
はじめに
サーバー運用の現場では、システムの健全性を保つために様々な通知設定が行われています。cronジョブの成否、アプリケーションのエラー、セキュリティイベント…。従来、これらの通知はサーバー内の設定(/etc/aliases、cronのMAILTO=、スクリプト内のmailコマンドなど)とPostfixのようなメール転送エージェント(MTA)を組み合わせて実現されることが一般的でした。
しかし、この従来方式には、見過ごされがちな課題が潜んでいます。通知先変更のたびに各サーバーの設定を修正する手間、MTAの運用保守という継続的な負荷、サーバー台数増加に伴う管理の限界…。あなたも「メール通知の設定変更、また全サーバーか…」「Postfix、最近調子悪いな…」と感じたことはありませんか?
本記事では、これらの課題を解決するモダンなアプローチとして、オブザーバビリティプラットフォームである New Relic を活用したログ監視と通知統合をご紹介します。サーバーからログをNew Relicに集約し、その強力な分析・アラート機能を使うことで、サーバー内のメール設定やMTA運用から解放され、運用がいかに効率化されるかを解説します。
この記事を読めば、New Relicを活用した通知統合がなぜ運用コスト削減に繋がるのかが分かります。煩雑なメール通知設定から解放され、よりスマートなサーバー運用を目指しましょう!
なぜNew Relicなのか? 導入・管理コストを徹底比較
「New Relicの導入や運用にもコストがかかるのでは?」 当然の疑問です。しかし、従来方式の隠れたコストと比較することで、New Relic導入のメリット、特に管理コスト削減効果が見えてきます。
従来方式の課題(隠れたコスト):
- MTA (Postfix等) の運用保守:
- OSパッチとは別に、MTA自体のセキュリティアップデートが必要です。
- ログ監視、設定維持、スプール詰まり対応、原因不明のメール不達調査、送信元IPアドレスのレピュテーション管理…これらは継続的に発生し、見えにくいですが大きな運用負荷となります。「postfixの監視がいらなくなる」のは、運用者にとって非常に大きなメリットです。
