
はじめに
はじめまして。
案件でAmazon OpenSearch Serviceを使う機会がありました。そのため、OpenSearch Serviceのキャッチアップも兼ねて、実際に触りながらDynamoDBからOpenSearchにデータを取り込み、検索を行う流れをOpenSearch Serviceを用いて構築してみました。
Amazon OpenSearch Serviceとは
Amazon OpenSearch Service(旧:Amazon Elasticsearch Service)は、複数のドキュメントから特定の文字列を横断的に検索するOpenSearchを簡単に構築できるサービスです。
OpenSearchはElasticsearchを基に開発されているオープンソースの検索エンジンです。大規模なデータに対して高速な検索、インデックス化、管理、視覚化を行うことができます。そのため、以下の場面などで活用できると思います。
- ECサイトで大量の商品の中から検索ワードが含まれる商品を検索する。
- 大量のログファイルから特定の文字列が含まれるログを抽出する。
メリットと注意点
AWSのマネージドサービスでもあることから、以下の特徴があります。
- 手動で管理する場合と比較してインフラ部分の管理負担を減らすことができます。さらにServerlessも利用できるため、管理負担のさらなる軽減も期待できます。
- マルチAZや自動スナップショットも対応しているため、データ損失やサービス中断時のダウンタイムを最小限に抑えることができます。
- S3やKinesis及びDynamoDBからデータをロードすることや、CloudWatchを用いたアラーム設定など他のAWSサービスと統合することもできます。
しかし、OpenSearch Serviceを利用する場合には以下の点について注意する必要があります。
- Elasticsearchの構築もできますが、ライセンスの都合上からElasticsearchはバージョン7.10までしかサポートされておらず、バージョン7.10以降は完全互換ではないことから既存環境からの移行等には注意が必要です。
リソースを立ててみる
OpenSearchクラスターであるOpenSearch Serviceドメインを構築してみます。
検証用として作成したドメインの設定値は以下の通りです。
| 設定項目名 | 値 |
|---|---|
| ドメインの作成方法 | 標準作成 |
| テンプレート | 開発/テスト |
