
はじめに
多くの Web システムで利用されている Apache Web サーバーですが、その運用においてログの分析は欠かせません。
しかし、サーバー台数が増えるにつれて、従来のログ分析方法には様々な課題が出てきます。
皆さんも、一つ一つのサーバーへ SSH 接続し、コマンドラインで grep や awk を駆使してログを追いかける作業に、うんざりした経験はありませんか。
この方法は、手間がかかるだけでなく、分析の幅も限られてしまいがちです。
そこで今回は、この「つらみ」を解消するため、Apache のログを Amazon CloudWatch Agent、Amazon Data Firehose、AWS Glue Data Catalog、Amazon S3、そして Amazon Athena を使って分析するモダンな方法へ移行し、そのメリットを実際に検証します。
具体的には、ログを S3 へ集約し、Athena から SQL でクエリすることで、分析作業がどのように改善されるかを紹介します。
従来のログ分析方法とその課題
これまで、私たちは以下のような方法で Apache のログを分析していました。
- 調査対象の EC2 インスタンスへ SSH でログインする。
/var/log/httpd/ディレクトリなどに移動する。access_logやerror_logに対して、tail,less,grep,awk,sort,uniq,wcなどのコマンドを組み合わせて目的の情報を探す。- 必要に応じて、複数のサーバーで同じ作業を繰り返す。
この方法には、以下のような課題がありました。
| 課題項目 | 具体的な内容 |
|---|---|
| 非効率性 | 複数サーバーへのログインやコマンド入力に多くの手間と時間がかかる。 |
