
はじめに
Mitsuoです、最近朝が寒すぎて起きるのに時間がかかります。
担当案件でAmazon Managed Streaming for Apache Kafka(以降Amazon MSK)に触れる機会がありました。
経験者に刺さる内容ではないのですが、Amazon MSKの概要説明とお試しで構築する記事を書いてみました。
もし興味があればご覧になってください。
対象読者
以下のような方が対象です。
- Amazon MSKを触ったことがない
- Apache Kafkaの概要を知りたい
- ざっくりと構築方法を知りたい
Amazon MSKとは?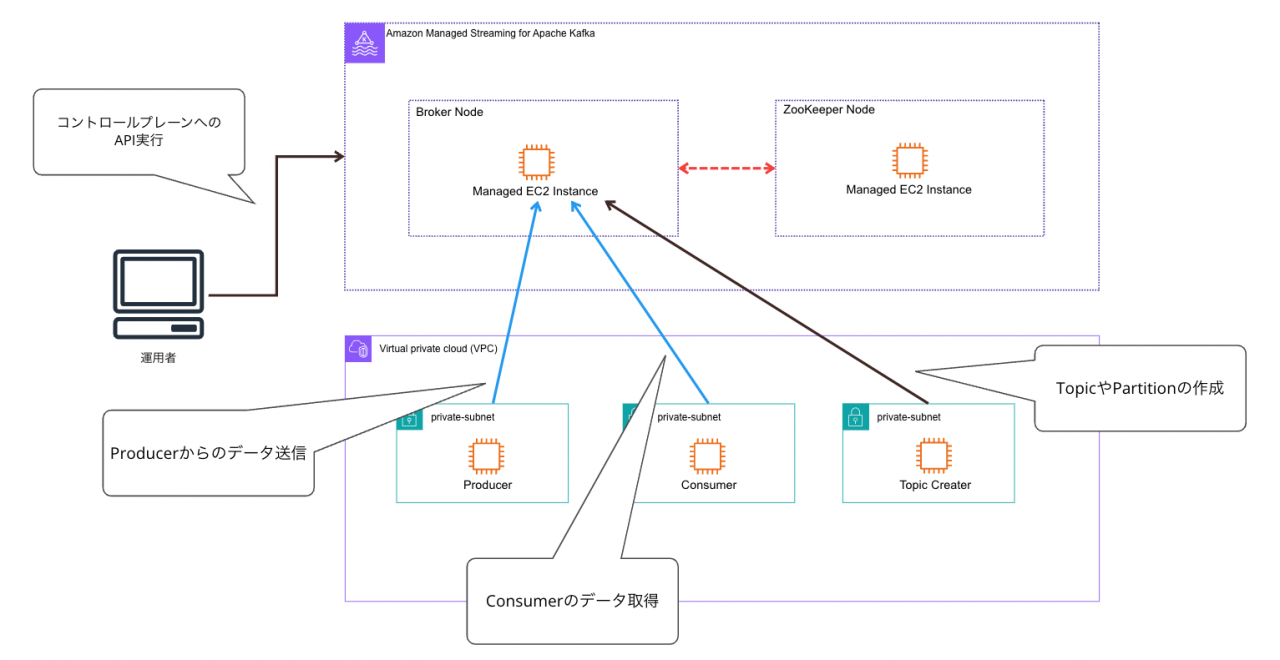
Amazon MSKは、一言で言うとフルマネージド型のApache Kafkaサービスです。
コントロールプレーンを提供し、API経由で作成、変更、削除が出来ます。
利用者はApach Kafkaにおけるクラスター管理をAWSに移譲する事が出来ます。
Apache Kafkaと互換性があり、既存のアプリケーション、ツールをそのまま利用できる特徴があります。
また大きなポイントとして、実際のクラスターはAWSが所有するVPC上に格納され、ユーザのVPC上にはそこにアクセスするためのENIが作成されます。

上記図ではApache Kafka特有のワードが登場していますが、以降の説明で解説します。
Apach Kafkaとは?
Apache KafkaはLinkedIn社が開発した分散メッセージングキューシステムで、現在はオープンソース化されています。
ストリームデータと呼ばれる制限なく発生するログデータ、IoTデータ、SNSのクリックデータなどを中継し、それらのデータを処理、後続のシステムに流すことが出来ます。
コンポーネント
Amazon MSKを利用する上で、Apach Kafkaの構成要素を把握する事は特に重要です。
以下に簡単な図を用意しました。
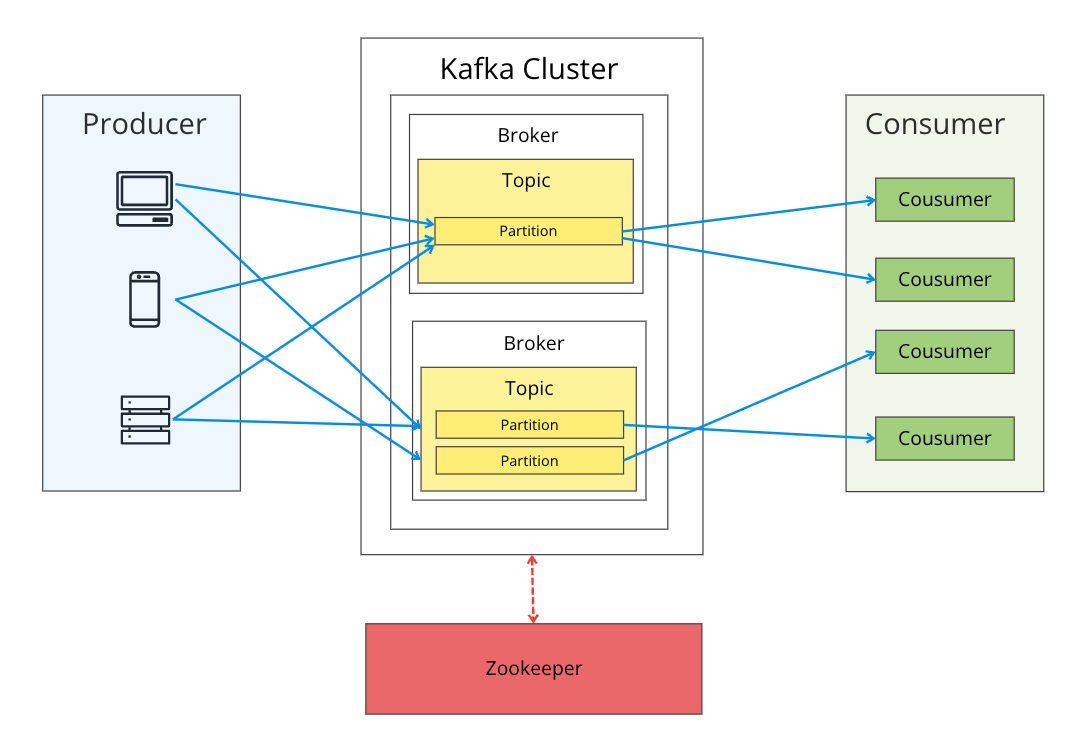
Apache Kafkaはクラスター内でデータの受配信を担う複数のブローカーサーバを起動させ、可用性やメッセージの耐障害性(冗長性)を担保します。
ブローカーだけで仕組みが完結する訳ではなく、データを送るProducer、データを受け取るConsumerで構成されます。
上記図の青矢印がデータの流れです。ブローカーに中継しますが、闇雲にデータを受けている訳ではなく、メッセージ種別によって受け取り先が変わります。
そのメッセージ種別によって論理的に保管先を分けるリソースがTopicです。かつ、そのTopic内に実際にデータをキューイングするリソースがPartitionです。
データ冗長化の仕組み
下図に整理しました。