| デプロイオプション | スタンバイが無効のドメイン |
| アベイラビリティーゾーン | 1-AZ |
| エンジン バージョン | 2.15 |
| 互換性モード | 無効 |
| データノード インスタンスファミリー | Memory optimized |
| データノード インスタンスタイプ | r7gd.medium.search |
| データノード ノードの数 | 1 |
| データノード ストレージタイプ | インスタンス |
| 専用マスターノードの有効化 | 無効 |
| カスタムエンドポイントを有効化 | 無効 |
| ネットワーク | パブリックアクセス |
| IP address type | デュアルスタックモード |
| きめ細かなアクセスコントロールを有効化 | 有効 |
| マスターユーザー | マスターユーザーの作成 (ユーザー名とパスワードを作成) |
| SAML 認証を有効化 | 無効 |
| Enable JWT authentication and authorization | 無効 |
| Amazon Cognito 認証を有効化 | 無効 |
| ドメインアクセスポリシー | きめ細かなアクセスコントロールのみを使用 |
| 暗号化 AWS KMSキーを選択する | AWS所有キーを使用する |
| オフピークウィンドウ 開始時間 | 00:00 |
| 自動調整 | オンにする |
| オフピークウィンドウ中に最適化をスケジュールする | 無効 |
| ソフトウェアの自動更新を有効にする | 無効 |
| 高度なクラスター設定 | デフォルト値 |
インスタンスファミリーやインスタンスサイズについてはマネジメントコンソール上からは一部のみ選択できることから利用できるインスタンスの種類には制限があります。また、リソースの構築は15分程度要しました。
作成したリソースを利用してみる
実際に構築したOpenSearch Serviceドメインを使ってみます。今回はDynamoDBテーブルに入れたデータを基にドメイン上のOpenSearchで検索してみたいと思います。
画面について
OpenSearch ServiceにはマネジメントコンソールとOpenSearch Dashboardsが用意されており、これらの画面から操作や管理する事ができます。
マネジメントコンソール
OpenSearch Serviceのマネジメントコンソールからはクラスターやセキュリティ設定の変更やインスタンスのヘルスチェックなど主にインフラ部分の操作ができます。
