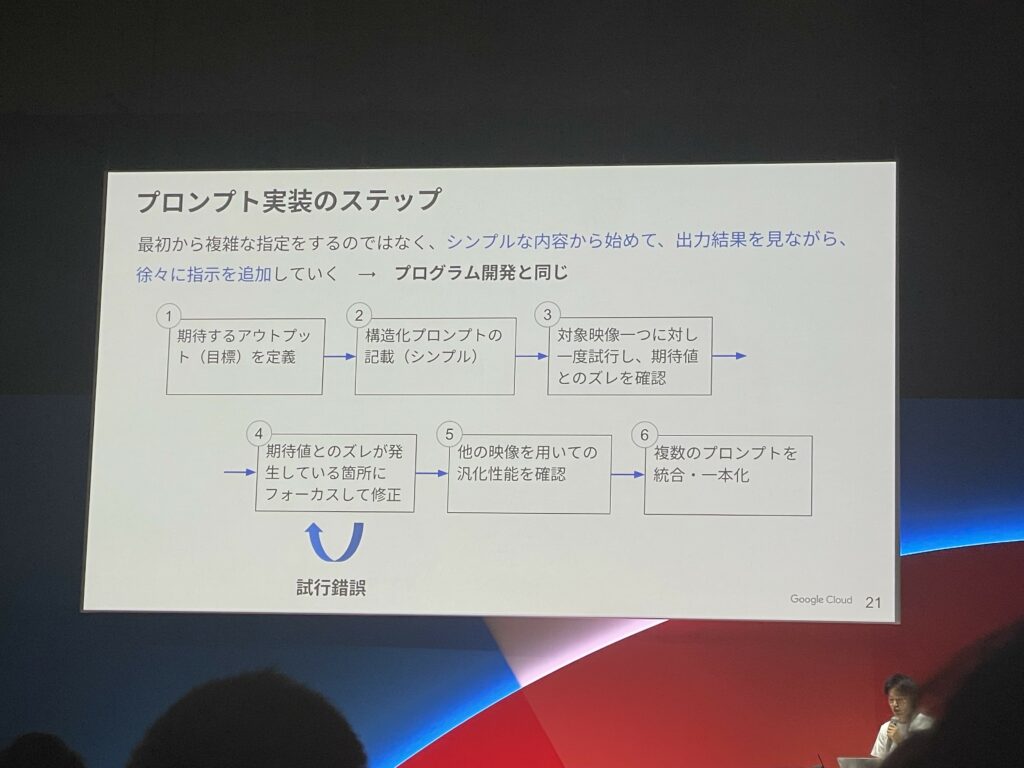
結論から言うと、最初から複雑な指示を出すのではなくシンプルかつ具体的な内容から始めていく事が効果的だそうです。
そこから徐々に指示を追加して出力結果を確認し、期待値と回答にズレが生じたタイミングでプロンプト調整をする事が重要になってきます。(画像④のステップ)
ステップ④では、動画の中で必要なシーンだけをトリミングして単体テストのような形でプロンプトの調整を繰り返す方がコスト・時間ともに効果的だそうです。
複数のタスクを解決したい場合
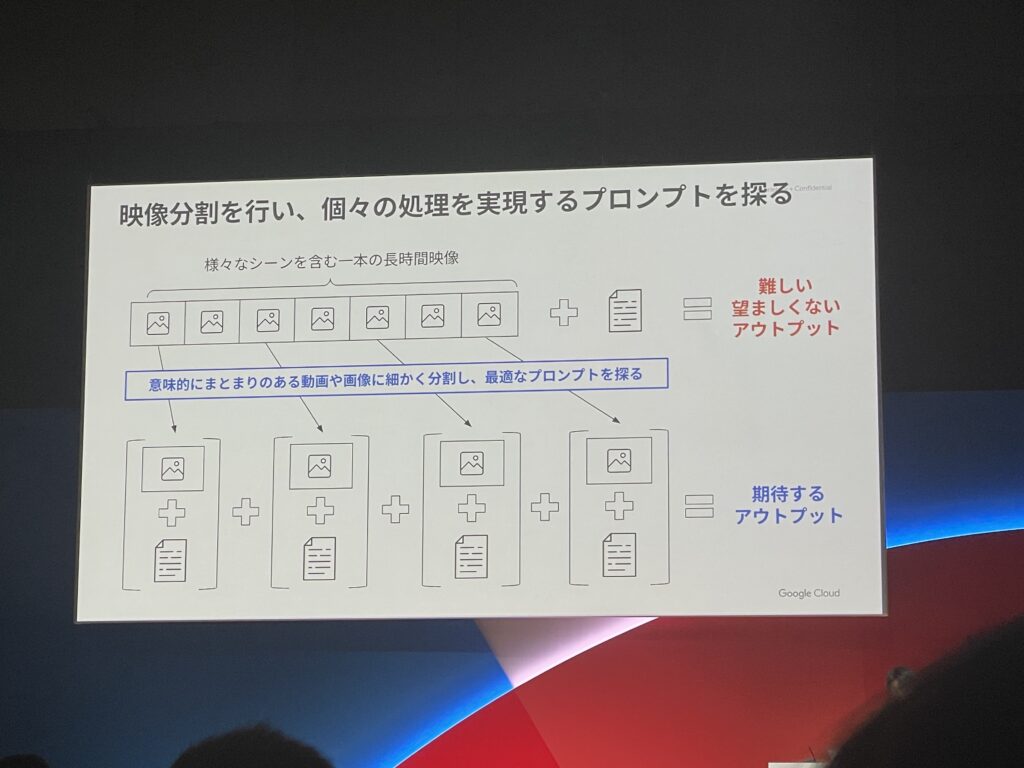
また、複数のタスクを解決したい場合、映像を意味的なまとまりで分割してから個々のまとまりに対してプロンプトを与えることも効果的だそうです。
これにより、ステップ毎に出力結果を表示させる事ができるので、どのステップで生成AIが期待値から逸れてしまったのか判断でき、プロンプト改善が容易になります。
動画ならではのプロンプト例
ここまでで、プロンプトチューニングのステップを理解する事ができました。
では、次はどのようなプロンプトが映像解析において効果的かのご説明を紹介します。
プロンプトは以下の画像のように構造化されているものが推奨されます。