| 分析の限界 | 全サーバー横断での集計や、複雑な条件でのログ抽出、時系列分析などが非常に困難である。 |
| スケーラビリティ | サーバー台数の増加に伴い、調査時間が比例して増大する。 |
| 属人化 | 高度なコマンドラインスキルを持つ特定の人しか詳細な調査ができない可能性がある。 |
| 管理の複雑さ | ログファイルが各サーバーへ分散し、一元管理や長期保管が難しい。 |
これらの課題は、特に大規模な環境や、迅速な障害対応、詳細なサービス分析が求められる場面で大きなボトルネックとなります。
新しいログ分析基盤の概要
今回紹介する新しいログ分析基盤の構成は以下の通りです。
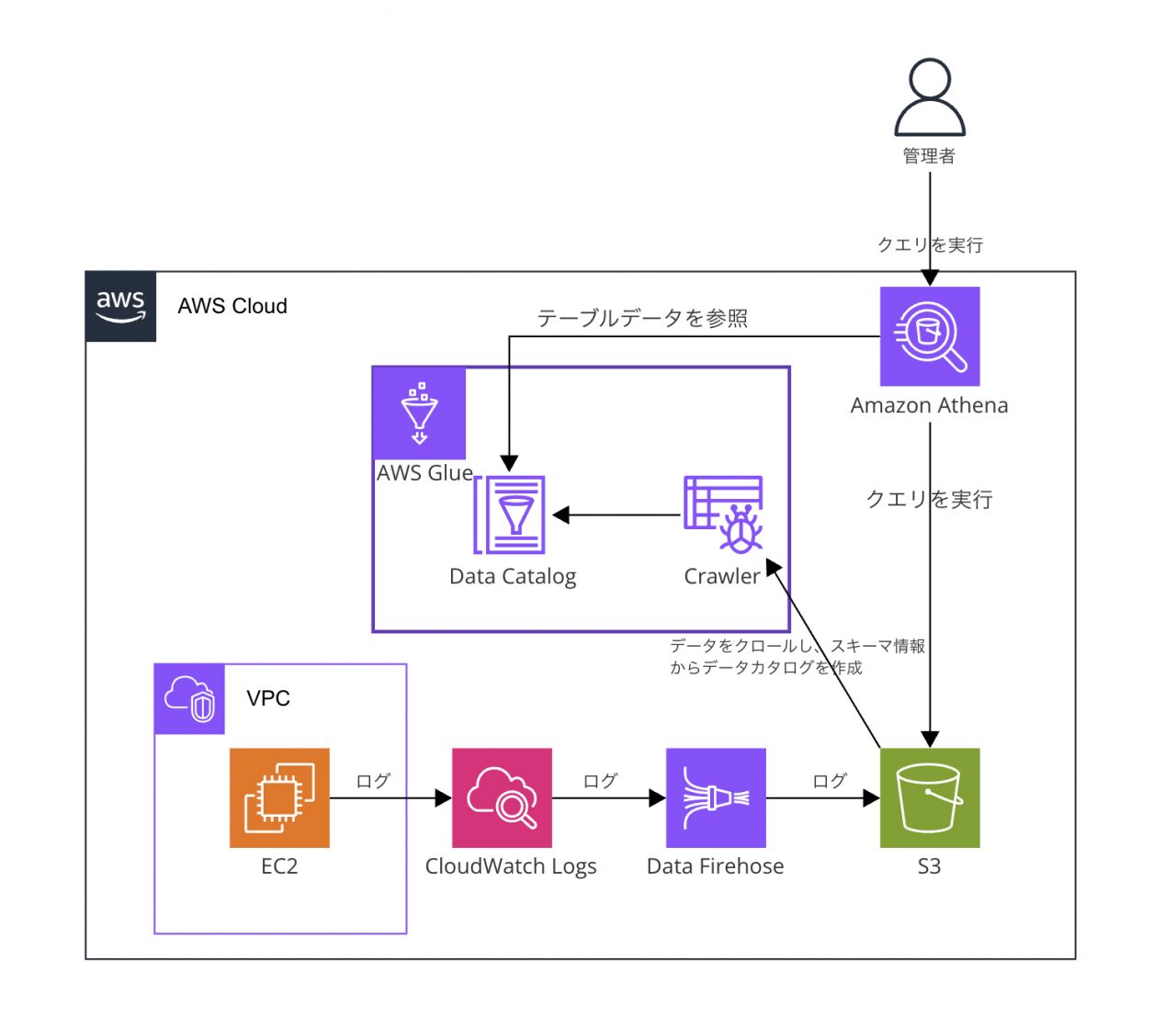
各コンポーネントの役割は次のようになります。
- Amazon CloudWatch Logs: CloudWatch Agent が収集した各 EC2 インスタンス上の、指定された Apache のログファイル (access_log, error_log等) を記録し、Data Firehose へ送ります。
- Amazon Data Firehose: CloudWatch Logs から送られてくるログデータを受け取り、指定された形式 (例: JSON) へ変換したり、データをバッファリングしたり、必要に応じて圧縮やパーティショニングを行ったりしながら、最終的に S3 へ配信します。
- Amazon S3: 全てのサーバーから集約されたログデータが、高い耐久性とスケーラビリティを持つストレージへ保存されます。Firehose により、日付などで整理されたフォルダ構造 (プレフィックス) で格納されることが多いです。
- AWS Glue Crawler: S3 に保存されたログデータから、データのスキーマ(構造)を自動的に検出し、AWS Glue Data Catalogにメタデータテーブルを自動的に作成・更新します。