- OSやミドルウェアのバージョンアップ時に、MTAや関連スクリプトの互換性問題に悩まされることもあります。
- 煩雑すぎる通知先の変更作業:
- 「担当者が変わったので通知先メールアドレスを変更したい」– よくあるケースですが、従来方式では関連する全サーバーの設定ファイル(
/etc/aliases、スクリプト、cron定義など)を一つ一つ特定し、修正して回る必要があります。サーバーが数十台、数百台とあれば、これは悪夢のような作業であり、設定漏れのリスクも高まります。
New Relic のメリット:
- メールサーバー保守コストの大幅削減:
- MTAの運用保守は一切不要になります。New Relicはログ収集とアラート通知機能を提供し、実際の通知(メール、Slack等)はNew Relicプラットフォームまたは連携サービスが行うため、自前でMTAを管理する必要がありません。
- 通知先変更が驚くほど簡単に:
- 通知先のメールアドレスやSlackチャンネルなどの変更は、New Relicの設定( Destinations)を変更するだけです。これにより、そのDestinationsを使用している全てのアラートポリシーの通知先が一括で変更されます。サーバー側の設定変更は一切不要です。この差は歴然です。
- 通知条件設定の容易さと高度化:
- 単純なエラー検知であれば、スクリプトで複雑なロジックを組むよりも、New Relic UI上でログパターンを指定したり、NRQL(New Relic Query Language)で条件を指定する方が直感的で導入コストが低い場合があります。
- NRQLを使えば、特定の期間内のエラー発生頻度、複数ログ間の相関、特定属性を持つログのフィルタリングなど、スクリプトでは実装が難しい高度な条件も比較的容易に設定できます。
結論:
