
はじめに
本記事ではAurora(PostgreSQL)をナレッジベースのベクトルストアとして使用する方法についてご紹介します。
Knowledge Bases for Amazon BedrockでPostgreを採用するケース
Knowledge Bases(以下ナレッジベース)では、以下のベクトルストアが選択可能です。
- Amazon OpenSearch Serverless
- Amazon Aurora
- Pinecone
- Redis Enterprise Cloud
- MongoDB Atlas
デフォルトではAmazon OpenSearch Serverlessが選択されますが、コスト面を考慮してAmazon AuroraやPineconeなどの他の選択肢を検討する場合もあります。
以下は、2024年9月9日時点(バージニア北部リージョン)のAmazon OpenSearch Serverlessの料金表です。
| リソースタイプ | 料金 |
|---|---|
| OpenSearch Compute Unit (OCU) – インデックス作成 | USD 0.24 1 OCU 1 時間あたり |
| OpenSearch Compute Unit (OCU) – 検索とクエリ | USD 0.24 1 OCU 1 時間あたり |
| マネージドストレージ | USD 0.024 1 ヶ月あたりの GB あたり |
Amazon Aurora (PostgreSQL) のコスト
Amazon Aurora(PostgreSQL)の場合、最小構成ではOpenSearchよりもコストが抑えられる可能性があります。
Aurora PostgreSQLの料金例は以下の通りです(2024年9月14日時点、バージニア北部リージョン)。
| コンポーネント | Aurora Standard | Aurora I/O 最適化 |
|---|---|---|
| ストレージ料金 | USD 0.10/毎月の GB あたり | USD 0.225/毎月の GB あたり |
| I/O 料金 | USD 0.20/100万リクエスト | 利用料に含まれる |
Data API コスト
| リクエスト数 (月間) | 価格 (100万リクエスト毎) |
|---|---|
| 最初の 10 億件のリクエスト | USD 0.35 |
| 10 億件を超えるリクエスト | USD 0.20 |
ただし、これは最小構成時の例であり、利用状況に応じてコストは変動します。
場合によっては、PineconeやRedisなど他のベクトルデータベースのほうがコスト効率が良い場合もあるため、用途に応じた比較が必要です。
それでは、Auroraを作成し、ナレッジベースに設定していきます。
Aurora(PostgreSQL)の作成
まずはAuroraのPostgreSQLを作成します。(普通のAurora or Serverless v2 どちらも選択可能)
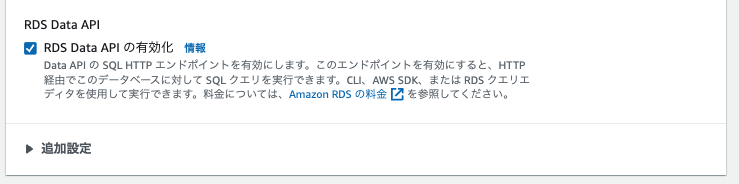
ここでRDS Data APIを有効化することを忘れないでください。
Aurora DBクラスターの作成が完了したら、PostgreSQLの中に入ってpgvector拡張機能をインストールします。
CREATE EXTENSION IF NOT EXISTS vector;
ナレッジベース用のテーブルを作成します。
CREATE SCHEMA test_schema;
Bedrock がデータベースのクエリに使用できるロールを作成します。
パスワードは文字列のため、シングルクォーテーションで囲う必要があるので注意です。
CREATE ROLE bedrock_user WITH PASSWORD '任意のパスワード' LOGIN
スキーマに対する権限を付与します。
GRANT ALL ON SCHEMA test_schema to bedrock_user;
以下のカラムを持つテーブルを作成します。
もしS3に配置したファイルにメタデータを付与していた場合は、そのメタデータのカラムを持ったカラムも作成します。(ここではtest_dataを追加しています)
vectorの値に関してはこの後、作成するナレッジベースに合わせる必要があります。
CREATE TABLE test_schema.bedrock_kb (id uuid PRIMARY KEY, embedding vector(1024), chunks text, metadata json, test_data text);
コサイン演算子を使用してインデックスを作成します。
CREATE INDEX ON bedrock_integration.bedrock_kb USING hnsw (embedding vector_cosine_ops);
またはpgvector 0.6.0 以降であれば、以下コマンドでインデックスを作成します。
CREATE INDEX ON bedrock_integration.bedrock_kb USING hnsw (embedding vector_cosine_ops) WITH (ef_construction=256);
ナレッジベース作成
Bedrockのナレッジベースから、作成したPostgreSQLの内容を入力してぽちぽち作成するだけ。


同期する
ナレッジベースが作成できたら、データソースを選択して同期を開始します。
同期が完了したら完成です。
※ナレッジベースの同期は止められないので注意

おわり
Amazon Aurora (PostgreSQL) は、OpenSearchに比べてコストを抑える可能性がありますが、用途や構成に依存します。ベクトルデータベースの選択は、使用シナリオと機能要件を考慮した上で判断することが重要です。詳細な料金や最新情報については、公式ドキュメントをご参照ください。
おまけ
当たり前ですが、Auroraを止めているとレスポンスは取得できません。