OpenSearch Dashboards
OpenSearch Dashboards(旧:Kibana)は対象データに対して視覚的に操作することができるツールです。OpenSearch Dashboardsへのリンクは以下の画像に示す通り、OpenSearch Serviceのドメイン設定画面上に記載されています。

リンクを開くと認証画面が表示されるため、ドメイン作成時に設定したマスターユーザーのIDとパスワードを入力して認証します。
DynamoDB側の準備
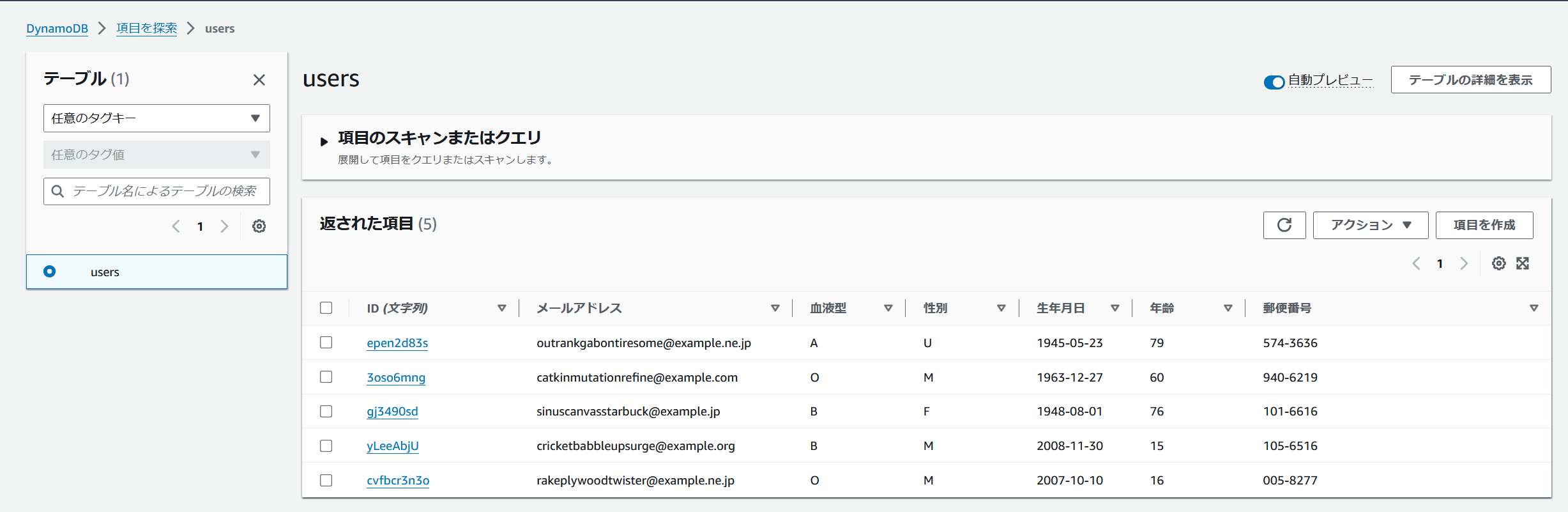
検索対象となるデータを格納する場所としてDynamoDBにテーブルを作成します。以下の画像のようなテーブルとデータを用意しました。テーブルアイテムはダミーデータです。
また、テーブルへの設定として、DynamoDBストリームとポイントインタイムリカバリ(PITR)を有効化する必要があります。
OpenSearch Service側の準備
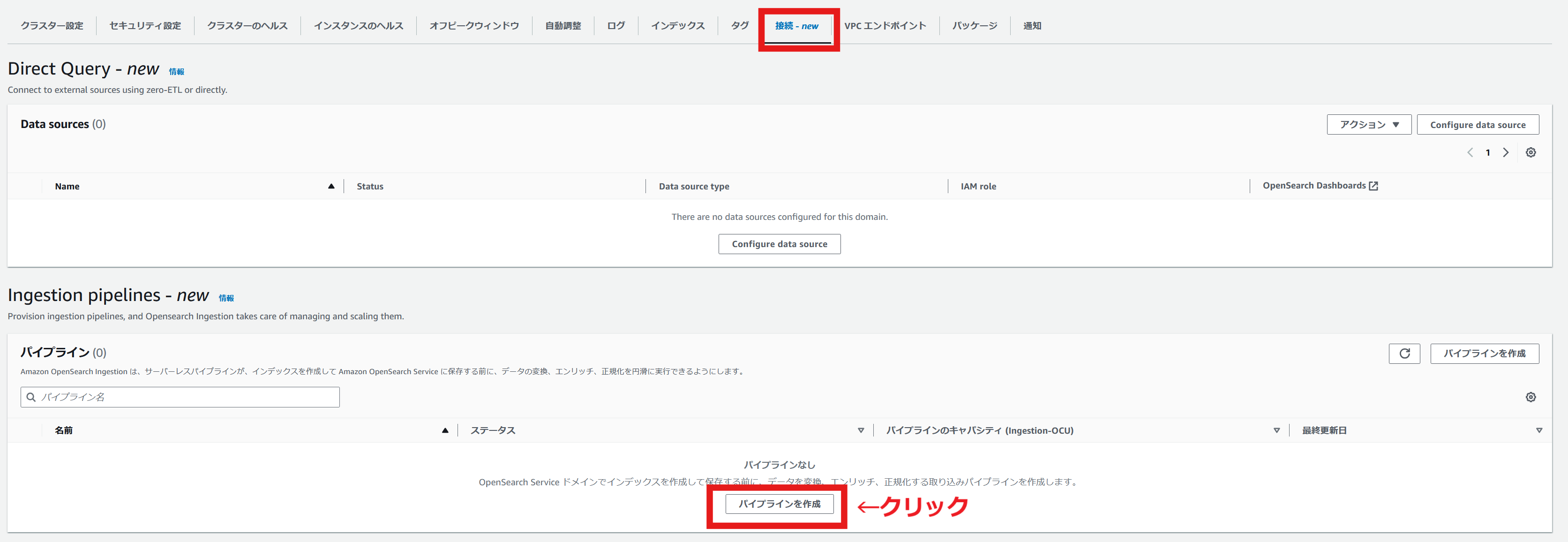
DynamoDBテーブルのデータをOpenSearchへ取り込むためにパイプラインを作成します。パイプラインの作成とDynamoDBにアクセスするために必要なIAMロール作成を行います。
IAMロールの作成
DynamoDBのデータをOpenSearch Serviceのパイプラインを通じて取り込む権限を設定するためにIAMロールを作成します。加えて、ドメインへの参照するための権限やDynamoDBからエクスポートしたデータを保管するS3バケットに対する読み書き権限も付与します。
許可ポリシーのリソースARN部分については実際に使用する環境の値に変更します。
信頼関係
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "osis-pipelines.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "OpenSearchaccess",
"Effect": "Allow",
"Action": [
"es:DescribeDomain"
],
"Resource": "arn:aws:es:{region}:{account-id}:domain/{domain名}"
},
{
