
セッションタイトル
Data Observability and OpenLineage
はじめに
AI の浸透において、データの重要性はますます高まっています。また、同時に AI システムも一つのシステムだけで完結せずに、複数のシステムをパイプラインで組み合わせて実装することも一般的になっています。
データが複雑なパイプラインを通過し、多様なシステムやチームを跨いで処理される過程で、予期せぬ瞬間に「不適切なデータ」が混入し、システム全体に影響を及ぼすこともあります。
例えば、データに誤った値が入力され、そのデータが機械学習モデルの学習に用いられた結果、検索結果が本来意図したものとは全く異なるものになってしまう、といった事例が挙げられます。このような状況において、原因を特定しようとしても、データの出所、流れ、利用者を把握することが困難な場合、「暗黙的な依存関係」が不明瞭であるために、問題解決に多大な時間を要します。そこで重要になってくるのが、「データリネージ」です。
データリネージとは?
データリネージとは、データがどこから来て、どこへ行き、どのように変換され、誰によって消費されるかを示すメタデータのことです。これはまるで、写真に付随するEXIFデータが、その写真がどこで、いつ撮られたかを示すのと同じように、データの「来歴」を記録するものです。
データリネージが確立されると、以下のようなメリットがあります。
- 迅速な問題特定:データの問題が発生した際、影響範囲を素早く特定し、原因箇所を突き止めることができます。
- 変更の影響分析:システムに変更を加える前に、その変更がどのデータやダウンストリームのアプリケーションに影響を与えるかを予測できます。
- コンプライアンス対応:法務チームなどからデータの出所や流れについて問い合わせがあった際に、正確な情報を提供できます。
しかし、現実のデータエコシステムは非常に複雑で多様なテクノロジーが混在しており、それぞれが異なる言語を話しています。この異なる言語を話すシステム間で、データのつながりや関係性を把握するのは至難の業でした。
この課題に対処するために、「OpenLineage」というオープンスタンダードが登場しました。
OpenLineageはいかにしてこの問題を解決するか?
OpenLineageは、この課題に対して「共通の言語を追加する」というアプローチを取ります。それは、データパイプラインに関するメタデータを収集し、共有するためのオープンでベンダーニュートラルな標準です。
メタデータを収集する方法はいくつか考えられます。
- ソースコード分析:SQLクエリなどを解析し、メタデータを抽出します。ただし、デプロイされていないコードや本番環境との乖離が生じる可能性があります。
- アクティビティログの解析:システムが出力するクエリ履歴やアクティビティログから情報を読み取ります。ログ形式の変更に弱い、リアルタイム性に欠けるなどの課題があります。
- データシステムとの直接統合:オーケストレーションツール、処理エンジン、データウェアハウス、データベースなど、実際にデータを処理するシステムと直接連携します。
OpenLineage においては、この3つ目の「直接統合」が最も優れていると考えています。これは、データベース自体がどのようなデータを処理しているかを正確に知っているため、推測やログ解析による誤差をなくすことができるからです。
OpenLineageはJSONスキーマ仕様として定義され、PythonやJavaなどの主要言語向けライブラリも提供されており、オープンソースコミュニティによって既に多くの統合が進められています。
標準化の重要性
標準化は非常に重要です。もし標準がなければ、各ベンダーやユーザーがそれぞれ独自の DBT や Spark 統合を開発することになり、全体の運用価値は低いものになってしまいます。例えば、データ品質の問題がパイプラインの左側で発生しても、標準がなければその影響が最終的なダッシュボードにどう現れるのか、なぜ数字が間違っているのかを追跡することができません。
OpenLineageは、オブザーバビリティの分野で広く知られるOpenTelemetryと同様のDNAを持っています。OpenTelemetryが分散ソフトウェアシステムのテレメトリーデータ(メトリクス、ログ、トレース)に焦点を当てるのに対し、OpenLineageはデータパイプラインに特化して性能分析を行うことを目指しています。
