
はじめに
Google Cloud の Gemini には、ファインチューニングを実行できる機能があります。
テキスト、画像、音声、ドキュメントのデータをチューニング可能です。
チューニングを行うメリットとして、以下が挙げられます。
- 特定のタスクの品質が向上する
- モデルの堅牢性が向上する
- プロンプトが短くなるため、推論のレイテンシとコストが低減される
プロンプトとチューニングの特徴の違い
| 特徴 | チューニング | プロンプト設計(推論) |
|---|---|---|
| 目的 | モデルの重みを更新し、特定のタスクやドメインに特化させる。 | モデルの入力(プロンプト)を工夫することで、既存のモデルから望ましい出力を引き出す。 |
| データの必要性 | 大量のラベル付きデータが必要(通常100サンプル以上)。 | 少量、またはラベルなしデータでも可能。ラベル付きデータが少ない場合に有効。 |
| リソース | 計算リソースと時間が必要。 | 比較的少ないリソースで実行可能。迅速なプロトタイピングに適している。 |
| 適したタスク | ・複雑で、高度なプロンプト設計だけでは対応が難しいタスク。 ・特定のドメインや構文への深い理解が必要なタスク。 | ・明確な指示で対応できるタスク。 ・一般的な知識や推論能力を活用できるタスク。 |
| カスタマイズ性 | 高い。モデル自体をカスタマイズできる。 | 中程度。プロンプトの工夫によって出力を調整する。 |
| パフォーマンス | 特定のタスクで高いパフォーマンスを発揮する可能性。 | プロンプトの品質に依存する。 |
要約すると:
- チューニング: モデル自体を根本的に変える(より専門家にする)
- プロンプト設計: 既存のモデルに上手く指示を出す(より良い質問をする)
ファインチューニングしてみる
今回は入力された文章をひらがなに変換するようにファインチューニングしてみたいと思います。
データセットの準備
JSONL形式のファイルをCloud Storageにアップロードします。
roleのuserのtextフィールドでユーザーからの入力を
roleのmodelのtextフィールドでGeminiの出力を
記載したデータセットを作成します。
{"contents": [{"role": "user", "parts": [{"text": "今日は良い天気ですね。"}]}, {"role": "model", "parts": [{"text": "きょうはよいてんきですね。"}]}]}
