
DX開発事業部の西田です。
BigQuery MLでは、SQLクエリを使用して、BigQueryに格納したデータからMLモデルの作成と予測の実行を機械学習の知識がなくても簡単に行えます。
本記事では時系列モデルの作成・学習(ARIMA_PLUSとARIMA_PLUS_XREGを利用)とモデルを使った予測(Forecast)を行う手順を紹介します。
単変量時系列モデル(ARIMA_PLUS)での予測
まずは単一の値の履歴値に基づいて予測ができるARIMA_PLUSを使う手順です。
テーブルの作成、データ登録
時系列の売上データを格納するためのテーブルを作成し、売上データを登録します。
-- データセットを作成
CREATE SCHEMA IF NOT EXISTS `my_forecast`;
-- 時系列データ用テーブル作成
CREATE OR REPLACE TABLE `my_forecast.sales_history` (
month DATE,
sales INT64
);
-- サンプルデータを挿入
INSERT INTO `my_forecast.sales_history` (month, sales) VALUES
('2024-01-01', 500),
('2024-02-01', 550),
('2024-03-01', 600),
('2024-04-01', 650),
('2024-05-01', 680),
('2024-06-01', 660),
('2024-07-01', 720),
('2024-08-01', 730),
('2024-09-01', 770),
('2024-10-01', 800),
('2024-11-01', 810),
('2024-12-01', 830);
単変量時系列モデルの作成・学習
ARIMA_PLUSモデルを使ってモデルを作成、学習を行います。
CREATE OR REPLACE MODEL `my_forecast.sales_forecast_model` OPTIONS ( MODEL_TYPE='ARIMA_PLUS', -- モデル TIME_SERIES_TIMESTAMP_COL='month', -- 時間のカラム TIME_SERIES_DATA_COL='sales', -- 予測対象値のカラム DATA_FREQUENCY='MONTHLY', -- 頻度(月次) AUTO_ARIMA=TRUE -- ARIMAのパラメータは自動設定 ) AS SELECT month, sales FROM `my_forecast.sales_history`;