New Relicのライセンスコストや初期の学習コストは考慮が必要です。しかし、継続的な運用管理、特に「通知先の一元管理」と「MTA運用保守からの解放」、そして「高度なアラート設定能力」という点で、中長期的には運用コストが削減される可能性が高いと言えます。
実践!管理コスト削減メリットの検証
さて、ここまではNew Relic のメリットについて説明してきました。そこで、具体的な運用シナリオを通して、従来方式と比較した場合の管理コスト削減効果を検証してみましょう。
検証環境(想定):
- 複数のEC2インスタンス(例: Webサーバー3台、APサーバー2台)が稼働中。
- 各インスタンスにはNew Relic Infrastructure Agentが導入され、ログ転送設定によりログがNew Relicに収集されている。
- 各種アプリケーションログに対するエラー検知などのアラートポリシーと条件がNew Relic上で複数設定されており、すべて共通の Destinations (通知先設定) に通知を送っている。
- 当初の通知先として
old-admin-group@example.comが Destinations に設定されている。
検証1: 通知先メールアドレスの一括変更
シナリオ: システム管理チームのメールアドレスが変更になり、全アラームの通知先を old-admin-group@example.com から new-admin-group@example.com に変更する必要が出てきました。
従来方式の場合(比較のための考察):
- まず、通知先メールアドレスがハードコーディングされている箇所を特定する必要があります。
/etc/aliases、各サーバーで動作している監視スクリプト、cron定義のMAILTO=など、設定箇所が散在している可能性が高いです。 - 対象となる全てのサーバーに個別にログインします。
- 特定した設定ファイルを一つ一つ開き、古いメールアドレスを新しいメールアドレスに手作業で置換します。
/etc/aliasesを変更した場合はnewaliasesコマンドを実行、スクリプトを修正した場合は構文チェックや再起動が必要になるかもしれません。- サーバーが10台、20台…と増えるにつれて、この作業の手間と時間は膨大になり、設定漏れやタイプミスなどのヒューマンエラーのリスクも増大します。