OpenLineageのコアコンセプト
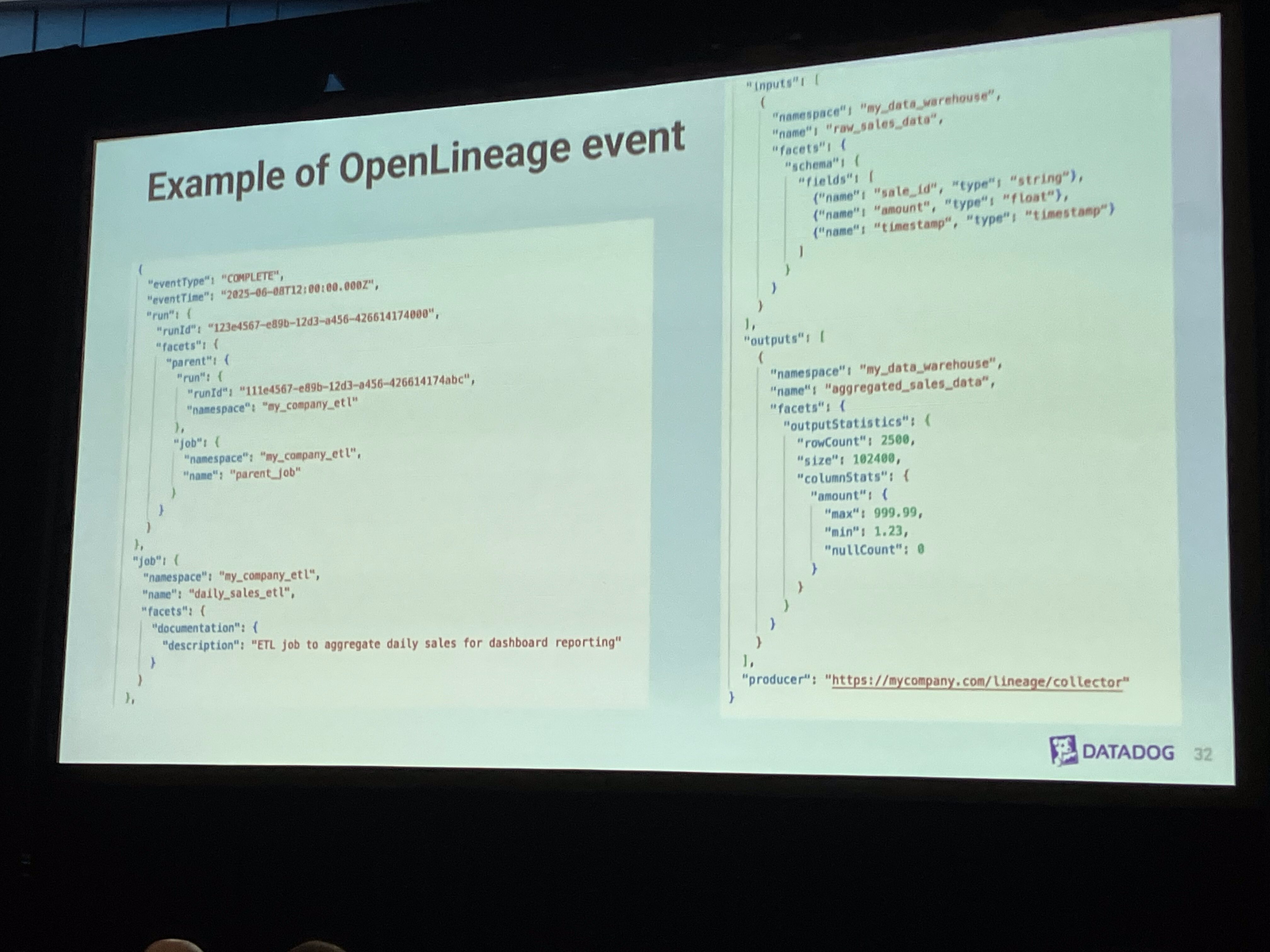
OpenLineageの核となるのは、以下の3つのエンティティです。
- ジョブ (Job):データを変換するパイプラインのタスク(例:Sparkジョブ、DBTモデルなど)。名前と名前空間で識別されます。
- 実行 (Run):特定のジョブの実行インスタンス。実行IDで識別されます。
- データセット (Dataset):パイプラインで生成または消費されるデータの抽象的な表現。名前で識別されます。
これらのエンティティには、さらに「データファセット (Data Facets)」と呼ばれる拡張可能なメタデータ構造を付与できます。これには、データセットのスキーマ情報(カラム名、型)、処理されたSQLクエリ、またはジョブの階層情報を表す「親ファセット (Parent Facet)」などが含まれます。
この情報は、「イベント」という形で送信されます。特に重要なのが「実行イベント (Run Events)」で、これにはジョブが消費する「入力データセット」と生成する「出力データセット」が記述されており、これによって実行時のリネージ情報をキャプチャできます。実行イベントには、開始、実行中、完了(成功・失敗)、中止といったライフサイクルがあります。
異なるシステムのつながりを可視化する
OpenLineageの優れた点は、異なるテクノロジーで動くジョブ間のリネージを「データセットの命名規則」を標準化することで繋ぎ合わせる点にあります。例えば、SparkがSnowflakeのデータセットを生成し、次にDBTがそれを使って分析を行うといった場合でも、OpenLineageの標準化された命名規則(データベース、テーブル名、プロジェクトIDなど)を用いることで、これら別々のジョブによって生成・消費されるデータセットを結合し、エンド to エンドのリネージグラフを構築することができます。
これは分散トレーシングとは異なり、データパイプラインでは「あるチームがデータを作り、別のチームがそれを読む」というように、直接的なリクエストの伝播がないため、データセットの命名規則とジョブの観測を組み合わせてグラフを繋ぎ合わせる必要があるのです。
DatadogでのOpenLineage活用事例
Datadogも、OpenLineageの恩恵を受けています。 Datadogのデータジョブ監視プロダクトでは、OpenLineageイベントを直接取り込むことで、Airflow DAGsやDBTモデル、Sparkジョブの実行状況、タスクの期間、失敗などのトップレベルのメタデータを監視できます。
特に、Airflow DAGがDBTプロジェクトを起動するようなシナリオでは、OpenLineageのrun IDとparent run IDの概念を使って、異なるエンティティやジョブ間のコンテキストを伝播させ、最終的に全ての情報をバックエンドで統合し、エンドツーエンドの体験を提供しています。これにより、例えばAirflowから起動されたSparkジョブの実行状況や、それが消費・生成するデータセットのスキーマ情報まで、ランタイムで完全にキャプチャすることが可能になります。
OpenLineageは、Datadog社内でもエンジニアリングチームの議論を削減し、データモデルの設計時間を大幅に短縮するのに役立っています。拡張性のあるモデルのおかげで、迅速な意思決定が可能になるのです。
まとめ
OpenLineageは、データパイプライン全体に統一されたオブザーバビリティをもたらします。何かが壊れたときに、どこで壊れたのかを特定するのが格段に容易になります。特定のカラムがどのデータソースからどのように計算されたのかを追跡できるため、データの来歴と正確性に対する信頼を高めることができます。
OpenLineageはオープン標準であるため、その動作は業界全体で一貫しており、エコシステム全体のコラボレーションを促進します。
GitHubへの参加やSlackコミュニティもあるようですので、ご興味のある方はぜひ!