Kafka Serverというのが上述したブローカーサーバを指します。
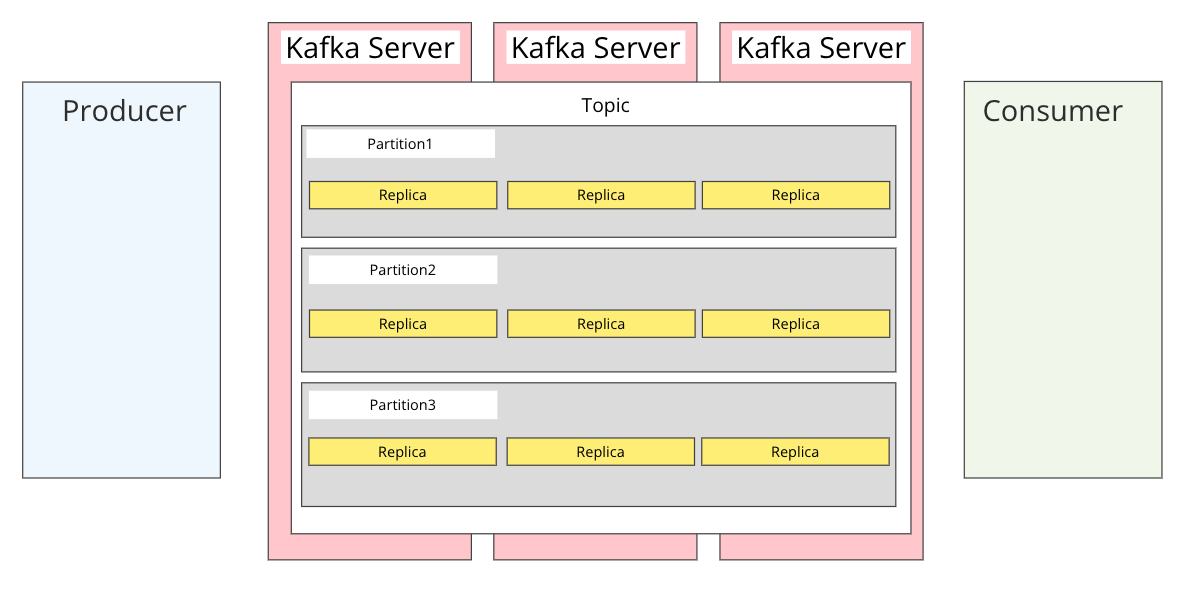
Apache Kafkaでは複数のブローカーサーバを起動させつつ、メッセージングデータの消失を防ぐための仕組みがあります。
Partitionの中にあるReplicaが実際のデータだと思ってください。Partitionはブローカーサーバにまたがる形で配置され、それぞれのブローカーサーバ毎にReplicaが作成されます。
この仕組みによってデータの耐障害性を担保することが出来ます。
また、ReplicaにはLeader ReplicaとFollower Replicaの2種類があります。
Leader ReplicaがパーティションにおけるWriterの役割を担い、Producerからのデータ送信先はLeader Replicaになります。
Leader Replicaは受け取ったデータをFollower Replicaに同期します。
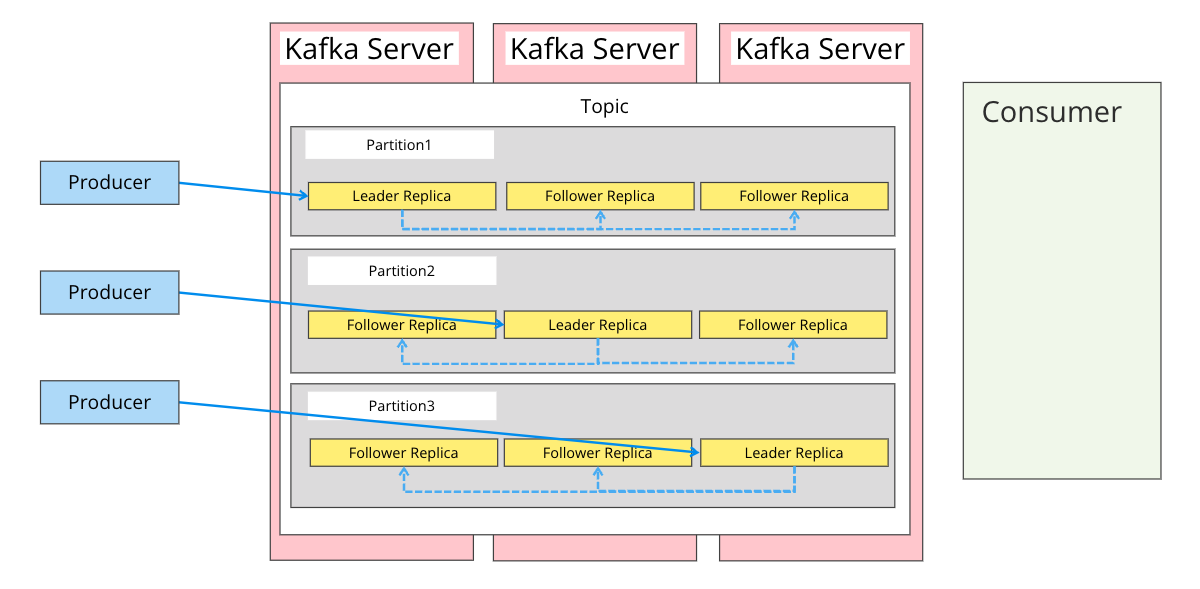
補足として、Replicaの中からLeader Replicaを選出するのはzookeeperが担っています。
Amazon MSKがマネージド化する範囲
以下3点です。
- Kafka Cluster
- Broker
- Zookeeper
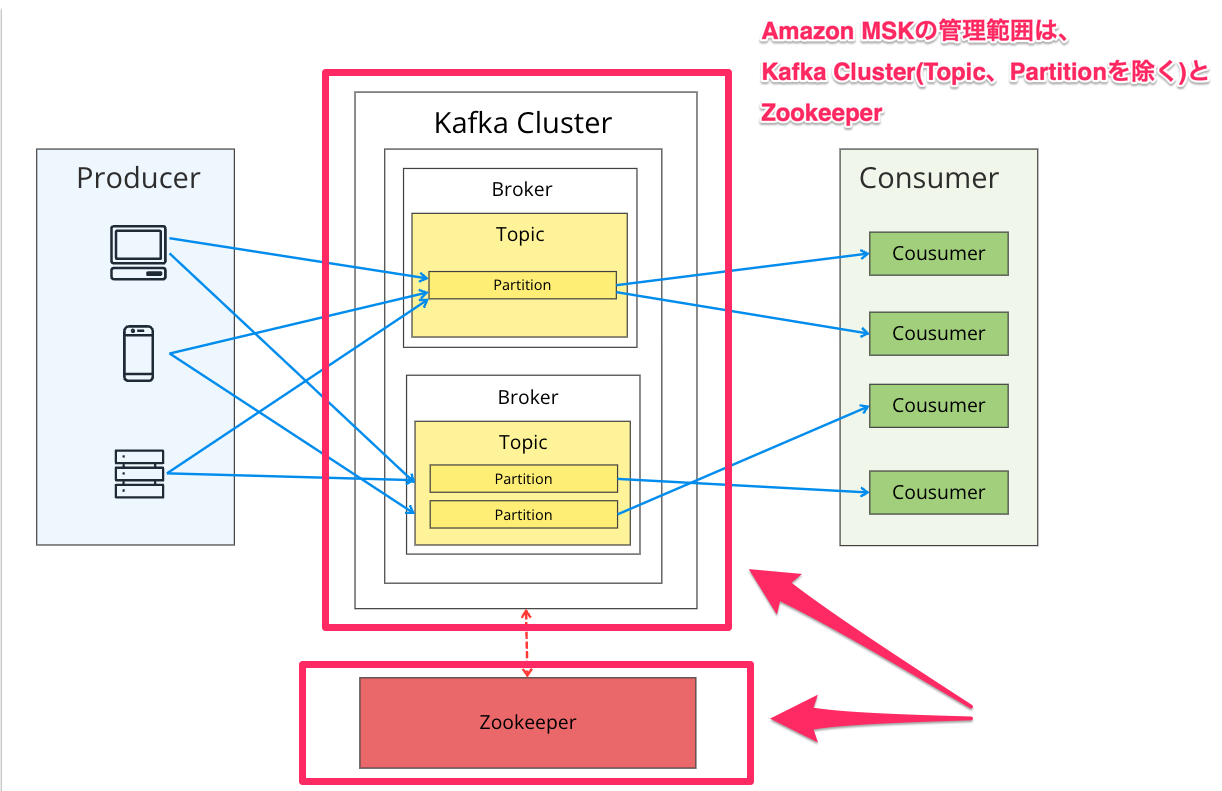
注意点として、Amazon MSKはKafka Cluster、Brokerまで作成しますが、Topic、Partitionは作成してくれません。
利用者にて別途作成する必要があります。
実際に試してみる
事前作業
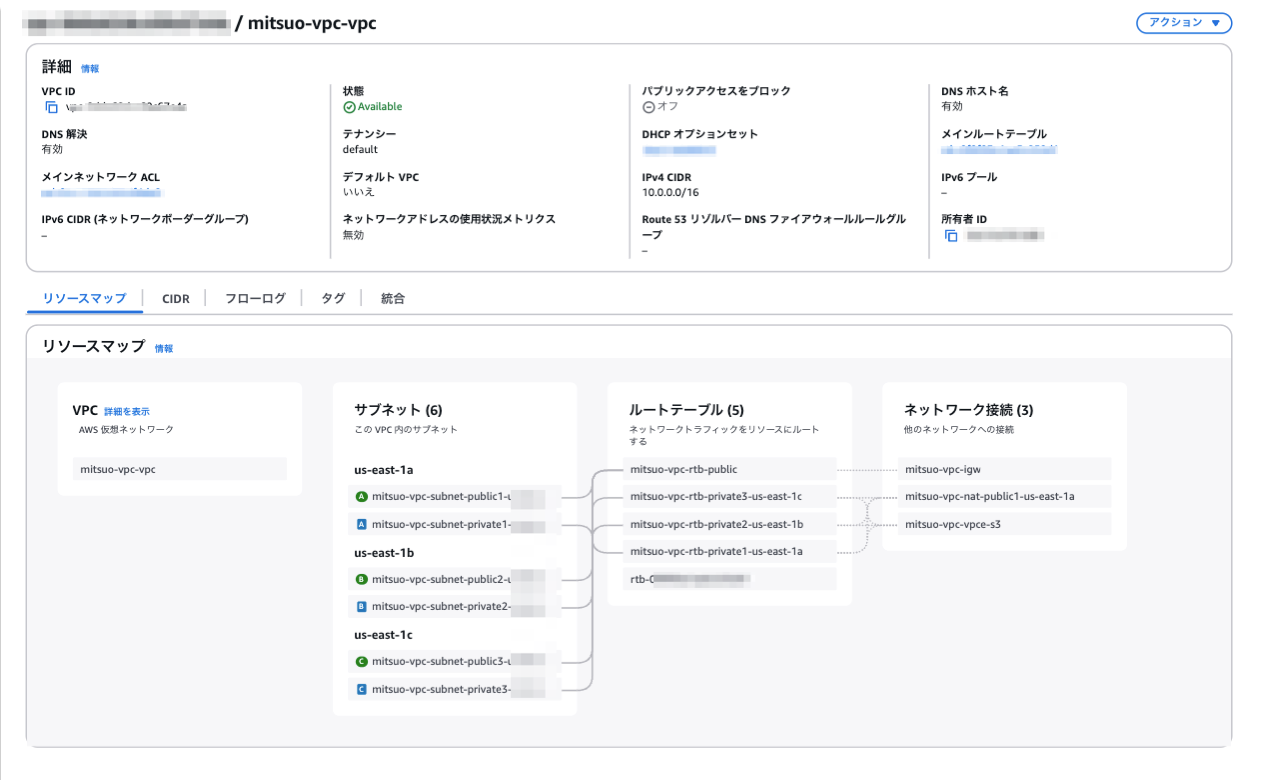
Amazon MSKクラスターを配置するVPCネットワークを作成します。
3AZで構築します。
Amazon MSKはプライベートサブネットのみで起動しますが、同VPC内にKafkaクライアントを動かすEC2を立て、外部から必要となるパッケージ等を取得するためパブリックサブネットやNAT Gatewayを立てています。
次にMSK、EC2(Producer、Topic作成など)にアタッチするSecurity Groupを作成します。
例:MSK用(EC2からのアクセスのみに制限)、クライアントからブローカー接続の際に指定するTLS通信の可否によってポート番号が変わります。
例:EC2用(SSMアクセス想定でアウトバウンドはフル開放)
Amazon MSK構築
各項目を選択、入力し画面を進めます。
| 項目 | 値 | 備考 |
|---|---|---|
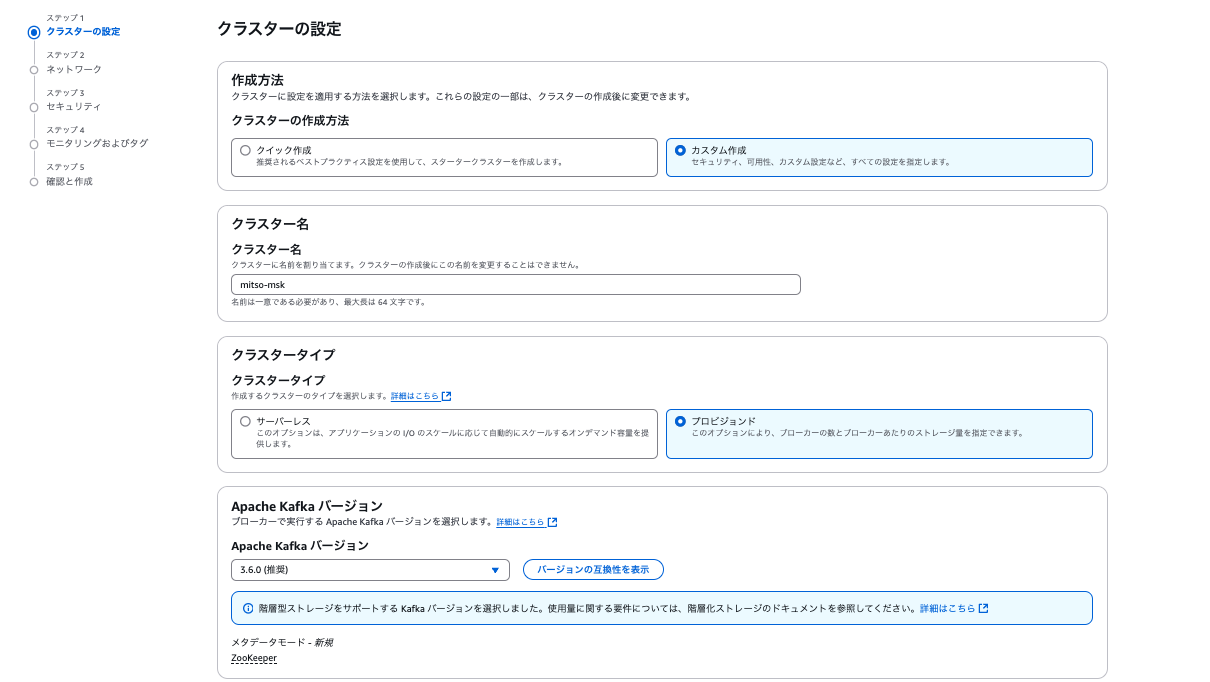
