
はじめに
Google Cloud Next’24 での Hypercomputing に関するセッションで、インフラのデプロイで Cluster Toolkit (旧称HPC Toolkit) を使いデプロイされているという話しがありました。当該記事では Cluster Toolkit ではどのようなことができるのか、を記載していきます。
なお、この記事内では詳細なデプロイ方法に関する情報は記載しません。詳細な手順については、こちらの Google Cloud のドキュメントで説明されておりますので、そちらを御覧ください。
また、以降の内容は基本的に A3 及び A3 Mega インスタンスを対象として記載させていただいております。
※ Cluster Toolkit は随時アップデートが行われており、この記事内容は公開日時点の情報を元に記載したものとなりますので、ご了承ください。
Cluster Toolkit とは
概要
Google Cloud で HPC 関連の環境を簡易的にデプロイすることが可能な OSS の Toolkit になっております。ブループリントで必要な情報を定義し、Terraform 及び Packer を利用してインフラ環境をデプロイすることが可能です。
こちら Google Cloud のドキュメントにも記載されておりますが、以下イメージを見ていただくとわかりやすいです。
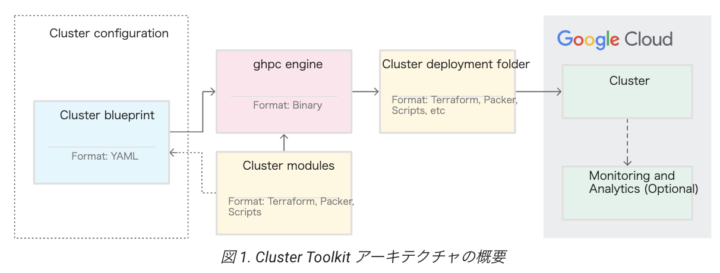
作成されるリソース
Cluster Toolkit でデプロイすると以下のリソースが作成されます。
- VPC
- GCE
- Cloud NAT
- Filestore
構成イメージは以下のとおりです。
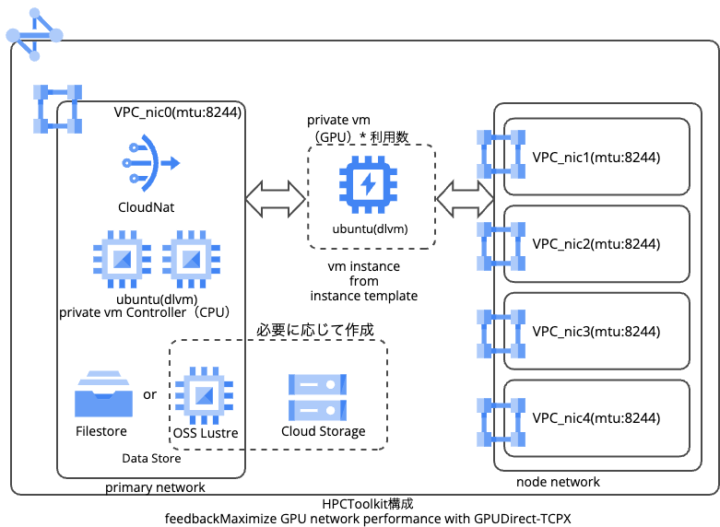
それぞれのリソースの詳細について記載します。
VPC
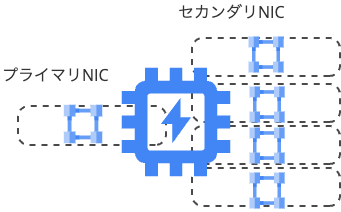
こちらはただ VPC を1つ作成するだけでなく、以下のように5つの VPC にまたがるような構成を取る必要があります。
1つをプライマリ NIC として、その他4つをセカンダリNICとして位置づけた構成をとります。
※A3 Mega の場合、セカンダリ NIC が8つとなり、帯域が倍になるような構成となります。
A3 インスタンスでは GPUDirect-TCPX と呼ばれる機能を利用することでパフォーマンスが向上します。
※A3 Mega インスタンスですと、似たような仕組みを GPUDirect-TCPXO と呼びます
GPUDirect-TCPX は Google Cloud でカスタムされた、NVIDIA のリモート ダイレクトメモリアクセス(RDMA)です。利用することにより、GPUデータ転送用に 1NIC 最大 200Gbps の帯域幅をサポートすることが可能になります。仕組みとしては、CPU と メモり を経由せずに、データを GPU メモリからネットワークインターフェースに転送が可能になり、パフォーマンスが向上します。
また、GPUDirect-TCPX に必要なミドルウェアも当該 Cluster Toolkit を利用することで、含まれた状態でインスタンスを構築することが可能となります。
GCE
GCE は以下の内容がデプロイされ、slurm を利用して、学習ジョブを制御することを前提とした構成が展開されます。
- slurm コントローラーインスタンス
- slurm ログインインスタンス
- 学習ジョブ実行インスタンス
学習ジョブ実行インスタンスが GPU インスタンスであり、今だと A3 Mega インスタンスまでサポートされています。
※Cluster Toolkit のセットアップ手順と、A3 Mega インスタンスのデプロイ手順はこちら参照ください。
OS については各種 OS を選択することが可能ですが、こちらの yaml 内に記載がある通り、詳細には Google Cloud へお問い合わせください。
Cloud NAT
インスタンスがインターネットへ出るために必要になり、こちらが構築されます。
Filestore
学習データを保存するためのストレージとして利用されます。各種オプションで Tier を選択することが可能で、HPC ワークロード向けストレージオプションを利用した、高速なストレージをデプロイすることも可能です。
Cluster Toolkit のドキュメントでオプションの選択について確認することが可能です。
また、Filestore のサービス Tier ページでサービス内容についてもご確認ください。
※もし Filestore ではないストレージをご利用したい場合、GCE 上に Lustre を構築いただいたり、DDN EXAScaler 等を構築いただくことを検討ください
纏め
Cluster Toolkit を利用することで、イチからユーザ側でインフラを構築せずとも、テンプレートで、ある程度の構成を作成することが可能であることがわかっていただけたかと思います。また、Google Cloud での HPC を行いたい場合のインフラ経験者や有識者でないと考慮しがたい、 Google Cloud 特有の GPUDirect-TCPX に必要な構成を含めて設定されていたり、 必要なミドルウェアがインストールが行われるなど、そういった部分も行き届いており、別クラウド等で HPC を今まで利用されていたり、学習を素早く始めたい人にとっては嬉しいと感じる機能でした。
今回ご紹介したような構成でご利用になられる場合はもちろんですが、異なるストレージを利用したい場合などであればパラメータの変更でマウントするときのオプションを変更したりと、ブループリント内で補完できる部分もありますので、インフラデプロイ前に、イメージした構成のどこまでが Cluster Toolkit で実現できるか、をご確認いただき、すべてでなくても、自身で手動で構築する部分以外を効率的に進めるような方法でご利用いただくのも良いかと思いました。
また、GPU インスタンスの利用のあたり、以前記載したような予約やDWSを利用したインスタンス確保が必要となりますので、そちらは注意いただければと思います。



