
セッションタイトル
LLMs, GPUs, and Everything in Between: End-to-End Observability For Your Entire AI Stack
はじめに
生成AI(Generative AI: GenAI)アプリケーションは、ビジネスに大きな変革をもたらす可能性を秘めていますが、その開発、デプロイ、そして運用は非常に複雑です。AIスタックは、基盤となるGPUインフラストラクチャから始まり、データレイク、モデルホスティング層、そして最も上位にあるアプリケーションとオーケストレーション層に至るまで、多層的な構造をしています。各レイヤーはそれぞれ固有の複雑性を持ち、特に基盤部分での問題は、AIアプリケーション全体に影響を及ぼす可能性があります。
本記事では、Datadogがいかにこの複雑なAIスタック全体を可視化し、特にGPUインフラストラクチャとGenAIアプリケーションの両面における運用課題を解決しているかを探ります。

GPUモニタリング:AI基盤を盤石にする
AIアプリケーションの根幹を支えるGPUは、その性能がアプリケーション全体のパフォーマンスに直結します。しかし、GPUインフラストラクチャの運用には多くの課題があります。実際、モデルトレーニングの失敗の30%はGPUに起因し、さらにGPUクラスターの約70%がアイドル状態にあり、コストが無駄になっているという報告もあります。
DatadogのGPUモニタリングは、これらの問題を解決するために、クラウドプロバイダー、オンプレミス環境、GPUアズ・ア・サービスプラットフォームを横断してエンドツーエンドの可視性を提供します。
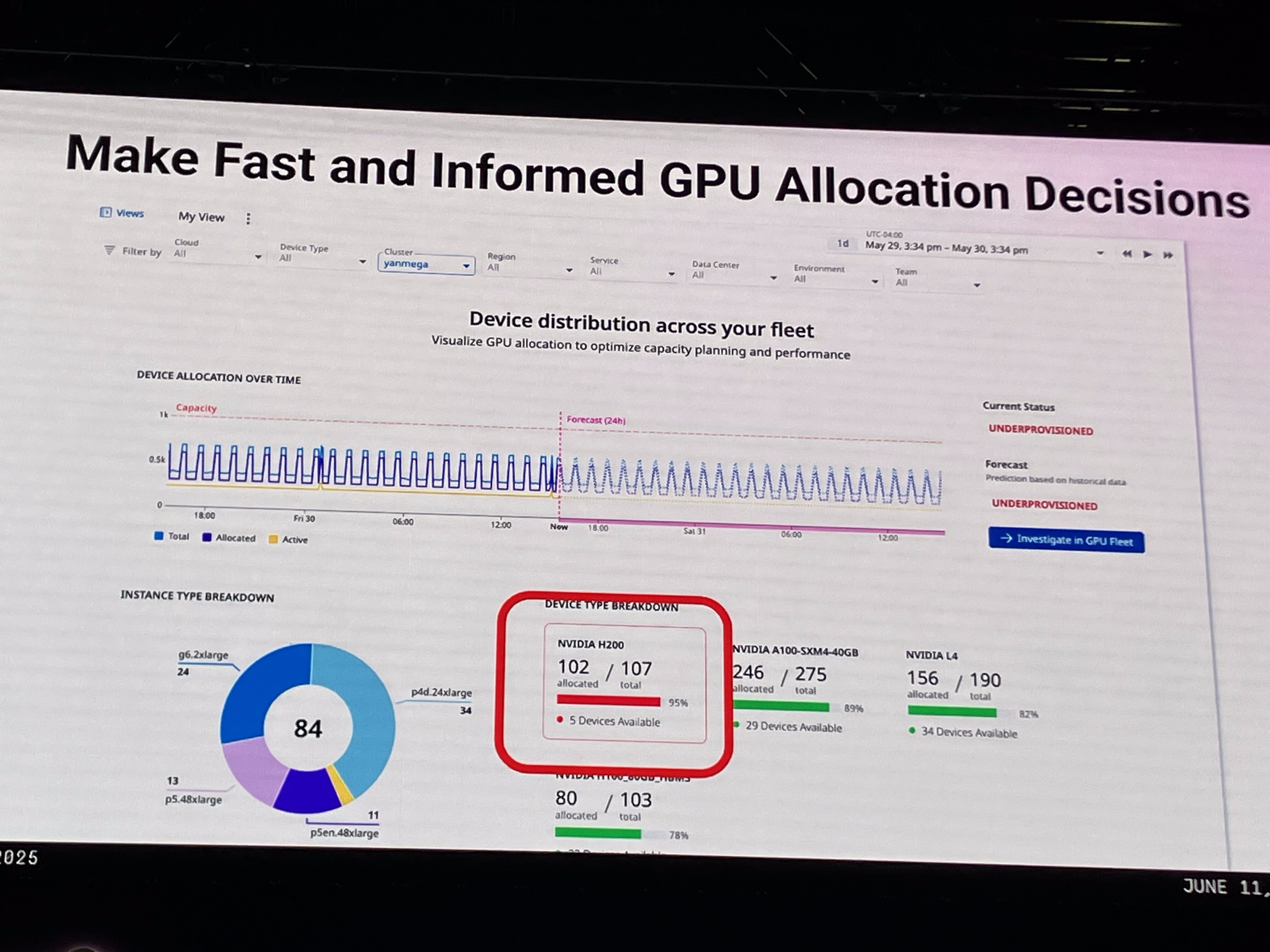