| クラスターの作成方法 | カスタム作成 | パラメータのカスタマイズが可能 |
| クラスター名 | 任意のクラスター名を入力 | |
| Apache Kafka バージョン | 3.6.0 | 執筆時点の推奨verを利用 |
| 項目 | 値 | 備考 |
|---|---|---|
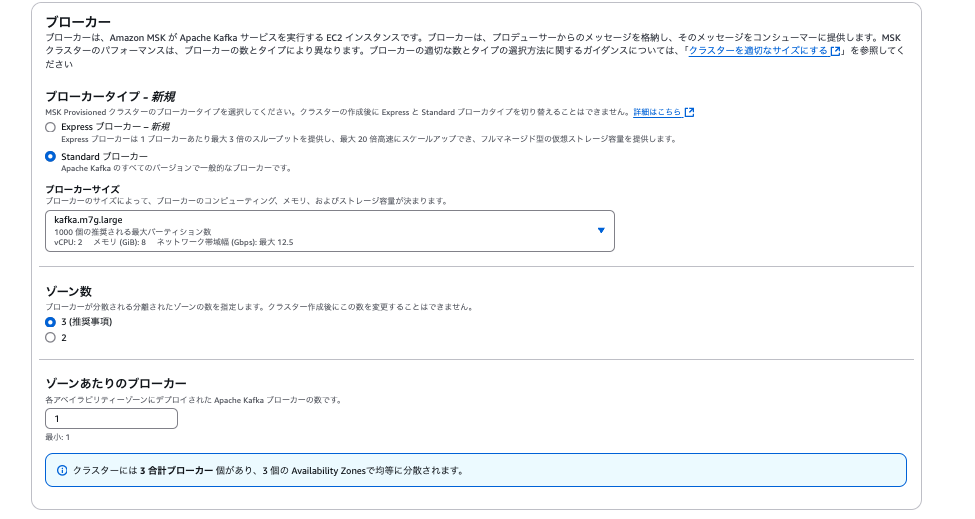
| ブローカータイプ | Standardブローカー | ブローカーサイズは任意のサイズを指定 |
| ゾーン数 | 3 | |
| ゾーンあたりのブローカー | 1 | 任意のブローカー数を指定可能、ブローカーの合計数はゾーン数と当設定値の積になる |
| 項目 | 値 | 備考 |
|---|---|---|
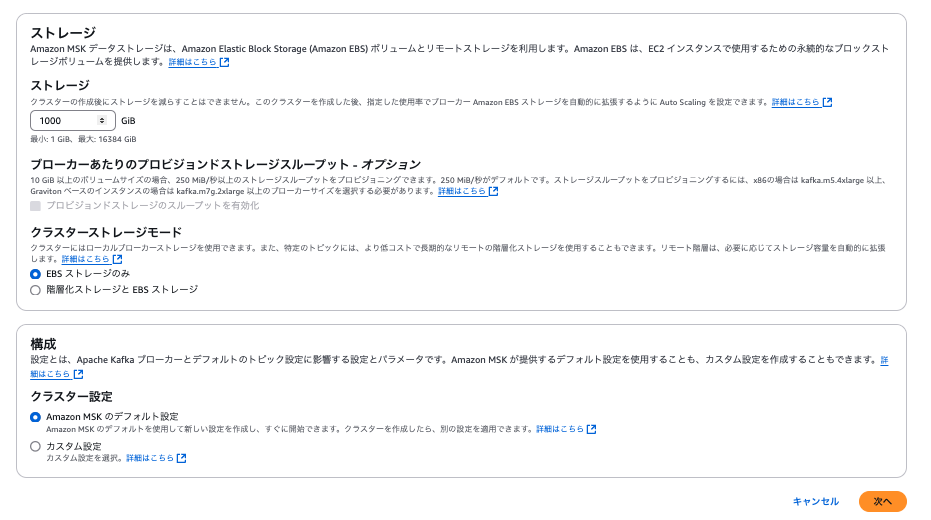
| ストレージ | 1,000 | GiB単位 |
| クラスターストレージモード | EBS ストレージのみ | |
| クラスター設定 | Amazon MSK のデフォルト設定 | Amazon RDSでいうパラメータグループの設定値、Kafkaクラスターに関する細かい設定変更が可能 |
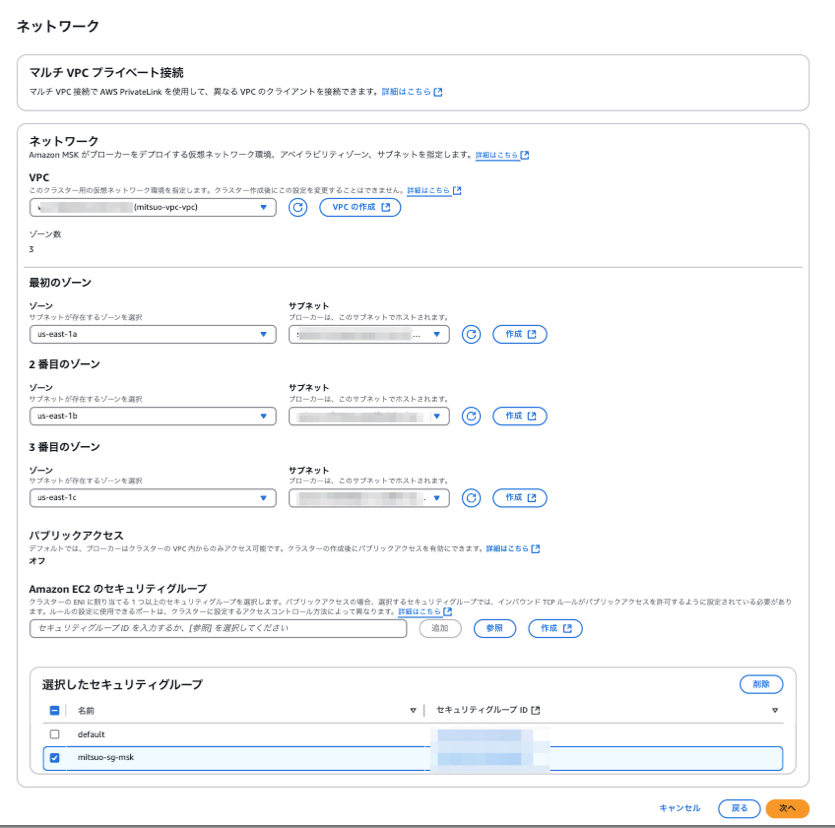
事前作業で作成したVPC及びサブネット、セキュリティグループを指定します。
| 項目 | 値 | 備考 |
|---|---|---|
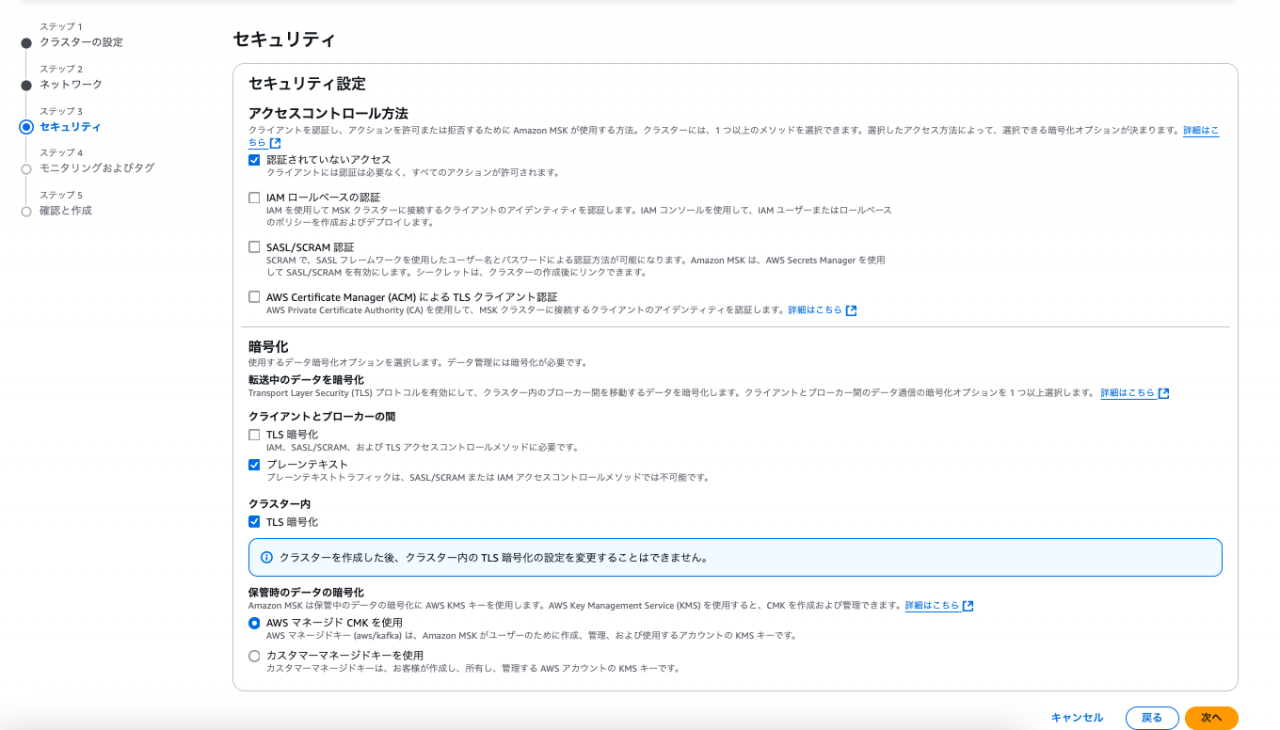
| アクセスコントロール方法 | 認証されていないアクセス | IAM認証の場合は、TLS暗号化か強制される |
| クライアントとブローカーの間 | プレーンテキスト | |
| クラスター内 | TLS 暗号化 | |
| 保管時のデータの暗号化 | AWS マネージド CMK を使用 |
| 項目 | 値 | 備考 |
|---|---|---|
| Amazon CloudWatchメトリクス | 基本モニタリング | トピック単位のメトリクスを出力したい場合は選択可能 |
| Prometheusによるオープンモニタリング | 設定しない | Prometheusを用いた詳細な監視をしたい場合に利用可能 |
| ブローカーログの配信 | 設定しない | CWLogs、S3、DataFirehoseに向けてログの送出が可能 |
| クラスタータグ | 任意のタグを入力 |
クラスター構築が始まった時点は以下の様な画面になります。
クライアントインスタンスの作成
Kafkaクラスター、ブローカーにアクセスするためのインスタンスと関連リソースを作成します。
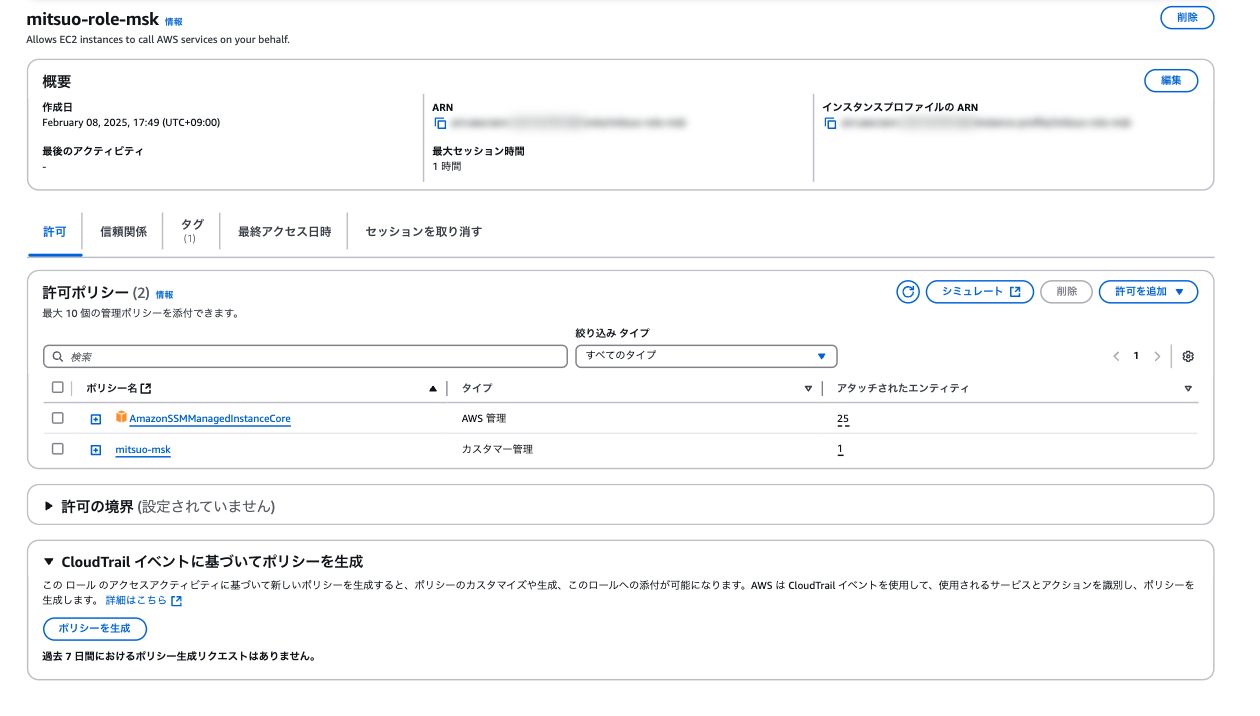