New Relic の場合:
- New RelicのUIにログインし、「Alerts 」>「 Destinations 」に移動します。
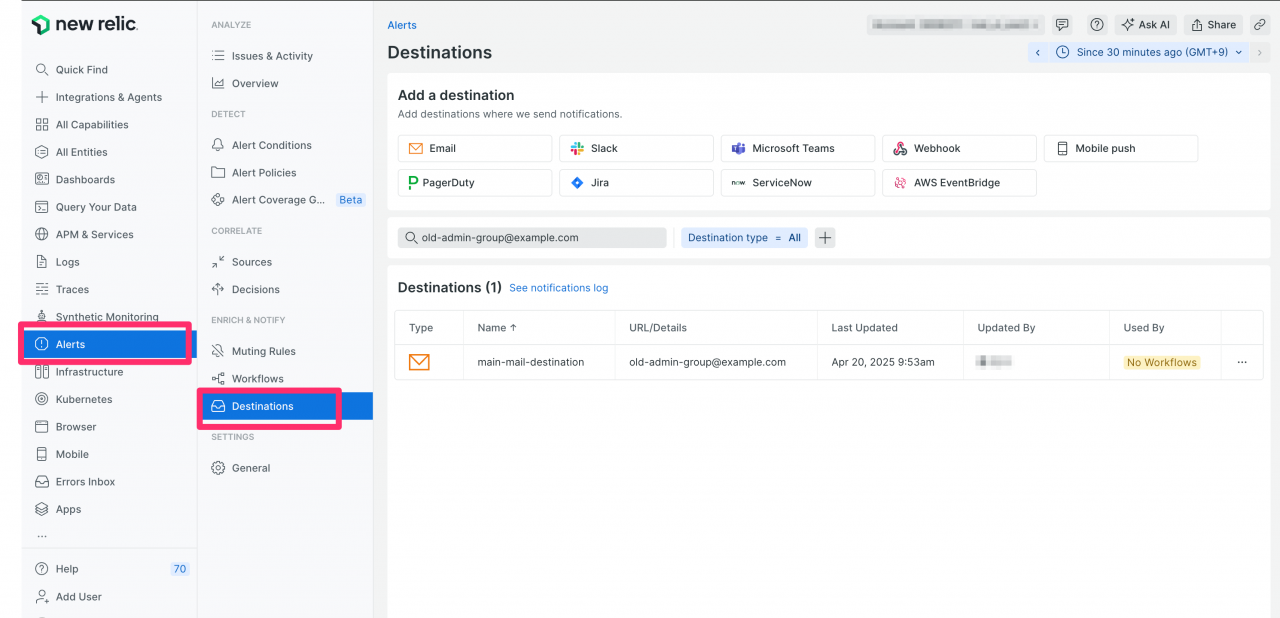
- 通知先として設定している Destination の
main-mail-destinationを選択し、編集画面を開きます。 - 通知先メールアドレスのフィールドを、
old-admin-group@example.comからnew-admin-group@example.comに変更します。
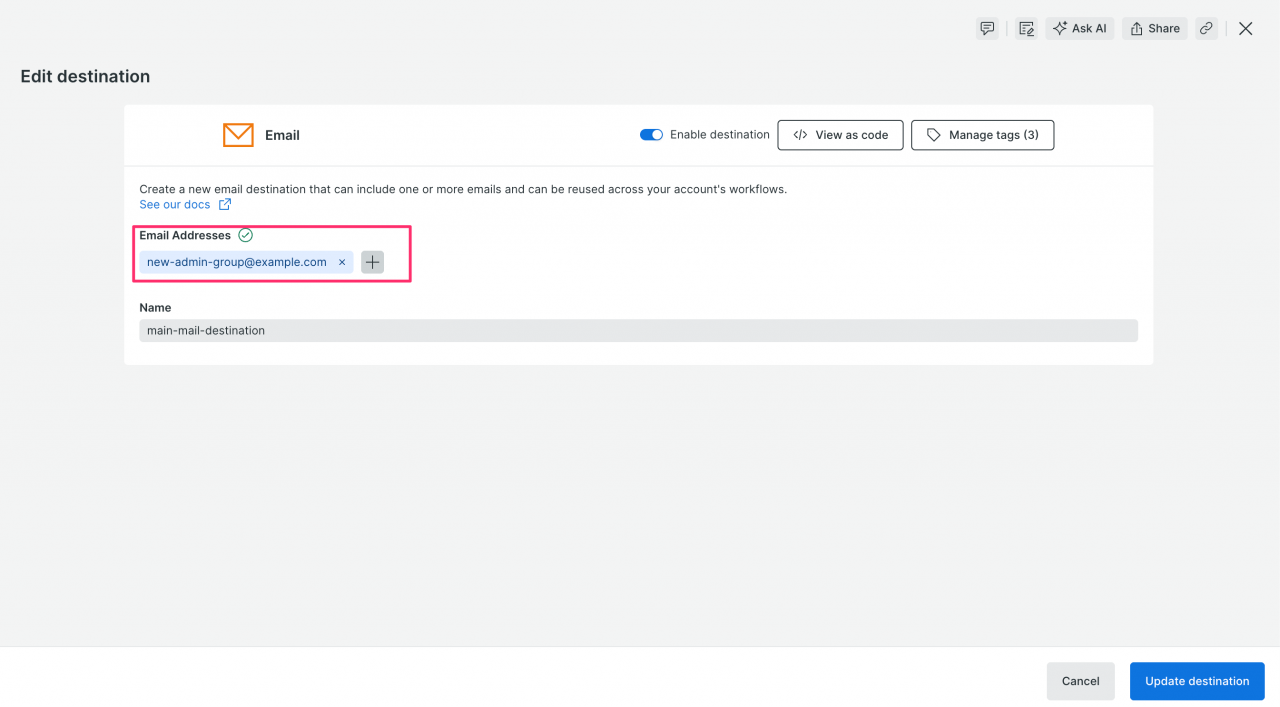
- 設定を保存します。
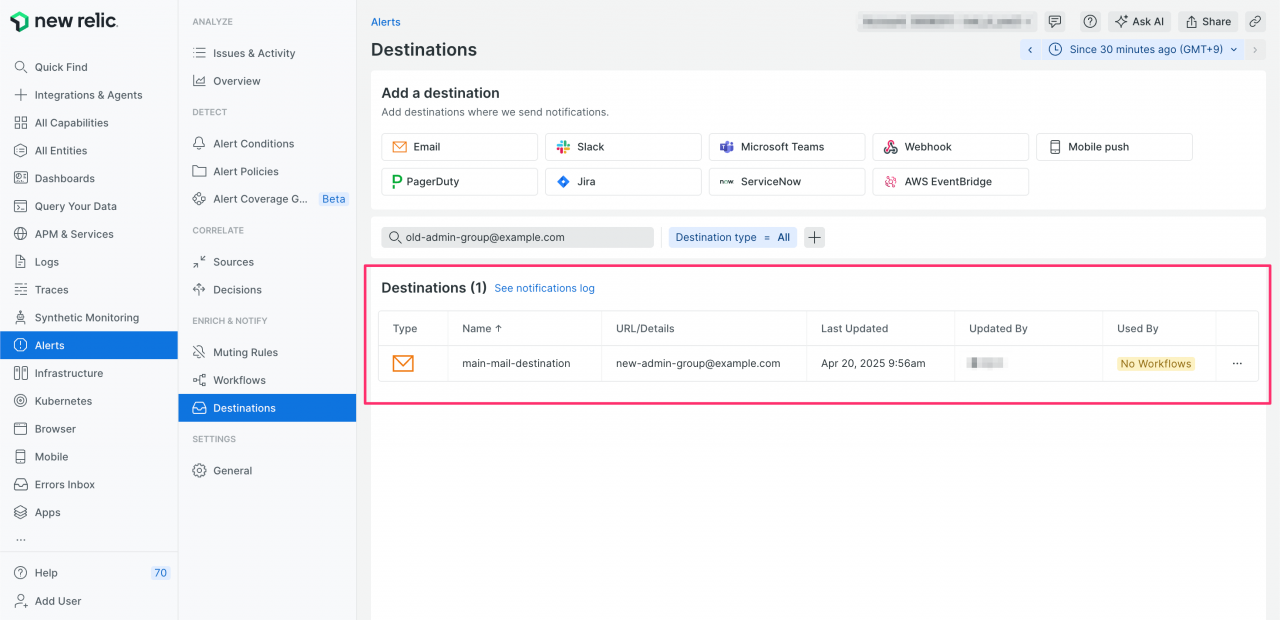
検証結果:
たったこれだけです。 New Relicの設定を一箇所変更するだけで、このDestinationsを使用している全てのアラートポリシー(=複数のサーバーやアプリケーションからのアラート)の通知先が一斉に変更されました。各サーバーにログインする必要も、設定ファイルを個別に修正する必要も一切ありません。管理コスト、作業時間、リスクのいずれにおいても、従来方式との差は明らかです。
検証2: 新しい監視対象ログの追加(複数サーバーへの展開)
シナリオ: 新機能で導入されたアプリケーション SuperApp が全Webサーバー(3台)にデプロイされました。このアプリのエラーログ /var/log/superapp/error.log を監視対象に追加し、エラー発生時に通知を受けられるようにします。
従来方式の場合(比較のための考察):
- 多くの場合、既存のログ監視スクリプトを修正するか、新しい監視スクリプトを作成する必要があります。これには、新しいログファイルのパス、監視するエラーパターン、通知処理のロジック追加が含まれます。