Datadogは、GPU運用における3つの主要な課題に焦点を当て、解決策を提供します。
1. リソース競合の解消 MLチームが限られたGPUリソースを奪い合うことで、サービスの遅延や停止が発生することがあります。DatadogのGPUモニタリングでは、どのワークロードがGPU不足で失敗しているか、どのGPU(例:A100)が完全に飽和状態にあるかを即座に特定できます。これにより、例えばRayサービスが実行されている特定のクラスターで必要なGPU数を迅速に増やすなど、わずか30秒で問題を解決し、トラブルシューティングに費やす時間を大幅に削減できます。
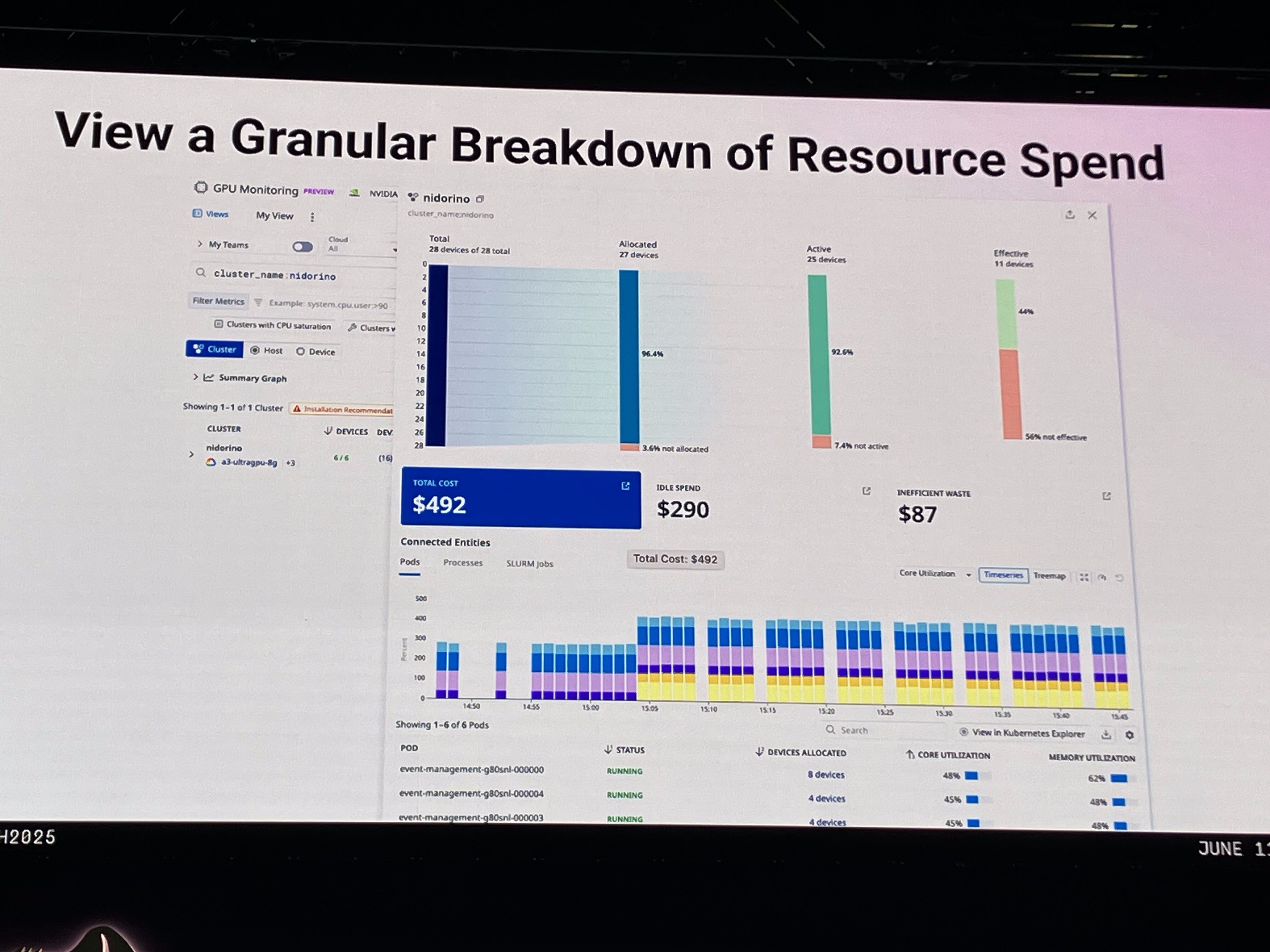
2. 暴走コストの抑制 GPUは非常に高価であり、無駄な使用は莫大なコストにつながります。Datadogは、GPUフリートにおける最も高価なクラスターや、無駄になっているコスト(アイドル状態のGPUや非効率なコア使用)を正確に可視化します。これにより、例えば非効率的に使用されているGPUを稼働しているポッドを特定し、統合することで、総コストを削減する具体的な最適化ポイントを特定できます。
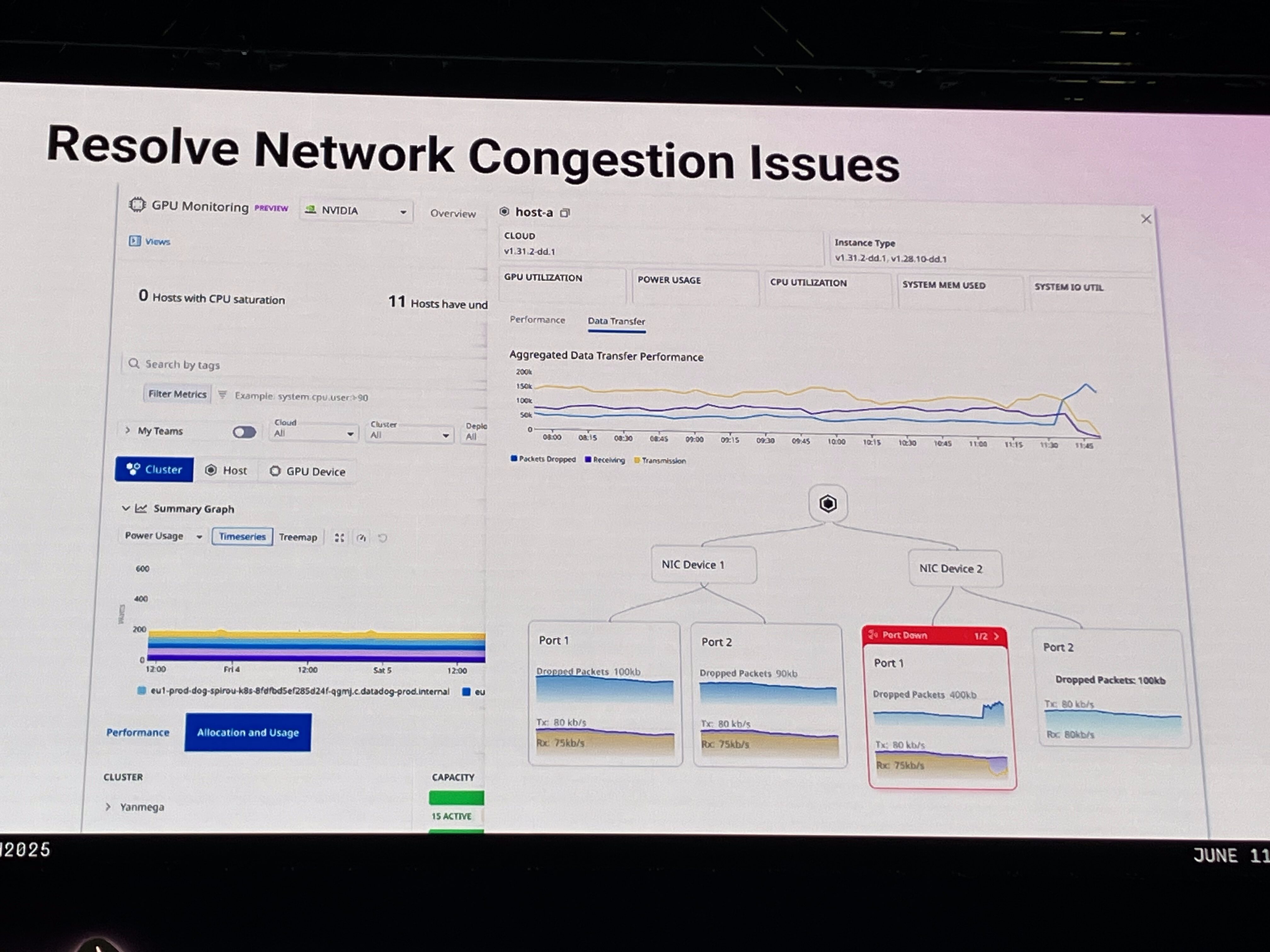
3. データ輻輳の解消 マルチノード、マルチGPUのワークロードでは、RDMA、EFA、Infiniband、NVLinkといった技術を使ってGPUホスト間や個々のGPU間を接続します。しかし、GPU間でデータが適切に転送されない「データ輻輳」が発生すると、モデルトレーニング時間が長引く原因となります。Datadogは、ノードごとのネットワークトポロジーや、データ転送のボトルネックとなっているネットワークスイッチやポートを可視化します。これにより、データ転送パスを最適化し、GPU間の効率的な通信を確保することで、ネットワーク問題によるトレーニング時間の遅延を防ぎます。