IAMポリシー、ロールの作成
まずはIAMリソースの準備です。
IAMポリシーは以下を設定します。
region、Account-ID、MSKTutorialClusterが可変になので構築する環境、リソースに応じて変更してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeCluster"
],
"Resource": [
"arn:aws:kafka:region:Account-ID:cluster/MSKTutorialCluster/*"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:*Topic*",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": [
"arn:aws:kafka:region:Account-ID:topic/MSKTutorialCluster/*"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": [
"arn:aws:kafka:region:Account-ID:group/MSKTutorialCluster/*"
]
}
]
}
EC2のロールを別途作成し、AWS管理ポリシーのAmazonSSMManagedInstanceCoreと上記で作成したポリシーをアタッチします。
EC2の作成
以下情報を参考に作成してください。
| 項目 | 値 | 備考 |
|---|---|---|
| AMI | Amazon Linux 2 AMI (HVM) – Kernel 5.10, SSD Volume Type | |
| インスタンスタイプ | t2.micro | |
| キーペア | 指定しない | SSM経由でアクセスするため不要です |
ネットワーク、Security Group、IAMプロファイルは前手順で作成したものを指定します。
EC2インスタンスは、MSKにアクセスできるプライベートサブネットであればどこでもよいです。
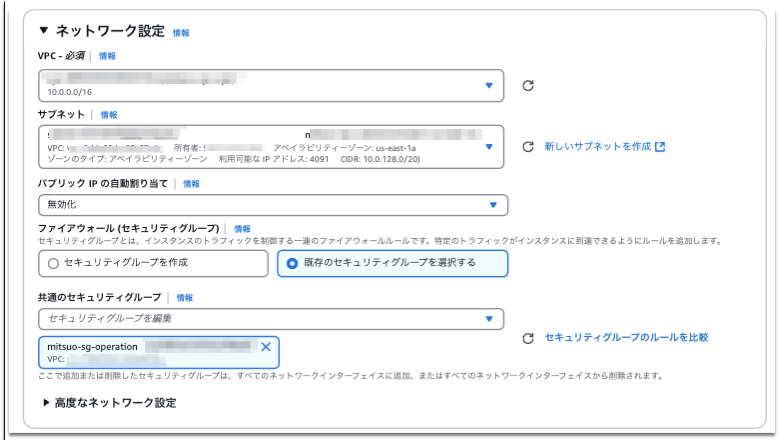
クライアントのセットアップ
SSMでEC2にアクセスし、以下コマンドを実行します。
Apache KafkaのバージョンによってURLパスが変わります。検証では3.6.0バージョンを指定します。
コマンドで指定している値について、著者が検証した際に指定しているものですので、参考にされる際は、適宜置き換えてください。
Javaのインストール
sudo yum -y install java-11
Apache Kafkaのダウンロード
sudo wget https://archive.apache.org/dist/kafka/3.6.0/kafka_2.13-3.6.0.tgz