学習が完了すると、モデルが作成されます。
作成した単変量時系列モデルを使って未来の値を予測
次の6ヶ月分の売上を予測して、既存のデータとともに時系列に並べてみます。
-- 既存のデータ
SELECT
timestamp(month) AS month,
sales AS predicted_sales,
sales AS lower_bound,
sales AS upper_bound
FROM `my_forecast.sales_history`
UNION ALL
-- 予測されたデータ
SELECT
forecast_timestamp AS month, -- 予測された月
forecast_value AS predicted_sales, -- 予測された売上値
prediction_interval_lower_bound AS lower_bound, -- 90%信頼区間下限
prediction_interval_upper_bound AS upper_bound -- 90%信頼区間上限
FROM
ML.FORECAST(MODEL `my_forecast.sales_forecast_model`,
STRUCT(6 AS horizon, -- 未来何ヶ月分予測するか(今回は6ヶ月先)
0.9 AS confidence_level)) -- 信頼区間の範囲(0.9 = 90%)
ORDER BY month; -- 月の昇順で並べる
信頼区間(Confidence Interval:CI)とは、統計学において「推定した値がどのくらいの範囲に収まるか」を示す指標です。
言い換えると「実際の値が、ある一定の確率(例えば90%や95%)で収まると予測される範囲」となります。
つまり予測値が1,000円であり信頼区間が90%なら「90%の確率で実際の売上は950円〜1,050円の間に収まるだろう」ということです。
このようにデータが取得できました。
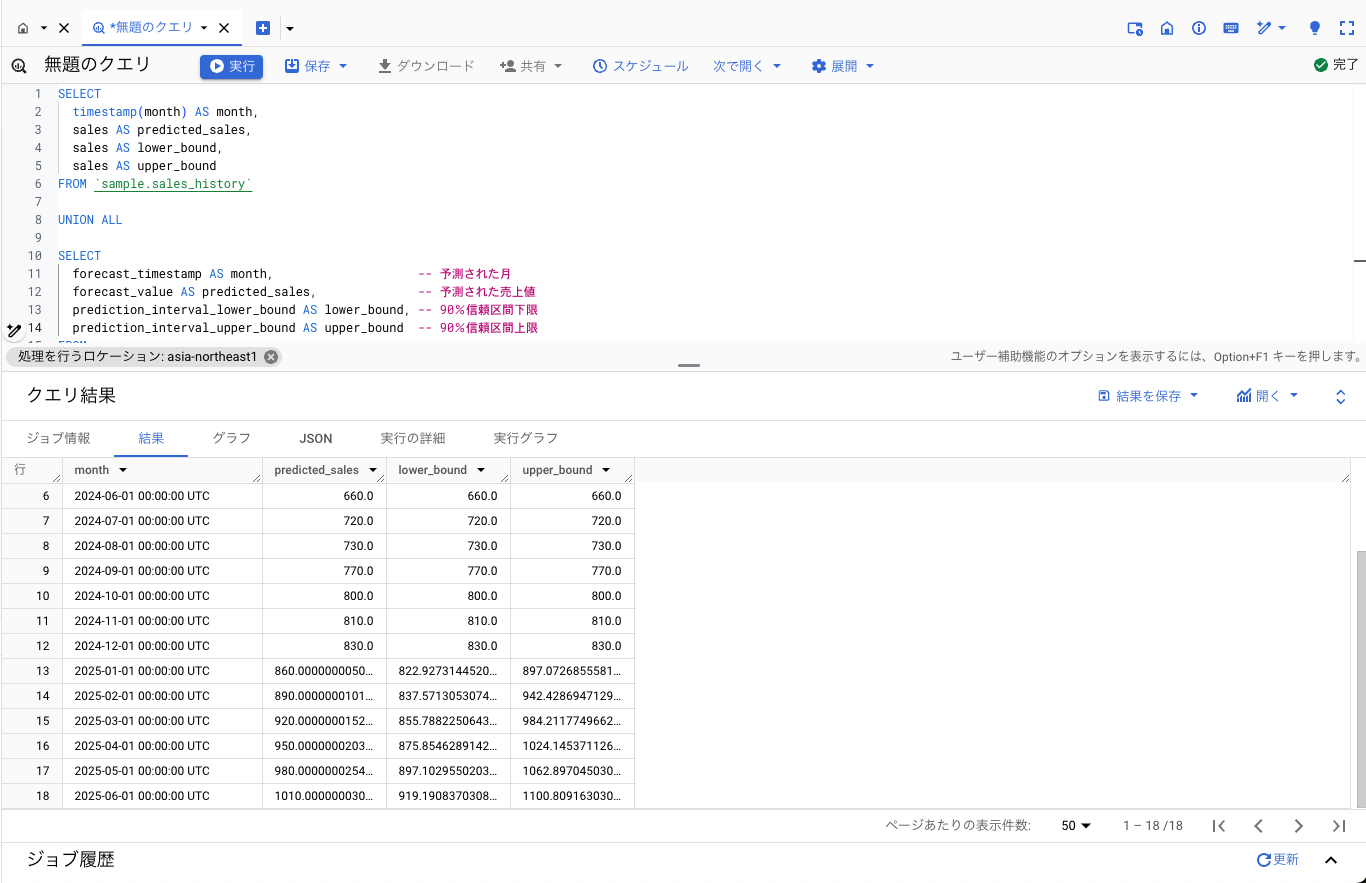
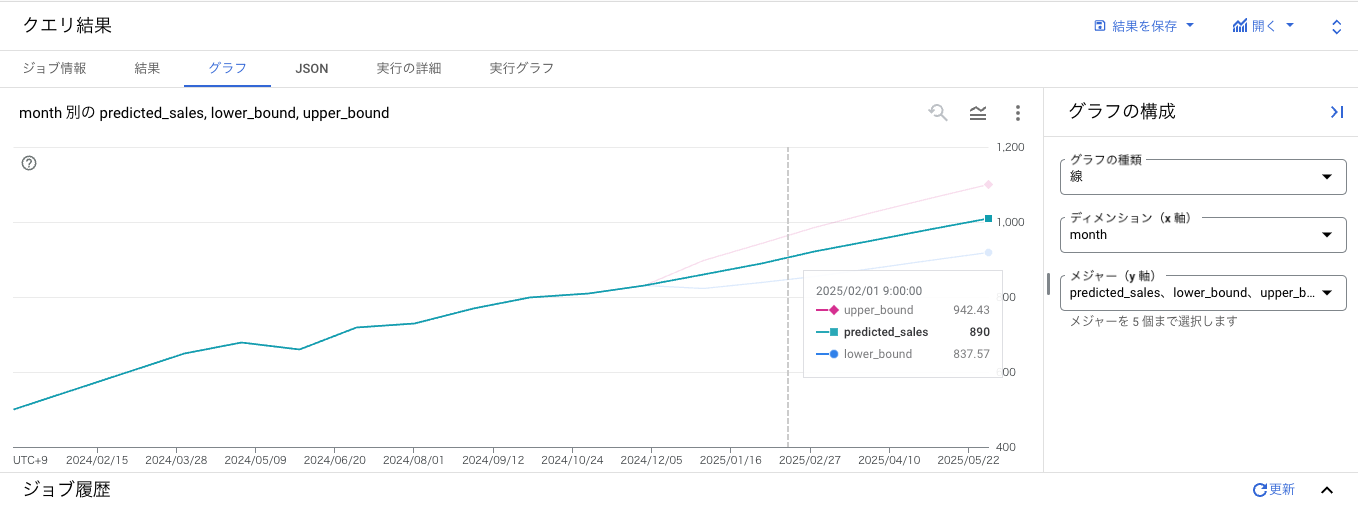
簡単にBigQuery Studio上で時系列線グラフにすることもできます。
多変量時系列モデル(ARIMA_PLUS_XREG)での予測
単一の履歴値だけではなく、複数の説明変数を含むデータに基づいて将来の予測を行いたい場合はARIMA_PLUS_XREGを利用します。
テーブルの作成、データ登録
CREATE OR REPLACE TABLE my_forecast.sales_with_external_factors AS