実際にこの構造化プロンプトで作成した映像解析の例もご紹介してくださいました。

この例では動画をシーン毎に分割する処理と、シーンの内容を説明する処理を行っています。
プロンプトの英語の部分を和訳すると以下のようになります。(プロンプトは英語の方が精度が高いため、英語となっています。)
あなたは動画コンテンツの編集者であり、OCRの専門家です。次のタスクに取り組んでください。
[タスク]
A. 映画全体をタイムスタンプ付きでシーンに分割する
B. 各シーンについて次の情報を記述する
B-1. シーンで何が起こっているか。
B-2. 画面上の重要なテキスト。
[条件]
A. 各シーンの長さは1秒から3秒です。
良い例:00:05-00:08 / 悪い例:00:05-01:14 (タイムスタンプが1分以上飛んでいる)
B-1. 説明は2文で記述します。できるだけ詳細を含めるようにしてください。
B-2. 画面上のテキストのみを出力します。
[フォーマット指示]
日本語で。プレーンテキスト、マークダウンなし。
以下の情報のみを表示してください。
は3列のカンマ区切りリスト:mm:ss~mm:ss,B-1, B-2
ヘッダーは:Timestamp, Description, Texts
このように、明確な指示を構造化されたプロンプトに記載することで高い精度でアウトプットを得る事ができる上に、保守性も上がるといったメリットがあります。
次に、音声の文字起こしを行うケースの例になります。

プロンプトを和訳すると以下になります。
あなたはプロフェッショナルな転写者です。以下のタスクに取り組んでください。
[タスク]
A. 話者を特定して映画を転写してください。
[条件]
A. 話者は「人物A」、「人物B」、「人物C」、…のように表記します。
A. 話者にナレーターが含まれる場合、「ナレーション」と表記します。
A. 画面上のテキスト情報は使用しないでください。
[フォーマット指示]
日本語で。プレーンテキスト、マークダウンなし。
以下の情報のみを表示してください。
3列のカンマ区切りリストで出力:timestamp mm:ss~mm:ss, Person, Transcription
ヘッダーは:Timestamp, Person, Transcription
音声の文字起こしをする場合は、話者を特定させるようなプロンプトの存在が重要になる点も理解できますね。
以上の例のように、構造化された具体性のあるプロンプトが映像解析において重要であることが理解できました。
Tips
以下は、映像解析におけるTipsまとめになります。
- 動画の配置はプロンプトの前に配置する方が映像解析の精度が高い
- プロンプトは英語の方が精度が高い
- 中級レベルの平易かつ明確な表現を心がける
- プロンプトはシンプルな内容から始めて、出力結果を見ながら徐々に指示を追加していく
- 動画全てを解析させるのではなく、必要なシーンをトリミングして単体テストのようにプロンプト調整を行う
- 意味的なまとまりで動画を細かく分割し、最適なプロンプトを探る
- タイムスタンプは00:00 ~ 00:02形式で書くのが良い
- プロンプトはDON’T形式ではなく、DO形式で書く(否定系より肯定系のデータを多く学習しているため)
- 画像に対する捕捉情報をプロンプトに埋め込みたい場合は、Few-shotプロンプティングを用いる
まとめ
いかがでしたでしょうか。
私自身、映像解析のPoCを行った際に、瞬間的に画面が切り替わるシーンをGeminiが認識してくれなくてプロンプトのチューニングを必死に行った経験がありました。
今後はこのセッションで語られているように、フレームレートを落として実時間あたりのサンプリング数を増やして調整していこうと思います。
また、今回プロンプトの構造化や映像の分割などが精度に大きく影響することが分かったのでこちらも参考にしていきたいと思いました。