"Sid": "allowRunExportJob",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:DescribeContinuousBackups",
"dynamodb:ExportTableToPointInTime"
],
"Resource": [
"arn:aws:dynamodb:{region}:{account-id}:table/{table名}"
]
},
{
"Sid": "allowCheckExportjob",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeExport"
],
"Resource": [
"arn:aws:dynamodb:{region}:{account-id}:table/{table名}/export/*"
]
},
{
"Sid": "allowReadFromStream",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeStream",
"dynamodb:GetRecords",
"dynamodb:GetShardIterator"
],
"Resource": [
"arn:aws:dynamodb:{region}:{account-id}:table/{table名}/stream/*"
]
},
{
"Sid": "allowReadAndWriteToS3ForExport",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::{bucket名}/*"
]
}
]
}
パイプラインの作成
OpenSearch ServiceのマネジメントコンソールからIngestion pipelinesからパイプラインを作成します。
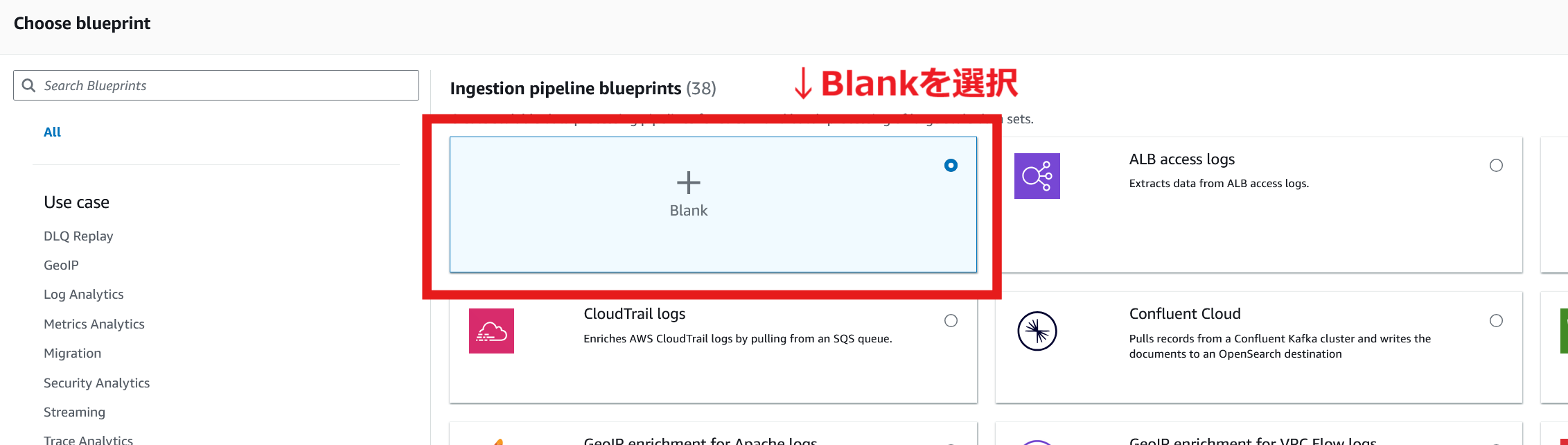
いくつかのパイプラインのテンプレートが用意されていますが、今回は「Blank」を選択します。
今回の検証では、パイプラインのキャパシティは最小1最大1、ネットワークはパブリックアクセスに設定しました。
また、パイプラインの構成は以下の通りです。S3バケット名、リージョン、OpenSearchドメインのホスト名、ARNに関しては使用する環境に合わせて値を指定します。sts_role_arnには上記で作成したIAMロールのARNを指定します。