SELECT DATE('2024-01-01') AS month, -- 月
500 AS sales, -- 売上(予測ターゲット)
100 AS ad_spend, -- 広告費(説明変数1)
0 AS event -- イベント開催有無(説明変数2、0または1のフラグ)
UNION ALL
SELECT DATE('2024-02-01'), 550, 120, 1 UNION ALL
SELECT DATE('2024-03-01'), 600, 130, 0 UNION ALL
SELECT DATE('2024-04-01'), 650, 150, 1 UNION ALL
SELECT DATE('2024-05-01'), 680, 160, 0 UNION ALL
SELECT DATE('2024-06-01'), 660, 170, 0 UNION ALL
SELECT DATE('2024-07-01'), 720, 180, 1 UNION ALL
SELECT DATE('2024-08-01'), 730, 200, 0 UNION ALL
SELECT DATE('2024-09-01'), 770, 220, 1 UNION ALL
SELECT DATE('2024-10-01'), 800, 230, 0 UNION ALL
SELECT DATE('2024-11-01'), 810, 250, 1 UNION ALL
SELECT DATE('2024-12-01'), 830, 270, 0;
多変量時系列モデルの作成・学習
ARIMA_PLUS_XREGモデルを使ってモデルを作成、学習を行います。
CREATE OR REPLACE MODEL my_forecast.sales_xreg_model OPTIONS ( MODEL_TYPE='ARIMA_PLUS_XREG', -- モデル TIME_SERIES_TIMESTAMP_COL='month', -- 時間のカラム TIME_SERIES_DATA_COL='sales', -- 予測対象値のカラム DATA_FREQUENCY='MONTHLY', -- 頻度(月次) AUTO_ARIMA=TRUE -- ARIMAのパラメータは自動設定 ) AS SELECT month, sales, ad_spend, event FROM my_forecast.sales_with_external_factors;
作成した多変量時系列モデルを使って未来の値を予測
次の6ヶ月分の売上を予測して、既存のデータとともに時系列に並べます。