- 完成したスクリプト(または修正版)を、対象となる全Webサーバー(3台)に配布します。配布方法も手動コピーなど様々ですが、手間はかかります。
- 必要に応じて、各サーバーでcronの設定を追加・修正します。
- 各サーバーでスクリプトが正しく動作するか、エラーを検知して通知が飛ぶかを確認します。
- 新しい監視対象が増えるたびに、スクリプト開発・テスト・配布・設定という一連の作業が必要となり、管理対象が増え続けます。
New Relic の場合:
- Agent設定の更新:
* 各Webサーバー(3台)にログインし、New Relic Agentのログ設定ディレクトリ(例: /etc/newrelic-infra/logging.d/)に、新しいログファイル /var/log/superapp/error.log を監視対象とする設定ファイル(例: superapp.yml)を追加します。
[root@ip-10-0-1-218 ~]# vi /etc/newrelic-infra/logging.d/superapp.yml [root@ip-10-0-1-218 ~]# cat -n /etc/newrelic-infra/logging.d/superapp.yml 1 logs: 2 - name: superapp-log 3 file: /var/log/superapp/error.log 4 pattern: WARN|ERROR [root@ip-10-0-1-218 ~]#
- 設定変更後、各サーバーでNew Relic Agentを再起動します。
[root@ip-10-0-1-218 ~]# systemctl restart newrelic-infra [root@ip-10-0-1-218 ~]#
- New Relicアラート設定の作成:
* New RelicのUIにログインし、「Alerts」>「Alert Conditions」に移動し、「 + New alert condition」をクリックします。
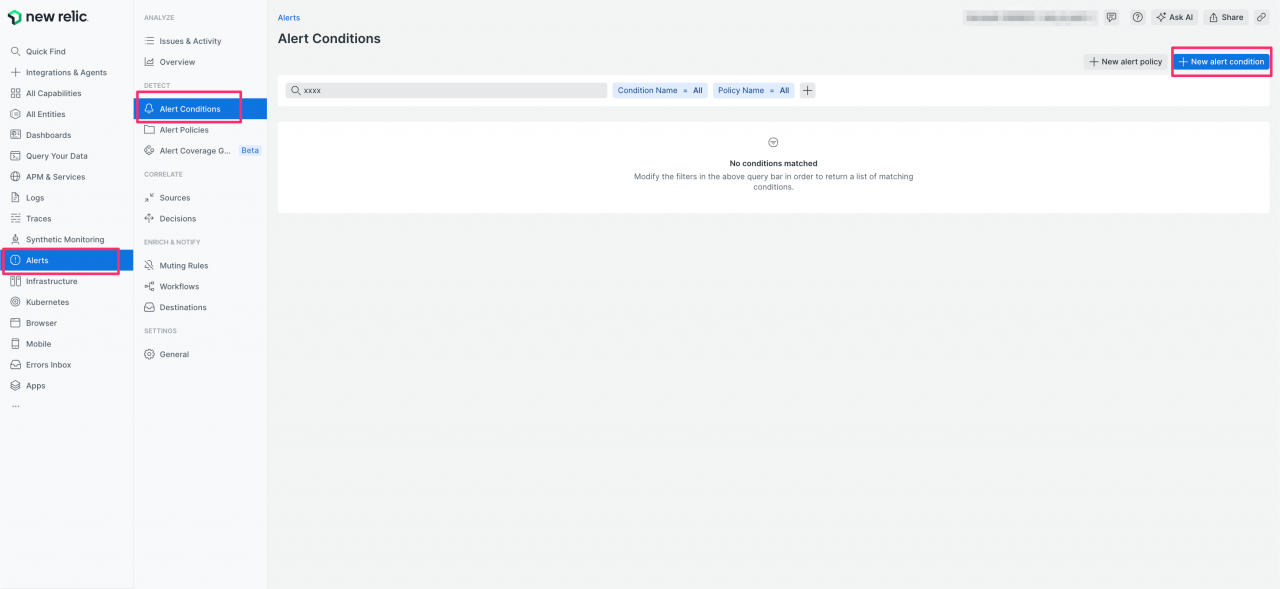