version: "2"
cdc-pipeline:
source:
dynamodb:
tables:
- table_arn: "arn:aws:dynamodb:us-east-1:{account-id}:table/{table名}"
export:
s3_bucket: "{bucket名}"
s3_prefix: "export/"
stream:
start_position: "LATEST"
aws:
region: "{region}"
sts_role_arn: "arn:aws:iam::{account-id}:role/{IAM role名}"
sink:
- opensearch:
hosts: ["https://search-{domain名}-xxxxx.{region}.es.amazonaws.com"]
index: "users"
index_type: custom
normalize_index: true
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
region: "{region}"
sts_role_arn: "arn:aws:iam::{account-id}:role/{IAM role名}"
パイプラインが作成されると自動的にデータがOpenSearch側にも取り込まれます。うまく取り込まれていない場合はCloudWatch Logsに発行されたログを見ることでエラーの原因を探ることができます。
データ検索
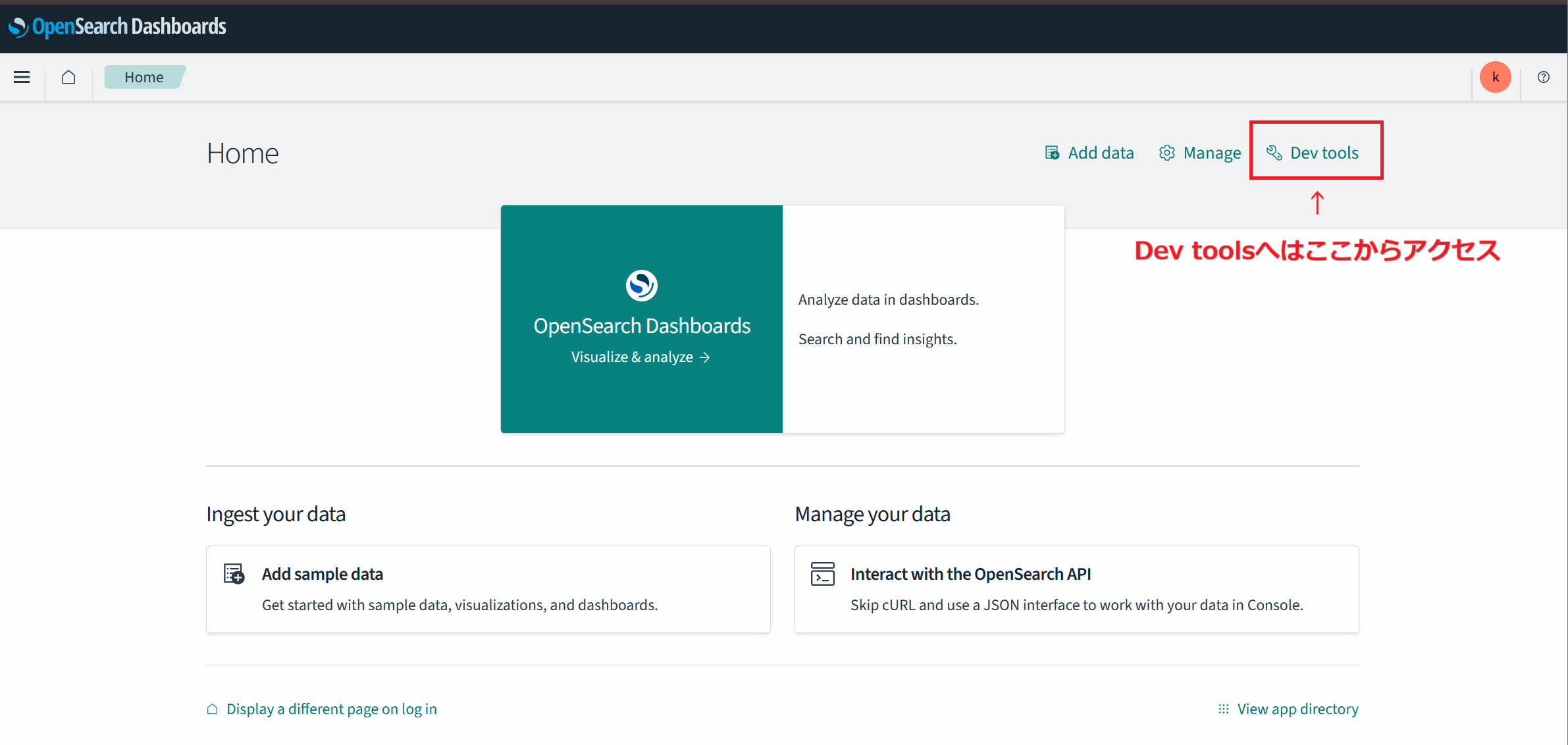
書き込まれたデータに対して検索を実行してみます。今回はOpenSearch Dashboards上でOpenSearchに対してCRUD操作ができるツールのDev toolsを用いました。
OpenSearch Dashboardsの右上にあるDev toolsをクリックして開くことができます。
Dev toolsは左側でコマンドを入力し、実行すると右側に実行結果が表示されます。
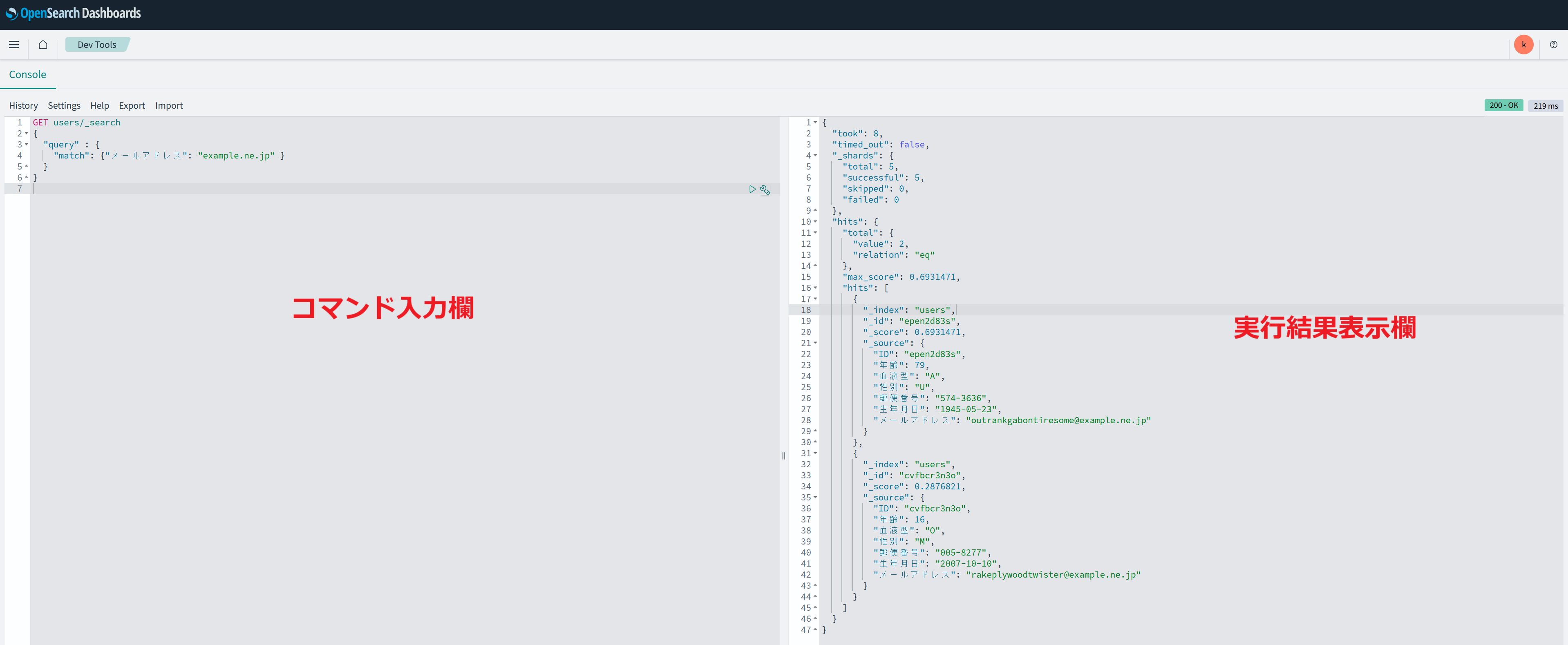
以下のコマンドを実行し、メールアドレスにexample.ne.jpが含まれているデータを検索してみます。
GET users/_search
{
"query" : {
"match": {"メールアドレス": "example.ne.jp" }
}
}