GenAIアプリケーションのオブザーバビリティ:品質とパフォーマンスの確保
GenAIアプリケーション、特にLLMやエージェントベースのシステムは、その開発から本番運用に至るまで、独自の複雑性を持っています。
- 開発・実験段階の課題: モデルやプロンプトの変更が、システムの品質やレイテンシ、出力結果にどう影響するかを把握するのは困難です。手作業での評価は時間と労力がかかります。
- 運用段階の課題: 顧客向けのアプリケーションでは、レイテンシは非常に重要です(例えば、3秒のレイテンシでエンゲージメントが80%減少した事例もあります)。また、LLMは機密データを扱う可能性があり、データ漏洩のリスクも考慮する必要があります。エラーが発生した場合、複雑なシステムチェーンのどこで、なぜ問題が発生したのかを特定するのも一苦労です。
Datadogのオブザーバビリティソリューションは、これらの課題に対応し、監視、トラブルシューティング、評価、実験といった機能を提供します。
- エンドツーエンドの可視化: アプリケーション全体の健全性、会話数、リクエスト数、ユーザーが質問するパターンの概要をダッシュボードで確認できます。
- エラーの迅速な特定: エラーの経時的なトレンドを把握し、最も頻繁に発生するエラーや、特定の関数、APIコール、ステップなど、問題の根源を特定できます。
- 応答品質の評価: モデルの応答が質問に答えられているかどうかの評価機能が組み込まれています。また、ユーザーが応答に「良い/悪い」といった評価を付けた場合、それをトレースに紐付けて品質改善に役立てることも可能です。