- AWS Glue Data Catalog: S3 上のデータに対するメタデータ (データベース名、テーブル名、カラム名、データ型、データ形式、S3 の場所など) を管理するカタログです。Athena はクエリ実行時にこのカタログ情報を参照し、S3 上のファイル群をあたかもデータベースのテーブルのように扱えるようにします。
- Amazon Athena: Glue Data Catalog のメタデータを利用し、S3 に保存されたログデータに対して標準 SQL で直接クエリを実行できるサーバーレスのインタラクティブなクエリサービスです。インフラ管理は不要です。
この構成により、ログデータは自動的に S3 へ集約され、Athena を使って一箇所から全てのログデータを分析できるようになります。
Athena 導入によるメリット
S3 へログを集約し、Athena で分析する構成には、従来の課題を解決する以下のようなメリットがあります。今回の検証では、これらのメリットを確認していきます。
| メリット項目 | 具体的な内容(Athena でどう解決されるか) |
|---|---|
| 効率性向上 | 各サーバーへの SSH ログインが不要になり、Athena から単一の SQL クエリで全サーバーのログを横断的に調査できる。 |
| 高度な分析能力 | 標準 SQL を利用し、複雑な条件でのフィルタリング、集計、複数ログの結合、時系列分析などを容易に実行できる。 |
| スケーラビリティ | Athena はサーバーレスで自動的にスケールするため、データ量の増加に対してインフラ管理の手間なく対応できる。 |
| アクセシビリティ向上 | IAM でアクセス権限を管理でき、サーバーアクセス権限がないユーザーも SQL を使って安全にログ分析へ参加できる。 |