ファイル展開
sudo tar -xzf kafka_2.13-3.6.0.tgz
パス移動し、JARファイルの取得、以下コマンドを実行することでクライアントからKafkaクラスターにアクセス可能
cd /usr/bin/kafka_2.13-3.6.0/libs sudo wget https://github.com/aws/aws-msk-iam-auth/releases/download/v1.1.1/aws-msk-iam-auth-1.1.1-all.jar
コマンドの成功時の最終行は以下の様なものが出力されます。
2025-02-09 14:17:19 (93.5 MB/s) - ‘aws-msk-iam-auth-1.1.1-all.jar’ saved [12417891/12417891]
また、クライアントの認証方法を指定する設定ファイルが必要なため、/usr/bin/kafka_2.13-kafka_2.13-3.6.0/bin配下に
client.propertiesという名前で作成します。今回は認証設定がないのでプレーンテキストであること明記します。
sudo sh -c 'echo "security.protocol=PLAINTEXT" > client.properties' cat client.properties security.protocol=PLAINTEXT
Topic、Partitionの作成
次にTopicとPartitionを作成してみます。
MSKのクラスター画面に戻り、クライアントの情報の表示をクリックします。
ブローカー毎に接続先のエンドポイントが確認できました。カンマ区切りになっています。
今回は頭に「1」がついているエンドポイントを使います。
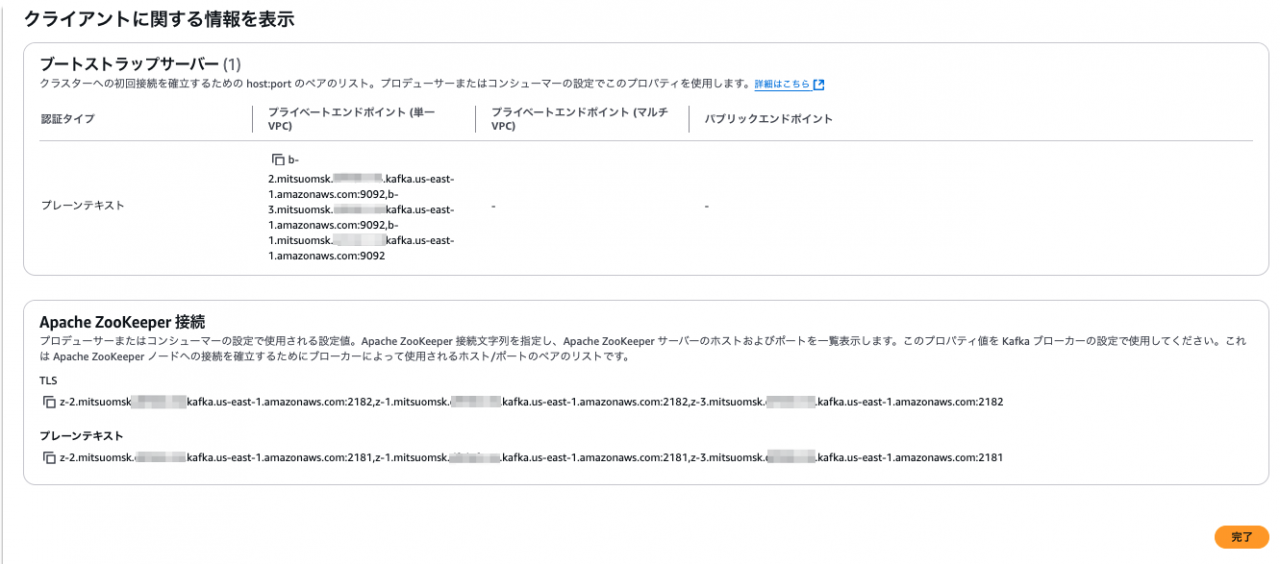
SSMのプロンプト画面に戻ります。
上記の手順で進めると、/usr/bin/kafka_2.13-3.6.0/binにKafkaクライアントで用いるsh群が配置されています。
クライアントはこのshを駆使して様々なアクションを行います。
cd /usr/bin/kafka_2.13-3.6.0/bin ls -la total 180 drwxr-xr-x 3 root root 4096 Sep 29 2023 . drwxr-xr-x 7 root root 105 Sep 29 2023 .. -rwxr-xr-x 1 root root 1423 Sep 29 2023 connect-distributed.sh -rwxr-xr-x 1 root root 1396 Sep 29 2023 connect-mirror-maker.sh -rwxr-xr-x 1 root root 963 Sep 29 2023 connect-plugin-path.sh -rwxr-xr-x 1 root root 1420 Sep 29 2023 connect-standalone.sh -rwxr-xr-x 1 root root 861 Sep 29 2023 kafka-acls.sh -rwxr-xr-x 1 root root 873 Sep 29 2023 kafka-broker-api-versions.sh -rwxr-xr-x 1 root root 871 Sep 29 2023 kafka-cluster.sh -rwxr-xr-x 1 root root 864 Sep 29 2023 kafka-configs.sh -rwxr-xr-x 1 root root 945 Sep 29 2023 kafka-console-consumer.sh -rwxr-xr-x 1 root root 944 Sep 29 2023 kafka-console-producer.sh -rwxr-xr-x 1 root root 871 Sep 29 2023 kafka-consumer-groups.sh -rwxr-xr-x 1 root root 959 Sep 29 2023 kafka-consumer-perf-test.sh -rwxr-xr-x 1 root root 882 Sep 29 2023 kafka-delegation-tokens.sh -rwxr-xr-x 1 root root 880 Sep 29 2023 kafka-delete-records.sh -rwxr-xr-x 1 root root 866 Sep 29 2023 kafka-dump-log.sh -rwxr-xr-x 1 root root 877 Sep 29 2023 kafka-e2e-latency.sh -rwxr-xr-x 1 root root 874 Sep 29 2023 kafka-features.sh -rwxr-xr-x 1 root root 865 Sep 29 2023 kafka-get-offsets.sh -rwxr-xr-x 1 root root 867 Sep 29 2023 kafka-jmx.sh -rwxr-xr-x 1 root root 870 Sep 29 2023 kafka-leader-election.sh -rwxr-xr-x 1 root root 874 Sep 29 2023 kafka-log-dirs.sh -rwxr-xr-x 1 root root 881 Sep 29 2023 kafka-metadata-quorum.sh -rwxr-xr-x 1 root root 873 Sep 29 2023 kafka-metadata-shell.sh -rwxr-xr-x 1 root root 862 Sep 29 2023 kafka-mirror-maker.sh -rwxr-xr-x 1 root root 959 Sep 29 2023 kafka-producer-perf-test.sh -rwxr-xr-x 1 root root 874 Sep 29 2023 kafka-reassign-partitions.sh -rwxr-xr-x 1 root root 885 Sep 29 2023 kafka-replica-verification.sh -rwxr-xr-x 1 root root 10884 Sep 29 2023 kafka-run-class.sh -rwxr-xr-x 1 root root 1376 Sep 29 2023 kafka-server-start.sh -rwxr-xr-x 1 root root 1361 Sep 29 2023 kafka-server-stop.sh -rwxr-xr-x 1 root root 860 Sep 29 2023 kafka-storage.sh -rwxr-xr-x 1 root root 956 Sep 29 2023 kafka-streams-application-reset.sh -rwxr-xr-x 1 root root 863 Sep 29 2023 kafka-topics.sh -rwxr-xr-x 1 root root 879 Sep 29 2023 kafka-transactions.sh -rwxr-xr-x 1 root root 958 Sep 29 2023 kafka-verifiable-consumer.sh -rwxr-xr-x 1 root root 958 Sep 29 2023 kafka-verifiable-producer.sh -rwxr-xr-x 1 root root 1714 Sep 29 2023 trogdor.sh drwxr-xr-x 2 root root 4096 Sep 29 2023 windows -rwxr-xr-x 1 root root 867 Sep 29 2023 zookeeper-security-migration.sh -rwxr-xr-x 1 root root 1393 Sep 29 2023 zookeeper-server-start.sh -rwxr-xr-x 1 root root 1366 Sep 29 2023 zookeeper-server-stop.sh -rwxr-xr-x 1 root root 1019 Sep 29 2023 zookeeper-shell.sh