実行結果は以下の通りです。メールアドレスにexample.ne.jpが含まれているデータ2件が抽出されました。
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "users",
"_id": "epen2d83s",
"_score": 0.6931471,
"_source": {
"ID": "epen2d83s",
"年齢": 79,
"血液型": "A",
"性別": "U",
"郵便番号": "574-3636",
"生年月日": "1945-05-23",
"メールアドレス": "outrankgabontiresome@example.ne.jp"
}
},
{
"_index": "users",
"_id": "cvfbcr3n3o",
"_score": 0.2876821,
"_source": {
"ID": "cvfbcr3n3o",
"年齢": 16,
"血液型": "O",
"性別": "M",
"郵便番号": "005-8277",
"生年月日": "2007-10-10",
"メールアドレス": "rakeplywoodtwister@example.ne.jp"
}
}
]
}
}
DynamoDBテーブルにあるデータをOpenSearchで検索できる事が確認できました!
料金
ドメインに含まれるノード数とそのインスタンスサイズ、ストレージの種類と容量でコストが確定します。ノード数やインスタンスサイズを抑えることで節約できますが、性能や障害耐性とトレードオフであるため、利用用途や要件に応じて調整が必要です。
また、リザーブドインスタンスも利用することができます。OpenSearch Serviceで使用するノードは基本的に常時起動状態であり停止等ができないため、長期的に利用する予定であればリザーブドインスタンスを活用することでコスト削減が期待できます。
まとめ
今回はAmazon OpenSearch Serviceを利用してOpenSearchを利用開始するための手順や、実際にOpenSearchの使い方の基本的な内容を理解することができました。
また実際にDynamoDBテーブルにあるデータをOpenSearchで検索する手順についても確認できました。柔軟な検索ができるため、DynamoDBのクエリでは難しい検索の代替手段の1つとして利用できると思います。
これからOpenSearch Serviceを利用しようとする方の何かの役に立てばと思います。