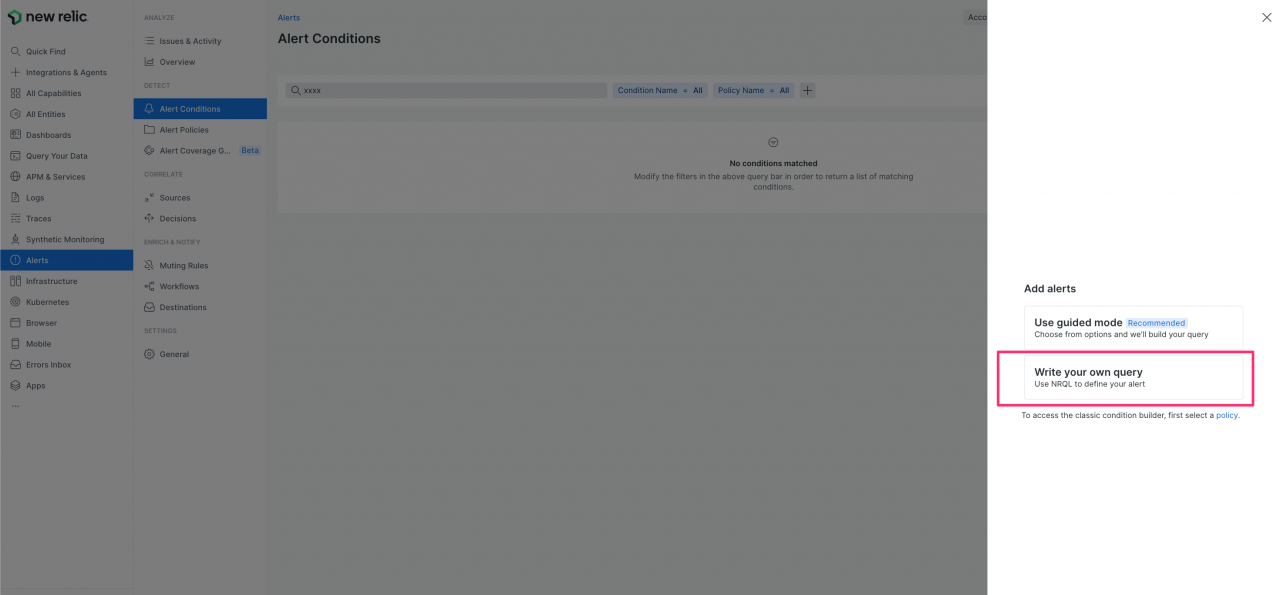
* 表示される Add alerts で、「Write your query」を選択します。
* Condition 設定:
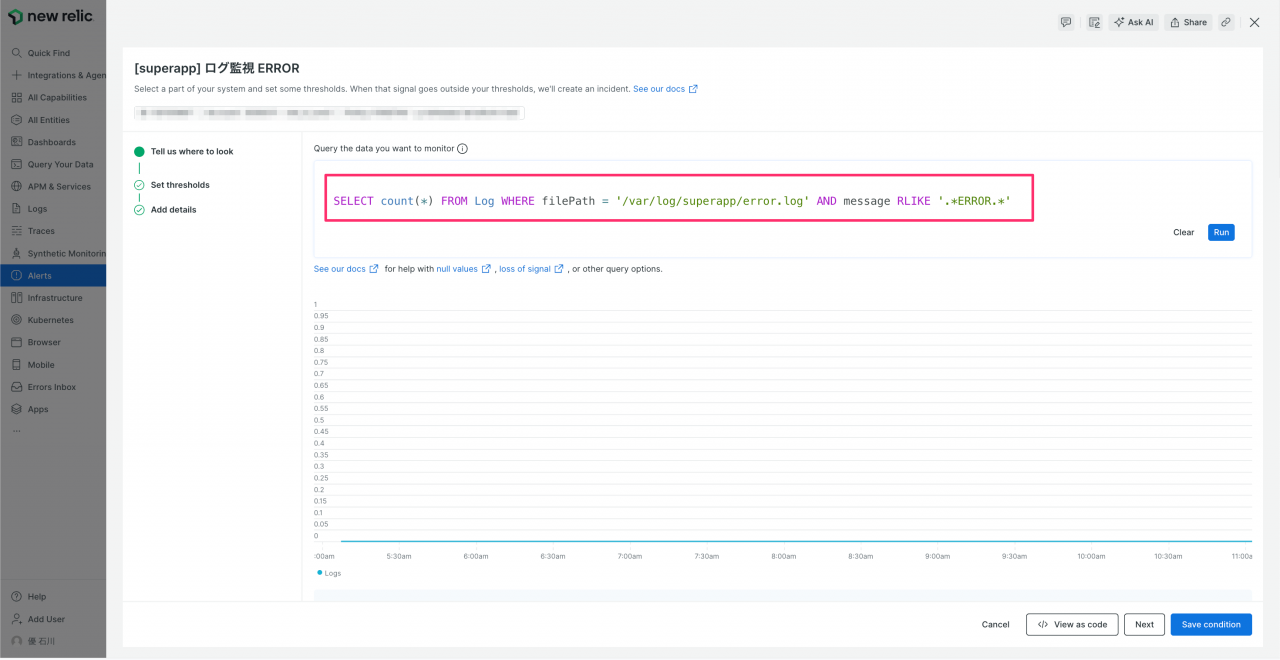
- NRQLクエリに、新しいログのエラーを検知するクエリを入力します。例:
SELECT count(*) FROM Log WHERE filePath = '/var/log/superapp/error.log' AND message RLIKE '.*ERROR.*'
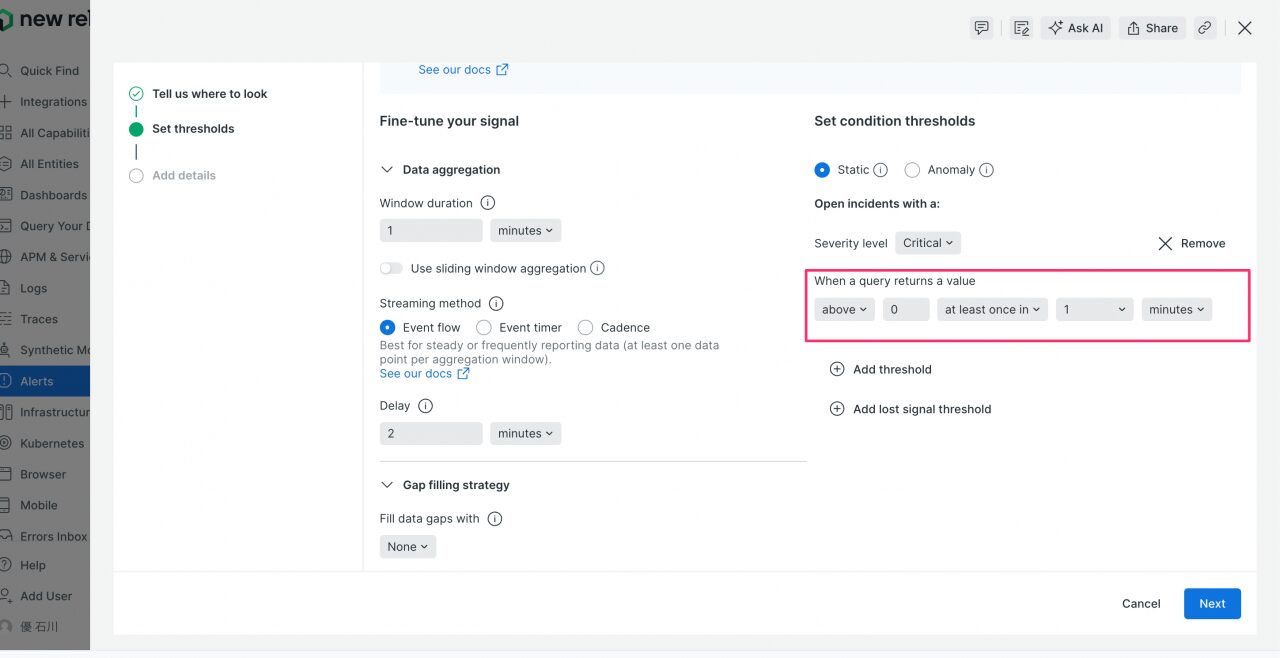
「Threshold」を「above 0 at least once in 1 minute」のように設定します(1分間に1回以上エラーログが出たら)。
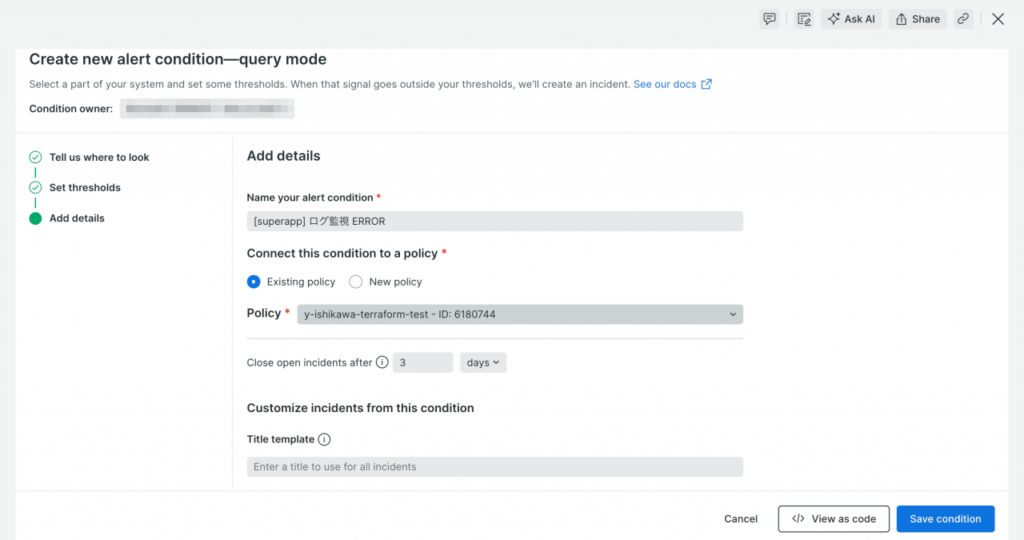
必要に応じて condition名や policy の選択等の設定を行い、条件を保存します。
- 発砲テスト:
* エラーログファイルに、テストエラーログを出力します。
[root@ip-10-0-1-218 log]# echo "ERROR" >> /var/log/superapp/error.log [root@ip-10-0-1-218 log]#
- NewRelic 上でアラートを検知していることが確認できます。
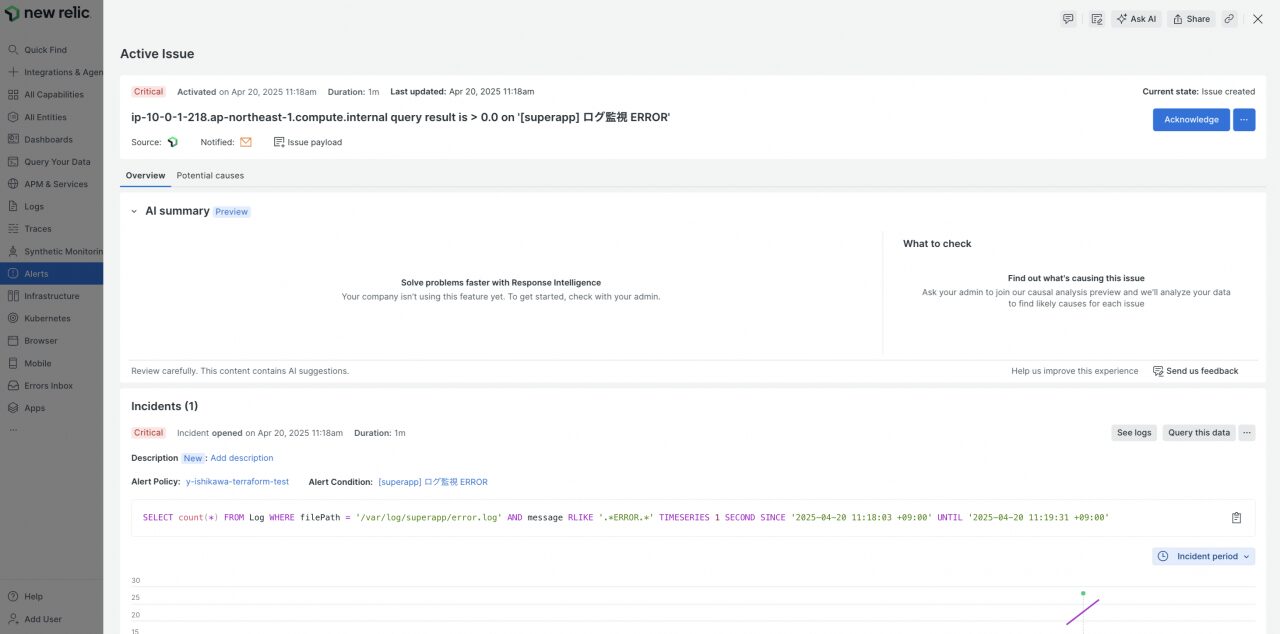
- メールにも通知されることが確認できます。
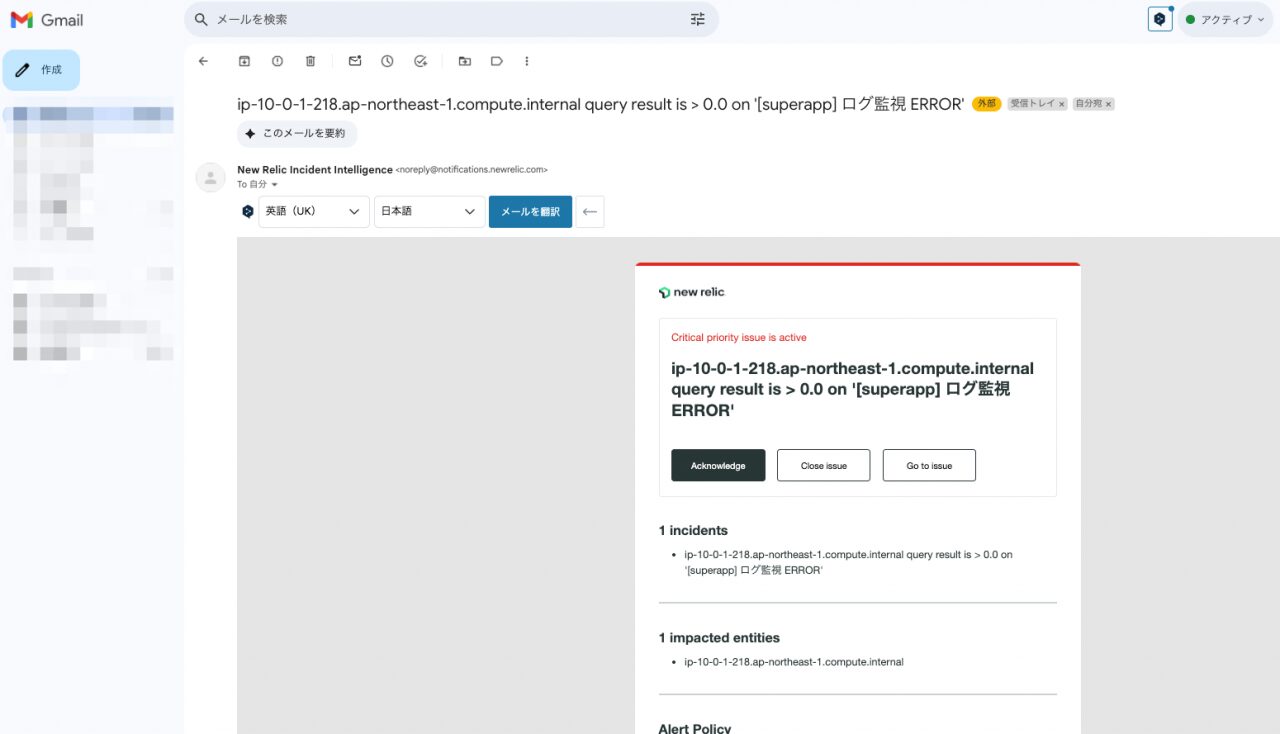
検証結果:
Agentの設定変更はサーバーごとに行う必要がありますが、監視ロジックやアラート条件、通知設定はNew Relic上で一元的に管理できます。新しい監視対象を追加する際も、サーバー側での複雑なスクリプト開発や配布は不要で、New Relic上でアラート条件を設定するだけで済みます。これにより、監視設定の追加・変更に伴う手間と時間は大幅に削減されます。