| 管理の容易化 | S3 でログを一元管理でき、ライフサイクルポリシーによる長期保管や削除、バージョニングなどの設定が容易になる。 |
Athena によるメリット検証手順
それでは、実際にこの新しい基盤を使って、従来の課題がどのように解決されるか検証していきましょう。
前提条件
- 上記のログ転送設定 (CloudWatch Agent -\> Amazon Data Firehose -\> S3) が完了していること。
- ログが保存されている S3 バケット名とパス (プレフィックス) を確認済みであること。
- 検証を行う IAM ユーザーまたはロールに、Athena, S3, Glue への適切なアクセス権限が付与されていること。
ステップ1: Athena テーブルの作成
まず、Athena が S3 上のログデータを認識できるように、テーブルを作成します。AWS Glue クローラーを使うのが最も簡単です。
- AWS マネジメントコンソールから AWS Glue へ移動します。
- 「クローラー」から、「Create crawler」をクリックし、名前を入力します。
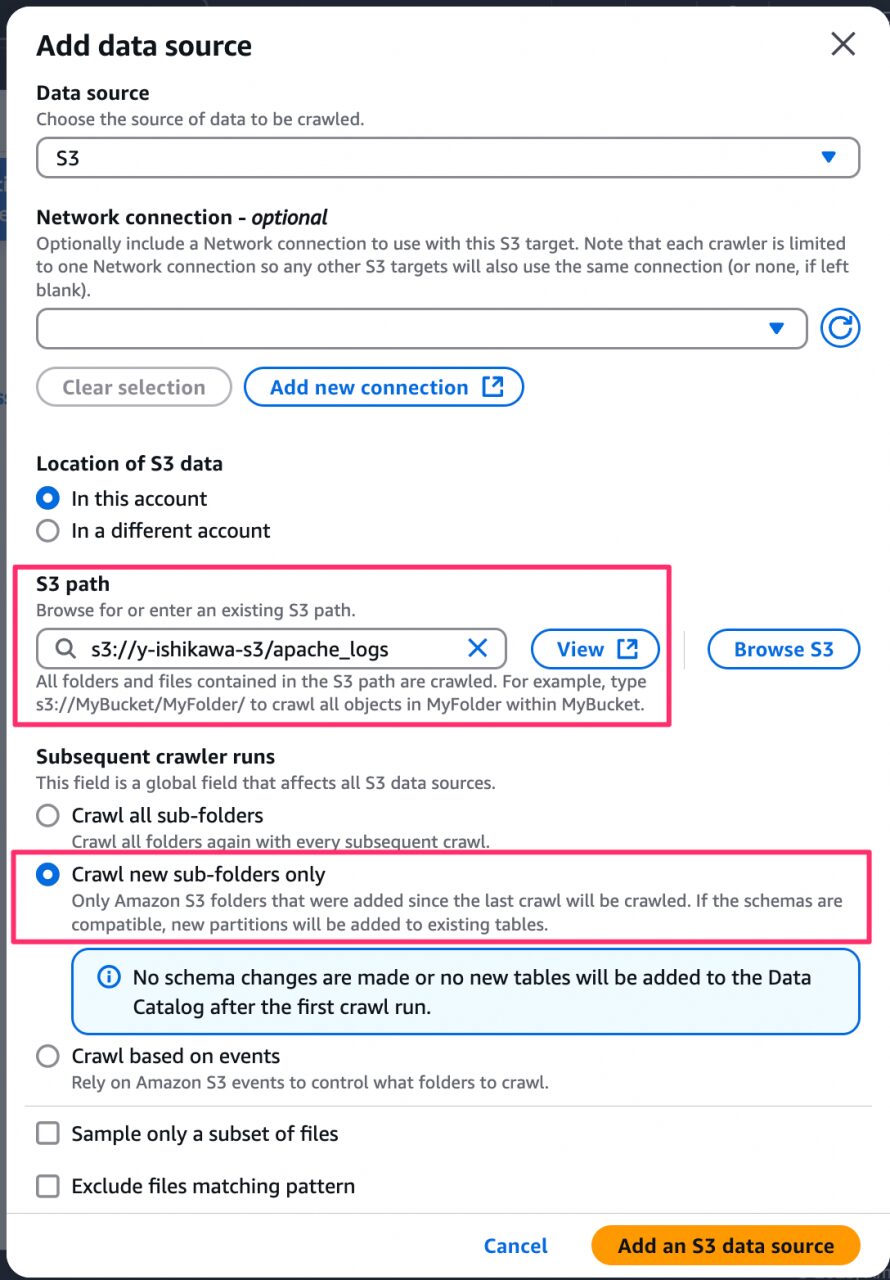
- データソースとしてログが格納されている S3 パスを指定します。
- 「Subsequent crawler runs」は「Crawl new sub-folders only」を選択します。これは、前回のクローラー実行時以降に新しく追加されたサブフォルダのみをスキャン対象とするという設定です。詳細は以下から確認してください。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/define-crawler-choose-data-sources.html