以下のコマンドを実行します。
これは、ブローカーサーバにTopicとPartitionを作成するコマンドです。
レプリケーション係数が3のため、Leader ReplicaとFollower Replicaのセットが生成されます。
–bootstrap-serverオプションの値に、上述したブローカーサーバのエンドポイントを指定しています。
pwd
/usr/bin/kafka_2.13-3.6.0/bin
sudo ./kafka-topics.sh --create --bootstrap-server {エンドポイント名} --command-config client.properties --replication-factor 3 --partitions 1 --
Created topic testtopic.
メッセージの送信
パスは変えずに以下のコマンドを実行します。
これはkafkaクライアントがProducer機能を起動させるshファイルを実行しています。
sudo ./kafka-console-producer.sh --broker-list {エンドポイント名} --producer.config client.properties --topic testtopic
>が出力されるとメッセージが入力できる状態です。

文字列を入力、Enterボタンを押下を繰り返します。
ありきたりな文字を入れてみました。

メッセージが送信されたかどうかを確認してみましょう。
以下のコマンドはConsumer側からメッセージを確認するものです。
cd /usr/bin/kafka_2.13-3.6.0/bin
sudo ./kafka-console-consumer.sh --bootstrap-server {エンドポイント名} --consumer.config client.properties --topic testtopic --from-beginning
ohayou
honmassuka
benkyouninarimasu
問題なく取得できましたね!

最後に
Amazon MSKの概要説明から実際にKafkaクライアントを使ってデータを送信するところまで確認しました。
内容は入門者向けですが、Amazon MSKの学習の足かがりになれば幸いです。
参考資料
Apache Kafka
Amazon Managed Streaming for Apache Kafka AWS Black Belt Online Seminar
Get started using Amazon MSK
当記事のハンズオンはディベロッパーガイドのチュートリアルを参考に、若干修正した手順で記載しています。