{"contents": [{"role": "user", "parts": [{"text": "明日は雨が降るかもしれません。"}]}, {"role": "model", "parts": [{"text": "あしたはあめがふるかもしれません。"}]}]}
最適な結果を得るには、100個のサンプルが必要とのことですが、今回は30個のサンプルで学習させます。
学習データ同様に検証データも用意します。
検証データは必須ではないですが、チューニングの効果を測定するのに役立ちます。
チューニングを実行
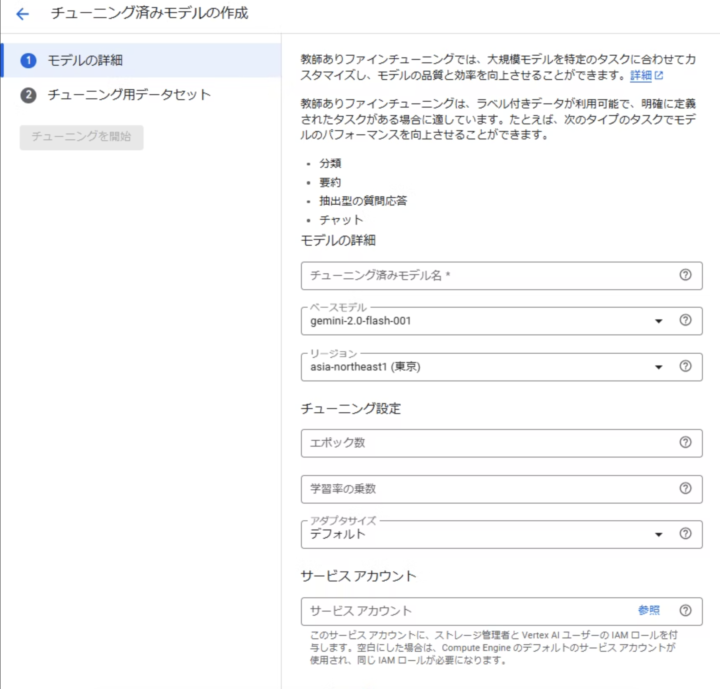
Vertex AI > チューニングから「チューニング済みモデルを作成」をクリックします。
モデル名やエポック数などを記載します。
Cloud StorageにアップロードしたJSONLデータセットを選択します。
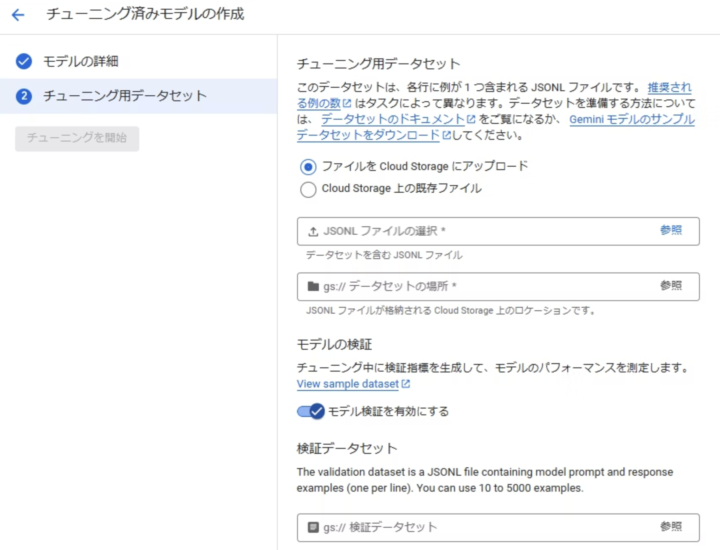
そして「チューニングを開始」をクリックして、開始します。
データセットの準備が終わると、学習が始まり、モニタリングで学習時のメトリクスを確認できます。
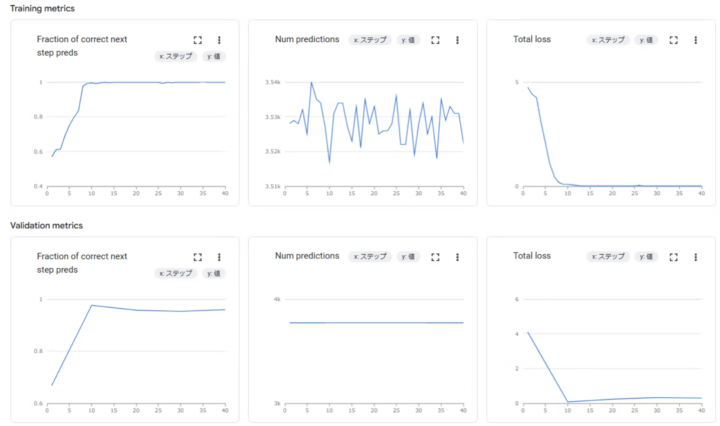
| 項目 | 説明 |
|---|---|
| total_loss | 損失 |
| fraction_of_correct_next_step_preds | 正解と予測のトークンの精度 |
| num_predictions | 予測されるトークン数 |
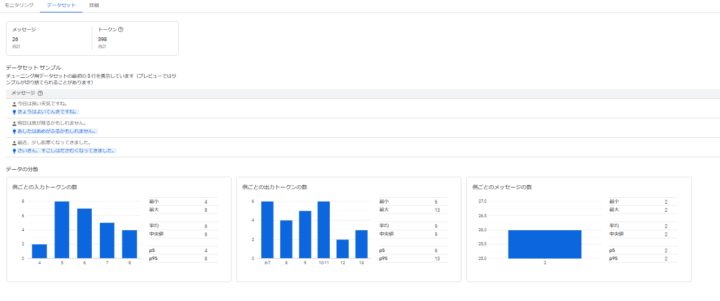
データセットでデータセットのトークン数などの分析を確認することもできます。
学習が終了すると、Model Registryにモデルがデプロイされます。
Vertex AI Studioのモデル選択で、チューニング済みの項目にモデルが追加されています。
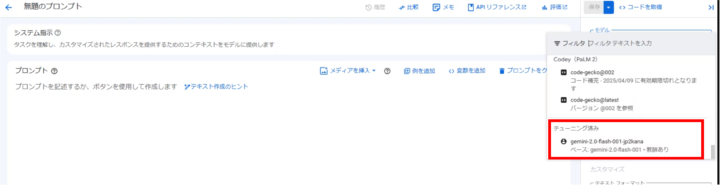
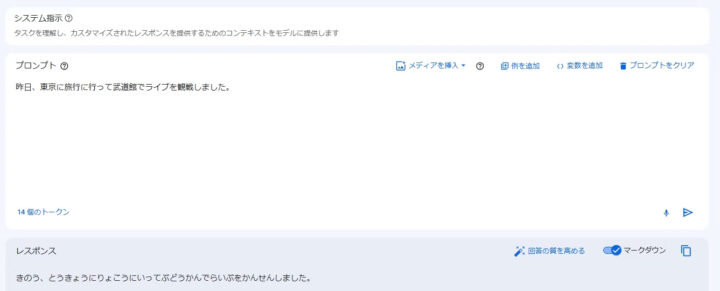
プロンプトを入力して、回答を確認します。
チューニングさせた通り、Instractionに指示しなくても文章をひらがなに変換してくれました!
おわりに
Google Cloud の Gemini のファインチューニングを試してみました。
今回は簡単な例でしたが、ファインチューニング機能を活用することで、より専門的で高度なタスクへの応用が期待されます。
プロンプト設計だけでは難しいタスクの場合の手段の1つとして考えてもらえたらと思います。