- 適切な IAM ロールを選択します。
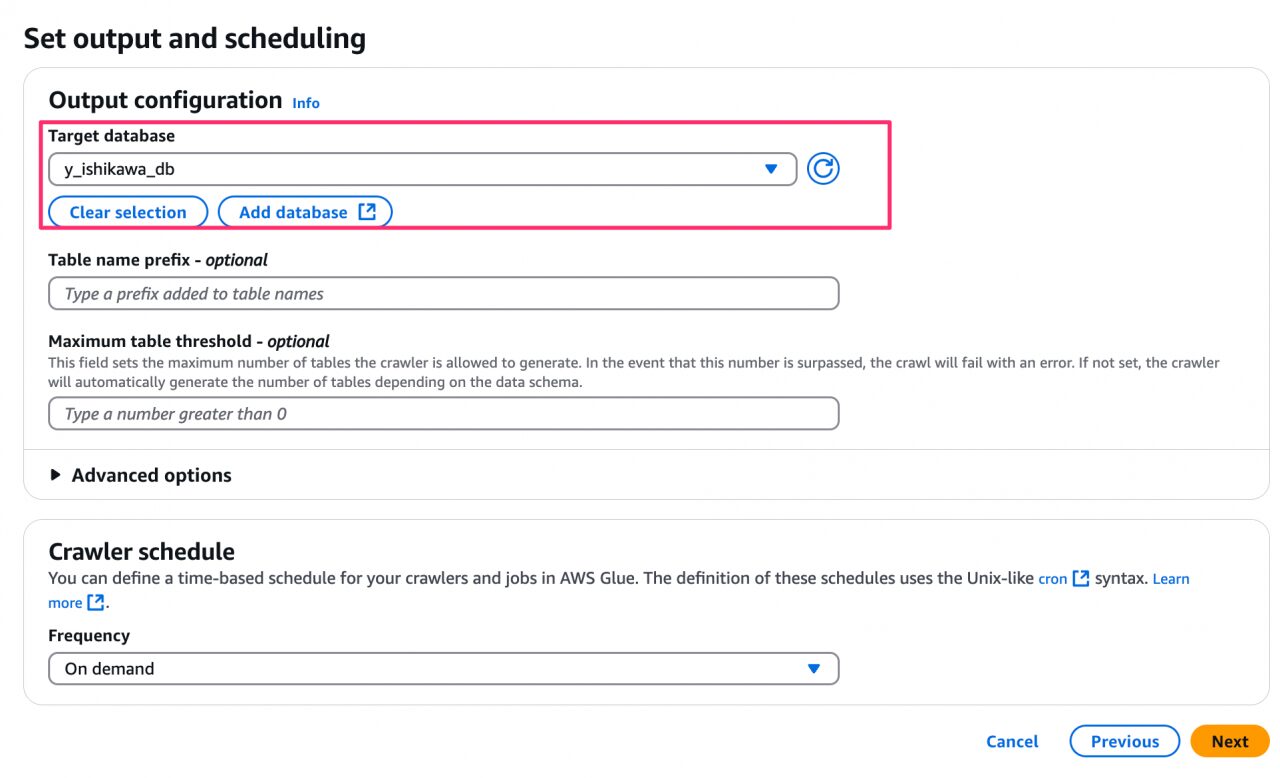
- 出力先のデータベースを指定します。これは、AWS Glue データカタログ内に作成されるデータベースになります。新規作成する場合は、「Add database」から作成できます。
- 作成が完了したら「Run Crawler」をクリックしてクローラーを実行します。
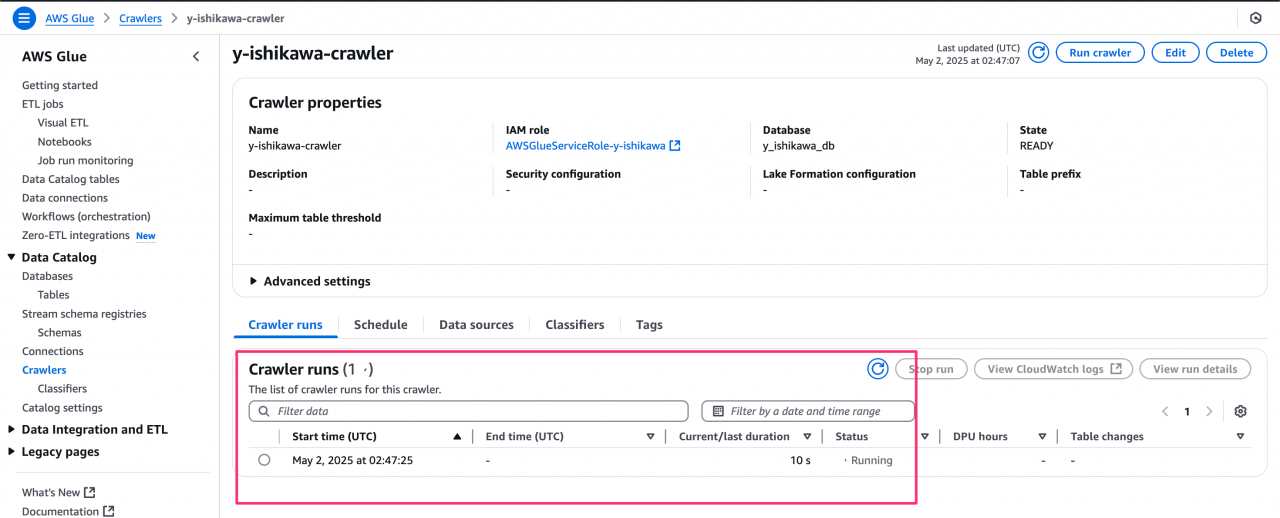
しばらく待つと、クローラーが S3 のデータをスキャンし、データ構造を自動で判別して Glue Data Catalog へテーブルを作成してくれます。

Glue クローラーによってスキーマが自動認識され、テーブルが作成されることを確認できました。
ステップ2: 基本的なクエリの実行
テーブルができたので、Athena のクエリエディタから簡単なクエリを実行し、データへアクセスできるか確認します。
左にデータソースを選択するメニューがあるので、作成した Data Catalog のデータベースを選択し、以下のクエリを実行してみます。
-- アクセスログテーブルから最初の10件を表示 (テーブル名はクローラーが作成したものに合わせる) SELECT * FROM apache_logs LIMIT 10;
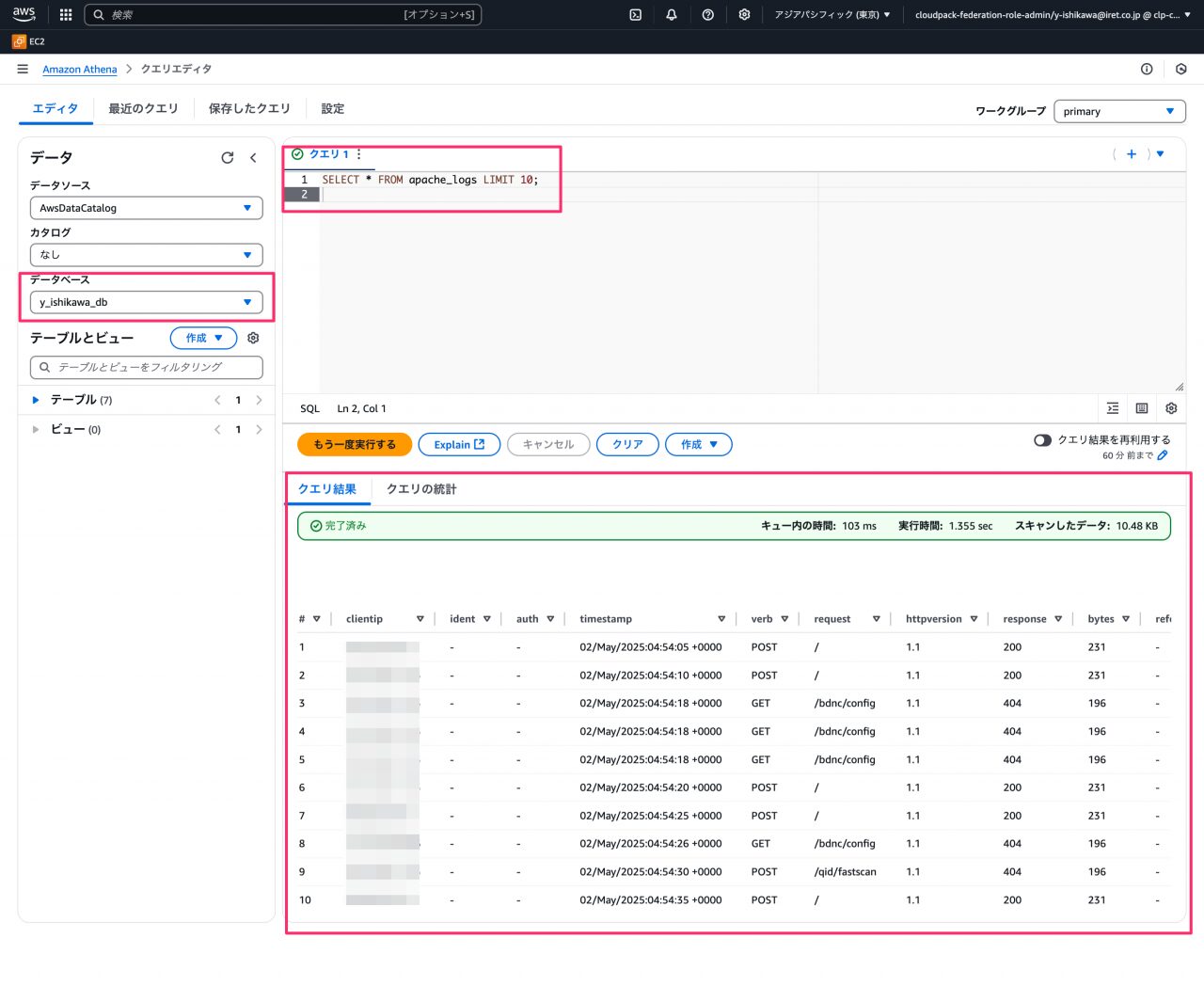
Athena から S3 上のログデータへアクセスできることを確認できました。これで分析の準備は完了です。
ステップ3: メリットを検証するためのクエリ実行
ここからは、具体的なシナリオに基づいてクエリを実行し、Athena のメリットを体感していきます。
検証項目1: 効率性・一元管理