- マルチエージェントシステムの可視化: 複数のエージェントが連携する複雑なシステムでは、エラーの特定が非常に困難です。Datadogは、エージェントの操作を視覚的に表示し、線形のシーケンスだけでなく、実行パスをトレースすることで、トラブルシューティングを劇的に容易にします。
- 迅速なイテレーションと継続的改善: データセットを用いて実験を実行し、変更したモデルやプロンプトのパフォーマンスを比較検討できます。これにより、デグレード(性能劣化)のリスクを低減し、アプリケーションを継続的に改善していけます。
まとめ
生成AIの領域は常に進化していますが、今日のセッションで強調された主要なポイントは以下の通りです。
- 適切なオプションの選択: 組織のAI戦略、専門知識、ビジネス要件に基づいて、GenAIアプリケーションの構築とデプロイに最適なアプローチを選択することが成功の鍵です。
- セキュリティと責任あるAIの事前考慮: セキュリティを常に最優先し、責任あるAIについては、後から修正に戻るのではなく、事前に十分に検討しておく必要があります。
- データ駆動型アプローチ: 推測や見積もりではなく、GPUの使用状況やアプリケーションのパフォーマンス、コストなどの実際のデータに基づいて意思決定を行うことが、効率的かつ効果的な運用につながります。
Datadogは、GPUインフラストラクチャの最適化から、LLM・エージェントアプリケーションの品質とパフォーマンス管理、セキュリティ対策に至るまで、GenAIライフサイクル全体を支援する強力なオブザーバビリティソリューションを提供しています。これらの原則を適用し、適切なツールを活用することで、最も成功するGenAIアプリケーションを構築し、運用できるでしょう。