検証3: MTA運用保守からの解放(考察)
これは直接的な検証手順ではありませんが、New Relic がもたらす最も大きなコスト削減効果の一つです。
- 従来方式で必要だったタスク:
- Postfix等のMTAソフトウェア自体のインストール、設定、継続的なセキュリティパッチ適用。
- MTAのプロセス監視、ログ監視(エラー、スプールキューの滞留など)。
- スプールディレクトリのディスク容量監視とクリーンアップ。
- OSやカーネルのアップデートに伴うMTAとの互換性確認や再設定。
- 送信元IPアドレスの評価(レピュテーション)管理、ブラックリスト登録時の対応。
- 原因不明のメール不達時の詳細なログ調査とトラブルシューティング。
- New Relic では:
- 上記のMTAに関連する全ての運用保守タスクが不要になります。通知処理はNew Relicプラットフォームが担います。
- 効果:
- これにより、インフラ管理チームの工数が大幅に削減され、より戦略的な業務(アプリケーション改善、インフラ最適化など)に集中できるようになります。日々のMTAトラブル対応に追われることがなくなります。
これらの検証シナリオを通して、New Relic を活用した通知統合が、単に通知を実現するだけでなく、継続的な運用管理のコストと手間を大幅に削減する強力なソリューションであることがお分かりいただけたかと思います。
まとめ
この記事では、従来のサーバー内メール通知の課題を明らかにし、New Relicを用いたログ監視・通知統合がもたらすメリット、特に管理コスト削減効果に焦点を当てて解説しました。
- MTA運用からの解放: Postfix等の運用保守にかかっていた目に見えないコストがゼロになります。
- 通知先の一元管理: New RelicのDestinations 設定で通知先を一括管理でき、変更作業が劇的に簡素化されます。
- 高度なアラート設定: NRQL等により、ログに基づいた柔軟で強力なアラート条件を設定できます。
- 監視設定の集約: サーバー側に複雑な監視スクリプトを持つ必要がなくなり、監視ロジックをNew Relicに集約できます。
New Relicのライセンスコストや学習コストは考慮が必要ですが、中長期的な視点で見れば、運用コスト削減と運用効率の向上、そしてオブザーバビリティの向上に大きく貢献します。
参考New Relic公式ドキュメント
- Introduction to log management:
https://docs.newrelic.com/docs/logs/log-management/get-started/introduction-log-management/ - Forward your logs using the infrastructure agent:
https://docs.newrelic.com/docs/logs/forward-logs/forward-your-logs-using-infrastructure-agent/ - Introduction to alerts and Applied Intelligence:
https://docs.newrelic.com/docs/alerts-applied-intelligence/overview/ - NRQL alert conditions:
https://docs.newrelic.com/docs/alerts-applied-intelligence/new-relic-alerts/alert-conditions/create-nrql-alert-conditions/ - New Relic Query Language (NRQL) introduction:
https://docs.newrelic.com/docs/query-your-data/nrql-new-relic-query-language/get-started/nrql-introduction/