- シナリオ: 直近 1 時間の全サーバーの総アクセス数を確認する。
- クエリ例:
-- request_timestamp カラムの形式に合わせて、適宜 parse_datetime 等で変換してください SELECT COUNT(*) AS total_requests FROM apache_logs WHERE parse_datetime(timestamp, 'dd/MMM/yyyy:HH:mm:ss Z') BETWEEN (current_timestamp - interval '1' hour) AND current_timestamp; - 実行結果:
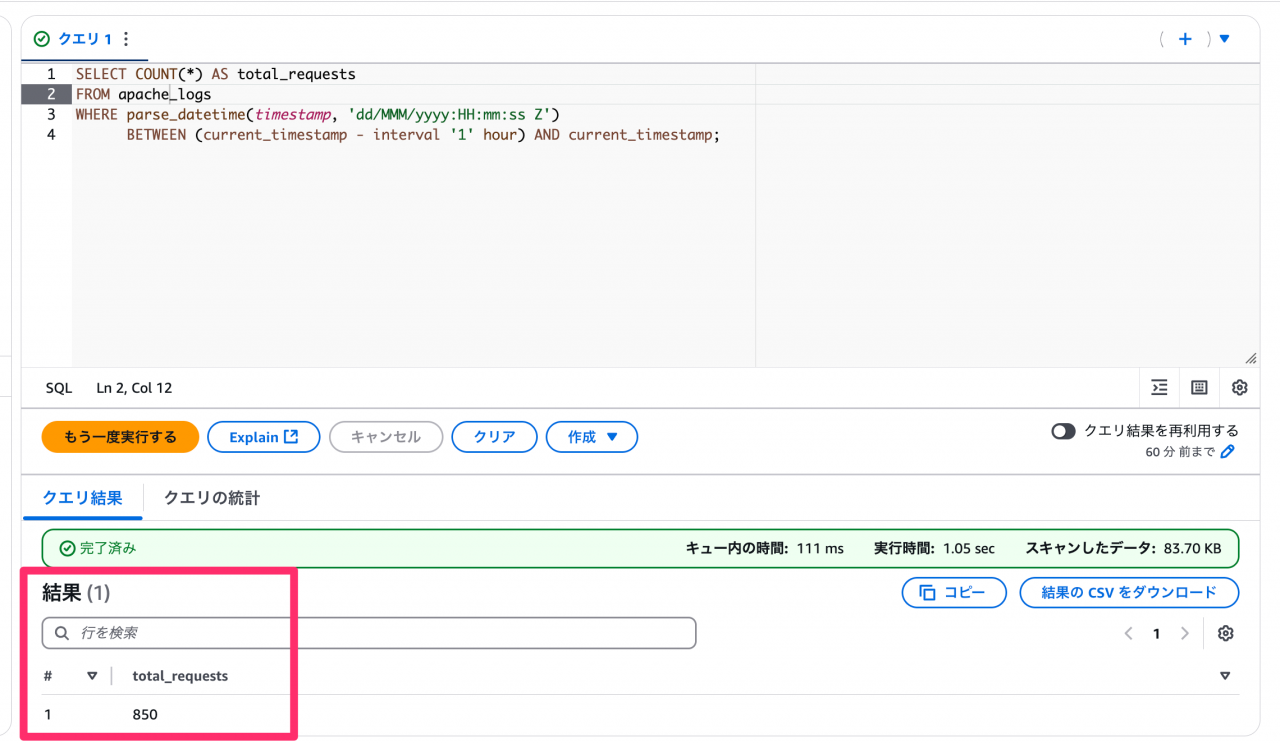
- 確認: 各サーバーへのログインなしに、単一クエリで全サーバーのログを集計できる効率性を確認できました!これは大きな時間短縮につながります。
従来であれば、各サーバーへログイン後、以下のようなコマンドを実行し、結果を合算する必要がありました。# grep "$(date -d '1 hour ago' '+%d/%b/%Y:%H')" /var/log/httpd/access_log | wc -l
検証項目2: 高度な分析(集計)
- シナリオ: 過去 24 時間でアクセス数が多かった上位 10 件の IP アドレスを調べる。
- クエリ例:
SELECT clientip, COUNT(*) AS request_count FROM apache_logs WHERE parse_datetime(timestamp, 'dd/MMM/yyyy:HH:mm:ss Z') BETWEEN (current_timestamp - interval '1' day) AND current_timestamp GROUP BY clientip ORDER BY request_count DESC LIMIT 10; - 実行結果:
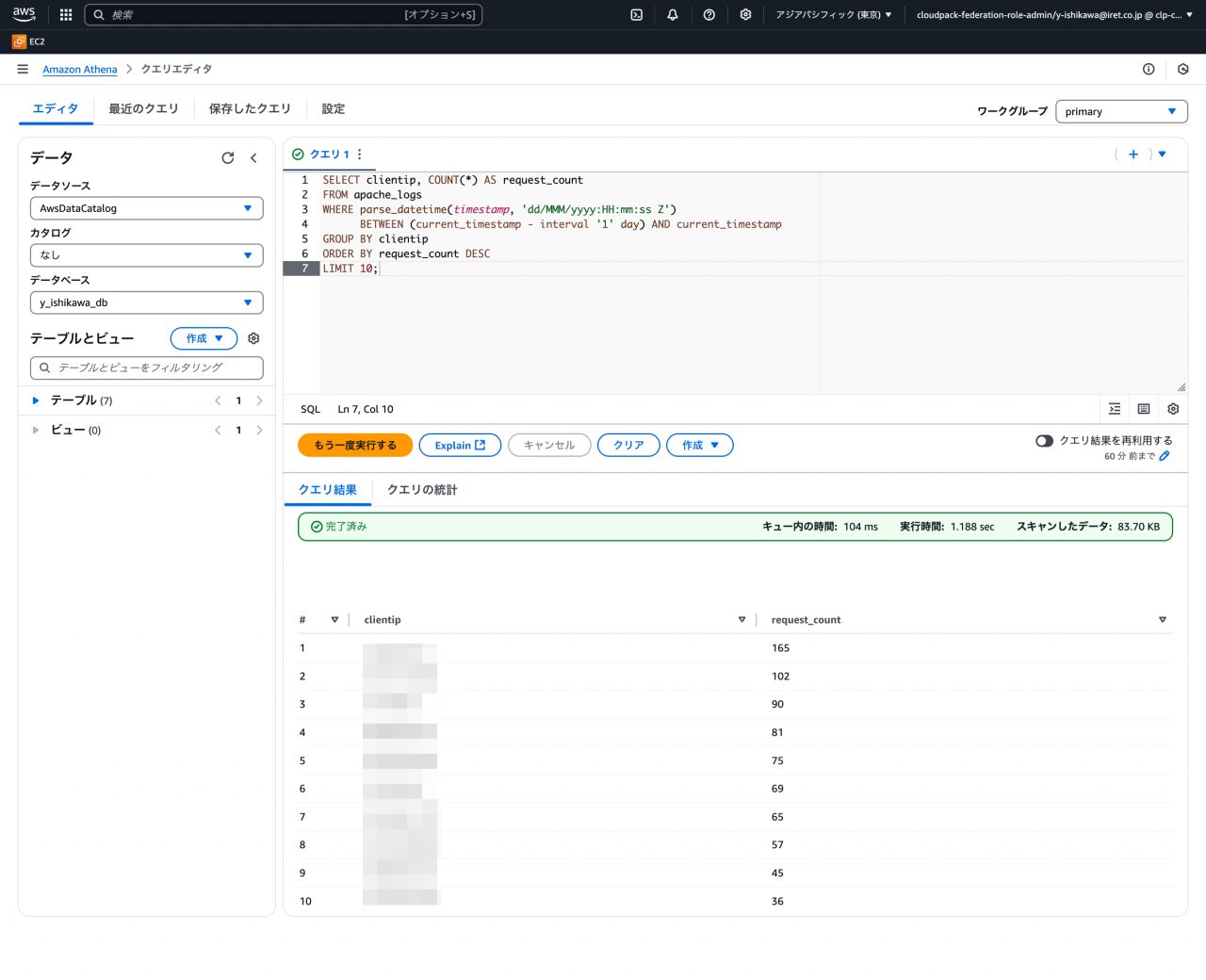
- 確認: コマンドラインでは非常に手間がかかる集計やランキングが、SQL を用いて容易に実行できることを確認できました。
検証項目3: 高度な分析(フィルタリング)
- シナリオ: 400 番台のエラーが発生したアクセスログを確認する。
- クエリ例:
SELECT * FROM apache_logs WHERE CAST(response AS INTEGER) >= 400 AND CAST(response AS INTEGER) < 500 LIMIT 10;
- 実行結果:
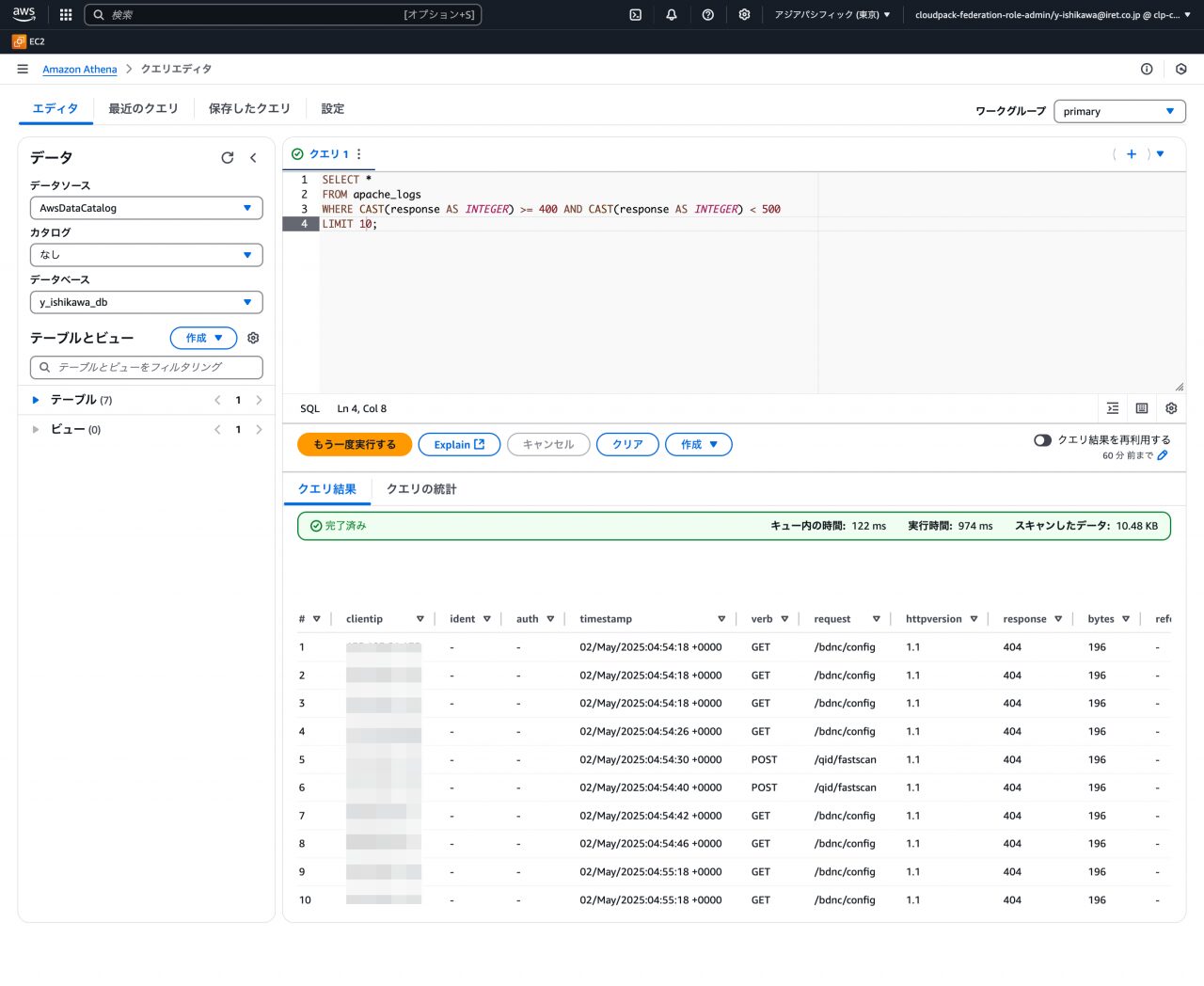
- 確認:
WHERE句を活用することで、特定の条件 (ステータスコード、IP アドレス、URL など) に合致するログだけを素早く抽出できることを確認できました。
- 確認:
ステップ4: 実行結果の保存
Athena のクエリ実行結果は、S3へ保存されます。
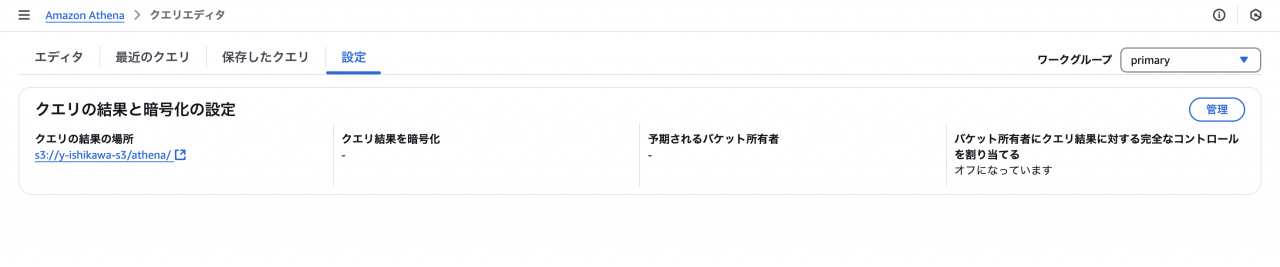
実行結果自体にさらにクエリをかけることもできるので分析の幅もさらに広がることが期待できます。
まとめ
今回の検証を通じて、Apache のログ分析基盤を従来の SSH とコマンドラインによる方法から、S3 と Athena を活用する構成へ移行することで、以下のような大きなメリットが得られることを確認しました。
- 効率性の大幅向上: 各サーバーへログインする手間がなくなり、単一のインターフェース (Athena) から全ログへアクセス、分析が可能になった。
- 高度な分析能力: 標準 SQL を用いて、これまで困難だった複雑な集計、フィルタリング、複数ログの関連付けなどが容易になった。
- 高いスケーラビリティ: サーバレスのため、データ量の増加に対して、インフラ管理の手間なく対応できるようになった。
ログ分析基盤の移行は、日々の運用負荷を大幅に軽減し、データに基づいた意思決定を加速させる強力な一手となります!
まだ従来のログ分析方法で「つらみ」を感じている方は、ぜひこの構成を導入し、より快適なログ分析環境を手に入れてください!
参考ドキュメント
Amazon Athena
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/what-is.html
AWS Glue
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/what-is-glue.html
Amazon Data Firehose
https://docs.aws.amazon.com/ja_jp/firehose/latest/dev/what-is-this-service.html
CloudWatch Agent
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/Install-CloudWatch-Agent.html
Athena でのパーティション射影
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partition-projection.html
Athena でのパフォーマンスチューニング
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/performance-tuning.html