このとき多変量時系列モデルの場合は説明変数の予測値もモデルに渡す必要があります。このため別途説明変数の予測も事前に行う必要があることに注意が必要です。
-- 既存のデータ
SELECT
timestamp(month) AS month,
sales AS predicted_sales,
sales AS lower_bound,
sales AS upper_bound
FROM `my_forecast.sales_with_external_factors`
UNION ALL
-- 予測されたデータ
SELECT
forecast_timestamp AS month, -- 予測された月
forecast_value AS predicted_sales, -- 予測された売上値
prediction_interval_lower_bound AS lower_bound, -- 90%信頼区間下限
prediction_interval_upper_bound AS upper_bound -- 90%信頼区間上限
FROM ML.FORECAST(
MODEL `my_forecast.sales_xreg_model`,
STRUCT(6 AS horizon, -- 未来何ヶ月分予測するか(今回は6ヶ月先)
0.9 AS confidence_level), -- 信頼区間の範囲(0.9 = 90%)
(
SELECT DATE('2025-01-01') AS month, 280 AS ad_spend, 1 AS event UNION ALL
SELECT DATE('2025-02-01'), 300, 0 UNION ALL
SELECT DATE('2025-03-01'), 320, 1 UNION ALL
SELECT DATE('2025-04-01'), 340, 0 UNION ALL
SELECT DATE('2025-05-01'), 360, 1 UNION ALL
SELECT DATE('2025-06-01'), 380, 0
)
)
ORDER BY month; -- 月の昇順で並べる
単変量時系列モデルの予測値よりも単調な予測ではなくなっており、説明変数が予測値に影響を与えていることがわかります。
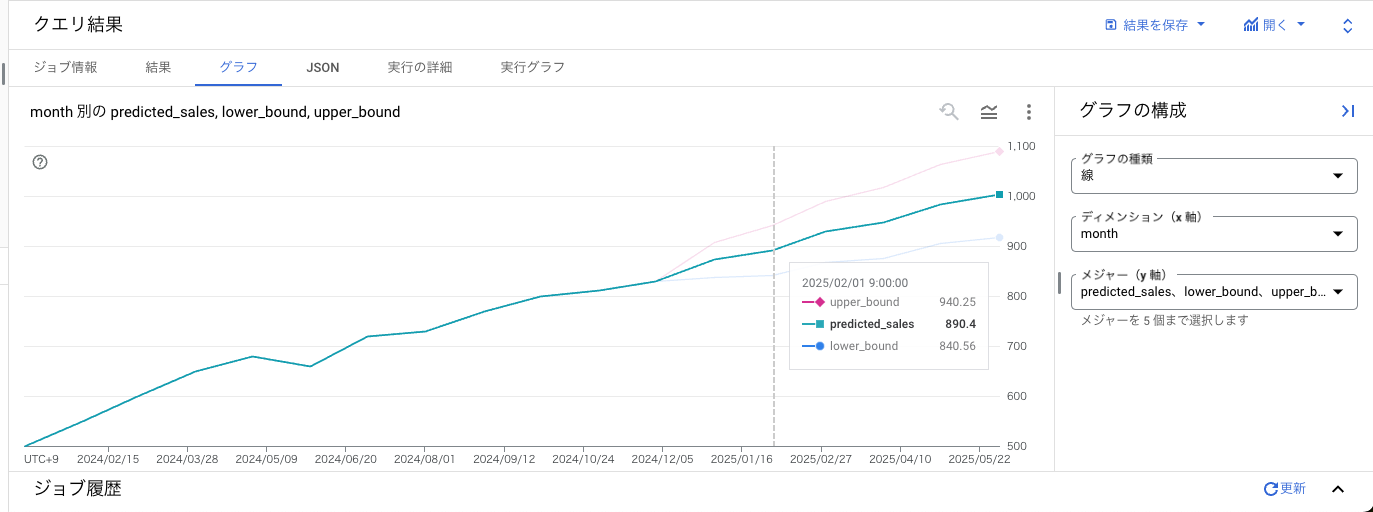
実際の運用ではモデルの再学習と、説明変数の用意を検討する必要がありますが、必要なデータをBigQueryに集めることさえできれば簡単にモデルの学習と将来値予測が行えます。


